[Go] json.Unmarshal と json.Decoder の使い分け ~ json.Decoder に親しむ
はじめに
今やあらゆるアプリケーションは Go で書かれていると言っても過言ではない(過言)。そして、今やあらゆるデータは json であると言っても過言ではない(過言)。
となると、Go で json を扱う頻度も必然的に多くなる。そして初めて Go で json をデコードするコードを書こうとした人は、必ずこの問題にぶち当たる。
「json.Unmarshal と json.Decoder は何が違うのか?そしてどちらを使えばいいのか?」
そしてググると大抵以下のような答えにたどり着く。
- 入力が文字列(
string)やバイト列([]byte)の場合はjson.Unmarshal()を使う - 入力がストリーム(
io.Reader)の場合はjson.Decoderを使う
なるほど、確かにパッと見はそれでいいように思える。思えるんだが、よく見ると実は他にもいくつか考慮すべき点がある。
入力形式以外にjson.Unmarshal() と json.Decoder に何か違いがあったっけ?となるかもしれないが、実は json.Decoder の方が機能が豊富なのだ。json.Decoder にしかできないことは以下の 4 つ。
- トークン単位でデコードできる
- 連続した
json値をデコードできる - オブジェクトの知らないキーをエラーにできる
- 数値を
json.Number型で受け取れる
と言う訳で、この記事ではこの 4 つの機能について解説しようと思う。 入力形式の違いが、選択の決定的基準でないことを教えてやる! そして最後に、ググると出てくる「入力に合わせて使い分ける」のがホントにいいのかについても触れる。
なお、当方 Go も json もエアプなのでツッコミは大歓迎。おかしな点や改善点などがあれば遠慮なくツッコミを入れて欲しい。
json.Decoder はトークン単位でデコードできる
もしかしたらあんまり使われていないのかもしれないが、json.Decoder には完全な json 値ではなく json の「トークン」を 1 つづつ順次デコードして読み進めていく機能がある。Token() メソッドがそれだ。一方 json.Unmarshal() にはそんな機能はない。そもそも一回のメソッド呼び出しで json 値をデコードする関数なんだから当たり前だ。
個人的には json.Decoder のイチオシの機能で、むしろ json.Decoder はこの機能のためにあるんじゃないかとすら思っている。
Token() の使い方
さっそく、コードとその実行結果を見て行こう。
s := `{"foo":"data","bar":42,"baz":[true,null]}`
r := strings.NewReader(s)
dec := json.NewDecoder(r)
for {
t, err := dec.Token()
if err != nil {
if err != io.EOF {
fmt.Printf("エラー発生:%#v\n", err)
}
break
}
fmt.Printf("トークン:%T, %+[1]v\n", t)
}
トークン:json.Delim, {
トークン:string, foo
トークン:string, data
トークン:string, bar
トークン:float64, 42
トークン:string, baz
トークン:json.Delim, [
トークン:bool, true
トークン:<nil>, <nil>
トークン:json.Delim, ]
トークン:json.Delim, }
これを見ればもうなんとなくの使い方は分かったという人も多いかもしれない。
Token() メソッドは次の「トークン」を返す。ここで、「トークン」とは以下の 5 種類の値のいずれかである。
| 入力データ | トークンの型 | トークンの例 |
|---|---|---|
| 配列やオブジェクトの区切り文字 | json.Delim |
json.Delim('{') |
| 真偽値 | bool |
true |
| 文字列 | string |
"foo" |
| 数値 |
float64 または json.Number
|
42 |
null |
nil |
nil |
入力データが数値の場合のトークンの型が 2 つあることについては「でも Token() は UseNumber() の影響受けるよ」を見て欲しい。
ちなみに、上記の出力からも分かる通りオブジェクトのキーは string 型のトークンとして返される。また、配列内やオブジェクト内の , や : は(配列やオブジェクトの区切り文字ではあると思うが)json.Delim で返却されたりはしない。返却されなくても大丈夫なのか?と思うかもしれないが、正しい場所になかったり正しくない場所にあったりした場合はエラーになるだけなのでトークンとしては不要なのだ。
// : じゃなくて , になってる
s := `{"foo","data","bar",42,"baz",[true,null]}`
// あとは「Token」と一緒
トークン:json.Delim, {
トークン:string, foo
エラー発生:&json.SyntaxError{msg:"invalid character ',' after object key", Offset:6}
また、配列やオブジェクトのネスト構造が狂ってるとエラーが返る。
// 配列の閉じ括弧が } になってる
s := `{"foo":"data","bar":42,"baz":[true,null}}`
// あとは「Token」と一緒
トークン:json.Delim, {
トークン:string, foo
トークン:string, data
トークン:string, bar
トークン:float64, 42
トークン:string, baz
トークン:json.Delim, [
トークン:bool, true
トークン:<nil>, <nil>
エラー発生:&json.SyntaxError{msg:"invalid character '}' after array element", Offset:39}
が、単に閉じてないだけの場合にはエラーにはならないので注意。
// オブジェクトも配列も閉じてない
s := `{"foo":"data","bar":42,"baz":[true,null`
// あとは「Token」と一緒
トークン:json.Delim, {
トークン:string, foo
トークン:string, data
トークン:string, bar
トークン:float64, 42
トークン:string, baz
トークン:json.Delim, [
トークン:bool, true
トークン:<nil>, <nil>
なので、ちゃんと閉じてるかの確認は自前でする必要がある。エラーさえ出せればいいのであればネストの深さだけカウントして終了時に 0 であることをチェックすればいいので簡単だ。
// オブジェクトも配列も閉じてない
s := `{"foo":"data","bar":42,"baz":[true,null`
r := strings.NewReader(s)
dec := json.NewDecoder(r)
nest := 0 // ネストチェック用カウンタ
for {
t, err := dec.Token()
if err != nil {
if err != io.EOF {
fmt.Printf("エラー発生:%#v\n", err)
}
break
}
fmt.Printf("トークン:%T, %+[1]v\n", t)
// 配列やオブジェクトのデリミタならネストチェック用カウンタを調整する
if v, ok := t.(json.Delim); ok {
switch v {
case '{', '[':
nest++
default:
nest--
}
}
}
if nest != 0 {
fmt.Printf("ネストエラー検出:%d\n", nest)
}
トークン:json.Delim, {
トークン:string, foo
トークン:string, data
トークン:string, bar
トークン:float64, 42
トークン:string, baz
トークン:json.Delim, [
トークン:bool, true
トークン:<nil>, <nil>
ネストエラー検出:2
何が閉じられていないかも確認したいのであればもうひと工夫必要だが、それでもそこまで大したことはない。
// オブジェクトも配列も閉じてない
s := `{"foo":"data","bar":42,"baz":[true,null`
r := strings.NewReader(s)
dec := json.NewDecoder(r)
var nest []byte // ネストチェック用バッファ
for {
t, err := dec.Token()
if err != nil {
if err != io.EOF {
fmt.Printf("エラー発生:%#v\n", err)
}
break
}
fmt.Printf("トークン:%T, %+[1]v\n", t)
// 配列やオブジェクトのデリミタならネストチェック用バッファを調整する
if v, ok := t.(json.Delim); ok {
switch v {
case '{', '[':
// 開き括弧なら追加(+2 すると { と [ が } と ] になる)
nest = append(nest, byte(v + 2))
default:
// 閉じ括弧なら削除
nest = nest[0:len(nest)-1]
}
}
}
if len(nest) != 0 {
slices.Reverse(nest) // 閉じる順番は逆順なので逆順に並べ替える
fmt.Printf("ネストエラー検出:%v\n", string(nest))
}
トークン:json.Delim, {
トークン:string, foo
トークン:string, data
トークン:string, bar
トークン:float64, 42
トークン:string, baz
トークン:json.Delim, [
トークン:bool, true
トークン:<nil>, <nil>
ネストエラー検出:]}
ちょっとエラーが見づらいが必要な情報は揃っているから許して。
どんな時に使うの?
上記の内容から分かる通り、Token() さえあればあらゆる json をデコードすることができる。できるんだが、さすがにそんなことをするマゾい人はいないだろう。(いたらゴメン)
じゃあどんな時に使うの?と言うと、例えばサーバのレスポンスが数値のクソデカ配列を返すことが分かってるんだけど実際に必要なのはその中の最大値だけ、みたいな時に以下のようにすると一度に全体をデコードしなくて良くなる。
// r はホントはサーバのクソデカレスポンスだとでも思ってくれ
r := strings.NewReader("[2,4,6,8,10,1,3,5,7,9]")
dec := json.NewDecoder(r)
_, _ = dec.Token() // 最初の '[' を飛ばす
m := math.Inf(-1) // 最大値用変数
for dec.More() {
t, _ := dec.Token()
m = max(m, t.(float64))
}
_, _ = dec.Token() // 最後の ']' を飛ばす
fmt.Printf("最大値:%v\n", m)
最大値:10
ほら、何となく入力が io.Reader であることを生かした使い方っぽくない?
なお、ループ条件に使っている More() は「現在の配列やオブジェクトの中で、まだ要素が残っているか否かを bool 値として返す」ためのメソッドである。
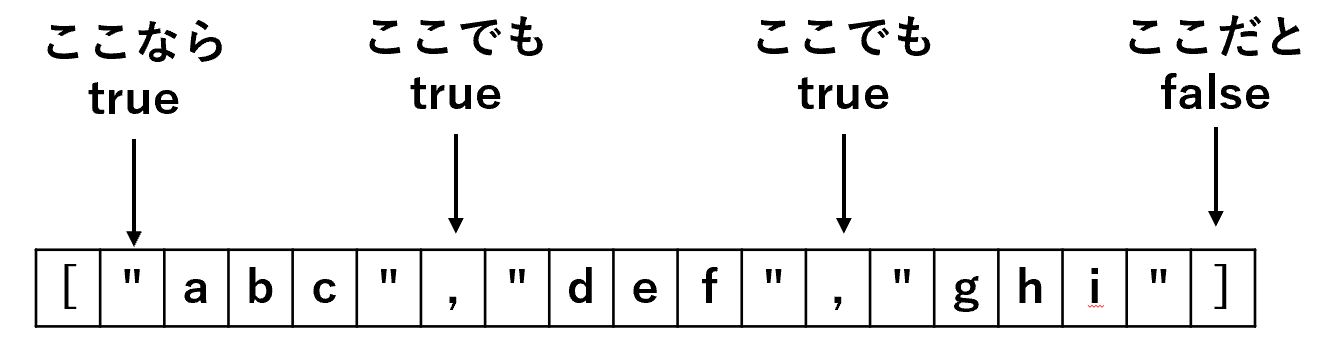
More() の挙動
Token() と Decode() を混ぜて使う
ところで、Token() を使うと決めたらひたすら Token() だけを使い続けなきゃいけない、と言うことは無くて、Token() と Decode() を混ぜて使うこともできる。
例えば、上記の例で配列の内容が単なる数値じゃなくて名前と年齢のオブジェクトだった場合に最高齢のデータだけを取得したいとすると、Token() だけでやるのはさすがにめんどくさすぎるので、要素のデコードには Decode() を使うと良い。
// r はホントはサーバのクソデカレスポンスだとでも思ってくれ
r := strings.NewReader(`[
{"name": "アウラ", "age": 500},
{"name": "フリーレン", "age": 1000},
{"name": "フェルン", "age": 17}
]`)
// 各要素用の型
type Character struct {
Name string
Age int64
}
dec := json.NewDecoder(r)
_, _ = dec.Token() // 最初の '[' を飛ばす
var m Character // 最高齢データ用変数
for dec.More() {
var v Character
_ = dec.Decode(&v) // <- NEW! 要素 1 つ分デコード
if m.Age < v.Age {
m = v
}
}
_, _ = dec.Token() // 最後の ']' を飛ばす
fmt.Printf("最高齢:%+v\n", m)
最高齢:{Name:フリーレン Age:1000}
このように配列の各要素毎に Decode() でデコードすることで、一度に全体をデコードすることなく必要な要素だけを取ってくることができる。(ちなみにフェルン以外の年齢はざっくりです)
ほら、なかなか便利でしょ?そうでもない?そうですか…
json.Decoder は連続した json 値をデコードできる
実は気付いてない人が多いんじゃないかと疑っているのだが json.Decoder は連続した json 値をデコードできるようになっている。
json.Unmarshal のデコード対象は単一の json 値
json.Unmarshal() は皆さん(カイさんではない)もご存知の通り単一の json 値をデコードするものなので、入力として複数の json 値を与えるとエラーになる。
// 入力データには 2 つの json 値が連続して入っている
s := `{"abc":"def"}` + `{"ghi":"jkl"}`
var m any
if err := json.Unmarshal([]byte(s), &m); err != nil {
fmt.Printf("エラー発生:%#v\n", err)
} else {
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
}
エラー発生:&json.SyntaxError{msg:"invalid character '{' after top-level value", Offset:14}
見ての通り、1 つ目の json 値をデコードした後にまだ { とか言う文字が出てきたので、「なんじゃあこりゃああ!」と言って殉職している。合掌🙏
そして、json.Unmarshal() ではこの挙動を変更することはできない。
あ、あと今更だがこの記事のコードではエラーを出力する際に %#v を使っているので、出力が若干ウザい。何で %#v を使っているかって言うと %v や %+v だと Offset が出力されないからだ。 でも実は %#v 使っちゃうと UnmarshalTypeError の時に Type がちゃんと出てくれないんだよね((*reflect.rtype)(0x4adfc0) みたいになっちゃう)。どのあたりでエラーが出たかって言う情報は割と重要だと思うんだけど、何でメッセージには出してくれないんですかね…
json.Decoder のデコード対象は複数の json 値
一方 json.Decoder は連続した json 値をデコードするようにできている。
// 入力データには 2 つの json 値が連続して入っている
s := `{"abc":"def"}` + `{"ghi":"jkl"}`
r := strings.NewReader(s)
dec := json.NewDecoder(r)
// データがある限りデコードし続ける
for i := 0; ; i++ {
var m any
if err := dec.Decode(&m); err != nil {
if err != io.EOF {
fmt.Printf("エラー発生(%d番目):%#v\n", i, err)
}
break
}
fmt.Printf("デコード結果(%d番目):%T, %+[2]v\n", i, m)
}
デコード結果(0番目):map[string]interface {}, map[abc:def]
デコード結果(1番目):map[string]interface {}, map[ghi:jkl]
見ての通り、確かに連続する複数の json 値をデコードできている。
特に気を付けて見て欲しいのは、複数の json 値の間には改行どころか空白すらない、と言うことだ。つまり ndjson とかそういう類のモノではなく、純粋に複数の json 値が並んでいるだけだ。
「純粋に複数の json 値が並んでいるだけ」と言うことから恐るべき(?)結論が導き出される。truefalse や nullnull と言った入力が 2 つの json 値として正しくデコードできるのだ!え、何それキモい…
// 入力データには true と false が連続して入っている
s := "truefalse"
// あとは「複数入力 OK」と一緒
デコード結果(0番目):bool, true
デコード結果(1番目):bool, false
// 入力データには 2 つの null が連続して入っている
s := "nullnull"
// あとは「複数入力 OK」と一緒
デコード結果(0番目):<nil>, <nil>
デコード結果(1番目):<nil>, <nil>
ちなみに、間に任意の空白文字を置くことはできるので、ndjson「も」デコードすることができる。しかし、一つの json 値の中に改行があってもエラーにはならないし、複数の json 値の間に改行が無かろうが複数あろうがエラーにはならない。ndjson をしっかりとチェックしたいのであれば、bufio.Reader の ReadBytes('\n') や bufio.Scanner の Bytes() などで 1 行ずつ切り出した後にデコードした方が良いだろう。
ところで、気付いた人もいるかもしれないが、実は Token() も配列やオブジェクトの一部ではない「地の部分」では空白も挟まずに連続したトークンをデコードできる。
s := "truefalsenull"
// あとは「Token」と一緒
トークン:bool, true
トークン:bool, false
トークン:<nil>, <nil>
あまり役に立つ知識ではないが、まぁ一応記憶の片隅には残しておいた方がいいかもしれない。
json.Decoder でも 1 個じゃなかったらエラーにしたい場合
さて、json.Decoder が複数 json 値をデコードするようになっていたとしても、普通はそれを無視しておけば良いだろう。いずれにせよ最初の json 値は普通にデコードできるからだ。通常、デコードした後ろに変な文字列があろうがそれほど困ることはないんじゃなかろうか。(実はちょっと困ったことも起きる。「おまけ:サーバのレスポンスを直接デコードする時の注意点」を参照)
しかし、入力値がユーザ入力なのでデータの正当性を確かめたい、と言う場合があるかもしれない。あるいは、原理主義的にオレは全ての入力をチェックするぜ、みたいな人もいるかもしれない。(いるか?)
余分な「トークン」をチェックする
その場合は以下のようにすると、いらん文字列(と言うかトークン)が続いていないかを判断できる。
// 入力データには 2 つの json 値が連続して入っている
s := `{"abc":"def"}` + `{"ghi":"jkl"}`
r := strings.NewReader(s)
dec := json.NewDecoder(r)
var m any
if err := dec.Decode(&m); err != nil {
fmt.Printf("エラー発生:%#v\n", err)
} else if t, err := dec.Token(); err != io.EOF {
if err == nil {
switch v := t.(type) {
case nil:
fmt.Printf("余分なトークン発見:null, null, 位置:%d\n", dec.InputOffset())
case json.Delim:
fmt.Printf("余分なトークン発見:%T, %[1]q, 位置:%d\n", v, dec.InputOffset())
default:
fmt.Printf("余分なトークン発見:%T, %#[1]v, 位置:%d\n", t, dec.InputOffset())
}
} else {
fmt.Printf("ナゾのエラー発生:%#v\n", err)
}
} else {
fmt.Printf("デコード結果:%#v\n", m)
}
余分なトークン発見:json.Delim, "{", 位置:14
見ての通り、前にも出てきた Token() で余分なトークンを検出している。
エラー出力部分が妙に長いのは、単純にいつでも %v で出力すると余分なトークンが " " みたいなヤツだと何も出力されなくて困惑するし、かと言って %#v で出力すると今度はデリミタ { が 123 と出力されて意味不明になってしまうし、じゃあ %q にできるかと言えば今度はデリミタや文字列以外の時に書式エラーになるしで、仕方なく場合分けしたからだ。
どうでもいいけど fmt.Printf の書式文字列難しすぎやしませんかね?そうでもない?そうですか…
これでも、1e5 が 100000 になってしまうのは避けられないが、まあ許してくれ。(実は Token() を呼び出す直前に UseNumber() を呼んでおくとマシになる。「でも Token() は UseNumber() の影響受けるよ」を参照)
しかし、余分なトークンでのチェックだと、続く文字列が # とかだと
// 入力データには json 値の後ろに # が入っている
s := `{"abc":"def"}` + "#"
// あとは「複数入力 NG 後続トークンチェック エラー出力改善」と一緒
ナゾのエラー発生:&json.SyntaxError{msg:"invalid character '#' looking for beginning of value", Offset:14}
になるし(json 値をデコードした「後」なのに beginning of value ってのはどうなのよ?)、続く文字列が - とかだと
// 入力データには json 値の後ろに - が入っている
s := `{"abc":"def"}` + "-"
// あとは「複数入力 NG 後続トークンチェック エラー出力改善」と一緒
ナゾのエラー発生:&errors.errorString{s:"unexpected EOF"}
になってしまう。(むしろ unexpected なのは - なのだが…)
ちなみに、非常にどうでもいいことだが、この続く文字が a とか F だと # と同じようなエラーになるが、同じアルファベットでも f とか t だと unexpected EOF になる。理由は分かるかな?
ちゃんと(?)余分な「文字」をチェックする
さて、エラーメッセージ出力のためにどうせ長くなるんなら、余分な「トークン」ではなくて余分な「文字」を出力した方がエラーメッセージは分かりやすくなる(と思う)。と言う訳で、余分な文字をチェックする方法についても紹介しようと思う。
が、余分な文字をチェックするには、ちょっとしたおまじないが必要だ。なぜおまじないかと言うと、ドキュメントには書かれていない json.Decoder の内部実装にがっつり依存しているからだ。
// 入力データには 2 つの json 値が連続して入っている
s := `{"abc":"def"}` + `{"ghi":"jkl"}`
r := strings.NewReader(s)
dec := json.NewDecoder(r)
var m any
if err := dec.Decode(&m); err != nil {
fmt.Printf("エラー発生:%#v\n", err)
} else {
// デコーダの内部バッファに必ず次の非空白文字が読み込まれている状態にする
_ = dec.More()
// 次の 1 文字を読み込む
c, err := dec.Buffered().(*bytes.Reader).ReadByte()
if err == io.EOF || (c == ' ' || c == '\t' || c == '\r' || c == '\n') {
// 次の文字が無いか、空白文字しか無いなら OK
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
} else {
// 非空白文字があったら NG
fmt.Printf("余分な文字発見:%q, 位置:%d\n", c, dec.InputOffset())
}
}
余分な文字発見:'{', 位置:13
結果として大して長くは無いが(何ならさっきより短い)、おまじないのせいで明瞭さに欠けているように思える。(そうでもないかな?)
そこで、一応おまじないの解説をしたいと思う。
おまじないその1:dec.More()
第1のおまじないは dec.More() である。
今我々がしたいことは、デコード済みの json 値の後ろに「良く分からないいらない文字」、つまりは「非空白文字」が存在しないかをチェックすることである。(空白文字はあってもいいよね?)
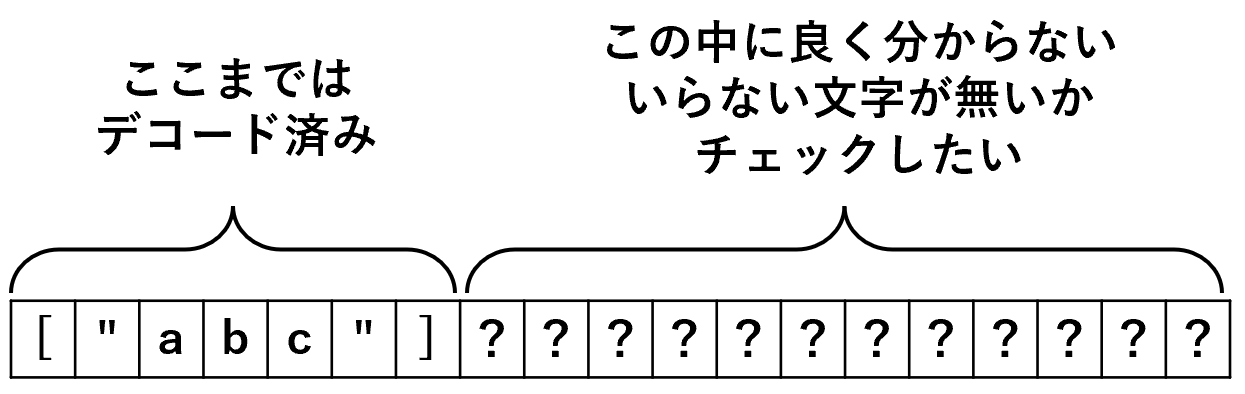 我々がしたいこと
我々がしたいこと
さて、json.Decoder から残りの文字を覗き見る方法は、Buffered() メソッドで io.Reader を取得してから、そのオブジェクトを通して文字を読み出す以外にはない。しかし、Buffered() が返すのはデコーダ内部に持っている []bytes のバッファ(以降内部バッファと呼ぶ)を基にした *bytes.Reader である。内部バッファを基にしたと言うことは、まだ内部バッファに読み込まれていない文字は読みだすことができないと言うことである。そして、残念ながら内部バッファを自在に操る手段は提供されていない。どうしよう、詰んだ…
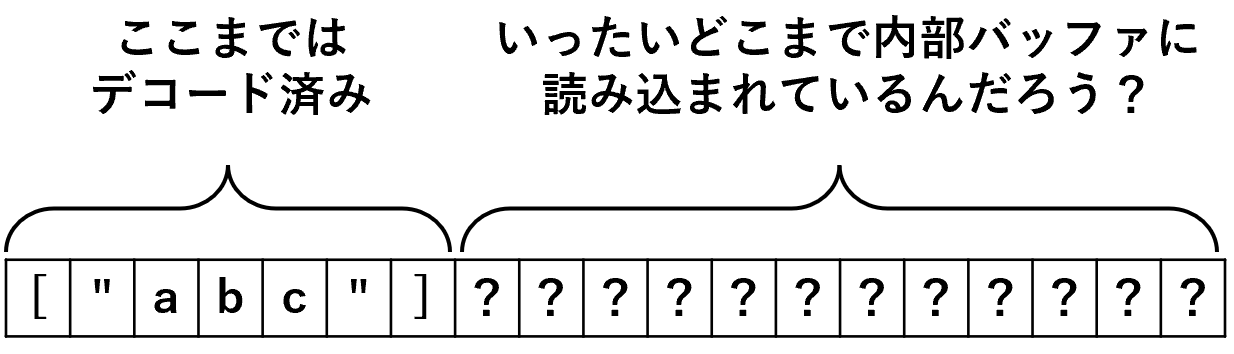 どこまで内部バッファにある?
どこまで内部バッファにある?
そこで唐突に登場する救世主が More() メソッドである。前にも出てきたが More() は本来 Token()とセットで使うものである。ではなぜここで出てきたのだろうか?
ソースコードを読むと分かるが More() の挙動は実はとても単純で、配列やオブジェクトの中かどうかとか関係なく、まだ非空白文字が残っていて、かつその文字が ] か } のいずれでもなければ true、そうでなければ false を返すだけである。しかし、ちょっと考えれば分かる通りこのチェックをするためには、
-
json.Decoderの内部バッファに 1 文字(1 バイト)以上の非空白文字が存在する。 -
json.Decoderの内部バッファには非空白文字が存在せず、かつ、io.Readerはio.EOFである。
のいずれかの状態になっている必要がある。だって io.Reader には Read() メソッドしかないので、中の文字を読みだしてしまうこと無く覗き見ることはできないからね。
 1 のケース(非空白文字がある)
1 のケース(非空白文字がある) 2 のケース(非空白文字が無い)
2 のケース(非空白文字が無い)
あ、絵の中の「△」は空白文字の意味だ、念のため。(空白文字ってよく△で表すよね?表さない?)
したがって、もしまだ非空白文字が残っているのであれば、More() を呼び出した後の json.Decoder の内部バッファに必ず格納されているはずなのである。やった、これで後は Buffered() で io.Reader を取得して非空白文字が無いかをチェックすればいい、目的達成だ!
そして、実は More() には更に「次の非空白文字まで読み飛ばす」と言う副次効果もある。つまり、もし dec.More() を呼んだ後に dec.Buffered() を通して次の文字を読むと、それは(もしあれば)次の非空白文字と言うことになる。
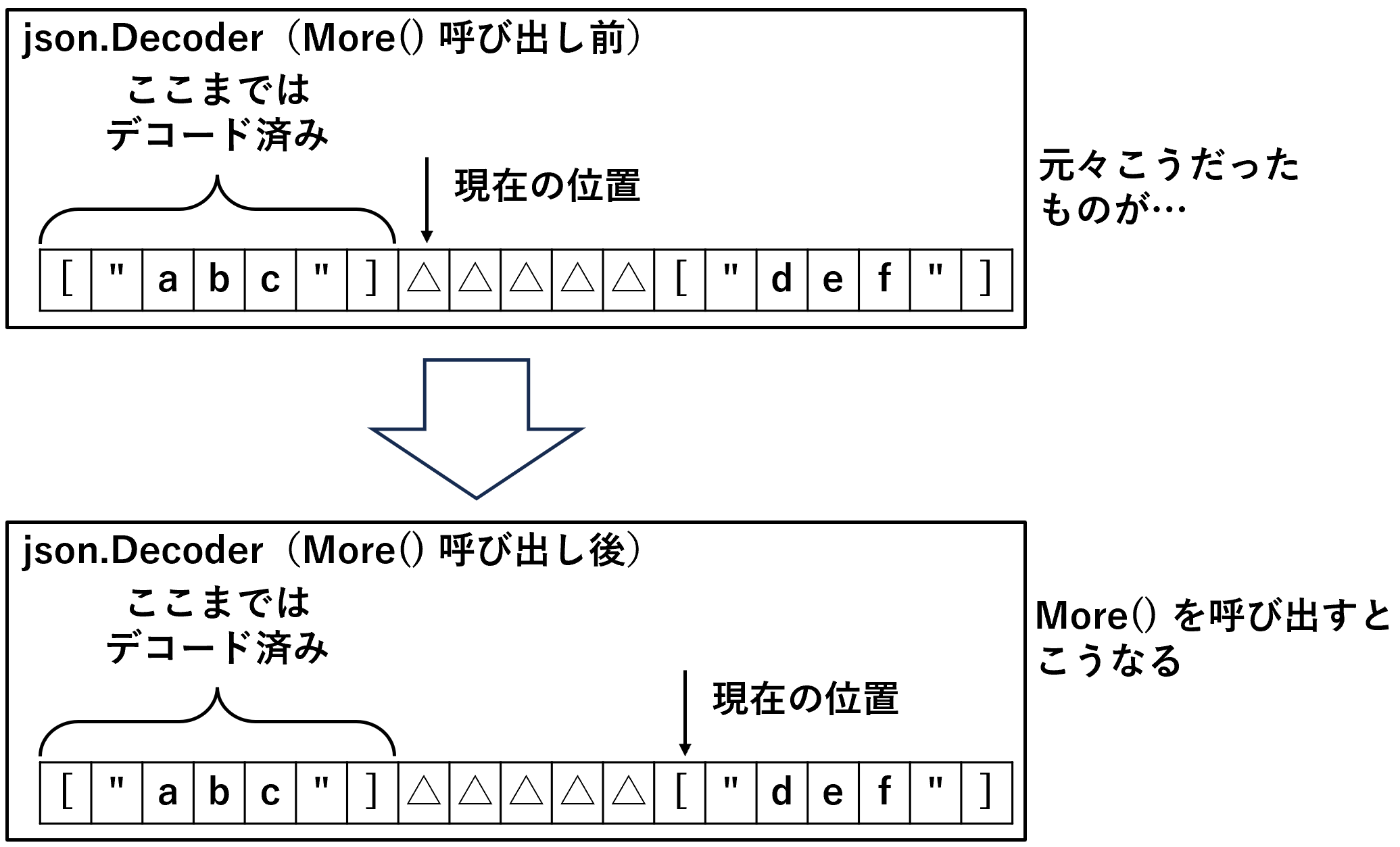 More() の副次効果
More() の副次効果
わざわざ空白文字を読み飛ばす必要がなくなるので、この副次効果も我々にとっては非常に都合が良い。
おまじないその2:dec.Buffered().(*bytes.Reader)
第2のおまじないは dec.Buffered() の戻り値の *bytes.Reader 型へのアサートである。
アサートの結果を何のチェックもせず使用しているが、これは上にも書いた通り、Buffered() が返すのは必ず *bytes.Reader であると分かっているからだ。で、何でわざわざ *bytes.Reader 型にアサートしてるかと言えば、単に 1 バイトだけ読むために ReadByte() が使いたいからだ。
ちょっと内部実装に依存し過ぎな気がしないでもないが、どうせその他の部分も内部実装に依存しているので、ここだけ配慮してもなぁ、と思って一番楽な方法を取っている次第だ。もちろん io.ByteReader インタフェースにアサートしてもいいんだが、何となくこの実装が *bytes.Reader 以外になる気がしないので *bytes.Reader をそのまま使っている。
なお、少しでも内部実装への依存度を下げようと思うのであれば、ここは
c, err := bufio.NewReaderSize(dec.Buffered(), 1).ReadByte()
でもいいし、何なら
buf := make([]byte, 1)
_, err := dec.Buffered().Read(buf)
c := buf[0]
とかでもいい。どっちもムダにバッファがアロケートされるが(後者の方が多少効率はいいかな?コード量はちょっとだけ多いけど…)、誤差程度の影響しか無いだろう。
でも、やっぱりこの実装が *bytes.Reader 以外になる気はしないなぁ。(個人の感想です)
おまじないその3:(c == ' ' || c == '\t' || c == '\r' || c == '\n')
第3のおまじないはナゾの条件式である。
これの説明をするにあたって言わなきゃならないことがある。ついさっき More() には「次の非空白文字まで読み飛ばす」と言う副次効果があると言ったな。あれはウソだ。いや、ウソとまでは言えないな。More() の挙動にはちょっとしたワナが仕掛けられている、と言うのが正解か。
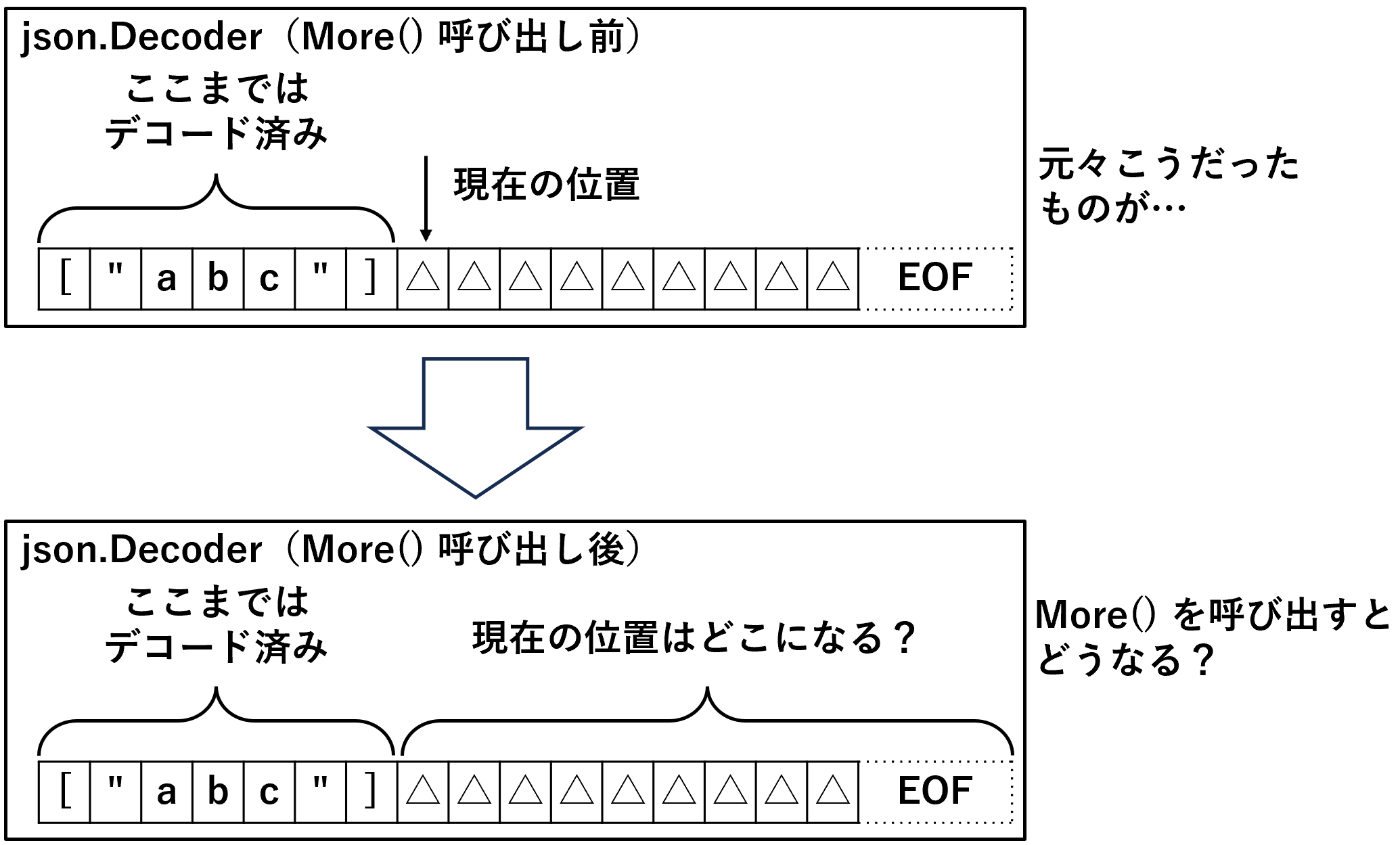
ではここでクイズを出そう。残存文字に空白文字しか残っていなかった場合、dec.More() を呼び出した後の dec.Buffered().(*bytes.Reader).ReadByte() の結果はどうなるだろうか?
 現在の位置はどうなるクイズ
現在の位置はどうなるクイズ
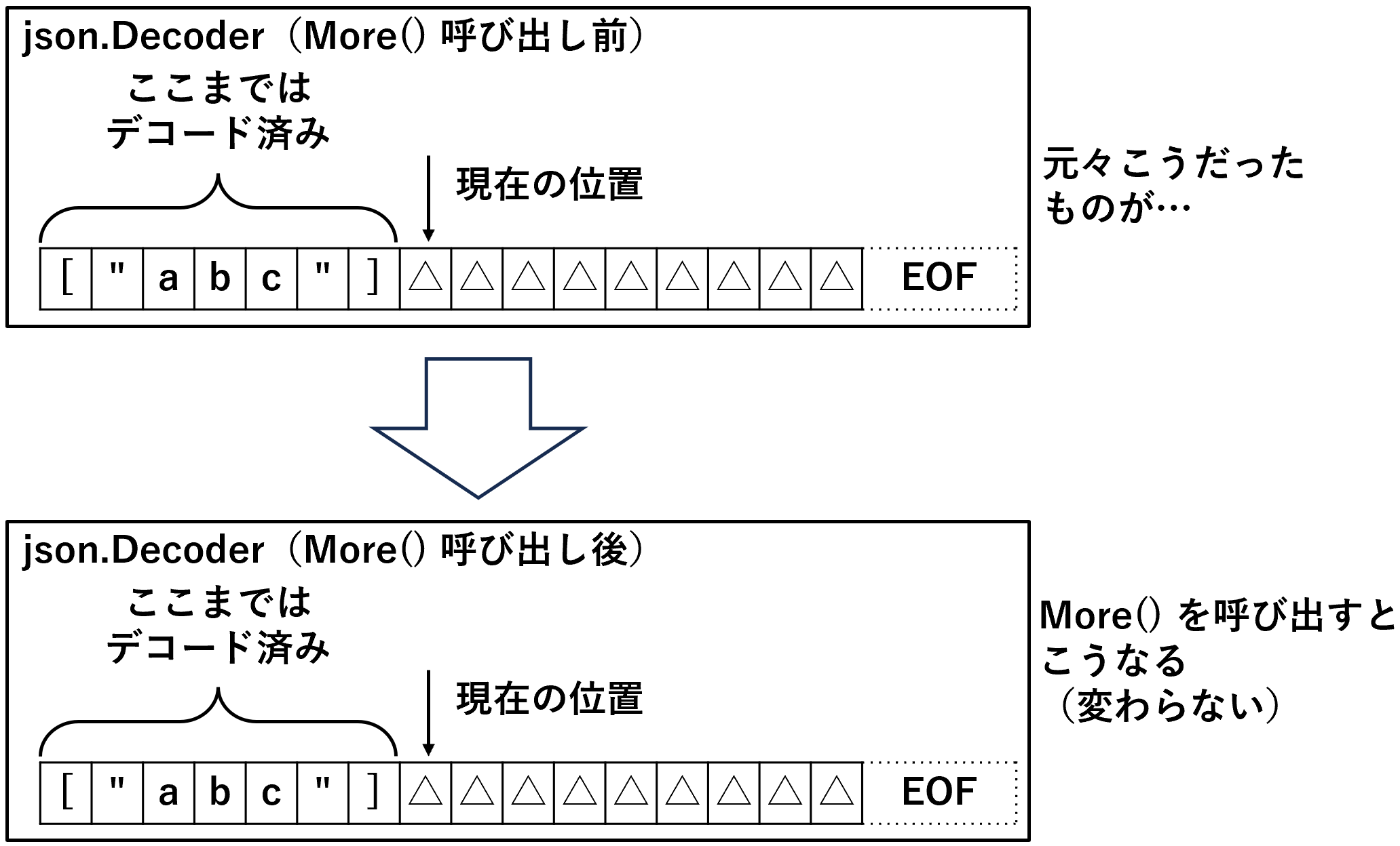
答えは「残っている先頭の空白文字を返す」である。
 現在の位置はどうなるクイズの答え
現在の位置はどうなるクイズの答え
んなアホな!?何で空白文字を飛ばして io.EOF を返さんのや!?
何でそうなっているのかは良く分からない。そうする積極的な理由はソースコードからは読み取れなかったのだが、実際そうなってしまっているのだから仕方ない。(空白文字を飛ばした方が余分な空白文字をバッファリングしなくて済むので効率いいと思うんだけどね…)
つまり、ReadByte() でエラーが出なかった(err == nil)、すなわち文字が残っている場合でも、読みだした文字が空白文字(c == ' ' || c == '\t' || c == '\r' || c == '\n')の場合には、実際には非空白文字は1文字たりとも残っていないのだ。
と言う訳で、後ろに非空白文字が残っていない条件としては、err == io.EOF だけではなく、(c == ' ' || c == '\t' || c == '\r' || c == '\n') もチェックする必要があるのだ。
ところで、本来ならここに err == nil && も必要じゃないの?と思った人もいるのではないだろうか。だかここは敢えて付けていないのである。理由は単純で、*bytes.Reader の ReadByte() は io.EOF 以外のエラーは返さないからだ。
まぁここも「実装が変わったら何か他のエラーが返って来るようになるかもしれないじゃん」とか言うのであれば、他のエラーもハンドリングすれば良い。
でも、やっぱりこの実装が *bytes.Reader 以外になる気はしないし、*bytes.Reader の ReadByte() が io.EOF 以外のエラーは返すようになるとも思えないなぁ。(個人の感想です)
ところで ReadByte() じゃなくて ReadRune() 使った方がいいんじゃないの?
なんて思った人もいるかもしれない。大丈夫だ、問題ない。
そもそも More() 呼び出し後のデコーダの内部バッファには非空白文字の先頭 1 バイトしか入っていない可能性があるので、ReadRune() を呼んでも正しい rune を得ることができるとは限らないのだ。
いやいや、やっぱりそれって大丈夫じゃないんじゃね?と思われるかもしれない。安心してください、履いてますよjson.Unmarshal() も同じですよ。
例えば入力データが {"abc":"def"}𩸽 だった場合、それぞれ以下のような結果となる。
エラー発生:&json.SyntaxError{msg:"invalid character 'ð' after top-level value", Offset:14}
余分な文字発見:'ð', 位置:13
ほら一緒。
いやいや、ð なんて入力してねぇし、𩸽 だし。と言っても実は何のことは無い。𩸽 は utf-8 で f0 a9 b8 bd なので、1 バイト目の f0 を Rune と解釈して出力しているだけだ。
そもそも正しい json の「地の部分」には ASCII の範囲の文字(U+0000~U+007F)しか出てこないはずなので、あんまり気にしてもしょうがない。気楽にいこうじゃないか。
ちなみに、Offset と 位置 が 1 つずれてるのは、json.Unmarshal() は ð を読んだ後の InputOffset() なのに対して、「複数入力 NG 後続文字チェック」は ð を読む前の InputOffset() だからだ。(Buffered() で取得した io.Reader からいくら文字を読んでも json.Decoder の内部位置は影響を受けないので)
そんなに大変ならもう json.Unmarshal() 使えばいんじゃね?
オレもそう思う。なので、後ろにいらん文字がある場合はエラーにしたくて、かつ、json.Decoder にしかない他の機能を使わないのであれば json.Unmarshal() を使っておけば良いんじゃないかな。
と言う訳で、入力は io.Reader 型なんだけど json.Unmarshal() を使いたい場合はio.ReadAll() で根こそぎ []byte に読んでやればよい。
// 手元には io.Reader しかないと思ってくれ…
r := strings.NewReader(`{"abc":"def"}`)
var m any
// 一旦全部読み込んでからデコードする
if b, err := io.ReadAll(r); err != nil {
fmt.Printf("読み込みエラー発生:%#v\n", err)
} else if err := json.Unmarshal(b, &m); err != nil {
fmt.Printf("デコードエラー発生:%#v\n", err)
} else {
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
}
ほら、単純明快でしょ?
ここで「あれ?」と思った人もいるだろう。他の機能を使いたいわけじゃないけど「入力がそもそも io.Reader 型の場合」は json.Decoder を使った方がいいんじゃないの?と。
そんな人は是非この記事の最後にある「入力が io.Reader 型だったらホントに json.Decoder を使った方がいいのか?」も見て欲しい。
json.Decoder はオブジェクトの知らないキーをエラーにできる
これは多くの人がよく知っていると思うが、json.Decoder では知らないキー(構造体に対応するフィールドが無いキー)をエラーにすることができる。
json.Unmarshal では無視される
json.Unmarshal() では、構造体に対応するフィールドが無いオブジェクトのキーは単に無視される。
type Character struct {
Name string
Age int64
}
s := `{
"name": "フリーレン",
"age": 1000,
"pastime": "魔法集め"
}`
var m Character
if err := json.Unmarshal([]byte(s), &m); err != nil {
fmt.Printf("エラー発生:%#v\n", err)
} else {
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
}
デコード結果:main.Character, {Name:フリーレン Age:1000}
見ての通り、特にエラーが出ずに単に無視されていることが分かる。
そして、json.Unmarshal() ではこの挙動を変更することはできない。
json.Decoder はデフォルト無視するが、エラーにもできる
json.Decoder でも、デフォルトでは構造体に対応するフィールドが無いオブジェクトのキーは単に無視されるが、DisallowUnknownFields() メソッドを使用することでエラーにすることもできる。
type Character struct {
Name string
Age int64
}
s := `{
"name": "フリーレン",
"age": 1000,
"pastime": "魔法集め"
}`
dec := json.NewDecoder(strings.NewReader(s))
dec.DisallowUnknownFields() // <- NEW! 知らないキーはエラーにする
var m Character
if err := dec.Decode(&m); err != nil {
fmt.Printf("エラー発生:%#v\n", err)
} else {
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
}
エラー発生:&errors.errorString{s:"json: unknown field \"pastime\""}
json.Unmarshal() や json.Decoder デフォルトの無視する挙動が望ましい場合もあるが、キーのスペルミスがあっても検出されなかったりするので、ナゾのキーをエラーにしたいこともあるだろう。その場合 json.Unmarshal() では対応できないので json.Decoder を使う必要がある。
なお、一度 DisallowUnknownFields() を呼んでしまうとその json.Decoder をデフォルトの挙動(知らないキーを無視する)に戻すことはできないので注意。
知らないキーでも後ろにゴミがあってもエラーにしたい
知らないキーがあったらエラーにしたいので json.Decoder を使わざるを得ないけど、json 値の後ろにゴミがあってもやっぱりエラーにしたい、と言う場合には「json.Decoder でも 1 個じゃなかったらエラーにしたい場合」にあるような対応をする必要がある。(もちろん最後の手段は使えない)
が、もし元の入力が string や []byte なのであれば、以下のような方法もある。
type Character struct {
Name string
Age int64
Pastime string
}
s := `{
"name": "フリーレン",
"age": 1000,
"pastime": "魔法集め"
}` + " ゴミゴミ "
dec := json.NewDecoder(strings.NewReader(s))
dec.DisallowUnknownFields()
var m Character
if err := dec.Decode(&m); err != nil {
fmt.Printf("エラー発生:%#v\n", err)
} else {
// dec の現在位置を取得する
pos := int(dec.InputOffset())
// 現在位置以降の非空白文字を探す
if idx := regexp.MustCompile("[^ \t\r\n]").FindStringIndex(s[pos:]); idx != nil {
// 非空白文字が見つかったらゴミ
fmt.Printf("ゴミ発見:%q, 位置:%d\n", s[pos+idx[0]:pos+idx[1]], pos+idx[0])
} else {
// 非空白文字が見つからなかったら OK
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
}
}
ゴミ発見:"ゴ", 位置:91
要は json.Decoder の現在位置以降に非空白文字があれば、それはゴミだと言う訳だ。
ところで、上記のコードは入力が string だった場合で書かれているが、そうでなくても例えば入力が単なる io.Reader じゃなくて io.ReadSeeker だったりすれば同様のことは可能だ。
つまり、json.Decoder を通して次の文字を取得しなくても大本の入力ソースから次の文字を取得できるのであればゴミがあるか否かの判断ができると言うわけだ。(現在の位置は InputOffset() で取得できるので)
だから、json.Decoder の内部実装には依存したくないけどちゃんとした(?)エラーを出力したい、と言うのであればその方がいいかもしれない。(でも string や []byte 以外だとそれなりに面倒ではあると思う)
json.Decoder は数値を json.Number 型で受け取れる
これはあまり知られていないかもしれないし、何ならあまり使い道がないかもしれない数値の扱いについてだ。
json.Unmarshal では float64 になる
3.1415926535897932384626433832795 と言う入力を json.Unmarshal() に食わすと以下のような結果になる。
s := `3.1415926535897932384626433832795`
var m any
_ = json.Unmarshal([]byte(s), &m)
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
デコード結果:float64, 3.141592653589793
float64 になっているので、途中でブチ切れているのが分かる。
そして、json.Unmarshal() ではこの挙動を変更することはできない。
json.Decoder はデフォルト float64 だが json.Number にもできる
json.Decoder でもデフォルトは float64 になるので何もしなければ同じ結果になるが、UseNumber() メソッドを使用することで json.Number にすることができる。
s := `3.1415926535897932384626433832795`
r := strings.NewReader(s)
dec := json.NewDecoder(r)
dec.UseNumber() // <- NEW! 数値は json.Number で受け取る
var m any
_ = dec.Decode(&m)
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
デコード結果:json.Number, 3.1415926535897932384626433832795
見ての通り json.Number では情報が一切欠落せずに取得できていることが分かる。
json.Number はメソッドを見れば分かる通り残念ながら演算には向いていないが、単に右から左へ受け流すなどの場合にはこちらを使った方が良いかもしれない。
なお、一度 UseNumber() を呼んでしまうとその json.Decoder をデフォルトの挙動(数値を float64 で受け取る)に戻すことはできないので注意。
でも受け取る変数が any 型じゃなかったらどっちでも大丈夫だよ
上記の話はあくまでも受け取る変数(やフィールド)が any 型だった場合の話だ。
json.Unmarshal() であろうと、 UseNumber() を呼んでいない json.Decoder であろうと、受け取る変数(やフィールド)が json.Number 型であれば当然 json.Number で受けられる。
s := `3.1415926535897932384626433832795`
var m json.Number
_ = json.Unmarshal([]byte(s), &m)
fmt.Printf("デコード結果:%T, %+[1]v\n", m)
デコード結果:json.Number, 3.1415926535897932384626433832795
通常 json をデコードする時に any 型で受け取ることはあまりないと思うので、この違いは普段使いでそこまで効いてくる訳ではないかもしれない。
でも Token() は UseNumber() の影響受けるよ
ところで、Token() は Decode() と違って受け取る型を指定できないので、any 型で受けた時と同じように UseNumber() の影響を受ける。
r := strings.NewReader(`3.1415926535897932384626433832795`)
dec := json.NewDecoder(r)
t, _ := dec.Token()
fmt.Printf("トークン:%T, %+[1]v\n", t)
トークン:float64, 3.141592653589793
r := strings.NewReader(`3.1415926535897932384626433832795`)
dec := json.NewDecoder(r)
dec.UseNumber()
t, _ := dec.Token()
fmt.Printf("トークン:%T, %+[1]v\n", t)
トークン:json.Number, 3.1415926535897932384626433832795
Token() を使う時は気を付けよう。
とは言っても、json の数値って普通 float64 なんだよね…
ここまで json.Number 使えば数値を正確に取得できる的なことを書いてきた。しかし、json が定義されているRFC8259には、数値は IEEE-754 の binary64、つまりは float64 の範囲で使うのが無難的なことが書いてあるんだよね。(まぁ当たり前だけど)
だからやっぱり UseNumber()(と json.Number)の出番はあまりないかもしれない…
入力が io.Reader 型だったらホントに json.Decoder を使った方がいいのか?
はじめににも書いたように、入力が文字列(string)やバイト列([]byte)だったら json.Unmarshal()、入力がストリーム(io.Reader)だったら json.Decoder、てな感じで使い分ければいい、とよく見かける。
しかし「json.Decoder は連続した json 値をデコードできる」にも書いたように、この 2 つは json 値の後ろに非空白文字があった際の挙動が異なる。
だから、もし入力は io.Reader 型なんだけど「json 値の後ろに何かいらん文字があったらエラーにしたい」と言うのであれば、「json.Decoder でも 1 個じゃなかったらエラーにしたい場合」に書いたいずれかの方法で対応する必要がある。
そして、個人的には最後の「そんなに大変ならもう json.Unmarshal() 使えばいんじゃね?」に書いた方法をお勧めする。何しろコードが単純明快だからね。
いやいや、入力がせっかく io.Reader 型なんだからわざわざ []byte に根こそぎ読み込まないで済む json.Decoder 使った方が効率いいだろ、と言う声が聞こえてきそうだ。しかし、果たしてホントにそうなのだろうか?
json.Decoder は効率がいい?
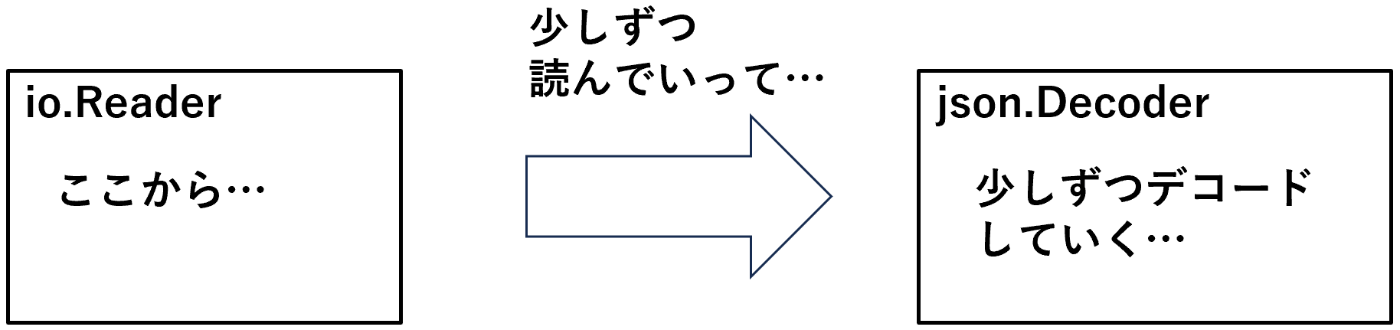
もしかして皆さんは json.Decoder を使うと io.Reader から文字列を少しずつ受け取っては順次デコードしていく、と考えてはいないだろうか?
 json.Decoder のデコードの仕方???
json.Decoder のデコードの仕方???
実はちょっと前までオレもそう思っていた。認めたくないものだな、自分自身の若さゆえの過ちというものを…(これを言う時点で若くも何ともない)
実は json.Decoder で Decode() メソッドを呼ぶと、デコード対象となる json 値の全ての文字を内部バッファに格納するのだ。
 json.Decoder の実際のデコードの仕方
json.Decoder の実際のデコードの仕方
信じられない?それならDecode()のソースコードを読んでみればよい。ウソでないことが分かるはずだ。そしてそんなこと当たり前だと思っていたあなた、あなたは賢くてとても注意深い。
一応 Decode() メソッドのソースコードの主要部分をざっくり解説すると、
-
encoding/json/stream.go:62 のコメントにも
Read whole value into bufferとある通り、まずreadValue()メソッドでデコード対象となるjson値の全ての文字を内部バッファに格納した後、 -
encoding/json/stream.go:67 で
decodeState(デコード中の状態を管理する構造体)のinit()メソッドに内部バッファ(のちょうどデコード対象に当たる部分のスライス)を渡してdecodeStateを初期化し、 - 最後に encoding/json/stream.go:73 で
decodeStateのunmarshal()メソッドを呼び出して根こそぎデコードしている。
と言うことで、json.Decoder が殊更効率がいいって訳では無いことがお分かり頂けたと思う。
あ、ここで言う「効率がいい」と言うのはもっぱらメモリ効率のことを指している。性能については測っていないので何とも言えないが、まぁ両者に大した差は無いんじゃないかな?(勘でモノを言っています)
json.Unmarshal もデコード処理は同じもの
json.Decoder の Decode()メソッドに出てきた decodeState の init() メソッドと unmarshal() メソッドは、json.Unmarshal() でも全く同じように使用されている。つまり、json.Decoder の Decode() と json.Unmarshal() では、デコード処理自体に違いはないと言うことだ。(まぁ当たり前っちゃあ当たり前だよね)
う~ん、だったら json.Unmarshal() でも UseNumber() や DisallowUnknownFields() 相当のことをできるようにしてくれてもいいのに、と思わないでもない。
ちなみに、json.Unmarshal() で呼び出される際に decodeState の init() メソッドに渡される []byte は、json.Unmarshal() に渡した []byte そのものである。つまり json.Decoder のように内部バッファをアロケートして使っている訳では無いので、[]byte が二重にアロケートされてしまうかもといった要らぬ心配は不要だ。
json.Decoder のいいところ:早期エラー検出
もし json.Decoder の Decode() の方が良い点があるとすれば、上記の readValue() メソッドでデコード対象を読み込んでいる最中にエラーを検知した場合、最後まで読み込まずにエラーを検知した時点で直ちに読み込みを中断することぐらいだ。(json 形式としてのエラーは全て読むことなく逐次チェック可能なので)
なので、例えばユーザ入力でクソデカぶっ壊れ json を渡される可能性があるとか、サーバがトチ狂ってクソデカぶっ壊れ json レスポンスを返す可能性があるとか、そういった事象に対する自衛としてであれば json.Decoder の Decode() メソッドを使うことに一定の意義がありそうではある。
なお、ここで言う「ぶっ壊れ json」と言うのはあくまでも「json 形式としてぶっ壊れてる」と言う意味であって、デコード結果を変数やフィールドに格納する時に型が合わないとかフィールドが無い(DisallowUnknownFields() を呼んでる場合)とかいうことではない。
後者のエラーはデータを最後まで読み込んでから発生するので、残念ながら「早期エラー検出」にはならない。
早期エラー検出以外に json.Decoder って使いどころ無いの?
もちろんある。
ここまで散々書いてきたように json.Decoder には json.Unmarshal() では代替できない機能が 4 つあるので、これらの機能に依存するようなことをしたければ、たとえ入力が string や []byte であったとしても json.Decoder 以外の選択肢はない。
逆に言えば、それ以外であれば素直に json.Unmarshal() を使っておいた方が良いんじゃなかろうか。
おまけ:サーバのレスポンスを直接デコードする時の注意点
完全に余談にはなるが、json.Decoder を使用するシチュエーションの例としてよく見かける、サーバのレスポンスを直接デコードするケースについて注意点を挙げておく。
func getJson(url string) (any, error) {
res, err := http.Get(url)
if err != nil {
return nil, err
}
if res.StatusCode != 200 {
return nil, fmt.Errorf("StatusCode:%d", res.StatusCode)
}
dec := json.NewDecoder(res.Body)
var m any
if err := dec.Decode(&m); err != nil {
return nil, err
}
return m, nil
}
「そんなに大変ならもう json.Unmarshal() 使えばいんじゃね?」にも書いたように、個人的なお勧めは io.ReadAll() で根こそぎ []byte に読んでから json.Unmarshal() なんだが(しつこい)、知らないキーはエラーにしたいかもしれないし、早期エラー検出の話もあるし、むしろ後ろに変な文字がくっついててもエラーにしたくないこともあるかもしれないので、ここではやっぱり json.Decoder 使いたいものとしておこう。
それでもこのコードは二つの点で良くない。
- 良くない一つ目はほとんどの人が気付いていると思うが、
res.Bodyをクローズしていないことだ。
ドキュメントにも書いてあるように、レスポンスボディのクローズは利用側の責務であり、クローズしないとリソース枯渇の恐れがあるので忘れないように。 - 良くない二つ目は実は気付いてない人が多いんじゃないかと思っているのだが、
res.Bodyを読み切っていないことだ。
現在の HTTP では通常サーバへのコネクションは使いまわされるが、レスポンスボディを読み切っていないとコネクションをぶった切ってしまうので使いまわすことができない。(これもドキュメントに書いてある)
そしてjson.Decoderは読み込みの最中にjsonの形式的なエラーを検出するとそこで読み込みを中断してしまうし、正常にデコードができてももし後ろにいらん文字列(それは単なる空白文字かもしれないし、今回は敢えて無視したいゴミかもしれない)があるとレスポンスボディとして残ってしまっている可能性がある。
というわけで、ちゃんと読み切ってからクローズするようにしよう。
func getJson(url string) (any, error) {
res, err := http.Get(url)
if err != nil {
return nil, err
}
defer res.Body.Close() <- NEW! 必ずクローズする!
defer io.Copy(io.Discard, res.Body) <- NEW! ゴミは読み捨てる!
if res.StatusCode != 200 {
return nil, fmt.Errorf("StatusCode:%d", res.StatusCode)
}
dec := json.NewDecoder(res.Body)
var m any
if err := dec.Decode(&m); err != nil {
return nil, err
}
return m, nil
}
ところで、こういった場合は無名関数を作って defer を 1 つにまとめた方がいいんですかね?
defer func() {
io.Copy(io.Discard, res.Body)
res.Body.Close()
}()
さいごに
結局 json.Unmarshal と json.Decoder はどちらを使えばいいのか分かりませんでした。いかがでしたか?
json.Unmarshal と json.Decoder には入力形式以外にも機能的な違いがあること、そして、入力形式の違いが必ずしも選択の基準とはならないことをおわかりいただけただろうか。
もしかしたら json.Decoder をディスってるように思われるかもしれないが、それは大いなる誤解だ。記事のタイトルからも分かる通りオレは json.Decoder 大好き鳥頭だ。(特に Token())
適材適所。皆さんがこれらの違いを正しく理解し、より良い選択をできることを願う。
Discussion