リッチテキストエディターはライブラリを活用した方が良い訳
リッチテキストエディター(RTE)触ってますか?
あまり聞き慣れない単語かもですが、意外にも皆さんの身近に沢山あります。
例えば、Notion・Note や はてな などのブログ・CMS などがあります。他にも、意外と普段使ってるサービスのテキスト入力欄が実は RTE だったりします。
これらのサービスは Web 技術の HTML を編集可能にするcontenteditable 属性を付与することで、見た目のまま編集することを可能にしています。
ただ、残念ながらこの属性をそのまま使うと確実に地獄を見ることになるでしょう。
世の中のエディタは contenteditable の辛いところを上手に回避して開発をしているのですが、どのようにしているか気になりませんか?
そこを、本記事では contenteditable の辛さに触れながら、それを解決するリッチテキストエディターの仕組みと使うべき理由について説明します。
結論
ビルトインの文書編集機能は使い物にならず、手軽な変更 API も用意されていません。
そこで、ライブラリはブラウザのデフォルト処理をさせず、カスタマイズ性の高い RTE の操作を実現しています。
この膨大な処理を自前実装するのは手間です。逆にライブラリを使わないと、ビルトインの contenteditable の不可思議な挙動で辛い気持ちになるため、やりたいことが小さくても使用を推奨しています。
contenteditable とはそもそも何か?
contenteditable は端的に説明すると、HTML 要素を編集可能としてみなす属性です。
contenteditable がない世界だと、基本的には入力可能エリアが input と textarea ぐらいしかありません。
これらの要素は、通常の文字の羅列を書くことしかできません。見出し・ハイライト・リスト ... といった、リッチなコンテンツは含めることが不可能です。
使い方はこのようになります。
<blockquote contenteditable="true">
<p>このコンテンツを編集して、自分自身で引用を追加してください。</p>
</blockquote>
親要素に contenteditable="true" を追加すると、子要素が全て編集可能になります。
ユーザー操作によるドキュメントの更新操作、選択範囲と表示がブラウザ毎に実装されています。
RTE に求められること
contenteditable を使って RTE の開発をするのですが、そもそも RTE はどのような要素で構成されているのか?仮に1から開発をする上で考えるべき観点をまとめます。
状態
- DOM構造
- 選択範囲(開始位置と終了位置)
モデル
- 構造定義(a タグの中には form を入れられないなど)
- DOM位置
編集操作
- 選択範囲にDOMの挿入・置換・削除
- 選択範囲の更新
インターフェース
- DOM の表示
- キャレット・選択範囲の表示
- 入力受付(キー入力・クリック・ドラッグ・ホバー....)
簡単に説明すると、文書を表す DOM と選択範囲を状態に持ち、その文書に対する編集操作を別途持つイメージです。そして、その文書と選択範囲をユーザーが確認するために描画の責任も持ちます。
例えば、段落と見出しとテキストのみのエディタについて考えてみます。以下のようなイメージです。
<div contenteditable="true">
<h2>One</h2>
<p>Two</p>
</div>
モデル
トップレベルに見出しと段落を持ち、各々の子要素にテキストノードのみを含むことができます。
利便性のため、DOM の位置に一意の番号を割り当てます。
<h2> の外側を 0 で、タグとテキストを跨ぐとカウント +1 にします。
0 1 2 3 4 5 6 7 8 9 10
<h2> O n e </h2> <p> T w o </p>
状態
DOM 構造と位置番号の選択範囲を持ち、編集操作がされるたびに更新されます。
編集操作
ユーザー入力とは切り離して考えます。挿入・削除・選択範囲の置換は、全て置換操作で捉えられます。置換関数をReplace(from, to, DOM)と定義すると、
-
3 番に「a」を挿入 ➡️
Replace(3, 3, "a") -
1 番と 2 番にある「O」を削除 ➡️
Replace(1, 2, "") -
先頭
<p>Zero</p>を追加 ➡️Replace(0, 0, Paragraph("Zero"))
複雑な例だと
-
3 番 - 7 番を削除して見出しと段落を結合 ➡️
Replace(3, 7, "")-
e</h2><p>Tの構造が削除され<h2>Onwo</p>が残る -
見出しと段落はテキストノードのみを含むため結合可能
-
開始タグを優先して
<h2>Onwo</h2>にする
-
-
7 の位置で段落を分割したい ➡️
Replace(7, 7, "</p><p>")-
終了タグと開始タグという特殊な HTML を挿入することで実現
-
<h2>One</h2><p>T</p><p>wo</p>になる
-
このように操作を表せます。選択範囲はユーザー操作を元に、移動先の番号を指定しましょう。
インターフェース
DOM の表示は、通常のレンダリングと同じです。
次に考える DOM 位置と表示位置のマッピングは曲者です。
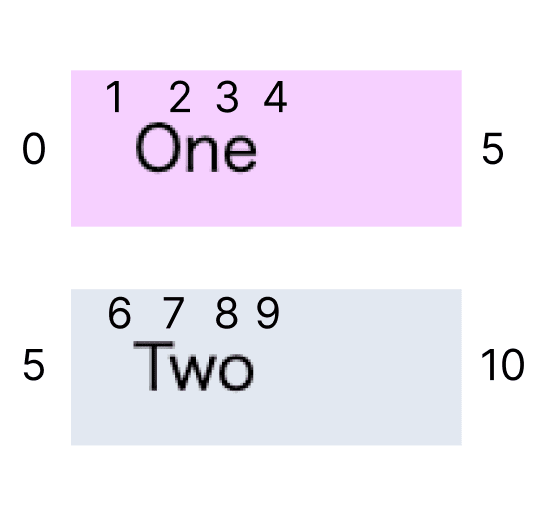
DOM 位置と表示のマッピング
上の画像はタグに背景色をつけてレンダリングしてみました。
例えば、5 番のように DOM での位置が表示上では複数の可能性を持つものがあります。
これは、h2 と p が CSS でブロック要素であることが起因しています。逆にインライン要素だと見た目上の位置が同じになるので、場合分けが必要です。
また、一見だと全番号を選択可能のように見えますが、背景色が見えない状態だとどうでしょう?
4 番で右矢印キーを押した時に、見えない何かの 5 番に飛ぶとユーザーが困らないでしょうか?
意図的には、6 番の T の前に移動して欲しいはずです。
このように、RTE は起こりうる挙動を想定して実装していくことになります。
標準の contenteditable の辛さ
現在は細かな挙動の仕様がなく[1]、標準の contenteditable はブラウザ毎に上記で説明した実装を任されています。
そして、我々に提供されているのはインターフェースのみです。
ユーザーのキー入力・マウス操作などの情報をもとに、内部のモデルと編集操作で次の構造が決定されます。悪く言えば、デフォルトの編集操作を変えるのが困難です。
辛いところの1つに、モデル定義があります。
現実では特定のモデルという制限を加えた中で DOM の編集をしたいですが、このデフォルトの挙動が牙を向きます。
例えば、前章で定義したモデルで <p> の中に <img /> をペーストするとどうなるでしょう?
本来はモデルとして不正ですが、デフォルトだとあっさり許可してしまいます。特定のモデルの中にこの構造のみ許可する。。。といったことは、DOM 構造を都度確認して判定する必要があります。
Enter で見出しを改行するという挙動はどうでしょうか?
段落の分割という操作をしたいのですが、分割先の要素を<h2> <p> <div> のどれか?などパターンがあります。
今回定義したモデルだと<p> になって欲しいのですが、悲しいことにデフォルトだと<div /> になります。そして、この要素を変える API は提供されていません。Enter が押されたら、今の位置を確認して。。。。と、泥臭い実装が求められます。
このようにモデル定義が困難なため、無限にあるパターンを 1 つ 1 つ判定して実装する必要性があります。先が見えない作業です。
さらにブラウザによって挙動が異なることもある追い打ちもあります。
さらにさらに、DOM を自前で操作しようとすると、キャレットの位置も自前で保存・移動することを求められます。。。
結局やりたいことを実現するために、ブラウザの挙動に任せたくないという方向に進みます。
調べてみると、他にも辛い思いをしてきた方々がいるので、一読してみることをお勧めします。
戦った・しんどい・使えない など、ネガティブなワードが目立ちます。
RTE ライブラリの解決策
RTE ライブラリは物にもよりますが、ブラウザに任せず構造と状態、編集操作を全て自前定義しよう!という発想です。
contenteditable を DOM とキャレット表示のみに制限し、モデル定義・状態・編集操作・入出力のインターフェースは全て自前で実装します。つまり、何かキー入力をするたびに、自前定義したモデルへの編集操作へと変換し、差分を都度 DOM に反映します。仮想 DOM みたいですね。
最近の代表的なところだと、ProseMirror や Lexical があります。
ProseMirror のデータフローは以下のようになります。
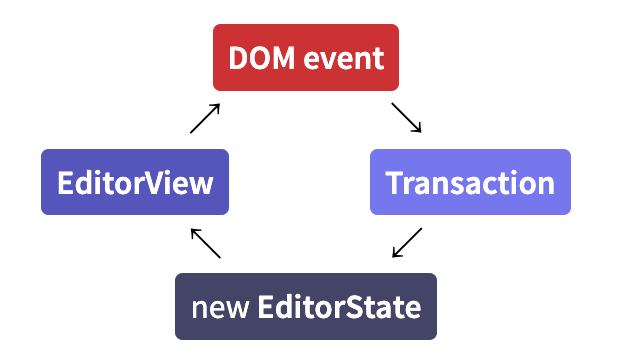
ProseMirror のデータフロー
EditorView がインターフェースになっており、DOM Event を編集操作である Transaction に変換しています。EditorState は Transaction のみによって変更可能で、都度 EditorView (DOM) に反映するフローです。
EditorState にはモデルの構造と選択範囲を持ちます。
EditorView 関連の処理はprosemirror-view にまとまっています。
下は DOM event の keydown ハンドラーを定義した箇所です。
IME のコンポジション状態とブラウザ仕様の違いを考慮しながら、入力されたキーをキャプチャーしています。
130 行目の captureKeyDown の中で、次の移動先の決定やテキスト追加をトランザクションにして反映しています。
他のイベントハンドラーも同様に定義していました。
ブラウザ毎にイベントの順番が異なることもここで抽象化されているため、利用者はブラウザの差異を考慮する必要がなくなります。
さいごに
このように、RTE のライブラリは contenteditable の辛いところを切り出してくれているため、小さな入力ボックスでもライブラリを使うべきだと考えています。
contenteditable な入力欄を開発するときの参考になれば幸いです。
この記事を執筆することでエディターの内部構造と編集操作に対する理解が深まりました。
執筆駆動調査、アリかもしれない。
Discussion