🌟
正規表現の整理メモ


最近正規表現をやってみて、全部は覚えてないけどその時点でもかなり有用だったから自分用に整理。覚える重要度が高い順で。
とても分かりやすかったので吉川ウェブさんのチートシートから一部を引用させていただきました。
重要度:高
ここだけ覚えて組み合わせるだけでもある程度通用するかも。
■パターン系
・ある1文字が指定の文字群のうちどれかに一致
[](ブラケット)内に記述した文字群からどれか1つに一致する箇所にマッチする
[(文字群)]
・ある1文字が任意の文字に一致
.
. (ドット)で表現
■繰り返し系
・指定の文字がn~m回連続 (n < m)
(文字){n,m}
nとmはどちらか一方を省略してもよい
・指定の文字がn回だけ連続(nは整数)
(文字){n}
・指定の文字が0個以上連続
(文字)*
・指定の文字が1個以上連続
(文字)+
■文字列系
・検索前の文字列をキャプチャする
(キャプチャしたい文字)
※ここでは()は置き換えの表現ではなく、括弧そのものを記述することを表す
・n番目にキャプチャした文字列を取得(nは整数)
$n
重要度:中
優先度:高と合わせるとさらにいろいろな表現が可能。
■パターン系
・ある1文字が指定の文字群の以外の文字に一致
[^(文字群)]
・n種類のパターンのうちいずれか一方に一致
(パターン1)|(パターン2) ...... |(パターンn)
| (バーティカルバー)で区切る
■繰り返し系
・最小一致
繰り返し系の表現の末尾に?を記載
(文字)(繰り返し表現)?
未指定では最長の繰り返しパターンにマッチしていたが、最短の繰り返しパターンにマッチするようになる。
例えば、"aaa"に対してa{1,3}?と指定した場合、"a"がマッチする。
■文字列系
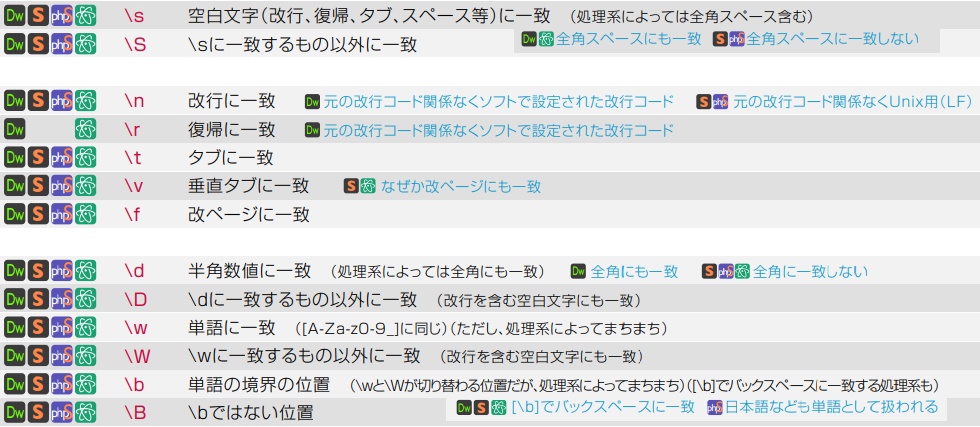
・制御文字を指定
吉川ウェブさんのチートシートを見た方が早い。タブ、改行とかを指定。
重要度:低
自分自身が覚えきれていないので整理できたらまた書こうと思います。
Discussion