【KotlinFest 2025にて発表】内部実装から理解するKotlin Coroutines
本記事では、2025年11月1日に開催される Kotlin Fest 2025 にて発表予定の
「内部実装から理解する Coroutines ― Continuation・Structured Concurrency・Dispatcher」のスライドおよび発表原稿を事前公開します。
同時刻には他にも魅力的なセッションが2つ予定されているため、本記事が「どのセッションを聴講するか」の判断材料としてお役に立てば幸いです。
また、聴講者の方々が、発表中にメモを取らずとも内容を振り返られるようにする意図もあります。
発表当日までにスライド・原稿をブラッシュアップしていく予定ですが、大筋を変えることはありません。
導入
表紙

この発表では、Kotlin Coroutinesの中心的なコンセプトである、Continuation、Structured Concurrency、そしてDispatcherの3つを、内部実装から解読していきます。
はじめに

はじめに、今から話す内容のスライドと原稿は、既に公開されています。
ですので、聞きながらメモを取っていただく必要はありません。
こちらのQRからスライドを見れますので、必要あらばお手元でもご確認ください。少し時間を取ります。
本発表のゴール

本発表のゴールは、2つあります。
1つ目は、Kotlin Coroutines の中心的なコンセプトを、仕組みから理解していただくことです。
これによって、皆さんがより安全に、より効率的にコルーチンを活用できるようになることを目指しています。
2つ目のゴールは、コルーチンのソースコードを気軽に読めるようになっていただくことです。
何か不明点があったときに、ドキュメントを見に行くのと同じくらいの軽い気持ちで、ソースコードを見に行ってもらえるようになってもらえたら嬉しいです。
Kotlin Coroutinesの中心的なコンセプト

この発表では、Kotlin Coroutines の中心的なコンセプトとして、次の3つを取り上げます。
1つ目は Continuation です。
Continuationを深掘ることで、suspend関数がどのように一時停止、再開しているのかを理解できます。
Continuationは、後の2つのトピックを理解するうえでも前提となる、重要な概念です。
2つ目は Dispatcher です。
Dispatchersの内部実装から、コルーチンがどのように非同期処理・並行実行を実行するのかを理解できます。
3つ目は Structured Concurrency です。
Structured Concurrency とはそもそも何か、そして Kotlin ではどのように実現されているのかを見ていきます。

では、1つ目の、Continuationの説明に入ります。
第1章:Continuation
suspend関数の仕様

まずは、suspend 関数の表面的な仕様を、こちらのサンプルコードを例におさらいしましょう。
この関数は、"Hello" と出力し、1秒後に "World" と出力する suspend 関数 です。
ポイントは、delay を呼び出した直後に、関数が一度中断して、1秒後に再開して処理が続くという点です。
では、この「中断」と「再開」が、どのような仕組みで実現されているのかを、内部実装から追っていきましょう。
Kotlin Coroutinesの内部実装の追い方

早速 suspend 関数の内部実装に入りたいところですが、
そもそも Kotlin Coroutines の内部実装をどのように追えばよいのか、最初に整理しておきましょう。
この発表では、主に3つの方法を使います。
まず1つ目は、Kotlin リポジトリのソースコードを読む方法です。
たとえば、これから説明する Continuation のような、言語レベルのコア機能を理解したいときに用います。
2つ目は、拡張ライブラリである kotlinx.coroutines のソースコードを読むことです。
Kotlin Coroutines では、言語に組み込まれている機能はごく一部で、
多くの機能、たとえば Coroutine Builder や Coroutine Scope、Dispatcher などは、この拡張ライブラリに実装されています。
そして3つ目は、コンパイル後のバイトコードをデコンパイルしたコードを読む、という方法です。
たとえば、これから深掘りする suspend 関数 は、コンパイル時に Continuation を使った形に変換されるため、このアプローチが必要となります。

今回はまず、3.のアプローチで、suspend関数がコンパイルされた後のコードを確認します。
すると Continuation という仕組みが登場するので、1.のアプローチで、Kotlinリポジトリに含まれるContinuationのソースコードを追っていきます。
suspend関数のバイトコードを表示

では、suspend関数の内部実装の深掘りに入ります。
suspend関数のコンパイル後のバイトコードを得るには、IntelliJ IDEAの「Show Kotlin Bytecode」という機能を使います。
suspend関数のバイトコードをデコンパイル

次に、IntelliJ IDEA上で「Decompile」を行うと、コンパイル後のバイトコードから Java コードを復元することができます。

この復元された Java コードを読んでいきます。
ここでは、3つのセクションに分けて見ていきます。
1つ目は 関数定義、2つ目は Continuation を初期化する部分、そして3つ目は suspend 関数を実際に実行する部分 です。
セクション① 関数定義

1つ目の関数定義から見ていきましょう。
ここでは、コンパイル前の suspend 関数と、コンパイルおよびデコンパイルを経た後の Java コードの関数定義を並べて比較します。
すると、コンパイル後には HelloWorldKt というクラスが生成されており、元の suspend 関数はこのクラスの static 関数 として定義されていることが分かります。
さらに、この関数の引数を見ると、新たに Continuation 型の completion という引数が追加されていることも分かります。
Continuationとは何か?

ここで登場した Continuation とは何かを説明します。
Continuation とは、一言で言うと「中断されたsuspend関数を再開するためのハンドラ」です。
Continuation は、Kotlin リポジトリ内で インタフェース として定義されています。
ここで覚えておいてほしいポイントが 2 つあります。
まず1つ目に、各 suspend 関数は Continuation を持っている という点です。
そして2つ目に、Continuation の resumeWith メソッドを呼ぶと、対応する suspend 関数が再開する という点です。
Continuationの役割をサンプルコードで解説

先ほどの覚えてほしい2つのポイントを、サンプルコードを例に解説します。
例として、以前も登場した helloWorld 関数を、main から呼び出すコードを使います。
まず、「各 suspend 関数は Continuation を持つ」ため、suspend関数であるmain 関数も Continuation を持っています。

続いて main から helloWorld 関数が呼ばれます。
この時、main 関数の Continuation が、helloWorld 関数の引数として渡されます。
コンパイル後の関数定義に、なぜ Continuation が追加されていたのか、ここで理由が見えてきたかと思います。
また、この helloWorld 関数も suspend 関数なので、対応するContinuation を持ちます。
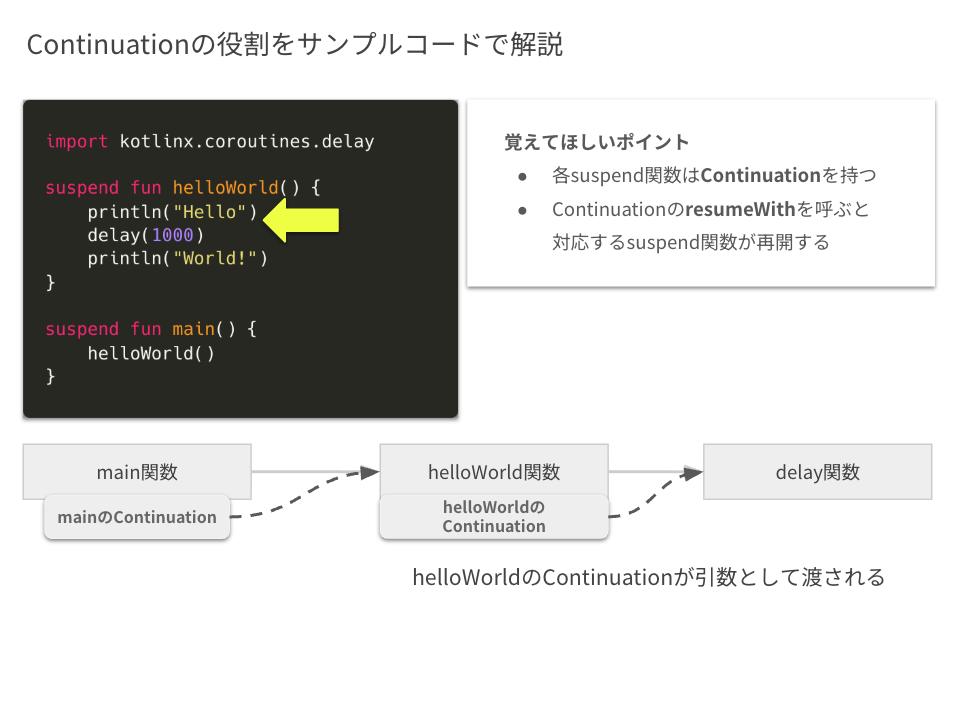
さらに helloWorld 関数は delay 関数を呼び出します。
この際には、今度は helloWorld 関数の Continuation が delay に渡されます。
この時点で、一度 helloWorld 関数の処理が中断します。
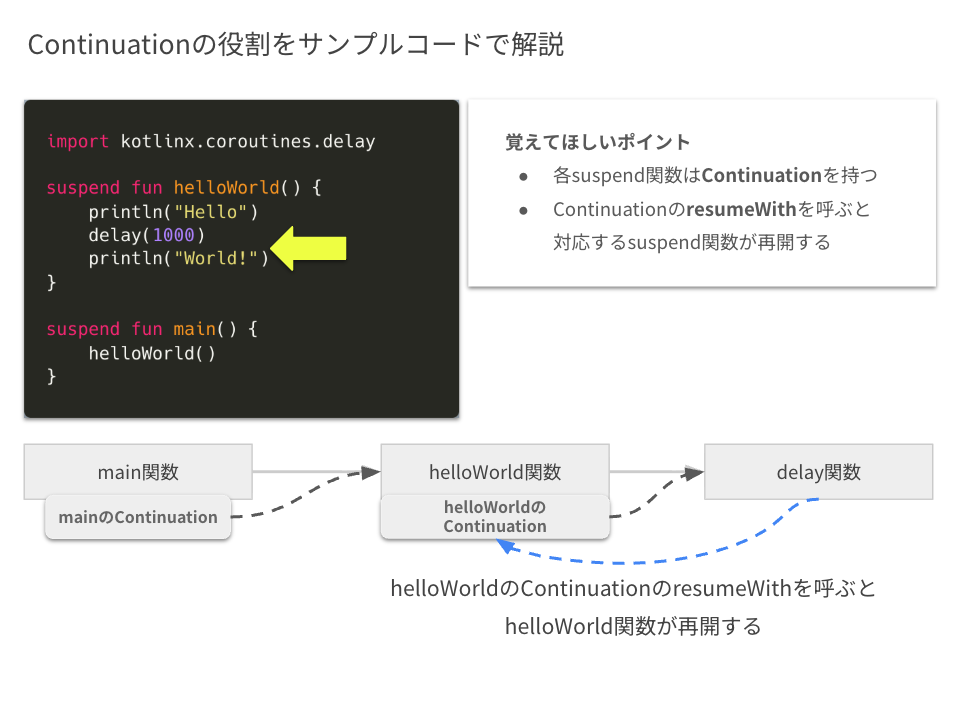
1秒後、delay 関数から helloWorld 関数の Continuation の resumeWith が呼ばれ、
これによって helloWorld 関数の処理が再開します。

最後に、helloWorld 関数から main 関数の Continuation の resumeWith が呼ばれ、
main 関数が再開します。
ここまでの説明で、各 suspend 関数が Continuation を持っていて、resumeWith によって対応するsuspend関数が再開する、ということのイメージが掴めてきたかと思います。
関数の引数に追加されたContinuationとは?

以上の説明を踏まえて関数定義に戻ると、ここで新たに追加されている Continuation 型の completion 引数は、呼び出し元の suspend 関数の Continuation である――と言えます。
と、言い切れれば話は単純なのですが、実際にはこれは 半分正解で、半分は不正解 です。
なぜ「半分不正解」なのかは、後で解説します。
セクション② suspend関数に紐づくContinuationの初期化

では、デコンパイルされた Java コードの2つ目のセクションを見ていきましょう。
このセクションでは、suspend 関数に紐づく Continuation の初期化 が行われています。
suspend関数の初回呼び出し時

suspend 関数の「初回呼び出し時」には、先ほど半分は正解と言った通り、呼び出し元の Continuation が渡されます。
初回呼び出し時には、下側の黄色の線で囲った部分に入り、ここでこの suspend 関数に紐づく Continuation の初期化 が行われます。
この Continuation の初期化部分を、より詳細に見ていきましょう。
Continuationの初期化

主に2つ、着目すべき点があります。
まず1つ目に、初期化される Continuation にはlabel というInt型の変数があります。
label は、この suspend 関数を「どこで再開すべき」か、言い換えると「suspend関数の処理がどこまで進んだのか」を保持する変数です。
2つ目に、invokeSuspend という関数があります。
invokeSuspend は suspend 関数が再開する際に呼ばれます。
中身を見ると、この suspend 関数自体、ここでは helloWorld 関数が呼ばれています。
つまり、再開時にも同じ suspend 関数が再度呼び出されることになります。
ここで注目したいのは、再開時には this、すなわちこの関数自体の Continuation が渡されているという点です。
つまり、初回実行時には呼び出し元の Continuation が渡されていたのに対し、再開時にはこの関数自体の Continuation が渡される、ということが分かります。
これが、呼び出し元のContinuationが渡されるというのは半分は不正解、と言った理由です。
invokeSuspendが再開時に呼ばれることの確認

ちなみに、「再開時に invokeSuspend が呼ばれる」ということも、ソースコードで確認できます。
前のスライドで示したとおり、各 suspend 関数は Continuation を持ち、その Continuation の resumeWith を呼ぶと、対応する suspend 関数が再開します。
ここで Continuation の resumeWith の実装を見てみると、詳細は省きますが、その中で先ほど登場した invokeSuspend が呼ばれていることが分かります。
まとめると、再開時には、その suspend 関数に紐づく Continuation の resumeWith が呼ばれ、その中で invokeSuspend が実行され、最終的に suspend 関数自体が再び呼ばれる という流れとなります。
suspend関数の再開時

suspend 関数のソースコードに戻りますと、再開時にはこの関数の Continuation が渡されます。
再開時には、上側の黄色の線で囲った部分に入り、そこで Continuation の持つ label が取得されます。
この label が次のセクションで重要になります。
セクション③ suspend関数の実行
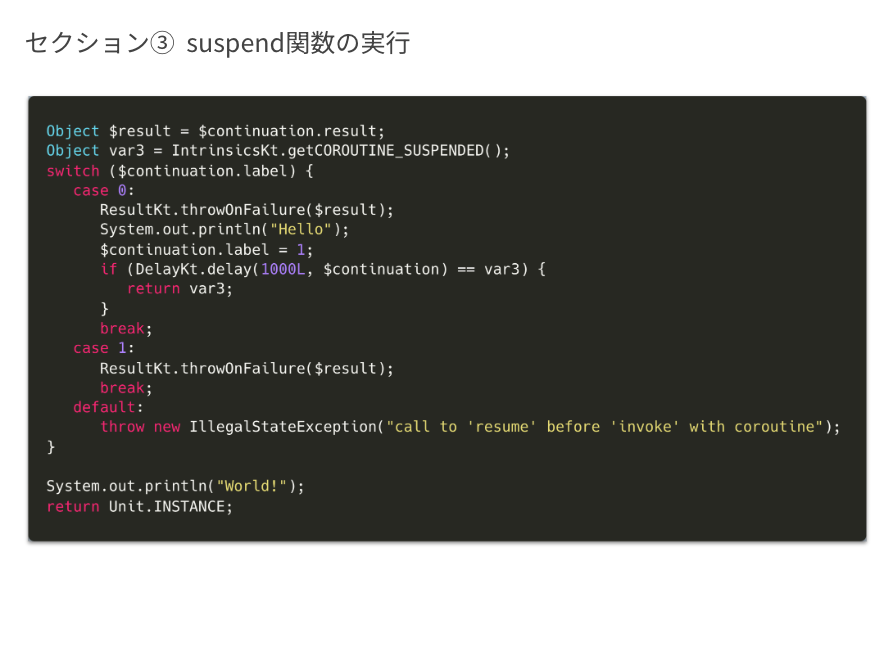
では、3つ目のセクションである suspend 関数を実行する部分 に移ります。
ここで重要なのは switch 文で、Continuation の label に応じて実行される処理を切り替えています。
セクション③ suspend関数の実行 - 初回実行時

まず、初回実行時には Continuation の label が 0 のため、case 0 の処理が実行されます。
これは元の関数でいう「Hello を出力し、delay を呼び出す」という部分に相当します。
また重要な点として、この時に label が 1 に更新されます。
セクション③ suspend関数の実行 - 再開時

次に、再開時には label が 1 に変わっているため、case 1 の処理が実行されます。
これは元の関数でいう「World を出力する」部分に相当します。
このように、Continuation の label という変数によって、
中断された suspend 関数を「どの位置から再開すべきか」が制御されています。
まとめ:Continuationによるsuspend関数の中断・再開の仕組み
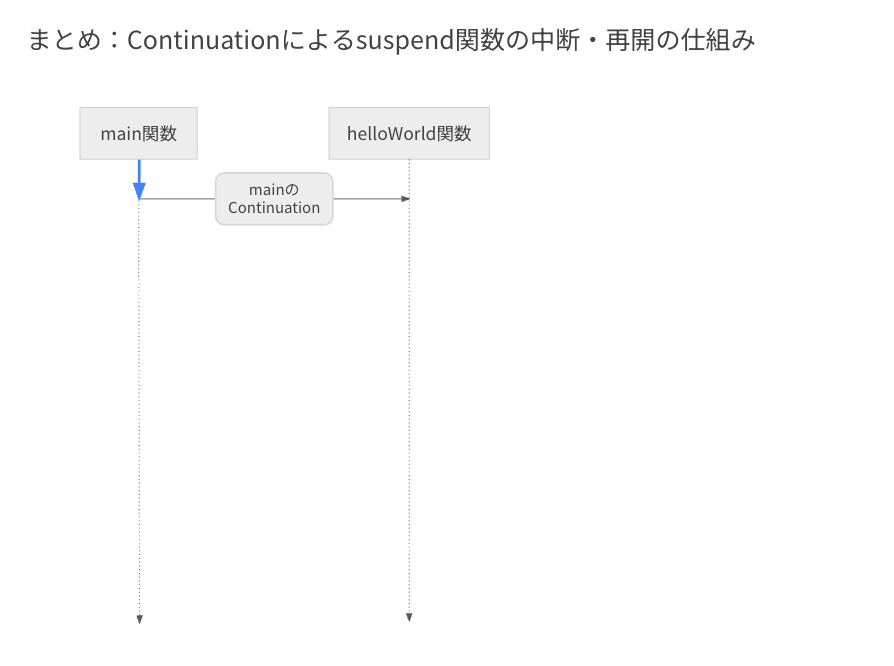
最後に、Continuation による suspend 関数の中断・再開の仕組みを振り返ります。
まず、suspend 関数(ここでは helloWorld 関数)が呼ばれると、呼び出し元の main のContinuation が引数として渡されます。
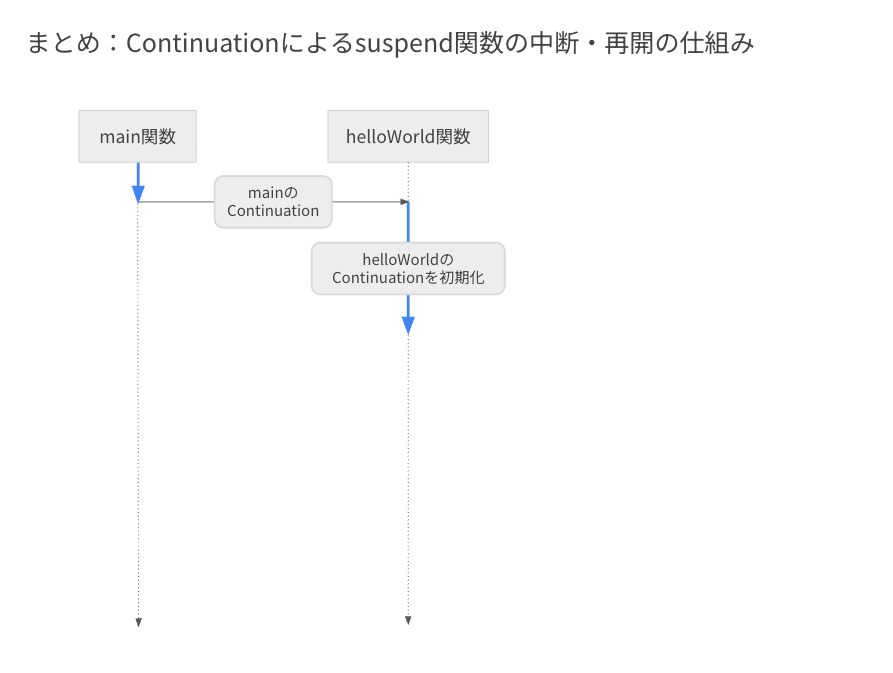
続いて、この suspend 関数に紐づく Continuation が初期化されます。
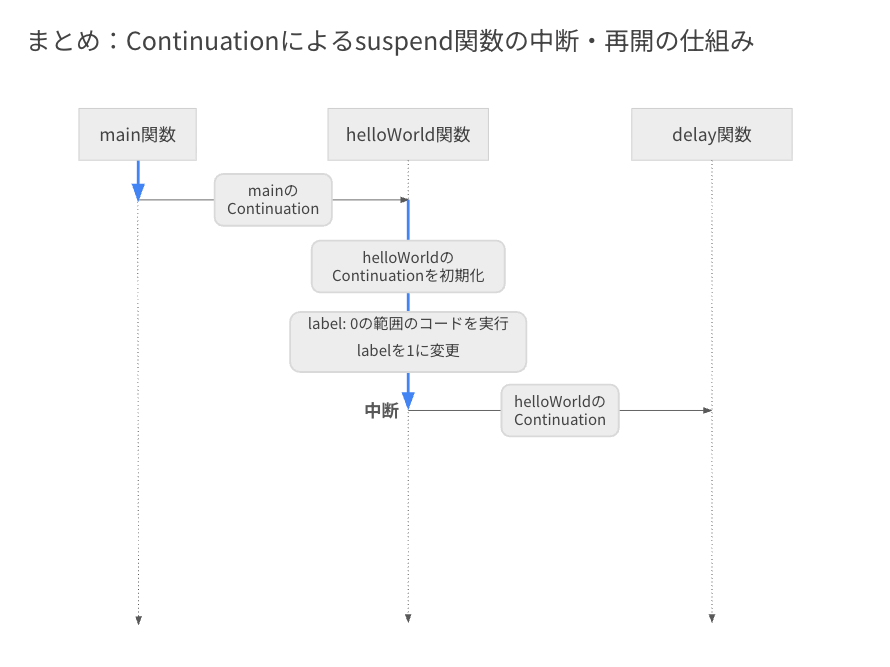
その後、label が 0 の範囲のコードが実行され、またlabel が 1 に変更されます。
そして、delay 関数が呼ばれ、この際には helloWorld の Continuation が引数として渡されます。
この時点で関数が中断します。
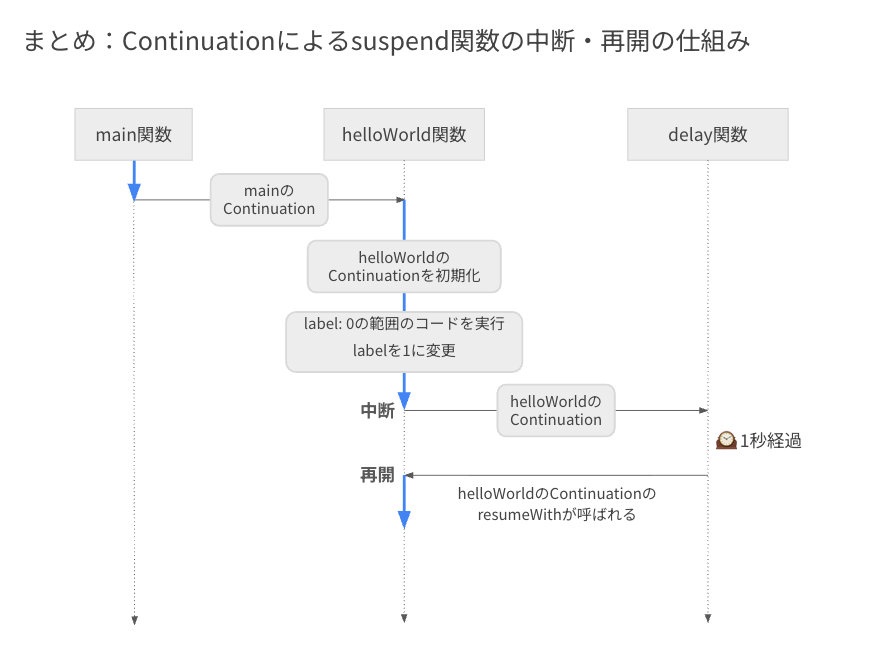
1秒後、delay 関数から helloWorld 関数の Continuation に対して resumeWith が呼ばれます。
これにより invokeSuspend 関数を介して helloWorld 関数が再び呼ばれ、このときは helloWorld 関数自身の Continuation が引数として渡されます。

今回は label が 1 に変わっているため、case 1 に対応する範囲のコードが実行され、helloWorld 関数の処理が完了します。
最終的には、main の Continuation の resumeWith が呼ばれ、呼び出し元の処理が再開されます。
ここまでの要点をまとめると、suspend 関数は Continuation を持ち、その Continuation に対して resumeWith が呼ばれることで再開します。
また、Continuation は label という変数を持ち、label の値によって実行時・再開時にどの範囲の処理を行うかが制御されています。
以上で、Continuation と suspend 関数の解説を終えます。
ただ、この後に続く Dispatcher や Structured Concurrency の理解にも深く関わるので、Continuation の仕組みは頭の片隅に留めておいてください。
第2章:Dispatcher

では、第2章に移ります。
先ほどは、suspend 関数がどのように一時停止・再開するのかという仕組みを明らかにしました。
しかし、コルーチンの主な目的である 非同期処理や並行処理がどのように実行されているのか は、まだ明らかにされていません。
ここからは、コルーチンがどのように実行されるのか、その仕組みを解き明かすために、
Dispatcher の内部実装 を見ていきます。
Dispatcherの表面的な仕様 (Dispatchers.Default)

まずは、こちらのサンプルコードを例に、Dispatcher の表面的な仕様をおさらいしましょう。
このコードでは、スレッド ID を出力する関数を、5つのコルーチンで並列に実行しています。
ここで使われている launch や、他にも async、runBlocking のように、コルーチンを起動するための関数は Coroutine Builder と呼ばれます。
Coroutine Builder は、デフォルトでは Dispatchers.Default という Dispatcher を使用し、バックグラウンドスレッド上でコルーチンを実行します。
右下の出力結果を見ると、最初は ID=1 のメインスレッドで実行されていますが、
launch で起動されたコルーチンは ID=12, 13 のバックグラウンドスレッドで実行されていることが分かります。
Dispatcherの表面的な仕様 (Dispatchers.IO)

Coroutine Builder(ここでは launch)に Dispatcher を明示的に渡すことで、
そのコルーチンが実行されるスレッド、あるいはスレッドプールを指定することができます。
ここでは、IO バウンドな処理を行うための Dispatchers.IO を指定しています。
Dispatchers.Defaultを使っていた場合には、ID=12,13 のスレッドのみが使われていましたが、今回は ID=12,13だけでなくID=14,15,17 のスレッドも使われていることが確認できます。
このように、コルーチンがバックグラウンドスレッドで非同期実行される仕組み、
そして Dispatchers.Default と Dispatchers.IO の違いがどのように生じているのかを、内部構造から明らかにしていきます。
Dispatcherの内部実装の追い方

ではここから、Dispatcher の内部実装を辿って、先ほどおさらいした表面的な仕様がどのような仕組みに基づいているのかを明らかにしていきます。
今回は、kotlinx.coroutines に含まれる Coroutine Builder と Dispatcher のソースコードを読み解きます。
launchのソースコードを読む

Coroutine Builder の代表例として、launch のソースコードを読みます。
launch 自体のコードは、わずか4行の非常にシンプルな実装です。

まず1行目で、起動するコルーチンに紐づく CoroutineContext が作られます。
CoroutineContext は、コルーチンに付随するメタデータのコンテナで、Dispatcher もその一要素です。
launch に Dispatcher を引数として渡すと、新たに起動されるコルーチンの CoroutineContext に追加されます。

次に、コルーチンのインスタンスである StandaloneCoroutine が初期化されます。
ここでコルーチンの親子構造の形成なども行われますが、ここの詳細は次の Structured Concurrency の章で扱います。

最後に StandaloneCoroutine の start メソッドが呼ばれ、コルーチンが起動します。
この start が「コルーチンの実行」を担っているため、このメソッドを深掘りしていきます。
AbstractCoroutine.startのソースコードを追う

start メソッドは、StandaloneCoroutine の基底クラスである AbstractCoroutine に定義されています。
最終的には、Cancellable.kt に定義された startCoroutineCancellable メソッドが呼ばれます。
startCoroutineCancellableのソースコードを読む

この startCoroutineCancellable のソースコードを読んでいきます。
ただ、実装は少し複雑なので、まずはイメージ図で流れを整理します。

まず、createCoroutineUnintercepted という関数が呼ばれます。
これは、起動されるコルーチンに紐づく Continuation を初期化するための関数です。

次に、初期化された Continuation に対して intercepted メソッドが呼ばれます。
intercepted は、Continuation を DispatchedContinuation というクラスで wrap するための関数です。

最後に、DispatchedContinuation に対して resumeCancellableWith が呼ばれます。
これによって、DispatchedContinuation が Dispatcher に dispatch(送信)されます。

その後、Dispatcher が処理を非同期実行するタイミングで、
DispatchedContinuation に wrap された Continuation に対して resumeWith が呼ばれ、実際にコルーチンの処理が実行されます。
この流れの中で特に重要なのが intercepted の部分です。
DispatchedContinuationでwrapすることによって、Continuation を同期的に実行するのではなく、Dispatcher を介して任意のスレッド上で非同期実行できるようになっています。
interceptedのソースコード

それぞれのステップのソースコードも軽く流します。
詳しく知りたい方は、スライドにソースコードのリンクを記載しておりますので、そちらをご確認ください。
まず intercepted のソースコードですが、CoroutineContext から CoroutineDispatcher が取り出されて、
その Dispatcher に対して interceptContinuation が呼ばれます。
この interceptContinuation の中で、Continuation が DispatchedContinuation によって wrap されます。
resumeCancellableWithのソースコード

次のステップである、resumeCancellableWith のソースコードを見ると、 CoroutineDispatcher の dispatch メソッドが呼ばれていることが確認できます。
つまり、ここでDispatchedContinuation が Dispatcher に対して、送信されています。
DispatchedTask.runのソースコード

Dispatcher内部の処理は一旦飛ばしまして、最後に Dispatcher がコルーチンを実行する部分を見ていきます。
ここでは、DispatchedContinuation の基底クラスである DispatchedTask の run メソッドが呼ばれます。
run メソッドのソースコードを見ると、DispatchedContinuation に wrap された Continuation に対して resumeWith が呼ばれていることが分かります。
これによって、Dispatcher によってスケジュールされたコルーチンの処理が、実際に実行されます。
Dispatcherの内部実装を追う

ここまでで、launch 実行時に Dispatcher にコルーチンが渡される仕組みを見てきました。
ただし、DispatchedContinuation が Dispatcher に渡された後、実際にコルーチンが実行されるまでのプロセス(赤枠の部分)は、まだ説明できていません。
そこで、ここからは、Dispatcherにコルーチンが渡された 後の流れ を追っていきます。
CoroutineDispatcherの種別

dispatch メソッドの内部実装を追う前に、CoroutineDispatcher の種別をおさらいします。
代表的には、CPU バウンドなタスク向けの Dispatchers.Default、IO バウンドなタスク向けの Dispatchers.IO、そしてメインスレッドで実行する Dispatchers.Main があります。
また、これらの実装は JVM/Native/Web などの実行環境ごとに異なります。
今回は、この中でも使用頻度の高い Dispatchers.Default と Dispatchers.IO の JVM 版の実装 を解説します。
CoroutineDispatcher.dispatchが呼ばれた後の流れ

dispatch メソッドが呼ばれた後の流れを簡単に紹介します。
左側の Dispatchers.Default の場合、SchedulerCoroutineDispatcher の dispatch メソッドを経由して、
最終的に CoroutineScheduler の dispatch メソッドが呼ばれます。
一方、右側の Dispatchers.IO の場合は、まず LimitedDispatcher の dispatch メソッドを経由し、最終的には Dispatchers.Default と同様に CoroutineScheduler の dispatch が呼ばれます。
いずれも最終的には CoroutineScheduler の dispatch を呼びますが、そこに至るまでのプロセスが異なるため、共通の仕組み (例えば共通のスレッドプール) を使いつつも、一部の挙動が変わります。
CoroutineScheduler の dispatch 以降のソースコードは非常に複雑なため、ここからは模式図でイメージをお伝えします。
ただし、ここからの説明は、かなり簡略化した内容であり、実際の仕組みはより複雑です。
実際の仕組みを正確に知りたい方は CoroutineScheduler のソースコードをご確認ください。
Dispatchers.Defaultでコルーチンが実行される仕組み
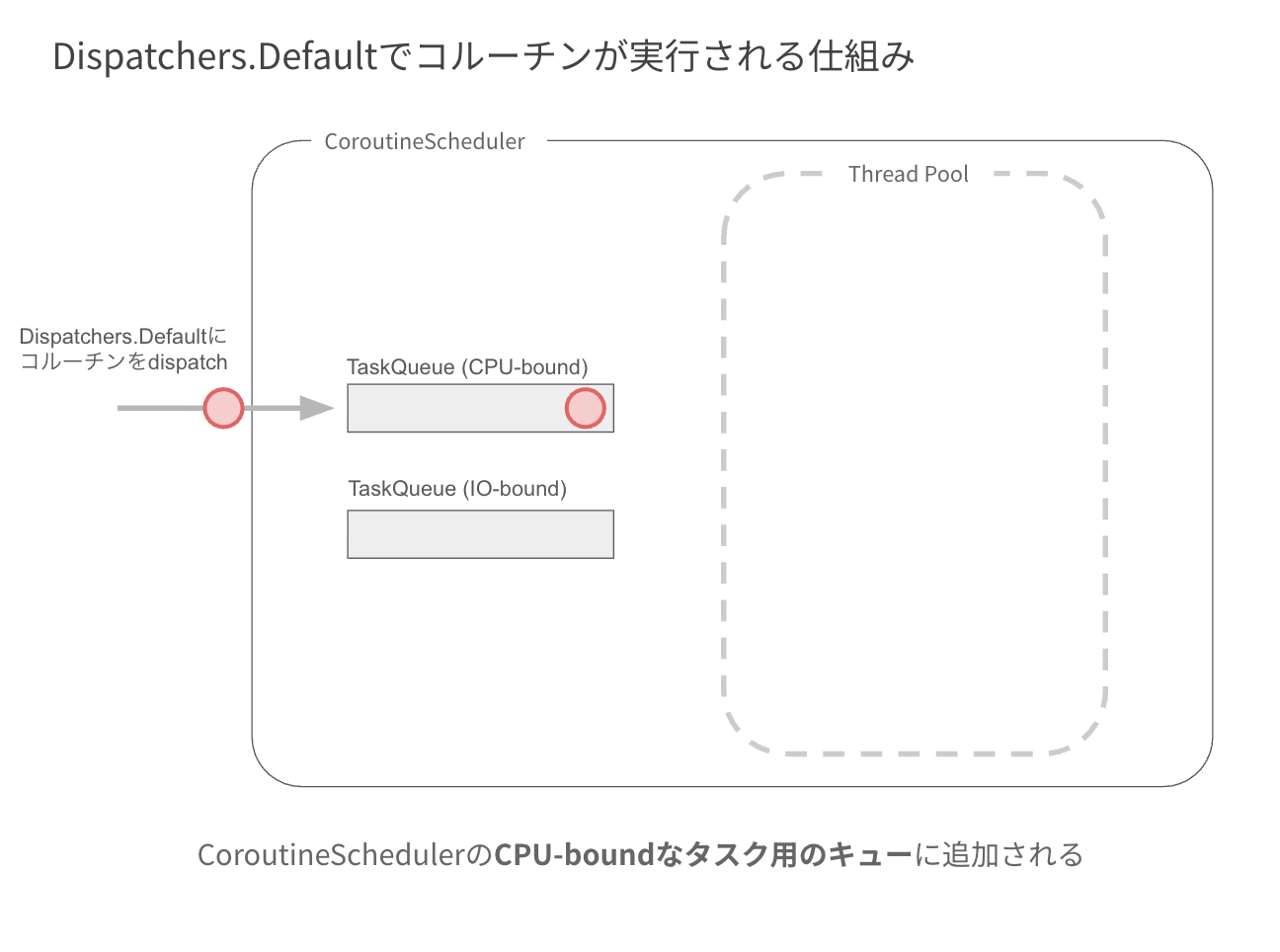
では、CoroutineScheduler でコルーチンが実行される仕組みを解説します。
まず、CoroutineScheduler 内には、実行すべきタスクを保持するキューがあり、
「CPU-bound なタスク用のキュー」と「IO-bound なタスク用のキュー」の2種類が存在します。
Dispatchers.Default に対してコルーチンが dispatch されると、CPU-bound なタスク用のキューにタスクが追加されます。

次に、このタスクを処理するための Worker が作られます。
この Worker とは、Javaの Thread を継承したクラスで、実際にタスクを実行する役割を持ちます。

Worker は、タスクキューからタスクを取得し、コルーチンを実行します。
ここでコルーチンが実行される際に、以前登場した DispatchedTask の run メソッドが呼ばれます。
タスクキューにタスクが存在する間、Workerはタスクの取得と実行をループし続けます。

CPU-bound なタスクがキューに追加される際に、必要に応じて Worker が追加されます。
ただし、CPU-boundなタスク、つまり Dispatchers.Default 経由で実行されるタスクを同時並行で処理できる Worker の数は、CPU のコア数以下 に制限されます。
これは、CPU-bound なタスクは、CPU を占有する傾向にあるため、Worker の数がコア数を超えてしまうと処理能力を低下させてしまうためです。
Dispatchers.IOでコルーチンが実行される仕組み

次に、Dispatchers.IO でコルーチンが実行される仕組みを見ていきます。
Dispatchers.IO にコルーチンが dispatch されると、IO-bound なタスク用のキュー に追加されます。

Dispatchers.Default の場合と同様に、タスクを処理するための Worker が必要に応じて生成されます。

その後、Worker が起動し、IO-bound なタスク用のキューからタスクを取得して、コルーチンを実行します。
ここで使用されるスレッドプールは、Dispatchers.Default と同じものです。

Dispatchers.Default との違いとして、IO-bound なタスクを同時並行で処理できる Worker の数には 上限がありません。
これは、IO-bound なタスクは、アイドル状態であることが多く、
同時にたくさん存在してもパフォーマンスが悪化しにくく、同時並行で処理することで、スループットが向上しやすいためです。
ただし、実際には無制限というわけではなく、前段で limitedParallelism という仕組みによって、実質的には上限が設けられています。
次は、この limitedParallelism について説明します。

最後にもう一度補足しておくと、ここまでの説明はあくまで簡略化したもので、実際の実装とは異なる部分があります。
例えば、実際には Worker ごとにローカルのタスクキューが存在するなど、より複雑な仕組みになっています。
正確な仕組みを知りたい方は、ぜひ CoroutineScheduler のソースコードを読んでみてください。
limitedParallelismによる並列に実行されるコルーチン数の制限

では、limitedParallelism の仕様について簡単におさらいします。
Dispatcher に対して limitedParallelism で制限を加えることで、
そのコンテキスト上で 同時並行に実行されるコルーチンの数に上限 を設定することができます。
こちらのサンプルコードで試してみると、Dispatchers.IO に対して limitedParallelism(2) を指定した場合、同時並行で実行されるスレッドの個数が2つに制限されることが分かります。
CoroutineDispatcher.dispatchが呼ばれた後の流れ (再掲)

ここで、以前示した「CoroutineDispatcherのdispatch が呼ばれた後の流れ」を再掲します。
Dispatcher に limitedParallelism を指定すると、Dispatchers.IO の場合と同様に LimitedDispatcher を経由して処理されるようになります。
実は、Dispatchers.IO はデフォルトで limitedParallelism(64) が適用されているため、常に LimitedDispatcher を介して、dispatchされる仕組みになっています。
LimitedDispatcherの内部実装

LimitedDispatcher の仕組みを簡単に解説します。
まず、LimitedDispatcher も CoroutineScheduler と同様に、タスクキュー と Worker を持っています。
CoroutineDispatcher にコルーチンが dispatch されると、まず前段にある LimitedDispatcher のタスクキューにタスクが追加されます。
続いて、LimitedDispatcher の Worker が生成され、そのタスクを CoroutineScheduler に dispatch します。
この Worker は、CoroutineScheduler に dispatch された処理が完了するまで存在し続けます。
Worker の数は、指定された並列数を超えないように制御されており、
もし並列数を超えそうな場合には、LimitedDispatcher 側のタスクキューで待機します。
このように、LimitedDispatcher は CoroutineScheduler の前段で動作し、
実行中のコルーチンの数が limitedParallelism で指定された並列数以下になるように制御しています。
そのため、Dispatchers.IO を利用している場合、CoroutineScheduler 側では Worker 数に上限が設けられていなくても、
LimitedDispatcher による制限によって、実質的には一定数以上の Worker が生成されないようになっています。
では、ここまでで Dispatcher に関する説明を終えます。
コルーチンがどのようにバックグラウンドで非同期実行されるのか、
Dispatchers.Default と Dispatchers.IO の違い、そして limitedParallelism の仕組みについて、理解が少しでも深まっていれば嬉しいです。
第3章:Structured Concurrency

では、最後のコンセプトである Structured Concurrency の解説に移ります。
Structured Concurrencyとは

まず、Structured Concurrency とは何かを説明します。
Structured Concurrencyとは、親コルーチンが子コルーチンを起動した際に、子コルーチンが完了するまでは親コルーチンも完了しない、というルールに従った並行処理を指します。

このルールに反する場合、子コルーチンのリソースがリークする危険性があります。
たとえば Java では、スレッドを fork したあとに join せずスコープを抜けるといったコードも書けてしまいますが、これはリソースリークの危険性があります。
一方、Kotlin Coroutines では、変な書き方をしない限り、Structured Concurrency が自動的に守られるように設計 されています。
Kotlin CoroutinesにおけるStructured Concurrency

Kotlin Coroutines における Structured Concurrency の実現には、
Coroutine Scope が中核的な役割を持ちます。
こちらのサンプルコードでは、coroutineScope 内で 2 つのコルーチンを launch していますが、
両方のコルーチンが完了してから coroutineScope を抜けていることが確認できます。
また、すべてのコルーチンは基本的に Coroutine Scope を起点に起動 する必要があります。
これは、launch や async といった Coroutine Builder が、CoroutineScope の拡張関数として定義されているためです。
これら 2 点から、Kotlin Coroutines では一般的な書き方をしている限り、
Structured Concurrency が強制的に守られる設計 になっていることが分かります。
ここからは、1 点目の「CoroutineScope は、子コルーチンがすべて完了してからスコープを抜ける」という仕様が、どのような仕組みで実現されているのかを、内部実装から見ていきます。
CoroutineScopeの内部実装の追い方

CoroutineScope のソースコードも、Dispatcher と同様に、拡張ライブラリである kotlinx.coroutines に定義されています。
coroutineScopeのソースコード

coroutineScope のソースコードを見ると、呼び出し元の Continuation と CoroutineContext を利用して、
Coroutine Scopeに紐づくコルーチンである ScopeCoroutine の初期化と起動を行っていることが分かります。
ScopeCoroutineのソースコード

この ScopeCoroutine のソースコードを見てみましょう。

ScopeCoroutine は AbstractCoroutine を継承しています。
AbstractCoroutine とは、以前に launch の説明で登場した StandaloneCoroutine も含めた、あらゆるコルーチンの基底クラスです。
この AbstractCoroutine の初期化時に、コルーチンの 親子構造 が形成されます。
今回は「子コルーチンの完了を待つ」仕組みを知りたいので、
この親子構造がどのように形成されるかを押さえることが重要になります。
コルーチンの親子構造の形成

AbstractCoroutine の初期化時のソースコードを見ると、親の CoroutineContext から 親コルーチンの Job が取り出され、それを引数に initParentJob というメソッドが呼ばれます。
initParentJob の中では、親の Job に対して、attachChild メソッドを使って、このコルーチンをJobを取り付けることで、Job の親子構造 を形成しています。
これによって、親コルーチンが子コルーチンを参照でき、逆に子コルーチンも親コルーチンを参照できるようになり、情報の伝達が可能となります。
コルーチンの親子構造の形成 (イメージ図)

イメージ図で説明すると、こちらのサンプルコードの場合、
まず main の Continuation の子として coroutineScope のコルーチンがあり、
さらにその子として launch で起動された 2 つのコルーチンが存在します。
子コルーチンが初期化される際には、親コルーチンの CoroutineContext が渡され、
その中に含まれる Job に対して子コルーチンの Job を attachChild することで、親子構造が形成されます。
Job は、コルーチンを使っていれば一度は目にしたことがあると思いますが、
その重要な役割のひとつが、コルーチン間の親子構造を形成すること です。
ScopeCoroutineのソースコード (再掲)

では、再び ScopeCoroutine のソースコードに戻ると、もう一つ注目すべき点があります。

それが、afterCompletion と afterResume の 2 つのメソッドです。
どちらも内部で、呼び出し元の Continuation に対して resumeWith を呼び出しています。
つまり、これらのメソッドのどちらかが呼ばれると、coroutineScope を抜けて 呼び出し元に制御が戻る ということになります。
したがって、afterCompletion または afterResume のいずれかが呼ばれるまでの過程を追うことで、 CoroutineScope が内部の子コルーチンの完了を待つ仕組み を知ることができます。
Jobの役割

ここで、もう一度 Kotlin Coroutines における Job の役割 について整理します。
Job の役割は大きく 2 つあります。
1つ目は、コルーチンの状態管理 です。
Job は状態を持っており、スライドに示すような状態遷移に沿って変化します。
通常は、Job が作成されて Active 状態になり、その後自身の処理が完了すると Completing 状態に移ります。
そして、すべての子コルーチンが完了したタイミングで、最終的に Completed 状態になります。
ただし、Active または Completing の間に例外やキャンセルが発生すると、Cancelling 状態に移り、最終的に Cancelled 状態になります。
2つ目の役割は、以前のスライドでも触れた コルーチンの親子構造を管理する役割 です。
これには、親子構造を通じて 完了やキャンセルといった状態を伝播させる という責務も含まれます。
これらの Job の役割が、Coroutine Scope が子コルーチンの完了を待つ仕組み を理解するための前提知識となります。
Coroutine Scopeが子コルーチンの完了を待つ仕組み

では、CoroutineScope が子コルーチンの完了を待つ仕組み を見ていきます。
この仕組みはソースコード上では JobSupport というクラスを中心に実装されていますが、非常に複雑なため、ここではイメージ図を用いて解説します。
こちらのサンプルコードを例に、coroutineScope が launch の完了をどのように待つのかを説明します。
まず、main 関数が呼ばれた直後の状態から見ていきます。
main は suspend 関数なので、main に紐づく Continuation が存在します。
この Continuation は CoroutineContext を持っており、その中に Job が含まれています。

続いて、ScopeCoroutine が起動し、main の Job と ScopeCoroutine の Job の間に 親子構造 が形成されます。

さらに、coroutineScope 内で最初の launch が呼ばれ、StandaloneCoroutine が起動します。
その際、ScopeCoroutine の Job と、起動された StandaloneCoroutine の Job の間に新たな 親子構造 が形成されます。

同様に、2つ目の launch によって StandaloneCoroutine が起動し、
ScopeCoroutine の Job と、起動された StandaloneCoroutine の Job の間に 親子構造 が形成されます。
ここまでで、すべての子コルーチンが起動し、Job の親子構造の全体像が完成します。

2つ目の launch が終わった時点で、coroutineScope 内の処理は完了します。
このタイミングで、ScopeCoroutine の Job は Active から Completing、つまり「子コルーチンの完了待ち」の状態へと遷移します。

少しソースコードを見ますと、coroutineScope 内の処理が完了すると、ScopeCoroutine の resumeWith が呼ばれます。
resumeWith のソースコードを見ると、まず makeCompletingOnce というメソッドが呼ばれます。
これが先ほど説明したように、ScopeCoroutine の Job を Completing 状態 に遷移させる役割を持ちます。
その後、未完了の子コルーチンが残っている場合は、何もせず return します。
一方で、この時点で全ての子コルーチンが完了していれば、afterResume が呼ばれ、coroutineScope を抜けます。
少し前のスライドでお伝えしたように、afterResume もしくは afterCompletion のどちらかが呼ばれると
coroutineScope を抜けるのですが、このケースでは afterResume が呼ばれるパターンに該当します。
ただし、今回のケースではまだ未完了の子コルーチンが存在しているため、ここでは return して終了します。

ここからが、CoroutineScope が子コルーチンの完了を待つ仕組みの重要なポイント です。
先ほど登場した makeCompletingOnce メソッドの中で、
未完了の子コルーチンのいずれかに対して、完了時に呼ばれるコールバック関数(CompletionHandler)が登録されます。
今回は、2つ目のコルーチンに CompletionHandler が登録されるケースを想定します。

その後、2 つ目の StandaloneCoroutine が先に完了し、 その Job が COMPLETED 状態になります。

すると、登録されていた CompletionHandler を介して、
ScopeCoroutine の Job の continueCompleting メソッドが呼ばれます。

この continueCompleting メソッドのソースコードを見てみましょう。
構造としては、先ほどの resumeWith と非常によく似ています。
まず、未完了の子コルーチンが残っている場合には、その未完了の子コルーチンに
CompletionHandler を登録して return します。
一方で、すべての子コルーチンが完了している場合には、afterCompletion が呼ばれ、
coroutineScope を抜けます。
先ほどの resumeWith では afterResume によってスコープを抜けていましたが、
この continueCompleting では、もう一方の afterCompletion によってスコープを抜けます。

今回のケースでは、まだ 1 つ目の子コルーチンが未完了のため、
この未完了の子コルーチンに対して、 CompletionHandler が登録されます。

さらに時間が経つと、1 つ目の StandaloneCoroutine が完了し、Job が COMPLETED になります。

すると、先ほどと同様に CompletionHandler を介して、ScopeCoroutine の Job の continueCompleting メソッドが呼ばれます。

今回は、子コルーチンがすべて完了しているため、afterCompletion が呼ばれ、coroutineScope を抜けます。
このように、CompletionHandler を使った仕組みによって、Coroutine Scopeが子コルーチンの完了を待つ、という仕様が実現されています。
Coroutine Scopeが子コルーチンの完了を待つ流れ

最後に、CoroutineScope が子コルーチンの完了を待つ流れ をおさらいします。
まず、coroutineScope 内の処理が完了すると、その時点で未完了の子コルーチンがあるかを確認します。
すべての子コルーチンが完了済みであれば、afterResume が呼ばれ、coroutineScope を抜けます。
一方で、未完了のコルーチンが存在する場合には、そのうちの1つに CompletionHandler を登録し、
そのコルーチンが完了するまで待機します。
CompletionHandler が登録された子コルーチンが完了すると、再び未完了のコルーチンがあるかを確認します。
この時点で全ての子コルーチンが完了していれば、afterCompletion が呼ばれ、coroutineScope を抜けます。
まだ未完了の子コルーチンが存在する場合には、別の子コルーチンに CompletionHandler を登録します。
つまり、全ての子コルーチンが完了するまで、この処理がループされます。
以上で、Coroutine Scopeの内部実装の関する説明も終わりとします。
Structured Concurrencyとは何か、そしてCoroutine ScopeやJobが果たす役割について、少しでもイメージが深まっていれば嬉しいです。
本発表のまとめ

最後に、本発表のまとめです。
この発表では、Kotlin Coroutines を支える3つの中心的なコンセプト について、
その内部実装をもとに仕組みを解読しました。
まず、Continuation のソースコードを読むことで、
suspend 関数がどのように一時停止し、再開するのかを明らかにしました。
次に、Coroutine Builder や Coroutine Dispatcher のソースコードを通じて、
コルーチンがどのように非同期処理・並行処理を実行しているのかを解説しました。
そして最後に、Coroutine Scope や Job の実装を追うことで、
Kotlin Coroutines が Structured Concurrency をどのように実現しているのかを見てきました。
この発表が、皆さんの中で Kotlin Coroutines に対する “ブラックボックス” を少しでも晴らすきっかけになっていれば幸いです。
また、AI ツールを活用すれば、今や誰でも簡単にソースコードを読み解くことはできます。
Kotlin Coroutines の仕様について腑に落ちないところがある方は、ぜひ実際にソースコードを覗いてみてください。
Discussion