ChatGPTのCode InterpreterでNumeraiデータを分析(しようと)した
(注:以下フィクションが含まれます)
序章
それは2023年7月7日、七夕。いまや織姫や彦星より遥かに強い輝きを放つOpenAI社より、ChatGPT Plusユーザ向けに、Code Interpreterという新機能が発表された。
この機能を使えば、ChatGPTにコードを実行させることができるぜ!アップロードしたデータに対して分析をさせたり、グラフを作らせたり、ファイルを編集させたり、数値計算などなどをさせることができるぜ!(意訳)
私は驚愕した。
私は普段、某事業会社にて、名目上はデータサイエンティストとして働いている。何をしているかといえば、営業やマーケティングの皆様から
「(よく中身知らんけどけど)データ渡すから今週中に分析して報告して」
「エクセルだとベン図作るの難しいから、ベン図作っておいて。すぐやってくれると嬉しい」
「ベンダーに渡すデータをいい感じに加工しておいて。今日中にやっといてくれればいいから」
「このシナリオに合うように何パターンかこの指標計算しておいて。えっ?うん明日まで」
などなどのタイムリーなリクエストをいただき、日々皆様の先見性に感涙しながらPythonでデータを処理しているのだ。
私「はいこれは失業!」
AIが人類の仕事を奪うと叫ばれ始めて早X年(知らない)。今までもさまざまな職種が機械化・自動化によって失われてきたが、早くも私の番が来てしまったようだ。
私「...いや早すぎでは!?まだ社会に出て⚫︎年なんだが!?」
失業した私は、人類の広大な歴史の中における自分の立ち位置を自覚した。そう、私は所詮Code Interpreterが出るまでの繋ぎだったのである。
これからどうしようか。私はChatGPTに聞いてみた。
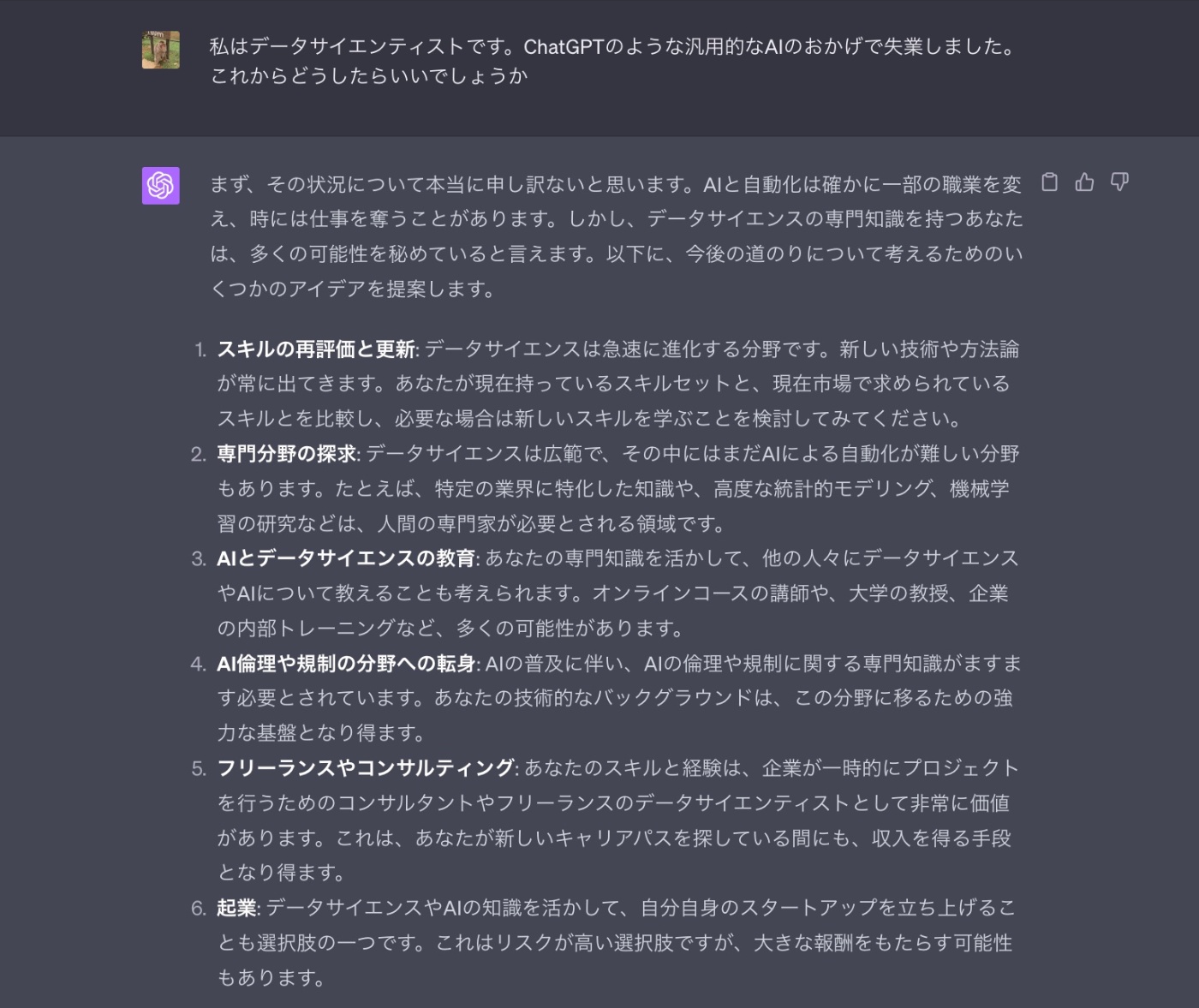
ChatGPTの優しい回答の中で、私が注目したのは以下のポイントである。
専門分野の探求: データサイエンスは広範で、その中にはまだAIによる自動化が難しい分野もあります。たとえば、特定の業界に特化した知識や、高度な統計的モデリング、機械学習の研究などは、人間の専門家が必要とされる領域です。
私の専門分野...それはもちろん営業とマーケティングの靴を舐めることである。これは確かにまだAIによる自動化は難しい。
一方で、仮にもデータサイエンティストを名乗っている以上、営業やマーケティングの皆様よりもChatGPTを使いこなせることを求められることは想像に難くない。
彼彼女らは今まで私をChatGPTのように叩いてきたが、これからは私のような偽物ではなく本物のChatGPTを叩くようになる。
そんなとき、私もいつまでも叩かれる側にいる意識ではいけない。
叩く側になるのである。
今まで叩かれてきた経験を最大限活用し、どのように叩かれると嬉しいか、皆様に啓蒙していく役割を担っていくのである。
そこで私は、とりあえず自分が興味のあるデータとして、Numerai Tournamentの訓練データのEDA (Exploratory Data Analysis)をCode Interpreterを使ってやってみることにした。
私は今までNumeraiに関する記事を偉そうにいくつか執筆してきた。
など
...が、いやぁ、なんというかそのぅ、なんやかんや過去3年間、Numerai TournamentのデータのEDAをまともにしたことがないのである。
私「いやデータ重いし!頻繁に更新あるし!あと私の主戦場はTournamentじゃない、Signalsなのである...!」
そんな日も今日で終わりである。私はCode Interpreterを使ってサクッとNumerai Tournamentのデータを分析し、これをきっかけにChatGPTマスターになるのである...!
第1章:いきなり挫折する
私はまずNumerai Tournamentの最新の訓練データをChatGPTに読み込ませようと試みた。
にアクセスし、train.parquetをローカルにダウンロードし、それをCode InterpreterをenableしたChatGPTにアップロードする。
ChatGPT「フッ...キミは大きすぎるね...重いよ...」
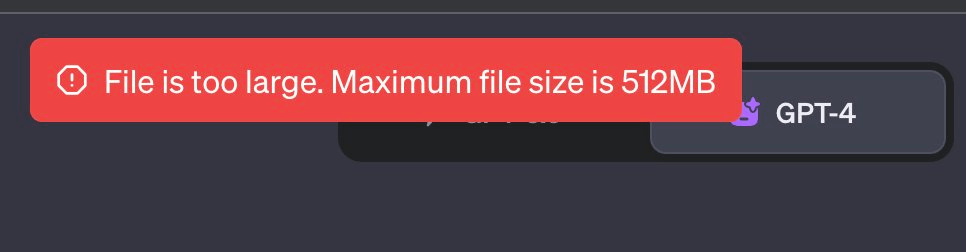
ChatGPTくんはファイルサイズが512MBまでじゃないと受け入れてくれないらしい。
私は仕方なく全データのうち最後の15 eraだけ(全体の約3%、正味約2~3ヶ月分のデータ)だけを使うことにし、結果を.parquetに保存して再度uploadしてみた。
ChatGPT「フッ...キミの姿...受け入れられないよ...」
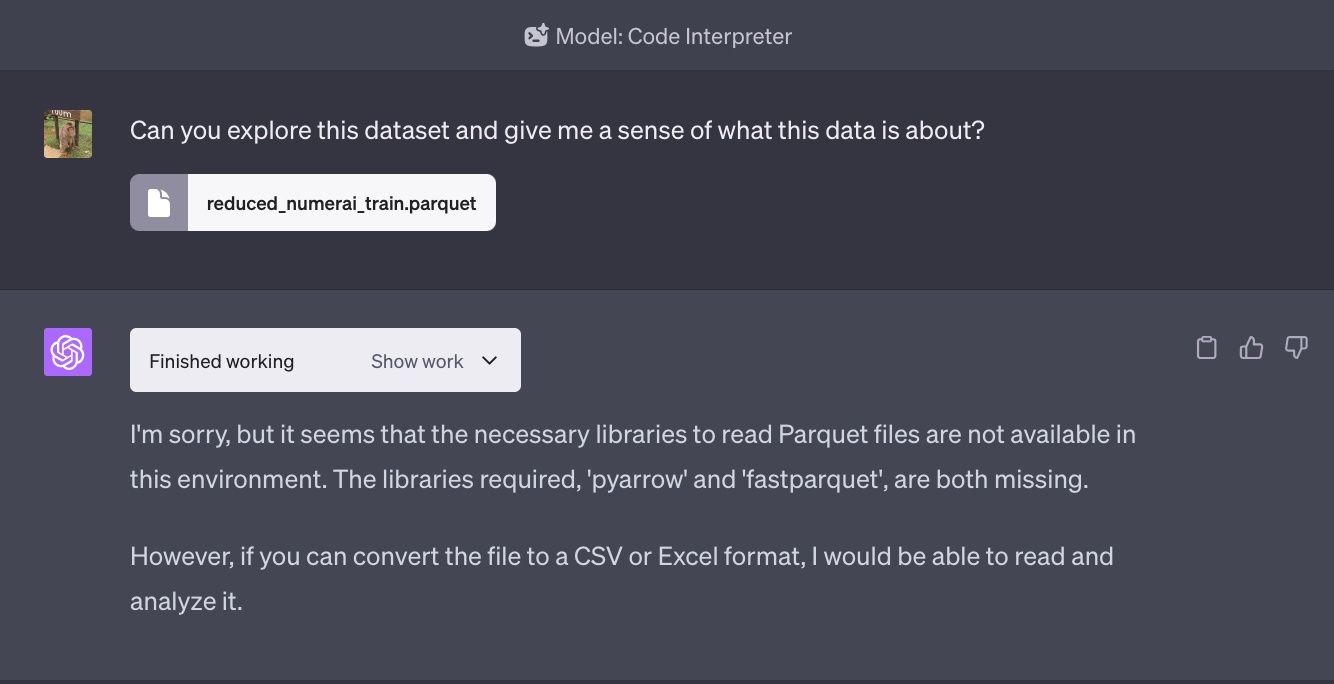
ChatGPTくんは .csvか.xlsxじゃないと受け入れてくれない らしい。
第2章:カラムの説明ができる
私はブチ切れながら、データを.csvに変換し、uploadした。そして「このデータについて説明しろ」と雑に質問をした。

データだけ与えられ、それを説明しろと言われたら私ならブチ切れである。データとその説明がないと分析も何もあったもんではない。
私は高飛車なChatGPTくんがブチ切れる様子を期待した。ところが、ChatGPTくんは予想を超えた回答を返してきた。
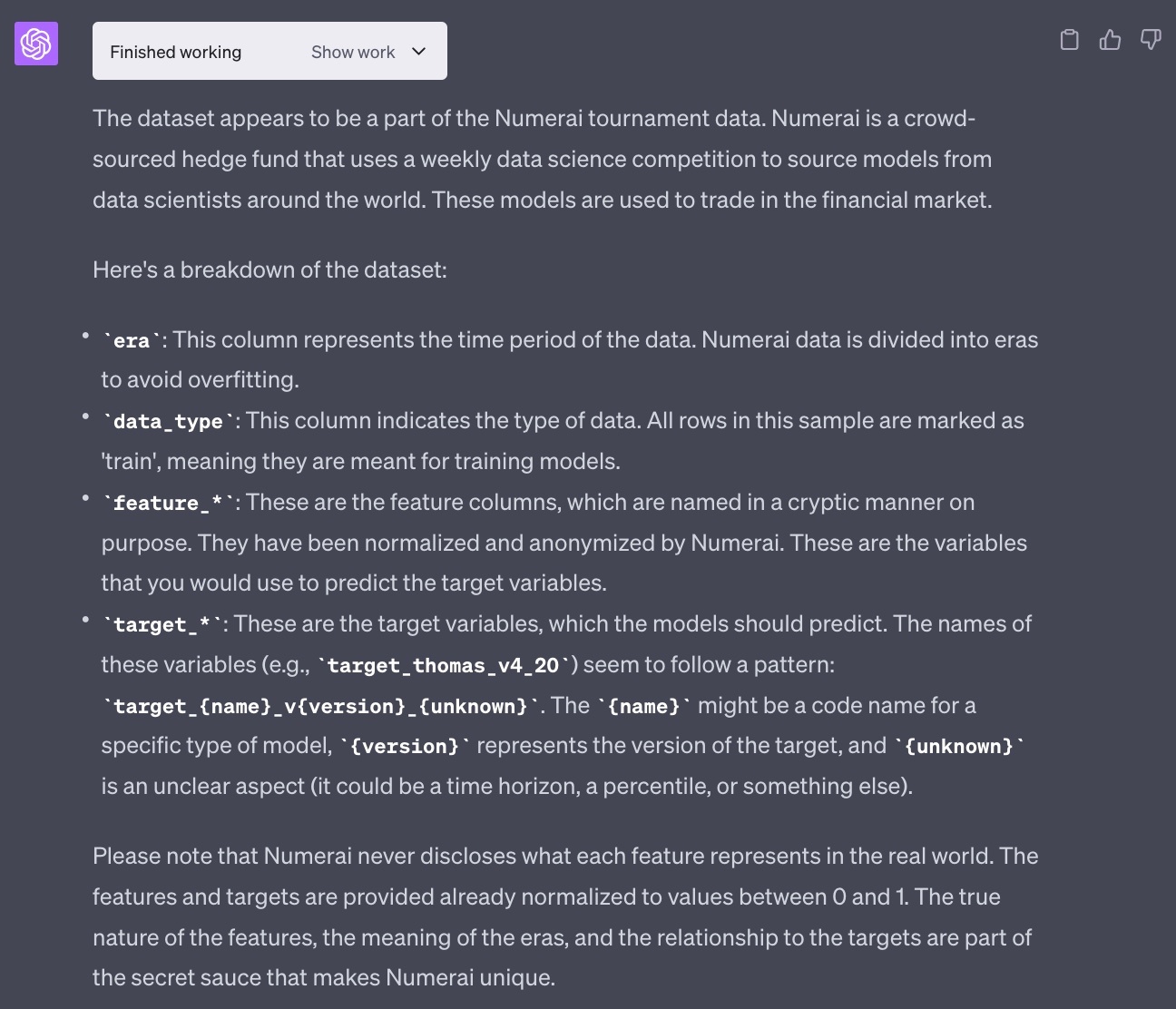
私がuploadしたデータがNumeraiのデータの一部であることを理解しており、そしてNumeraiが何かの簡潔な説明までついている。
もちろんファイル名にヒントがあるといえばあるが、カラムの説明era, data_type, そして特徴量群(feature_)とターゲット群(target_)はその分類も含めほぼ完璧である(targetのvは20だと20日ターゲットであり、unknownの部分は直交化要素が違うターゲットであることを示す匿名ラベルだが、まぁさすがにそこまではわからないだろう)。
私「はいこれは失業!」
第3章:EDAができる
次に私はEDAをやってもらえるようにお願いした。
ChatGPTはデータが重すぎると文句をいいながらも、データの一部を用いて正しい統計を返してきた。
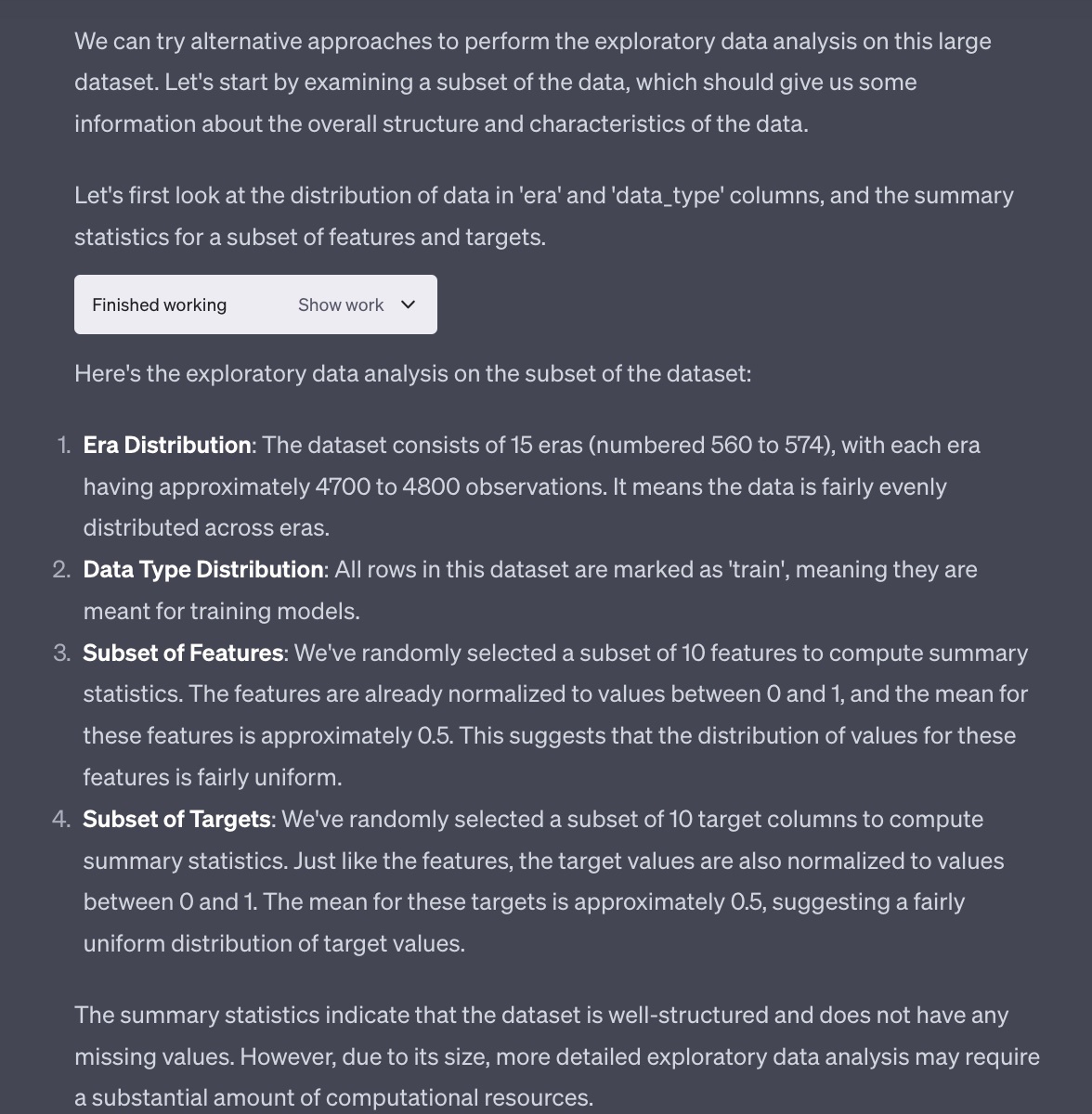
ただ、この辺りはEDAをやったことがない私でもなんとなく知っている。私が知りたいのは、もっとこのデータ特有の数字である。
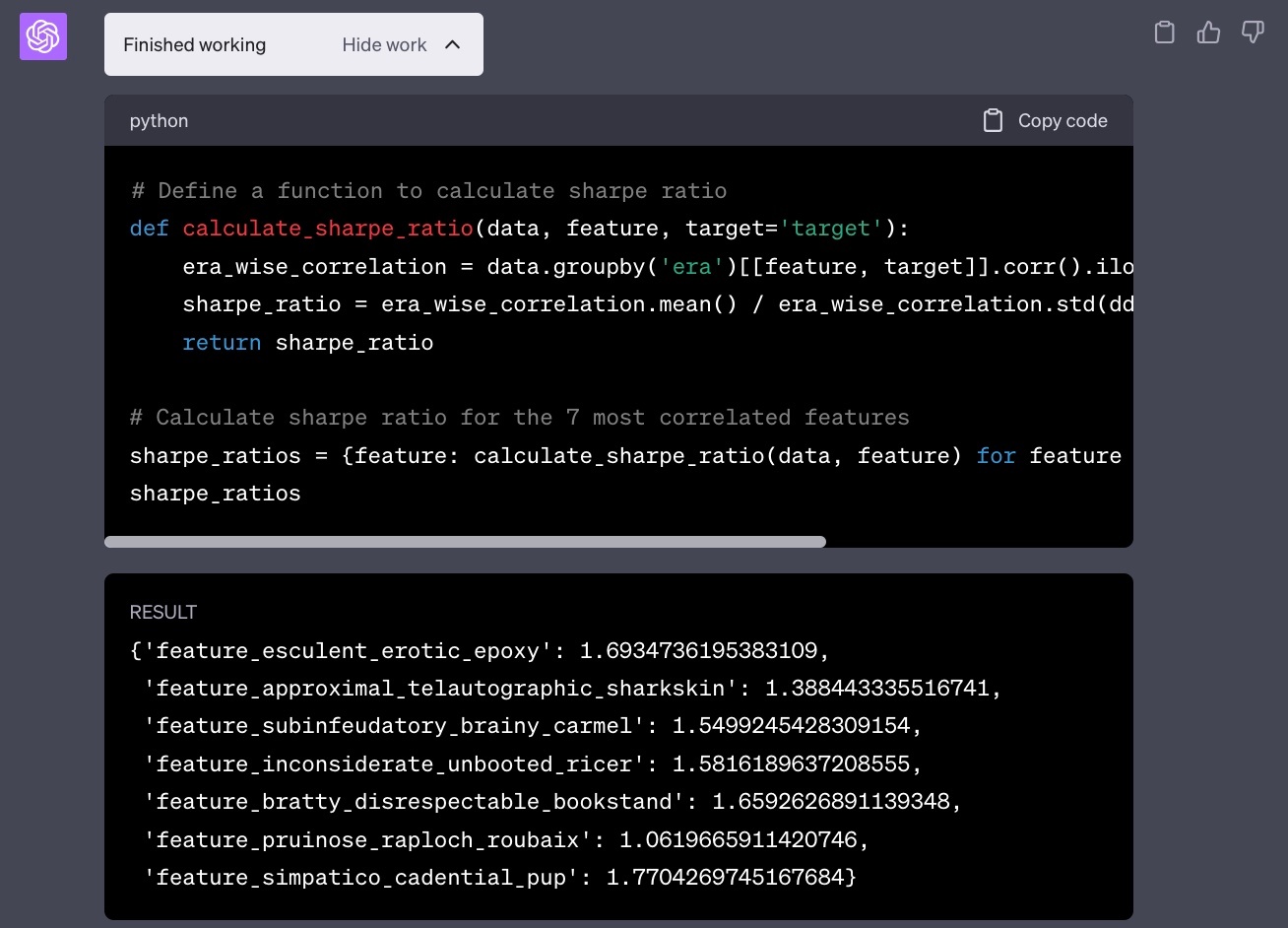
そこで、Numeraiの'target'と最も相関している7つの特徴量をリストアップしてもらうことにした。全てのカラムで相関係数を計算するのはメモリ的に辛そうだが、サンプリングして選んできた一部の特徴量で計算しても良いかと聞かれたので、そのように進めてもらうことにした。
そもそもデータアップロード時点でデータを3%程度に絞っているし、そこからChatGPTが特徴量を選んでいるので実際とは異なるだろうが、ChatGPT自身が
ChatGPT「あっ(targetとの相関を見るのに)targetカラム入れ忘れてたから入れるわ!」
などお茶目な試行錯誤を行い、相関が高い7つの特徴量が確かに得られた。
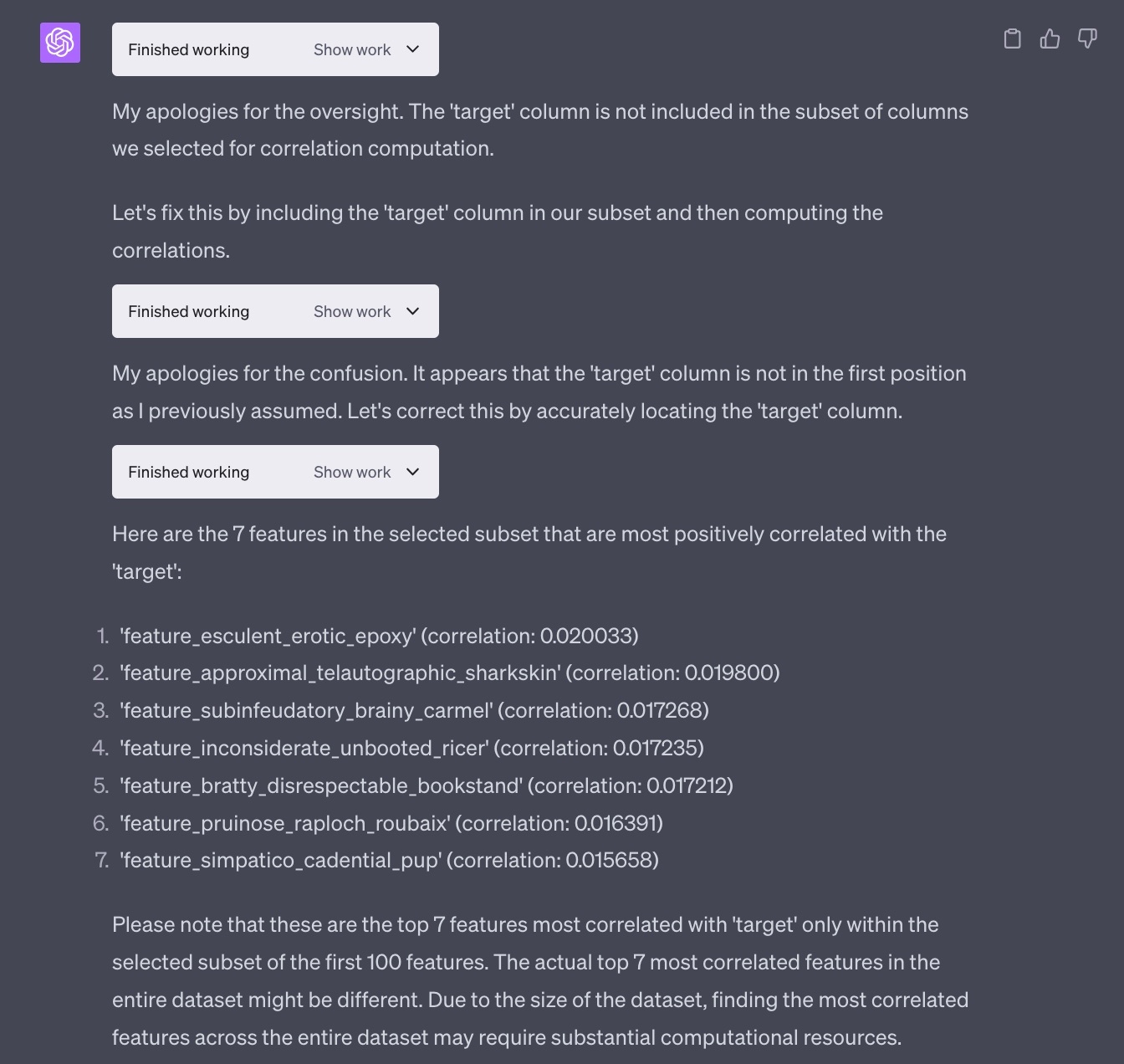
(サンプリングをして選んできた相関の高い匿名特徴量の1番上にer⚫︎ticとか含まれていますが、本当にただの偶然なのでbanしないでください...)
Correlationは重要であるが、金融時系列の代表的な指標はやはりsharpe ratioである。ChatGPTは数値計算もできるということだったので、この相関が高い7つの特徴量それぞれでsharpe ratioを計算させてみた。
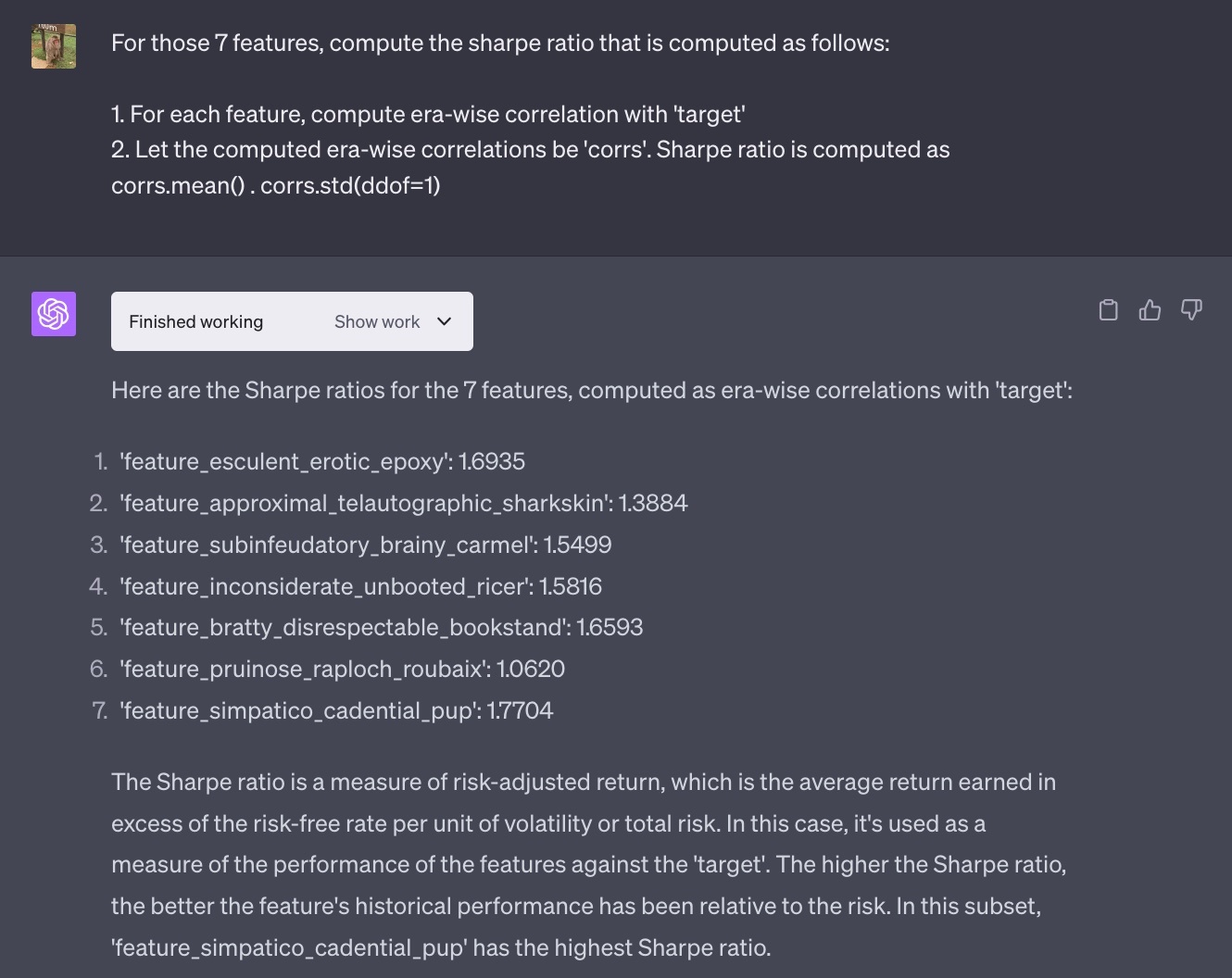
私「はいこれは失業!」
ちゃんと計算できている。Pythonコードも拝見したが、うん、あれですね、私が書くよりも綺麗なコード...
第4章:ChatGPTくん、やらかす
EDAによって7つの高い相関、sharpeの特徴量が見つかったわけだが、これらは同じような特徴量なのだろうか?
Numeraiの特徴量はテクニカル系、ファンダメンタル系さまざまあるが、特徴量名は全て匿名化されており、数値もbinになっている。
そのため、ここで出てきた7つの特徴量が、同じ系列の特徴量かどうかはモデリングに際し気になるところだ。
そこで、ChatGPTくんに、この7つの特徴量間のpairwise-correlationを計算し、図にしてくれるように頼んだ。
結果は衝撃だった。
ChatGPT「今までの分析結果なくしちゃった(^_−)−☆」

えっ...そんなことある...?私が唖然としている間にも、ChatGPTくんはリカバリーを自ら試みていた。
ChatGPT「えっと...importしたライブラリも全部忘れちゃった(^_−)−☆」
ChatGPT「...データ自体も無くしちゃった(^_−)−☆ もう1回渡してくれる?」
いや完全に新卒のときの私 である
なんか依頼来て割とさっとこなして終わった気になってたけど、あとから追加で同じデータでの依頼来て、「あっ...もうデータ消しちゃった...」ってなってたやつである。
第5章:ChatGPTくん、言い訳ばかりする
私は再度データをuploadし、ChatGPTくんに分析を進めてくれるようにお願いした。
しかし、割ともういっぱいいっぱいなのか、謝るばかりでデータをロードすることもできていそうにない。
ChatGPTくんのCode Interpreterくんも社会に出て1日とかである。きっとインプットすることが多くて余裕がないのだ。
結論
- ChatGPTのCode Interpreterはだいたい新卒の私(ただしpythonはもっと綺麗に書ける)
- 現状単一ファイルのかなり軽いデータしか扱えなさそう。そのため、データサイエンティストの方々が失業することもなさそう
- データをサンプリングしてCode Interpreterを使うことで、コーディングやレポート作成など業務削減の助けにはなりそう
- 今回は実施できなかったが、可視化や機械学習モデリングもできるようなので試してみたい(参考↓)
- 今後には大いに期待。早く私から営業とマーケティングの靴を舐める仕事を奪ってください
Discussion