映画推薦システム
Website: https://kawastream.kawamottyan.com
GitHub:https://github.com/kawamottyan/kawastream
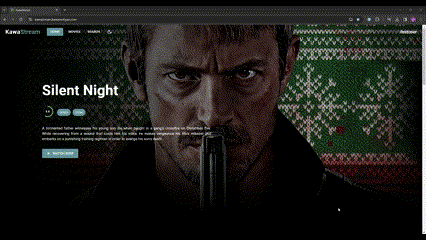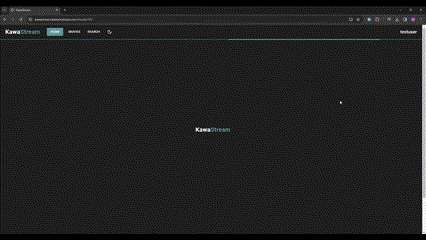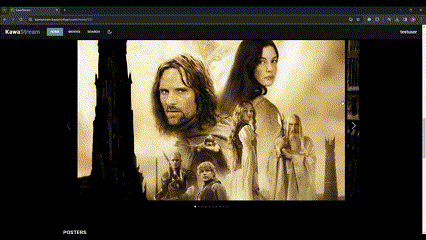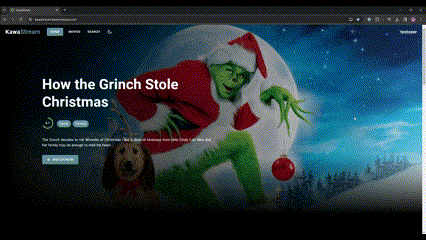
概要
目的
このプロジェクトは、映画ストリーミングサービスにおいてパーソナライズされた推薦システムの検討と構築を行う。これは、次に選択(クリック)される映画の予測を最適化すること、その予測を長期的に継続できるシステムを構築することによって達成される。
課題
- コールドスタート問題
- 探索と活用のトレードオフ
- 好みやトレンドの変動性
解決策
- セッションベースレコメンドアルゴリズム
- バンディットアルゴリズム
結果
- 映画推薦
ベンチマーク(Collaborative Filtering)より、NDGC@100が240%向上

- 映画ジャンル推薦
ベンチマーク(ε-greedy)より、推薦回数が少ない段階での精度が大幅に向上

課題
コールドスタート問題
コールドスタート問題とは、映画推薦システムにおける初期段階での課題である。これは新しいユーザーがシステムを利用し始めたとき、彼らの好みや履歴がまだないため、どの映画を推薦するべきか判断が難しいという問題である。
探索と活用のトレードオフ
探索と活用のトレードオフとは、新しい映画を試す「探索」と、過去のデータから映画を推薦する「活用」との間のバランスを指す。このバランスを適切に取ることで、ユーザー満足度を最大化することができる。
好みやトレンドの変動性
好みやトレンドの変動性は、ユーザーの映画に対する好みが時間とともに変化することを指す。ある時期はアクション映画を好むユーザーが、後にロマンス映画を好むようになるように、変動性を考慮した対策をしなければならない。
解決策
セッションベースレコメンドアルゴリズム
セッションベースレコメンドアルゴリズムは、ユーザーの一連の行動や選択を基に映画を推薦するシステムである。このアルゴリズムでは、ユーザーが一定の時間内に見た映画や評価した内容などのデータを分析し、そのセッションの文脈に基づいて関連性の高い映画を推薦する。
今回実装するモデルは、リカレントニューラルネットワーク(RNN)の一つであるGated recurrent unit(GRU)を使用した推薦アルゴリズム「GRU4Rec」である。長期的な使用を想定していないこのプロジェクトにおいて、比較的短期間のシーケンスデータに最適なアルゴリズムであるGRUを採用する。短期的な行動パターンの把握することで、コールドスタート問題の解決や短期トレンドの理解を図る。
解説や原著論文はこちらに記載する。
バンディットアルゴリズム
バンディットアルゴリズムは、特に探索と活用のトレードオフに対処するために設計されたアルゴリズムである。複数の選択肢の中から一つを選択し、その結果として得られる報酬に基づいて次の選択を行う。
今回実装するモデルは、コンテキストを考慮したバンディットアルゴリズム「LinUCB」
である。このアルゴリズムは、ユーザーの特定のコンテキストに基づいて最適な映画のジャンルを推薦する。
解説や原著論文はこちらに記載する。
結果
- GRU4Rec vs ベンチマーク(Collaborative Filtering)
評価指標として、上位100件の推薦アイテムの関連度を正規化して評価する指標であるNDGC@100を使用する。つまり20,000以上の映画から、予測した100の映画をクリックしたかどうかで評価する。
| NDGC@100 | |
|---|---|
| ベンチマーク | 0.0091 |
| GRU4Rec | 0.0219 |
ユーザー間の類似度に基づいて推薦するCollaborative Filteringよりも、シーエンスとしてデータを学習するGRU4Recの方が、2倍以上でNDGC@100が高い。
GRU4Recのコード
Collaborative Filteringのコード
- LinUCB vs ベンチマーク(ε-greedy)
アルゴリズムが特定の選択を行った結果、得られる数値的な利益の平均を比較する。ユーザーが好きな映画のジャンルをアルゴリズムが予測できた時、報酬1を渡す。アルゴリズムが映画のジャンルを30回選択し、その全ユーザーの各エポックにおける平均報酬の値が以下である。
| epoch1 | epoch5 | epoch10 | epoch20 | epoch30 | |
|---|---|---|---|---|---|
| ベンチマーク | 0.258 | 0.348 | 0.426 | 0.509 | 0.549 |
| LinUCB | 0.372 | 0.673 | 0.697 | 0.700 | 0.700 |
LinUCBはエポック5あたりで約70%の確率でユーザーの好きなジャンルを推薦していることがわかる。
LinUCBとε-greedyのコード
モデル
データ
下記条件に合うデータを使用
- 評価値が4以上のレビュー
- 上記条件において、5つ以上のレビューをしているユーザー
特徴量
- ユーザーID
- 映画ID
- タイムスタンプ
検証方法
- ユーザーIDごとに5フォールド交差検証
評価指標
- オフライン:NDCG@100
NDCG@100
DCG@100
-
i -
rel
IDCG@100
-
i -
rel
- オンライン:CTR(ABテスト)
モデル
- GRU4Rec
ベンチマーク
- コサイン類似度に基づく協調フィルタリング
モデル改善
- パラメータ探索
システム
システム構成
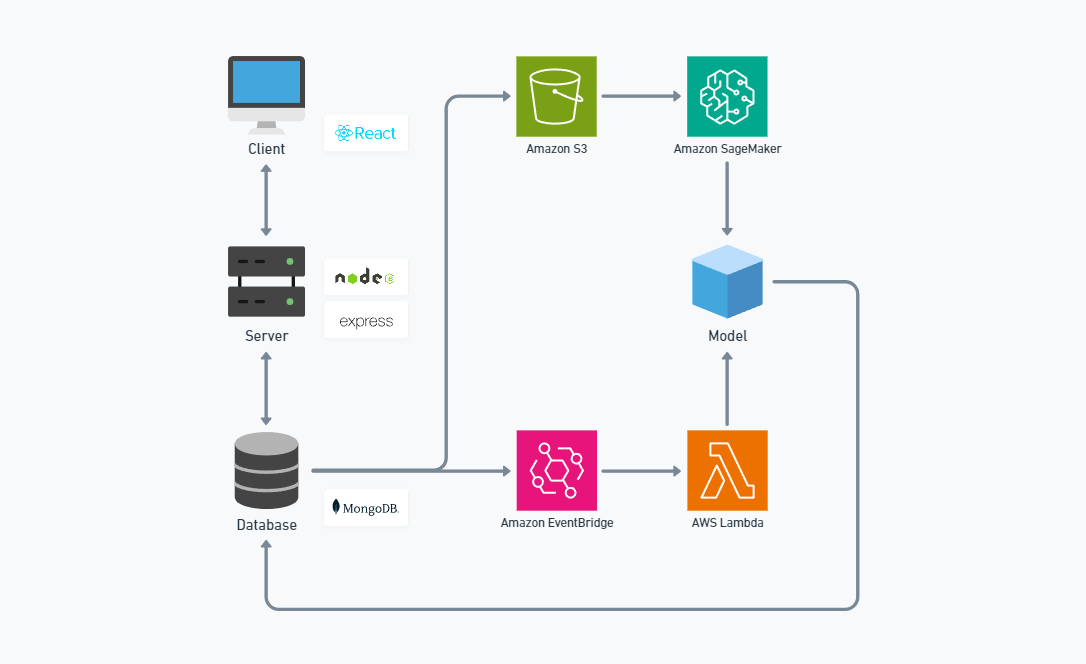
ワークフロー
モデル作成
- Amazon SageMakerでJupyter Notebookのインスタンスを立てる
- Jupyter Notebookでモデルのエンドポイントをサーバーレスで作成する
予測
- ログインユーザーのクリック、お気に入り、コメントデータをMongoDBに保存する
- MongoDBが更新されると、Amazon EventBridgeが起動する
- EventBridgeがAWS Lambdaがモデルのエンドポイントを呼び出す
- 予測結果をMongoDBに保存する
今後
- オンライン環境での効果検証
Discussion