はじめに
Google Cloud Run はじめて本格的に触りはじめました!たのしい!
もっと Cloud Run くん、とくに Jobs 実行となかよくなりたい!
ということで、今回は、dbt-labs さんが用意している架空のお店、jaffle_shop のデータを dbt で集計するようにして、それを Cloud Run Jobs で定期実行して、BigQuery に集計テーブルを作るハンズオン記事です。
概要
- 環境準備、使用するデータの説明
- local で実行してみる
- Cloud Run Jobs で実行してみる
1. 環境準備、使用するデータの説明
前提となる環境は以下です。
アカウント
- 有効な Google Cloud Account
ツール
Google Cloud の設定
gcloud によるプロジェクト作成
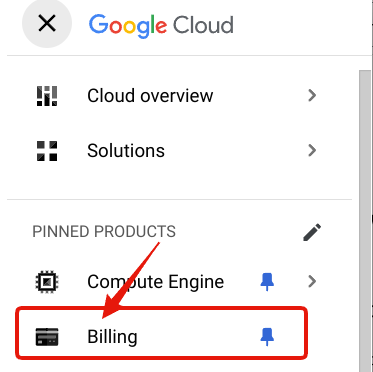
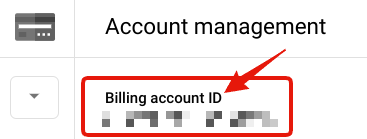
Billing account ID は、Google Cloud Console 上で "Billing" > "⚙Manage Billing Account" とすすんで、"Billing account ID" として表示されています。

$ export PROJECT_ID=[このハンズオン用のプロジェクトID]
$ gcloud projects create ${PROJECT_ID}
$ gcloud config set project ${PROJECT_ID}
$ gcloud alpha billing projects link ${PROJECT_ID} \
--billing-account=[Billing account ID]
gcloud による設定状況の確認
支払情報がプロジェクトに設定されているか確認します。
設定されていない場合は https://console.cloud.google.com から設定をお願いします。
$ gcloud beta billing projects describe ${PROJECT_ID}
以下の出力があれば大丈夫です
billingEnabled: true
使用するデータの説明
オープンソースのデータ操作ツール dbt を作成している dbt labs さんがチュートリアル用に公開している架空のお店のお客様とその購買データ達です。
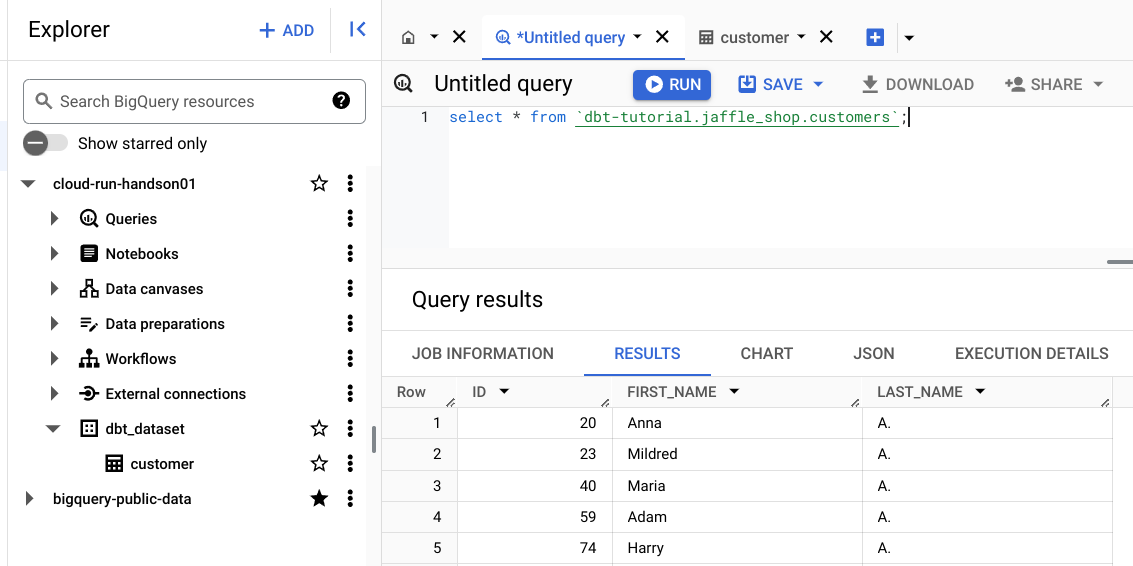
BigQuery 上からも、以下の query を発行することで、公開データを表示できます。
select * from `dbt-tutorial.jaffle_shop.customers`;
select * from `dbt-tutorial.jaffle_shop.orders`;
select * from `dbt-tutorial.stripe.payment`;
bq コマンドでの確認方法は以下です。
$ bq query --use_legacy_sql=false \
'select * from dbt-tutorial.jaffle_shop.customers limit 5'
2. local で実行してみる
Cloud Run で実行する前に local 環境で dbt を実行して試してみます。
gcloud による認証情報の作成
dbt コマンドから BigQuery に接続するための認証情報を作成します
$ gcloud auth application-default login \
--scopes=https://www.googleapis.com/auth/cloud-platform,\
https://www.googleapis.com/auth/bigquery
hands-on 用のディレクトリ、環境を用意
$ mkdir -p ./cloud-run-handson/jaffle_shop
$ cd ./cloud-run-handson/jaffle_shop
$ export DBT_DIR=$(pwd)
$ export PROJECT_ROOT=${DBT_DIR}/../
$ uv venv --python 3.12
$ source ./.venv/bin/activate
$ uv pip install dbt-bigquery
dbt プロジェクトに必要なディレクトリ、ファイルの作成
ディレクトリの作成
$ cd ${DBT_DIR}
$ mkdir models analysis tests seeds macros snapshots target
dbt_project.yml の作成
以下の内容を ./cloud-run-handson/jaffle_shop/dbt_project.yml として保存します
name: 'jaffle_shop'
config-version: 2
version: '1.0.0'
# 以降の手順で作成する接続用のプロファイル名を指定します
profile: 'jaffle_shop-bq-dev'
# dbt プロジェクトに必要なディレクトリたちです
# 詳細な説明はこちらに
# https://docs.getdbt.com/reference/dbt_project.yml
model-paths: ["models"] # ここで指定したディレクトリに集計用の sql ファイルを置きます
analysis-paths: ["analysis"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target"
clean-targets: [target, dbt_packages]
models:
jaffle_shop:
materialized: table
profiles.yml の作成
以下の内容を ./cloud-run-handson/jaffle_shop/profiles.yml として保存します
jaffle_shop-bq-dev:
target: dev
outputs:
dev:
type: bigquery
method: oauth
# Google Cloud の project id が
# 環境変数 PROJECT_ID に設定されいると自動的に読み込まれます
project: "{{ env_var('PROJECT_ID') }}"
dataset: jaffle_shop
threads: 4
接続チェックを行います
$ cd ${DBT_DIR}
$ dbt debug --profiles-dir .
下記のような出力が表示されれば、接続チェックは完了です。
03:11:49 Connection test: [OK connection ok]
03:11:49 All checks passed!
集計用の sql ファイルの作成
以下の内容を ./cloud-run-handson/jaffle_shop/models/customers.sql として作成します。
-- Description: This model aggregates customer data from the customers and orders tables
with customers as (
select
id as customer_id,
first_name,
last_name
from `dbt-tutorial`.jaffle_shop.customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from `dbt-tutorial`.jaffle_shop.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
BigQuery への dbt run 実行
以下のコマンドを実行します
$ cd ${DBT_DIR}
$ dbt run --profiles-dir .
下記のような出力が表示されれば、集計テーブル作成は完了です。
04:39:05 Running with dbt=1.9.0
04:39:05 Registered adapter: bigquery=1.9.0
04:39:06 Unable to do partial parsing because saved manifest not found. Starting full parse.
04:39:06 Found 1 model, 487 macros
04:39:06
04:39:06 Concurrency: 4 threads (target='dev')
04:39:06
04:39:09 1 of 1 START sql table model dbt_dataset.customer .............................. [RUN]
04:39:31 1 of 1 OK created sql table model dbt_dataset.customer ......................... [CREATE TABLE (100.0 rows, 4.3 KiB processed) in 22.04s]
04:39:31
04:39:31 Finished running 1 table model in 0 hours 0 minutes and 24.94 seconds (24.94s).
04:39:31
04:39:31 Completed successfully
04:39:31
04:39:31 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
bq コマンドでテーブルが作成されているか確認します。
$ bq ls dbt_dataset
以下のような表示があるはずです
tableId Type Labels Time Partitioning Clustered Fields
---------- ------- -------- ------------------- ------------------
customer TABLE
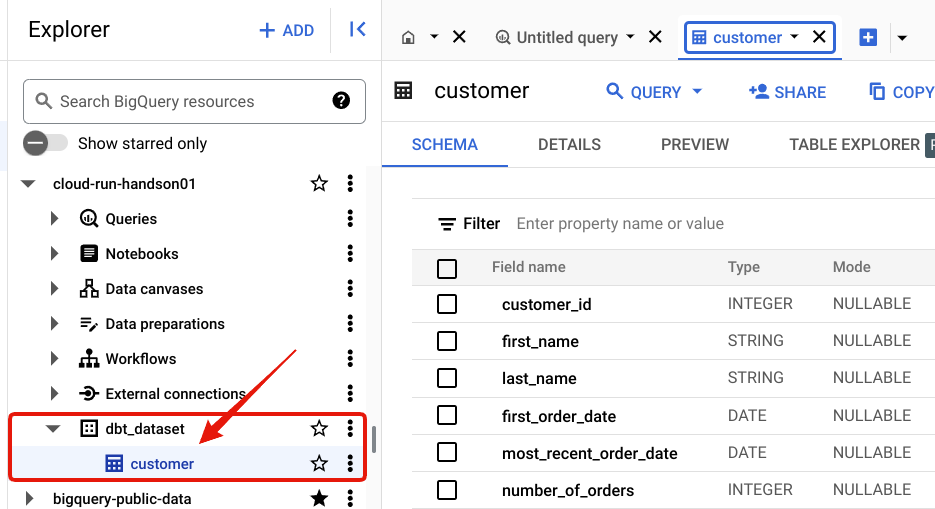
コンソール上からも確認できます
3. Cloud Run Jobs で実行してみる
Cloud Run Jobs で実行するために、必要なことを箇条書きにします
- dbt を実行する Shellscript を書く
- Dockerfile を用意する
- Job Container を build して Artifact Registry に送信する
- Cloud Run jobs を作成する
- 一度手動実行してみる
- うまくいったら定期実行する
dbt を実行する Shellscript を書く
以下の内容を ./cloud-run-handson/run.sh として保存します
#! /usr/bin/env bash
set -e
dbt run --profiles-dir .
Dockerfile を用意する
以下の内容を ./cloud-run-handson/Dockerfile として保存します
FROM fishtownanalytics/dbt:0.19.0
WORKDIR /dbt
COPY run.sh ./
COPY jaffle-shop ./
CMD [ "./run.sh" ]
Job Container を build して Artifact Registry に送信する
以下のコマンドで Artifact Registry API を有効にします
$ gcloud services enable \
cloudresourcemanager.googleapis.com \ # プロジェクト、フォルダ、タグ 管理の API
artifactregistry.googleapis.com #
Artifact Registory を作成します。
$ export REGION=asia-northeast1
$ gcloud artifacts repositories create \
${PROJECT_ID}-repository \
--location=${REGION} \
--repository-format=docker
Artifact Registry (asia-northeast1-docker.pkg.dev) に対して使用する Docker の認証情報を設定します
$ gcloud auth configure-docker ${REGION}-docker.pkg.dev
docker image を build します
$ cd ${PROJECT_ROOT}
$ export DOCKER_IMAGE_NAME=aggregate-dbt-dataset-customer
$ docker build \
-t ${REGION}-docker.pkg.dev/${PROJECT_ID}/${PROJECT_ID}-repository/${DOCKER_IMAGE_NAME} .
先ほど作成した docker image を Artifact Reagistry に送信します
$ docker push \
${REGION}-docker.pkg.dev/${PROJECT_ID}/${PROJECT_ID}-repository/${DOCKER_IMAGE_NAME}
docker image が存在するか確認します
$ gcloud artifacts docker images list \
${REGION}-docker.pkg.dev/${PROJECT_ID}/${PROJECT_ID}-repository
存在していれば、バッチリ OK です!
Cloud Run Jobs を作成する
さきほど、Artifact Registry に送信した docker image から Cloud Run Jobs を作成します
$ export JOB_NAME=aggregate-dbt-dataset-customer
$ gcloud beta run jobs create ${JOB_NAME} \
--image ${REGION}-docker.pkg.dev/${PROJECT_ID}/${PROJECT_ID}-repository/${DOCKER_IMAGE_NAME}:latest \
--region ${REGION}
下記が表示されれば、Cloud Run Jobs 作成完了です!
Creating Cloud Run job [aggregate-dbt-dataset-customer] in project [cloud-run-handson01] region [asia-northeast1]
⠧ Creating job...
(y/N)?y
⠧ Creating job...
✓ Creating job... Done.
Job [aggregate-dbt-dataset-customer] has successfully been created.
To execute this job, use:
gcloud beta run jobs execute aggregate-dbt-dataset-customer
一度手動実行してみる
先に、local からの dbt 実行で作成した customer テーブルを削除しておきます
$ bq rm --force dbt_dataset.customer
Cloud Run API を有効にします
$ gcloud services enable run.googleapis.com
Cloud Run Jobs を実行します。
$ gcloud beta run jobs execute \
${JOB_NAME} \
--region=${REGION}
すると、以下が表示されて、実行の詳細を見る方法がわかります
✓ Creating execution... Done.
✓ Provisioning resources...
Done.
Execution [aggregate-dbt-dataset-customer-brbrt] has successfully started running.
View details about this execution by running:
gcloud beta run jobs executions describe aggregate-dbt-dataset-customer-brbrt
# 以下の URL は架空です
Or visit https://console.cloud.google.com/run/jobs/executions/details/asia-northeast1/aggregate-dbt-dataset-customer-brbrt/tasks?project=1234556666666666
うまくいったら定期実行する
実行がうまく行ったので、定期実行を設定します
定期実行のために Cloud Scheduler API を有効にします
$ gcloud services enable cloudscheduler.googleapis.com
$ export SCHEDULER_JOB_NAME=aggregate-dbt-detaset-customer-every-1hr
$ gcloud scheduler jobs create http ${SCHEDULER_JOB_NAME} \
--location ${REGION} \
--schedule="0 * * * *" \
--uri="https://${REGION}-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/${PROJECT_ID}/jobs/${JOB_NAME}:run" \
--time-zone="Asia/Tokyo" \
--http-method POST
以下が表示されれば成功です!
Enabling service [cloudscheduler.googleapis.com] on project [cloud-run-handson01]...
Operation "operations/acf.p2-878187681891-cfe7162b-8935-4dd5-9966-379b0facc6ac" finished successfully.
attemptDeadline: 180s
httpTarget:
headers:
User-Agent: Google-Cloud-Scheduler
httpMethod: POST
uri: https://asia-northeast1-run.googleapis.com/apis/run.googleapis.com/v1/namespaces//jobs/aggregate-dbt-dataset-customer:run
name: projects/cloud-run-handson01/locations/asia-northeast1/jobs/aggregate-dbt-detaset-customer-every-1hr
retryConfig:
maxBackoffDuration: 3600s
maxDoublings: 16
maxRetryDuration: 0s
minBackoffDuration: 5s
schedule: 0 * * * *
state: ENABLED
timeZone: Asia/Tokyo
userUpdateTime: '2024-12-14T07:39:13Z'
Cloud Scheduler の定期実行リストを確認します
$ gcloud scheduler jobs list \
--location=${REGION}
ちゃんとでてますね!よかた
ID LOCATION SCHEDULE (TZ) TARGET_TYPE STATE
aggregate-dbt-detaset-customer-every-1hr asia-northeast1 0 * * * * (Asia/Tokyo) HTTP ENABLED
さいごに
ここまでお読みくださりありがとうございました!
Cloud Run くんと仲良くなれた気がします
今回作成したプロジェクトの削除をお忘れなくー
$ gcloud projects delete ${PROJECT_ID}
Cloud Run 5 周年!めでたい!

参考資料
今回の内容は、meteatamel さんの Scheduled Cloud Run dbt service with BigQuery を参考に、Cloud Run Jobs 対応版に書き換えました。

株式会社カウシェのProduct開発チームによる技術ブログです。 「日常に楽しさを」「新しい生活圏のカタチをつくる」をミッション・ビジョンに掲げ「誰かと一緒に」を楽しむソーシャルEC、カウシェを開発しています。 enjoy-working.kauche.com
Discussion