マイク入力をWhisperで音声認識

Whisperを試す
Whisperの音声認識が優秀ということで、マイクで試せるようにしてみました。
別に無理して使う必要なかったのですが、諸事上によりDockerを使ってマイクがつながったアプリとソケット通信したりしています。以下みたいな感じです。
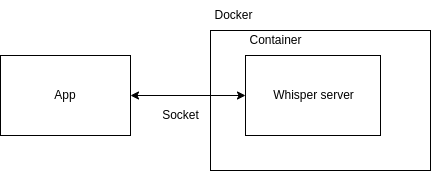
リポジトリは以下です。
ほとんど自分のためのメモですが、同じようなことしたい人がいるかもしれないので、簡単に説明を書いておきます。
説明はちょい雑です(すみません)。今後追記したり補足するかも…です。
セットアップ方法
Linux(Ubuntu)前提です。Windows(WSL2)でも多分動くと思います。
マイク
マイクは適当なUSBマイクをつなげてください。以下でデバイスを確認できます。
$ arecord -l
自分の環境での結果です。
**** ハードウェアデバイス CAPTURE のリスト ****
カード 0: Device [USB PnP Audio Device], デバイス 0: USB Audio [USB Audio]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
カード 1: UCAMC0220F [UCAM-C0220F], デバイス 0: USB Audio [USB Audio]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
カード 2: PCH [HDA Intel PCH], デバイス 0: ALC897 Analog [ALC897 Analog]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
カード 2: PCH [HDA Intel PCH], デバイス 2: ALC897 Alt Analog [ALC897 Alt Analog]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
音量を以下のような感じで調整しましょう。数字はデバイスに合わせて変更してください。
$ amixer sset Mic 50 -c 0
マイクの録音テストをしてみましょう。以下コマンドでtest.wavというファイルに音声が保存できます。plughw:0,0の0,0はカード ID, デバイス IDです。
$ arecord -D plughw:0,0 -r 16000 -f S16_LE test.wav
Docker
Dockerをインストールしましょう。以下記事参考にしてみてください。
GPUが不要ならとりあえず以下コマンド実行すればOKです。
$ curl -s https://raw.githubusercontent.com/karaage0703/ubuntu-setup/master/install-docker.sh | /bin/bash
$ git clone https://github.com/karaage0703/whisper-docker
$ cd whisper-docker
$ docker build -t whisper .
使い方
whisper-dockerディレクトリで以下実行します。
$ docker run -it -d -v $(pwd):/workspace/ --net host --name whisper whisper
$ docker exec -it whisper bash
root@hostname:/workspace# python whisper-server.py
以下でマイク入力を認識するアプリを実行できます。
$ python mic.py
実行結果です。
アプリは日本語専用ですが、Whisper自体は、英訳したり、言語を自動検出したりできます。コードを好きにいじって活用してみると良いと思います。
Google Colabで使う方法
マイクからGoogle Colabで使う方法もあります。以下のNotebook参照ください。
音声ファイルから文字起こしする方法
以下記事参照ください。
まとめ
Whisperを試してみました。大きいモデルを使って長文だとかなりの性能が出るようですが、小さいモデルで短文だと、間違えもある程度ありそうな感触です。
ただ、今までのオープンな音声認識ライブラリと比べると格段の性能の進化がありそうです。エッジで音声認識使えると、いろいろ遊べそうですね。
参考リンク
まだ試せていませんが、リアルタイムに認識できそうなソフトもあるようです。
【AIで字幕作成】Whisperで字幕の文字起こしをするWebアプリを作ってみた【コード付き】
Whisperより4倍速いらしいです。まだ試せていません
変更履歴
- 2023/05/26 文字起こしのリンク追記
Discussion