AWS Step Functionsの学習
AWSのデベロッパーガイドを見ながら使い方を覚えていきます。
Lambda自体は触ったことあるので、ざっくり雰囲気を掴むため、チュートリアルを先にやってみます。
-
Lambda を使用するStep Functions ステートマシンを作成する
-
ステートマシンを使用してエラー条件を処理する
-
インラインマップステートを使用してアクションを繰り返す
まず、上から3つまでやってみました。
翻訳の妙なのか、設定する箇所がわかりにくい部分もありつつも、基本的にコピペで動くとこまではいけました。 -
次の式を使用してステートマシンの実行を定期的に開始します。 EventBridge
- Amazon S3 イベント発生時にステートマシンの実行をスタートする
EventBridgeやS3イベント発生についてはLambdaで似たようなことはやったことがあったため、
イベントで起動するサービスが変わっただけという認識で、さらっと読んで終わり。 -
API ゲートウェイを使用してStep Functions API
API GatewayもLambdaと置き換えて考えられそうな雰囲気だったので、さらっと読んで終わり。 -
Step Functions ステートマシンの作成しますAWS SAM
ここは実務で使う部分なので、ちゃんとやりました。
SAMは以前使ったことがあったので、Step Functionsだとどんなコードになるのか、yaml定義まわりをざっくり理解できました。
- アクティビティステートマシンの作成
この辺でベースの知識のなさから意味がわからなくなってきたので、ガイドに戻って知識を吸収せねばと思い至り、トピックでやっていこうと思い立ちました。
AWS Step Functions とは?
公式より
概要
分散アプリケーションのための視覚的なワークフロー
- Workflow Studio は、複雑なビジネスロジックをドラッグ & ドロップで簡単に表現できるインターフェースで、迅速に構築を開始できます。
- 220 以上の AWS サービスにおいて、コードをメンテナンスすることなくワークフローを自動化することができます。
- 大規模な並列ワークフローを使用してオンデマンドでデータを処理するためのコードを使用します。
- イベント駆動型アーキテクチャのための耐障害ワークフローを可視化し、開発します。
特徴
AWS Step Functions は、アプリケーションにサーバーレスオーケストレーションを提供します。オーケストレーションにより、複数のステップに分割されフローロジックが追加されたワークフローを、ステップ間の入力と出力を追跡しながら集中管理できます。
視覚的で使いやすいワークフロー設定
コンソール上で視覚的にワークフローを作成できる環境が用意されています。
ワークフローはLambdaを始めとするAWSのサービスを呼び出したり、フローの分岐や繰り返しなどの制御をドラッグ&ドロップで作っていけます。
学習用のワークショップがあるみたい。
一旦ガイドを読み進めてみて、あとで試してみる。
AWS SDK と最適化された統合
他のAWSサービスを呼び出したり、他のサービスから呼び出せるよって話。
[SDK 統合]と[Step Functions の最適化インテグレーション]の2種類あります。
ちょっとよくわからなかったのですが、こちらの記事見たら理解できました。
元々、最適化された統合の方があって他のサービスは直接呼び出せずにいて、そのためにはlambdaを書いてlambdaからサービス呼び出しをする必要があったのが、ステートから直接Arnを指定して呼び出すことができるようになったという理解。
ステートマシンをコンソールからGUIベースで作っている分にはあまり困ることはなさそう。
ここで選べないものは統合されていないので、lambdaでAPI呼び出しするなどするものと思っておけば良い感じ。
IaC的に作るにしても一度コンソール上で仮組みしてそのASLをコピーしてasl.jsonにするのが楽な気がします。
サポート外のAPIは下記ページに一覧化されている。
サポート対象サービスのサポートされていない API アクション
Standard ワークフローと Express ワークフロー
ワークフローには2種類ある。
- Standard ワークフロー
- 各ステップが1回づつ実行される
- 実行時間:最大1年間実行できます。
- Expressとの比較で見ると、1回の実行で最長1年間ということか?多分タイムアウト1年的な意味
- 実行速度:2,000/秒
- 毎秒 4,000 の状態遷移レート
- Express ワークフロー
- 各ステップが複数回実行される可能性あり。
- 実行時間:最大5分間
- 実行速度:100,000/秒
- ほぼ無制限の状態遷移レート
ストリーミングデータやIoT系の大量なデータを扱うならExpressで、それ以外は標準で良さげ。
差分の詳細については下記
ユースケース
一般的なユースケース
ユースケース #1: 関数オーケストレーション
- 順番にlambdaを呼び出していく
- 前のlambdaの終了を待って、次のlambdaが動く
ユースケース #2: 分岐
分岐です。
ユースケース #3: エラー処理
エラーが起きた際の制御を指定可能
Retry:同じステートを再実行
Catch:エラー時に実行するステートを指定
詳細は以下
ユースケース #4: ヒューマンインザループ
人間による承認操作など別システムの応答など、外部からの応答を待つ
ユースケース #5: 並列処理
複数のステートを並列に同時実行
それぞれのステートは異なる処理を実行可能
ユースケース #6: 動的並列処理
こちらも同時にステートを実行するが、5との違いは同一のステートを並列に動作させ、
並列に実行されたステートの全ての終了を待って次のステートを実行する。
switch caseで分けた処理を同時実行するのが5で、
配列でfor文回して実行する部分を並列化するのが6という印象
サービス統合
序盤で色々見た統合の話と思いきや各サービスを呼び出した後、Step Functionsがどのように待つかを示している。
- レスポンス受信(デフォルト):レスポンスが返ってきたら次のステップへ進む
- ジョブの実行後:呼び出したサービスの処理が完了したら次のステップへ進む
- タスクトークン:タスクトークンでサービスを呼び出す。コールバックが返されるまで待つ
統合するサービスによって上記のパターンのどれが使えるかが違う。
ワークフローの種類によっても使えるパターンが違う。
現状、Expressはレスポンス受信のみ
コールバックパターンを用いたり、バッチなどジョブの実行まで待ちたい場合に考慮する
サポートされている リージョン
基本使えます。
一部対応していないリージョンがある。
ちょっと気になって見れるリージョン見てみましたが、デフォルトで選べるリージョン、有効にできるリージョンで、使えないリージョンはなかったです。
有効にできなかったリージョンが3つほどあったのでそこかもしれません。
開始方法
このイメージのステートマシーンを作っていく
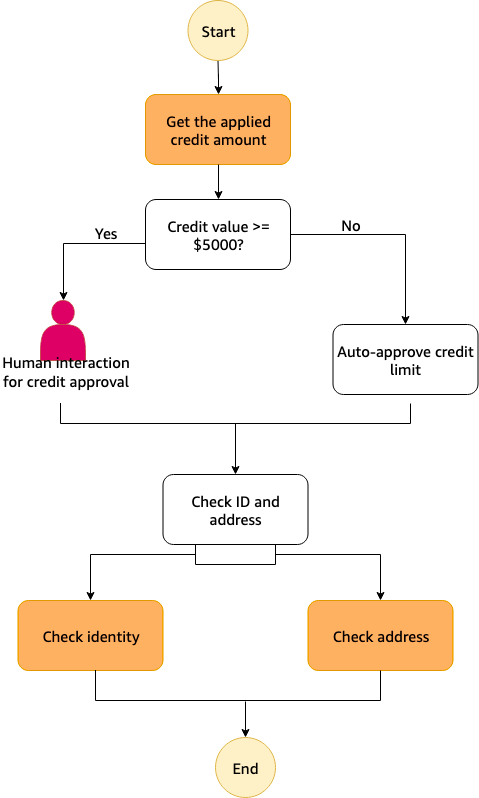
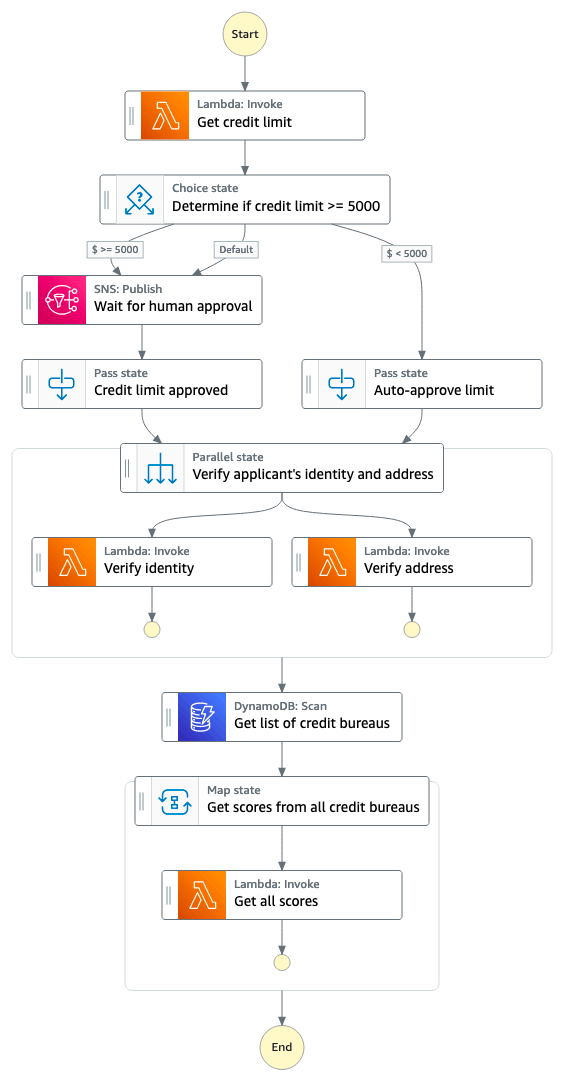
こちらのチュートリアルの方が、最初にやったチュートリアルより本格的。
というかStep Functionのガイド読みやすい気がする。
と思った矢先にチュートリアル1の手順が壊滅的にわからないw
分岐処理を配置した後6番から、どっちに何を作っていくかが伝わらない。
翻訳のせいかと思い、英語を見ても具体的な指定がないようです。
開始方法のページにしか完成系のイメージ画像ないので、これを見ていないと完成できる気がしない。
機械的に翻訳かけたからだろうか、ちょいちょいステートのことを〜〜州とか〜〜状態とか表現してくるのですが、ここでは都道府県と訳されている箇所もあり面食らいます。
翻訳が壊滅的だなと感じたら、英語ページをブラウザで翻訳した方が読みやすかったりします。
日本語ページ
でコンフィギュレーションタブ、用都道府県名、と入力します。Get credit limit。
英語ページ ブラウザ翻訳
「構成」タブの「状態名」に「 」と入力しますGet credit limit。
英語ページ 原文
In the Configuration tab, for State name, enter Get credit limit.
チュートリアル1からやれば良いかと思いきやチュートリアル1はある意味概要的な雰囲気でチュートリアル2以降で細かく実装を進めていくっぽい罠でした。
ステートマシンの保存をするためには追加したlambdaの呼び出しなど存在しているリソースを指定しないといけないが、チュートリアル1の段階では作っていないため、ステートマシンの作成ができません。
作成完了しないと当然保存されないので、せっかく作ったステートマシンが記録されません。
一応後からlambda作り始めても大丈夫ではあるのですが、いずれにせよチュートリアル1のページはなくてもよいですね。
チュートリアル2から順番に作っていけばステートマシンを保存出来ます。
テスト実行してみると、DynamoDB参照するところでエラーになりました。
チュートリアル1を無理やり終わらせた事による弊害なのかわかりませんが、適切な権限が与えられていない雰囲気だったので、ステートマシンのロールにDynamoDBのReadOnly権限(AmazonDynamoDBReadOnlyAccess)を付与して無事正常動作しました。
入力データ
{
"data": {
"firstname": "Jane",
"lastname": "Doe",
"identity": {
"email": "jdoe@example.com",
"ssn": "123-45-6789"
},
"address": {
"street": "123 Main St",
"city": "Columbus",
"state": "OH",
"zip": "43219"
}
}
}
実行結果
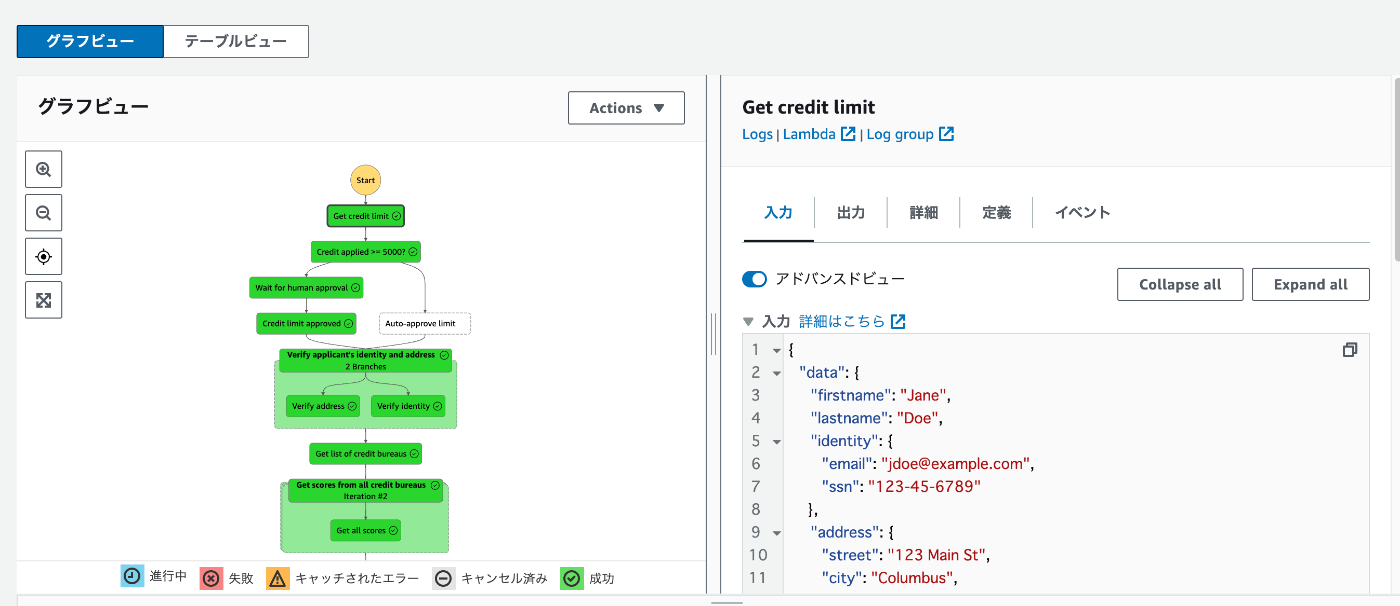
ASL
{
"Comment": "A description of my state machine",
"StartAt": "Get credit limit",
"States": {
"Get credit limit": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:123456789012:function:RandomNumberforCredit:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Next": "Credit applied >= 5000?"
},
"Credit applied >= 5000?": {
"Type": "Choice",
"Choices": [
{
"Variable": "$",
"NumericGreaterThanEquals": 5000,
"Next": "Wait for human approval"
},
{
"Variable": "$",
"NumericLessThan": 5000,
"Next": "Auto-approve limit"
}
]
},
"Wait for human approval": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish.waitForTaskToken",
"Parameters": {
"TopicArn": "arn:aws:sns:ap-northeast-1:123456789012:TaskTokenTopic",
"Message": {
"TaskToken.$": "$$.Task.Token"
}
},
"Next": "Credit limit approved"
},
"Credit limit approved": {
"Type": "Pass",
"Next": "Verify applicant's identity and address"
},
"Verify applicant's identity and address": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Verify address",
"States": {
"Verify address": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:123456789012:function:check-address:$LATEST",
"Payload": {
"street": "123 Any St",
"city": "Any Town",
"state": "AT",
"zip": "01000"
}
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"End": true
}
}
},
{
"StartAt": "Verify identity",
"States": {
"Verify identity": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:123456789012:function:check-identity:$LATEST",
"Payload": {
"email": "jdoe@example.com",
"ssn": "012-00-0000"
}
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"End": true
}
}
}
],
"Next": "Get list of credit bureaus"
},
"Get list of credit bureaus": {
"Type": "Task",
"Parameters": {
"TableName": "GetCreditBureau"
},
"Resource": "arn:aws:states:::aws-sdk:dynamodb:scan",
"Next": "Get scores from all credit bureaus"
},
"Get scores from all credit bureaus": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "Get all scores",
"States": {
"Get all scores": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:123456789012:function:get-credit-score:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"End": true
}
}
},
"End": true,
"ItemsPath": "$.Items"
},
"Auto-approve limit": {
"Type": "Pass",
"Next": "Verify applicant's identity and address"
}
}
}
入出力の各種フィルタ
必要に応じて入力パラメータや出力形式をフィルタして必要な部分のみにしたり出来る。
InputPath
入力ペイロード全体のどの部分をタスクの入力として使用するかを選択します。このフィールドを指定すると、Step Functions は最初にこのフィールドを適用します。
入力に指定するペイロード(json)のどの部分を用いるかを指定。
ルートを$としてドット区切りで階層を指定する。
このフィルタ使わなくてもルートから指定すれば当然該当の値を参照可能だが、階層が深い場合など、記述が簡潔に出来るので、そういう用途で使うと認識
パラメータ
タスクを呼び出す前に入力がどのように表示されるかを指定します。Parametersこのフィールドを使用すると、AWS のサービス関数などのインテグレーションへの入力として渡されるキーと値のペアのコレクションを作成できます。AWS Lambdaこれらの値は静的にすることも、状態入力またはワークフローコンテキストオブジェクトから動的に選択することもできます。
やれることは伝わったのだが、どこに記載するのかピンとこず。
Lambda InvokeだとAPIパラメータの部分に書くと良さそう。
以下、検証中(書き換えてもエラーなので、合っているかわからない。。。)
デザインで、ステートをクリックし、設定にある、APIパラメータの右にでている、Edit as JSONトグルをオンにするとlambda定義部分のjsonが表示されます。
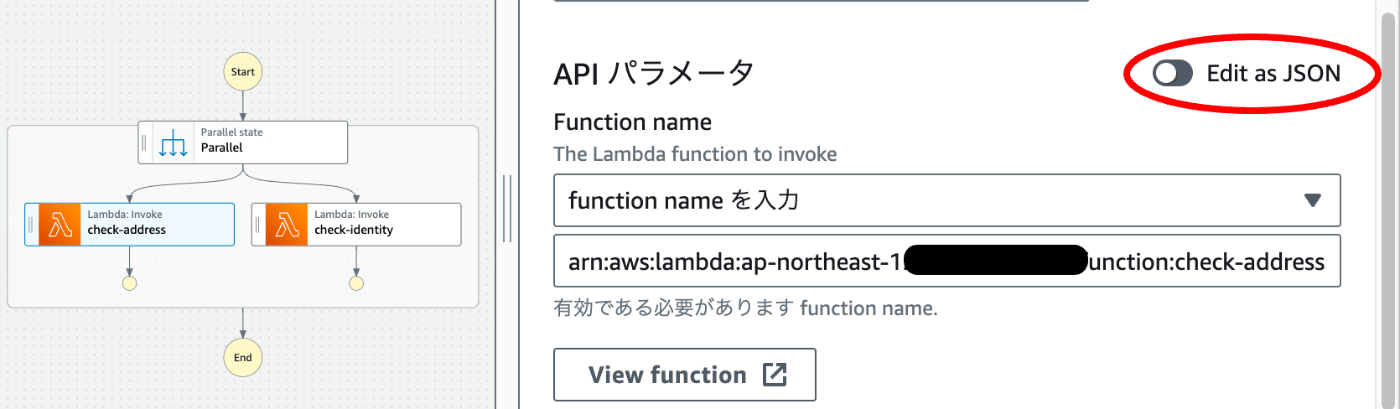
{
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:~~~:$LATEST"
}
このJSONがASL全体で言うところの、ステートのParametersに当たる部分なので、以下のように追加すると、
{
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:~~~:$LATEST",
"addressString.$": "States.Format('{}. {}, {} - {}', $.street, $.city, $.state, $.zip)"
}
Lambdaに本来渡される入力パラメータがaddressStringに置き換わるようなイメージ
チュートリアルに書いてあるものだけを設定してもlambdaはその引数を受け付けていないため、エラーになる。が$streetなどの値の変換はされてそう。
エラーログ
An error occurred while executing the state 'check-address' (entered at the event id #4). The Parameters '{"FunctionName":"arn:aws:lambda:ap-northeast-1:123456789012:function:HelloFunction:$LATEST","addressString":"123 Main St. Columbus, OH - 43219","Payload":{"street":"123 Main St","city":"Columbus","state":"OH","zip":"43219"}}' could not be used to start the Task: [The field "addressString" is not supported by Step Functions]
"addressString":"123 Main St. Columbus, OH - 43219",の部分をみると変数はちゃんと解釈されて入力したjsonデータの値を取得できている。
ResultSelector
タスクの出力から何を選択するかを決定します。ResultSelectorこのフィールドを使用すると、ステートの結果を置き換えるキーと値のペアのコレクションを作成して、そのコレクションをに渡すことができます。
ResultSelectorはマップ、パラレル、タスクの種類で使える
出力タブにあるResultSelector を使用して結果を変換にチェックを入れれば入力フォームが出るので、そこにjsonを書くことで設定可能
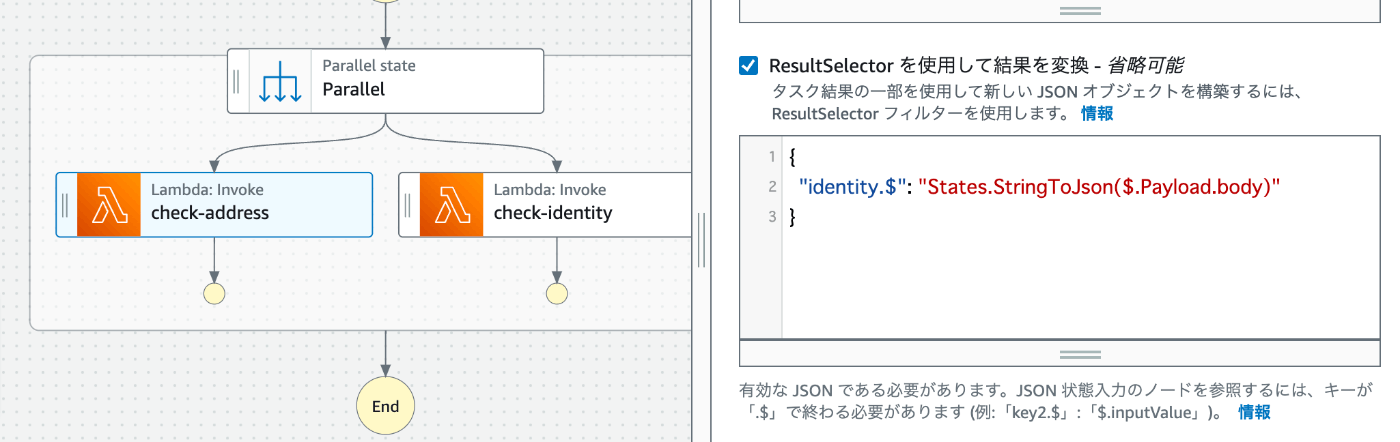
こちらはチュートリアル通りで正常動作できました。
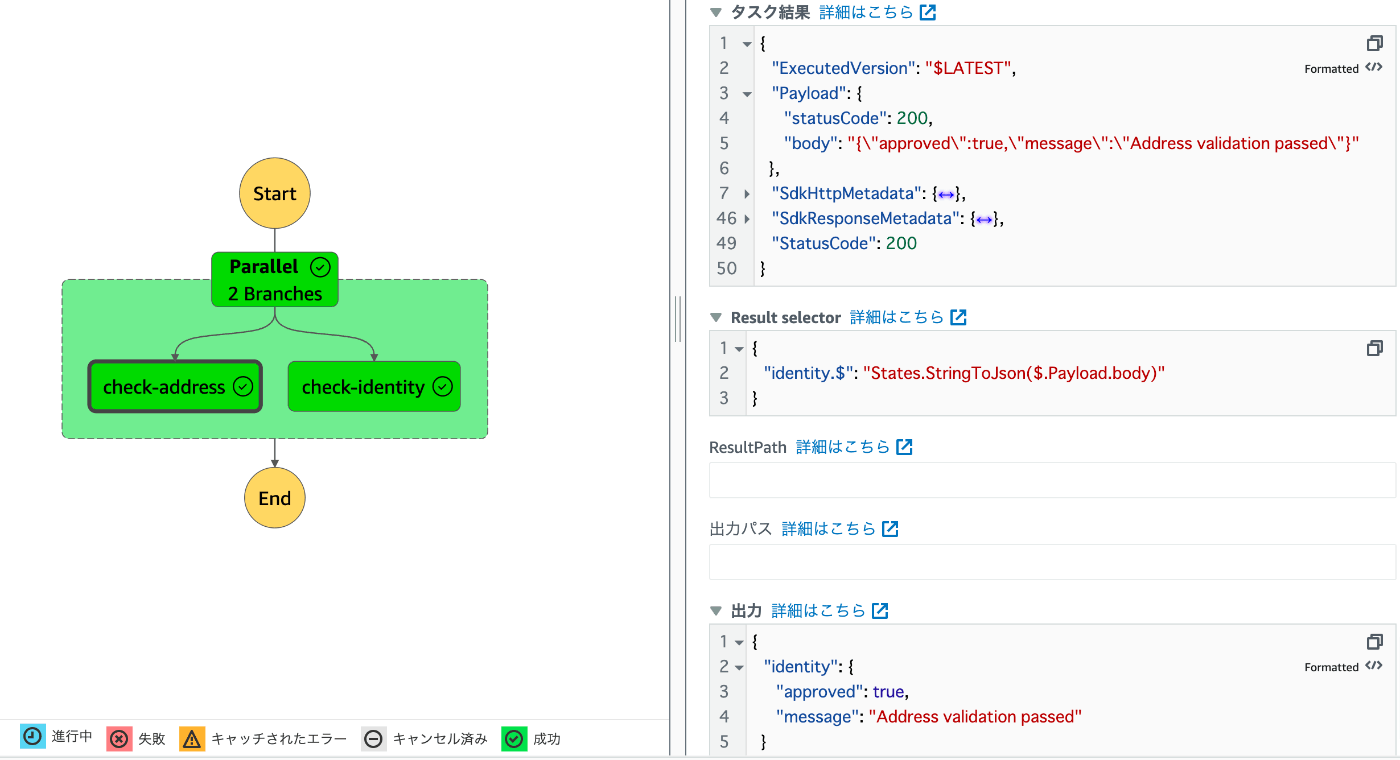
ResultPath
タスクの出力をどこに置くかを決定します。ResultPathを使用して、ステートの出力が入力のコピーなのか、生成される結果なのか、あるいはその両方の組み合わせなのかを判断できます。
入力で渡された値の全部または一部を出力してくれる。
出力タブにあるResultPath を使用して元の入力を出力に追加にチェックを入れれば有効にできます。
設定しても出力結果が変わらず。。検証中
→ $のみだと意味なし
$.に続けて任意の名前を指定することで、そのステートの出力結果に追加されます。
例えば$.resultとすると、そのステートの入力パラメータが"result"と言うキーの値として出力されます。
# 入力データ
{
"data": {
"name": "Jane",
"email": "jdoe@example.com"
},
"address": {
"city": "Columbus"
}
}
# 出力
{
"results": {
"data": {
"name": "Jane",
"email": "jdoe@example.com"
},
"address": {
"city": "Columbus"
}
}
}
となる。
パスのところでたまたま使われているが、要素が少ないので理解しやすい。
OutputPath
次のステートに何を送るかを決定します。を使用するとOutputPath、不要な情報をフィルターで除外し、JSON データのうち、気になる部分だけを渡すことができます。
InputPathの出力版
出力タブにあるOutputPath で出力をフィルタリングにチェックを入れれば有効にできます。
チュートリアルで指定する$.resultsとしてもエラーになり出力結果の確認ができず。
そもそもresultsって項目が元々ないんだが・・・ 検証中
入出力処理のイメージ
入出力のパラメータについて下記の画像が関係性をわかりやすく表現している。
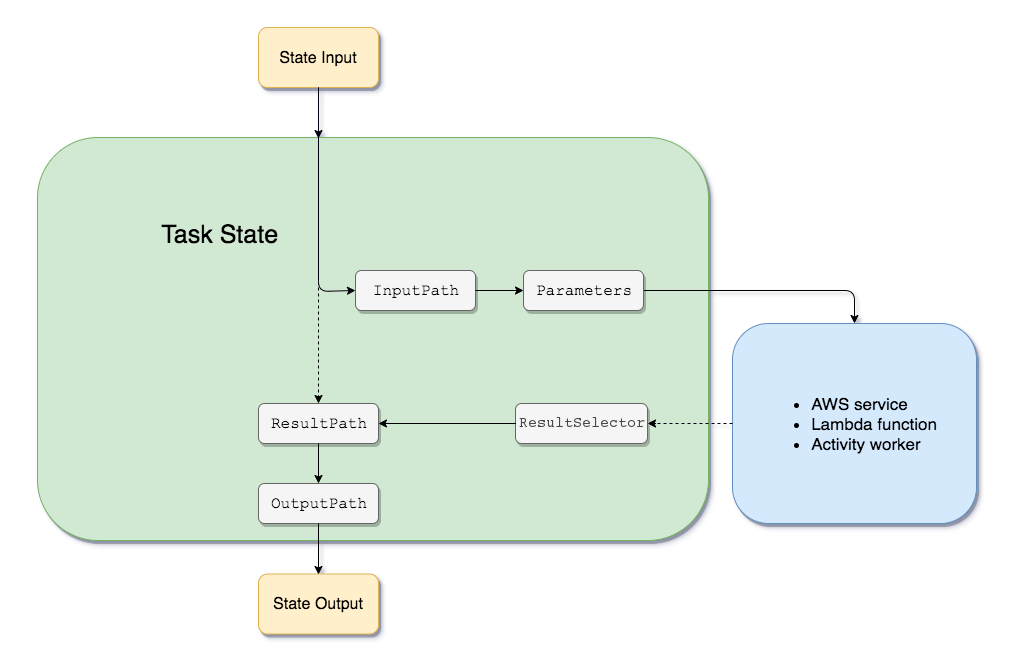
Step Functions 仕組み
標準ワークフロー対 Express ワークフロー
ワークフローは標準ワークフローとExpress ワークフローの2種類ある。
それぞれの特徴
標準ワークフロー
- 耐久性があり、監査可能なワークフローに最適です。
- Step Functions API を使用して、実行完了後最大 90 日間の実行履歴をすべて取得できます。
- ASL Retry で動作を指定しない限り、タスクとステートが複数回実行されないという 1 回限りのモデルに従います。
- Amazon EMR クラスターの起動や支払いの処理など、非段階的なアクションの調整に適しています。
- 処理された状態遷移の数に応じて課金されます。
Express ワークフロー
- IoT データの取り込み、ストリーミングデータ処理と変換、モバイルアプリケーションのバックエンドなど、大容量のイベント処理ワークロードに最適です。
- at-least-once1つの実行が複数回実行される可能性があるモデルを採用しています。
- 入力データの変換や Amazon DynamoDB の PUT アクションによる保存など、独立したアクションのオーケストレーションに最適です。
- 実行回数、実行時間、実行中に消費されたメモリによって請求されます。
ワークフローの特徴まとめ
| 項目名 | 標準ワークフロー | エクスプレスワークフロー:同期および非同期 |
|---|---|---|
| 最大期間 | 1 年 | 5 分 |
| サポートされている実行開始レート | リージョンによって制限値が異なる。※1 | ※1 |
| サポートされている状態遷移レート | リージョンによって制限値が異なる。※2 | 無制限 |
| 料金表 | 状態遷移の数によって価格設定。状態遷移は、実行のステップが完了するたびにカウント。 | 実行回数、実行時間、およびメモリ消費量によって価格設定。 |
| 実行履歴 | 実行内容は、ステップファンクション API で一覧表示および記述。コンソールで視覚的にデバッグ可能。CloudWatchログで確認も可。 | 実行履歴は無制限。CloudWatch Logs または Step Functions コンソールで実行内容を確認可。 |
| 実行セマンティクス ※3 | ワークフローを 1 回だけ実行。 | 非同期: t-least-onceワークフロー実行。同期: t-most-onceワークフロー実行。 |
| サービス統合 | すべてのサービス統合とパターンをサポート。 | すべてのサービス統合をサポート。Job-run (.sync) または Callback (.waitForTaskToken) サービス統合パターンは非サポート。 |
| Step Functions アクティビティ | サポートする。 | サポートしていない。 |
※1・・・API アクションのスロットリングに関連するクォータ
| API 名 | Standard - バケットサイズ | Standard - 補充レート/秒 | Express - バケットサイズ | Express - 補充レート/秒 |
|---|---|---|---|---|
| StartExecution — 米国東部 (バージニア北部)、米国西部 (オレゴン)、欧州 (アイルランド) | 1,300 | 300 | 6,000 | 6,000 |
| StartExecution — その他のすべてのリージョン | 800 | 150 | 6,000 | 6,000 |
※2・・・状態のスロットリングに関連するクォータ
| サービスメトリクス | Standard - バケットサイズ | Standard - 補充レート/秒 | Express - バケットサイズ | Express - 補充レート/秒 |
|---|---|---|---|---|
| StateTransition — 米国東部 (バージニア北部)、米国西部 (オレゴン)、欧州 (アイルランド) | 5,000 | 5,000 | 無制限 | 無制限 |
| StateTransition — その他のすべてのリージョン | 800 | 800 | 無制限 | 無制限 |
※3・・・実行セマンティクス
-
主な違いは標準は実行中の状態を保持し、実行履歴も比較的残る。
-
エクスプレスは標準より速さに優位性があるが、その分、実行中の状態保持せず、実行履歴も残らない。
-
実行履歴はStep Functionsでは残らないが、Cloud Watch Logsで有効化することでログは残せる。
-
非能性ってなんだ?と思ったらIdempotencyで、冪等性のことでした。
英語ページを翻訳すると冪等性と出ているので、翻訳はやはりGoogleの方が優秀。 -
同じ名前で複数のワークフローを開始の違いについてはよくわからない。
おそらく同一のStep Functionsを実行中にさらに実行した際の制御だと思われる。
標準・・・すでに動いてるならエラーにするよ。
非同期エクスプレス・・・すでに動いていても、呼ばれたらとりあえず動かすよ。どうなるかは知らんよ。
同期エクスプレス・・・すでに動いてたら、一旦待つよ。その後はどうするか不明。実行中のワークフローが終わった後に待機させた実行を再開させるのか、実行中のワークフローが終わった結果を待機させていたフローの結果としても返す?みたいなことなのか。(未検証)
料金
無料枠:月4,000 回の状態遷移
※ここで言う状態遷移はワークフロー内の1つのステップの実行を指す。
ワークフロー内にlambda(A)の実行、次に分岐が1つ、分岐のそれぞれにlambda実行(B, C)がある全部で4ステップがあるワークフローの場合、1回のワークフロー実行によってlambda(A)、分岐、BかCどちらかのLambda実行の計3つの状態遷移を消費したことになる。
ワークフロー設定の不備などで途中でエラーがあった場合は、おそらく途中のステップまでの実施分までの消費になるはず。
- 状態遷移のカウントには開始(Start)と終了(End)も含まれる。
- エラーによるリトライやMapやParallelによる繰り返し実行も1つ1つを状態遷移としてカウント
0.000025USD/以後の状態遷移ごと
0.025USD/1,000 回の状態遷移
意外と高い?単純なフローであれば、Lambda1本でも出来ないかなど検討する余地はある。
上記は標準ワークフローの場合、
Express ワークフローの場合は、リクエスト数(ワークフローの実行回数)とワークフローで使用したメモリと時間によって料金が発生する。
ワークフローの呼び出し
-
標準ワークフロー内でエクスプレスワークフローを呼び出すことも可能
-
エクスプレスワークフロー内で標準ワークフローを呼び出すことも可能
この場合標準ワークフローにはエクスプレスでの制限に近い制御が加わる。- ワークフローは 5 分以内に実行を完了する必要があります。
- ワークフローはat-least-once実行モデルになります。つまり、ワークフローの各ステップは 1 回以上実行される可能性があるということです。
- .waitForTaskTokenまたは.syncサービス統合パターンは使用できません。
ステート(状態)
ワークフローにおける1つの作業単位。ステップとも言う。
ステートの種類
- タスク(Task):ステートマシンで何らかの作業を実行します。Lambda実行など各種サービスの呼び出し。いわゆるサービス統合の定義箇所
- 選択(Choice):実行のブランチ間で選択を行う。いわゆる
If文 - 並列(Parallel):実行の並列分岐を開始します。同じ入力で複数の異なる処理を並列で実行可能
- マップ(Map):ステップを動的に反復する。いわゆる
for文。マルチスレッド的な実行も可能 - パス(Pass):入力を出力に渡すか、固定データをワークフローに挿入します。何もしない素通り
- 待機(Wait):一定時間、または指定された日時まで遅延を提供します。
- 成功(Succeed):成功で実行を停止する。
- 失敗(Fail):失敗で実行を停止する。
Amazon ステートメント言語
ステートはAmazon ステートメント言語(ASL)というJSONベースの定義言語を用いて記述します。
同様にワークフローもASLで記述し、1つのワークフローの情報とそのワークフローに含まれるステートすべてを1つのASLとして定義します。
IaCなどコード化する際は拡張子.asl.jsonとしてjsonファイルとして保存します。
ワークフローのASLの例
{
"Comment": "A Hello World example of the Amazon States Language using a Pass state",
"StartAt": "HelloWorld",
"States": {
"HelloWorld": {
"Type": "Pass",
"Result": "Hello World!",
"End": true
}
}
}
Comment:人間が読める状態マシンの説明。
StartAt(必須):開始するステートの指定。ステートの名前を設定する。
TimeoutSeconds:ステート マシンの実行が実行できる最大秒数。指定した時間を超えて実行すると、実行は失敗し、 States.Timeout エラー名 が表示されます。
Version:ステートマシンで使用される Amazon States Language のバージョン (デフォルトは「1.0」)。
States(必須):カンマで区切られた一連の状態を含むオブジェクト。Statesの中に複数のステートが含まれる。
ステートの共通項
HelloWorldというLambdaを実行するステートの例
"HelloWorld": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:HelloFunction",
"Next": "AfterHelloWorldState",
"Comment": "Run the HelloWorld Lambda function"
}
HelloWorld(必須)
ステートの名前。任意の名前を指定可能。スペースや記号、日本語なども扱える。
Type(必須)
上記のステートの種類を指定
Comment
ステートの説明文
Next(必須)
次に動作するステートを指定。Nextにどのステップを実行するかを指定していることで全体としてワークフローが作られています。
Next または End のどちらか 1 つのみを使用できます。
End(必須)
設定されたステートがワークフローの終了状態として扱われます。
ステートマシンごとに、任意の数の終了状態が存在します。※
Next または End のどちらか 1 つのみを使用できます。
選択・成功・失敗などの一部のステートは、Endフィールドをサポートまたは使用しません。
選択は分岐先のステートがEndになるため、選択自体にEndが付くことはありません。
※選択を用いることでワークフロー内の複数箇所でワークフローを終了させる事が出来ます。そのため、Endの指定はワークフローで1つとは限らないということです。
InputPath (オプション)
状態の入力の一部を選択して状態の処理タスクに渡すパス。省略した場合、入力全体を指定する値 $ が設定されます。詳細については、入力および出力処理を参照してください。
OutputPath (オプション)
ステートの出力の一部を選択して次のステートに渡すパス。省略すると、$出力全体を指定する値になります。詳細については、入力および出力処理を参照してください。
ステートの種類毎詳細
タスク(Task)
タスクには大きく3種類
- Lambdaの実行
- AWSサービスの実行
- アクティビティの実行
アクティビティは、EC2やECS、モバイル端末で動作するワーカーを実行するステート
ワーカー側でStepFunctionsをポーリングし、アクティビティのステートに達したらワーカの処理結果を待機します。
ワーカー側の処理で成功か失敗を返すことで、次のステートに進みます。
ステートはTimeoutSecondsで指定した時間待ちます。ワーカーはこの時間内に終了できない場合は、SendTaskHeartbeatAPIを使用することで最大1年間実行を待機させる事ができます。
選択(Choice)
いわゆるIf文
条件式はプログラムで扱う一般的な条件は扱えそう。
値としては扱えるのは
- 数値(Number)
- 文字列(String)
- 日時(Timestamp)
- 論理型(Boolean)
- null(Null)
選択ルール(条件式)
- 値の一致
- 値の比較(〇〇より小さい、〇〇以下、〇〇以上、〇〇より大きい)
- 値の型確認(数値か、文字列か、日時か、論理型か、nullか)
- 値が存在するか
- 値が特定のパターンにマッチするか(ワイルドカードを用いたり。"log-*.txt"など)
- それぞれの条件を否定するNOTも使用可能
- 上記の条件をANDやORで繋げた複合条件も可能
※値の一致や比較は、特定の固定の値との比較だけでなく別な入力値を指定することも可能。
エラーパターン
# 型違い
An error occurred while executing the state 'Choice' (entered at the event id #4). Invalid path '$.firstname': The choice state's condition path references an invalid value.
# 存在しない入力パラメータ
An error occurred while executing the state 'Choice' (entered at the event id #4). Invalid path '$.a': The choice state's condition path references an invalid value.
# defaultがない
An error occurred while executing the state 'Choice' (entered at the event id #4). Failed to transition out of the state. The state does not point to a next state.
※間違ってdefault消してしまうとデザイン上はエラー出ない(defaultはオプションのため文法上は合っている)default忘れずに。一応elseの選択ルールを追加することでも回避可能。
並列(Parallel):実行の並列分岐を開始します。同じ入力で複数の異なる処理を並列で実行可能
- Branches(必須):並列に動かすステートを指定する。
- Retry:Retrier と呼ばれるオブジェクトの配列。ステートでエラーが発生した場合のリトライ方法を定義します。
- リトライ回数(MaxAttempts)
- リトライするまでの間隔(IntervalSeconds)
- バックオフ率(BackoffRate)、最大待ち時間などを指定可能
※バックオフはリトライする度にリトライまでの間隔を増やすこと。 - 最大待ち時間(MaxDelaySeconds)
- Catch:Catcher と呼ばれるオブジェクトの配列。ステートでエラーが発生し、リトライをしても解消されない場合やリトライが定義されていない場合に実行されるフォールバック状態を定義します。

キャッチャーを追加してErrorsにどのエラーをキャッチするかを決め、エラーが発生した後、次にどのステートを動かすかを指定する。のが基本的な設定方法
Errorsはいくつか選ぶことが可能。
- States.All
- States.Timeout
- States.TaskFailed
など。
Allは全部拾いそうなイメージだが、他と組み合わせられるかは未確認
フォールバック状態については改めて整理しようと思う。あと、フォールバック状態は言葉的に収まりがよいが、タスクや選択などと同様フォールバックというステートだと思われる。
リトライの詳細 フォールバック状態の詳細
マップ(Map):ステップを動的に反復する。
マルチスレッド的な実行
基本的にはJSON配列を受け取り、配列要素を同時実行するもの。
2つの処理モードをもつ
- インラインモード
- 制限付き同時実行モード
- デフォルトはこちら
- 最大40個の同時実行
- 分散モード
- 高同時実行モード
- インラインとの違いはMap内のステートが子ワークフローとして扱われる。これにより高い同時実行数を実現
- 子ワークフローとなるため、親ワークフローと別に実行履歴が別れる(要検証)
- 最大10,000個の同時実行
- JSON配列だけでなく、S3データソースを受け取れる
同時実行数を指定できるので、1にすればいわゆるfor文的な動かし方も可能そう。
以下のような制限値を超えてくる場合は分散モードを選択する。
- データセットのサイズが 256 KB を超えています。
- ワークフローの実行イベント履歴は 25,000 エントリを超えています。
- 40 回を超える並列反復の同時実行が必要です。
パラメータ
- ItemProcessor:
処理モードなどが定義される箇所。元はIteratorだったようで、Step Functions LocalではItemProcessorがまだ対応されていないとの記載あり。(未確認) - ItemSelector:
元はParametersだったよう。 - MaxConcurrency:同時実行数。0が最大実行数まで実行させる意味。
- Retry:Parallelと同様
- リトライ発生時は失敗したものだけでなく成功したものもリトライされる点に注意。
- Catch:Parallelと同様
パス(Pass):入力を出力に渡すか、固定データをワークフローに挿入します。
何もしない素通り。入力で受け取った値を出力に渡す。
使い道としてはいくつかありそうです。
- Choiceを用いた分岐において、片方のみ処理を行い、他方は何もしなくてよい場合において、処理の中で出力結果を変える場合には、何もしなくてよい場合にパスを用いて出力形式を合わせる
- 入出力の変換を明示的に行いたい場合
- ステートは任意の名前をつけられるため、次のステートに渡す値を変換したい場合に専用の名前をつけてあげることで、視認性を高めることができそうです。
- テスト用に特定の値を埋め込み後続の動作確認を行う。
待機(Wait):一定時間、または指定された日時まで遅延を提供します。
2通り
- 任意の時間を待つ。10秒待つ、1時間まつ、など
- 指定された日時まで待つ。10月1日の0時まで待つ、など
それぞれ固定の値を指定出来るが、入力パラメータによる動的な値の指定も可能
成功(Succeed):成功で実行を停止する。
できるのはコメント指定くらい。
使い道としては、どでかいワークフローを作った際に途中で正常終了として終えたいが、Endの指定をするとデザインで見たときに線がゴチャゴチャしすぎて見づらい場合にわかりやすくなる。かな。
失敗(Fail):失敗で実行を停止する。
成功と違い多少制御可能
エラーに名前づけすることで、どんなエラーかを意味付けすることができます。
エラーの内容や一緒に確認したいパラメータをエラー出力として含めることも可能。
Error:固定文字列の見出し
Cause:固定文字列の詳細
ErrorPath:入力パラメータを用いた見出し
CausePath:入力パラメータを用いた詳細
ErrorとErrorPathはどちらか一方のみ指定可能
CauseとCausePathもどちらか一方のみ指定可能
パス
ASL(Amazon States Language)はJson形式のテキストで構成されています。
Json内の値を参照する際にルートを$として階層はドット.で繋ぎます。
参照パス
Json構造内の単一ノードを識別するパスを参照パスと言います。
- ドット(
.)および角括弧([ ])表記のみを使用してオブジェクト フィールドにアクセスできます[。 - length()などの機能はサポートされていません。
- subsetofなどの非記号的な字句演算子はサポートされていません。
- 正規表現によるフィルタリングや、JSON 構造内の別の値の参照によるフィルタリングはサポートされていません。
- @フィルターで処理されている現在のノードと一致する演算子は、スカラー値と一致しません。オブジェクトのみに一致します。
参照パスの使用例
{
"foo": 123,
"bar": ["a", "b", "c"],
"car": {
"cdr": true
},
"jar": [{"a": 1}, {"a": 5}, {"a": 2}, {"a": 7}, {"a": 3}]
}
次の参照パスは以下を返します。
$.foo => 123
$.bar => ["a", "b", "c"]
$.car.cdr => true
$.jar[?(@.a >= 5)] => [{"a": 5}, {"a": 7}]
配列の配列をフラット化
ParalelやMapステートで配列の配列を返すような場合、ResltSelectorフィールドを使うことで配列をフラット配列に変換できます。
ResltSelectorを用いた例
"ResultSelector": {
"flattenArray.$": "$[*][*]"
}
上記の構文は、JMESPath 構文を使用しています。
JMESPath 構文の例
search([*].foo, [{"foo": 1}, {"foo": 2}, {"foo": 3}]) -> [1, 2, 3]
search([*].foo, [{"foo": 1}, {"foo": 2}, {"bar": 3}]) -> [1, 2]
search('*.foo', {"a": {"foo": 1}, "b": {"foo": 2}, "c": {"bar": 1}}) -> [1, 2]
入出力処理
InputPath
入力ペイロード一部を取得します。
使用例1
入力データ
{
"comment": "Example for InputPath.",
"dataset1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
}
}
InputPathの指定
"InputPath": "$.dataset2",
結果
{
"val1": "a",
"val2": "b",
"val3": "c"
}
使用例2
入力データ
{ "a": [1, 2, 3, 4] }
InputPathの指定
"InputPath": "$.a[0:2]",
結果
[ 1, 2 ]
入出力処理
Parameters
パラメータはキーと値のセットで新しい入力データを作り変えるイメージ
パラメータを定義することで元の入力データを置き換えてしまうため、元の入力データを使用する場合はパラメータで元の入力データを定義しておく必要があります。
元の入力データを使用する場合はキー名の最後は.$で終わる必要があります。
使用例1
入力データ
{
"comment": "Example for Parameters.",
"product": {
"details": {
"color": "blue",
"size": "small",
"material": "cotton"
},
"availability": "in stock",
"sku": "2317",
"cost": "$23"
}
}
Parametersの指定
"Parameters": {
"comment": "Selecting what I care about.",
"MyDetails": {
"size.$": "$.product.details.size",
"exists.$": "$.product.availability",
"StaticValue": "foo"
}
},
-
commentは入力データにあった物を使用せず固定の値を使用しているので.$は不要 -
Parametersの下に任意の構造を定義することも可能MyDetailsという層の下にsizeなどのキーと値を定義している
結果
{
"comment": "Selecting what I care about.",
"MyDetails": {
"size": "small",
"exists": "in stock",
"StaticValue": "foo"
}
},
使用例2
入力データをそのまま用いたい場合はルートを指定すれば全て取得は可能。
Parametersの仕様上キーが必要。
Parametersの指定
"Parameters": {
"data.$": "$"
},
結果
{
"data": {
"comment": "Example for Parameters.",
"product": {
"details": {
"color": "blue",
"size": "small",
"material": "cotton"
},
"availability": "in stock",
"sku": "2317",
"cost": "$23"
}
}
}
入出力処理
ResultSelector
入力データを結果に含めるResultPathフィールドに渡すための入力データの部分を指定できます。
使用できるのは、Task、Map、Parallesです。
使用例1
元の結果
{
"resourceType": "elasticmapreduce",
"resource": "createCluster.sync",
"output": {
"SdkHttpMetadata": {
"HttpHeaders": {
"Content-Length": "1112",
"Content-Type": "application/x-amz-JSON-1.1",
"Date": "Mon, 25 Nov 2019 19:41:29 GMT",
"x-amzn-RequestId": "1234-5678-9012"
},
"HttpStatusCode": 200
},
"SdkResponseMetadata": {
"RequestId": "1234-5678-9012"
},
"ClusterId": "AKIAIOSFODNN7EXAMPLE"
}
}
ResultSelectorの指定
"ResultSelector": {
"ClusterId.$": "$.output.ClusterId",
"ResourceType.$": "$.resourceType"
},
"ResultPath": "$.EMROutput",
}
ResultSelectorと入力データのClusterIdとresourceTypeを選択しています。
また、ResultPathとしてEMROutputを指定しています。
結果
{
"OtherDataFromInput": {},
"EMROutput": {
"ResourceType": "elasticmapreduce",
"ClusterId": "AKIAIOSFODNN7EXAMPLE"
}
}
ResultPathの指定の通り、EMROutputをキーにResultSelectorで選択した情報が含まれます。
入出力処理
Mapの入力フィールドと出力フィールド
Mapはデータセット内の項目のコレクションを同時に反復処理します。
データセットの例
- JSON 配列
- Amazon S3 オブジェクトのリスト
- Amazon S3 バケット内の CSV ファイルの行
など
ステートの入出力フィールドのように、Mapにはコレクションに対して下記のような入出力フィールドが存在します。
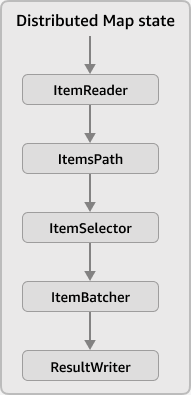
- ItemReader
- ItemsPath
- ItemSelector
- ItemBatcher
- ResultWriter