プロンプトエンジニアリング テクニックまとめ
プロンプトエンジニアリング
Large Language Model(以降LLM)のプロンプトエンジニアリング、色々テクニックがあるのですが、全然名前と内容が一致しないので一度自分なりにまとめてみることにしました。
そもそも、LLMOps:基盤モデルに基づくアプリケーション開発のワークフローによると、LLMの開発には以下の3つのアプローチがあるとのことです。

LLMOps:基盤モデルに基づくアプリケーション開発のワークフローより引用
本記事ではその中の、In-Context Learningについて(要は、プロンプトを工夫してなんとかしましょうというアプローチ)のみ記載します。そして、更にIn-Context Learningを、この記事の内容で分類した図を以下に示します。

ここで出てくるIn-Context Learningのテクニック、結構名前がカッコいいというか、仰々しいんですよね。「Zero-Shotのゼロってどういうこと?(何もしないの??)」とか「Learningとかついているけど、実際は学習してないじゃん!」など、よくわからなくなってしまうこと多いなと思っていたら、fukabori.fmという音声配信番組の97回目のエピソードでも同じようなことが語られてました。自分だけじゃなくて安心しました。この記事では、音声配信に出てくる内容の中でも、基本的な一部に関して紹介しています。
また、取り上げるプロンプトのテクニックは、誰かがちょっと試してみた的なオレオレプロンプトではなく、ある程度論文などで再現性が確認されているもの・OpenAIの公式情報で紹介されている情報を中心に、具体例や論文、公式情報と一緒にとりあげていきたいと思います。
In-Context Learning
概要
直訳すると「文脈を学習」でしょうか。よくわかりませんねコンテキストはLLM分野ではかなり広い概念になり、LLMに入力される、モデルがタスクを遂行するために参照・利用可能なあらゆる情報を構造化し、整理した入力データの全体を意味します。そのうえで、In-Context Learningは広い概念で、後のK-ShotとかChain of Thought(CoT)を内包するようなものと理解しています。
Learningと書いてありますが、実際にモデルを学習(ファインチューニングなど)をするわけではなくて、プロンプト内にいくつか具体例(タスク例)を挙げることで、モデルの出力をコントロールしていくプロンプトのテクニックです。
具体例
この後出てくるものは、ほぼ全てIn-Context Learningの範疇となります。
論文
Zero/Few/K-Shot
概要
In-Context Learningのために、プロンプトと一緒に提供されるタスク例の数Kに応じてK-Shotと呼ばれるらしいです。
Zero-Shotってどういうこと?と思ったら、タスク例がなく、単純に指示だけだとZero-Shotになるみたいです。Zero-Shotって何かカッコいいけど、実際は単に指示しているだけというね。
Kがちょっとだけ(多分1〜3くらい)だとFew-Shotらしいです。
Open AIの公式ガイドには、Instructionをプロンプトの最初に書いて、文脈(In-Context)は、"""か###で区切るのが推奨のようです。
具体例
Zero-Shotのプロンプトは以下です。
fried chickenを日本語に訳してください
Few-Shot(K=3)は、以下のように3つ例を挙げたプロンプトになります。
fried chickenを日本語に訳してください。
日本語訳例:"""
apple > りんご
bear > くま
beer > ビール
"""
論文
Chain of Thought(CoT)
概要
思考の連鎖って、なんかかっこいいですね。
プロンプトのタスク例として、論理的思考の過程を記載すると性能が上がるという話みたいです。説明より具体例をみた方が分かりやすいと思います。
具体例
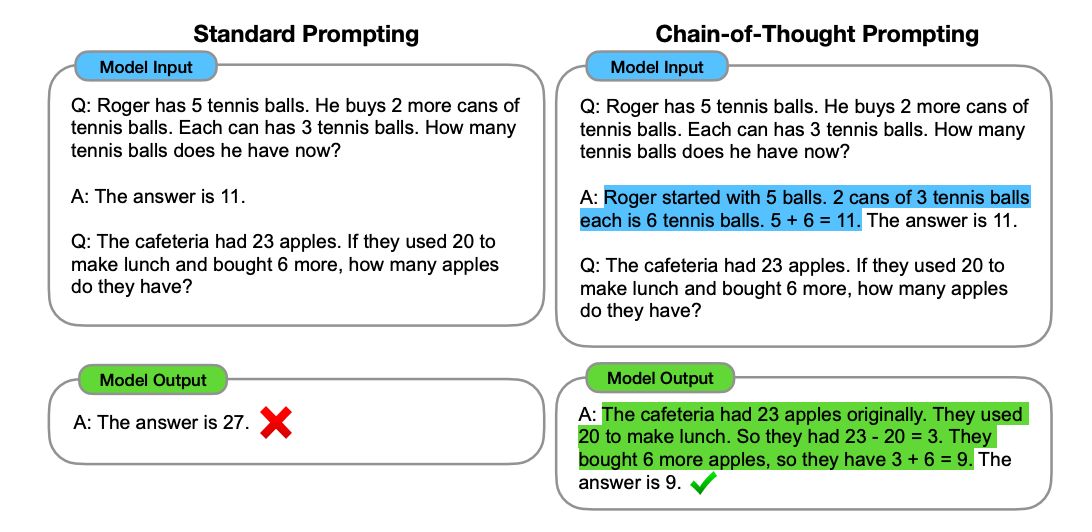
Chain-of-Thought Prompting Elicits Reasoning
in Large Language Modelsより引用
論文
Zero-Shot CoT
概要
プロンプトの最後に「Let’s think step by step.(ステップごとに考えよう)」とつけるだけで、性能が上がるというものです。
それだけ??と思ってしまうのですが、ここでのポイントは、CoTという高度なIn-Context Learningを、タスク例を挙げること無くZero-Shotで実現してしまうという点ですね。
そう捉えると、この「Let’s think step by step.」の発見の凄さが少し分かるのではないでしょうか??
具体例
ほんとに、最後に「Let’s think step by step.」つけてるだけです。

Large Language Models are Zero-Shot Reasonersより引用
論文
外部(実世界)から取得した情報を活用する方法
システムが現実にアクセスする手段を提供することをLLMの分野だと「Grounding」といいます。そのGroundingを活用した手法を紹介します。
ここからは、まだまとめきれてないので、簡単に紹介します。
Retrieval-Augmented Generation(RAG)
情報をベクトル化(Embedding)して、プロンプトで検索して、距離が近い文章をプロンプトと一緒に投げる手法です。In-Context LearningのIn-Contextを外部からひっぱってくることですね。
実際にやってみた例が以下となります。
参考情報
ReAct
外部のサービスから必要な情報をLLMが取得する方法です。
参考情報
Recursively Criticizes and Improves(RCI)
LLMの出力をLLM自身で確認して修正する方法です。いわゆるエージェントと環境の相互作用で生まれる情報を活用しているわけで、これもGroundingの一種ではないかと自分は思っています(あんまりそういう文脈で語られていない気がするので、ちょっと自信ないです。
Code Interpreterがエラーを自分で修正してくのも、このRCIを使っているのかと思います。
参考情報
Self-Consistency
概要
名前を聞くと難しそうですが、要は多数決です。何回か推論させて、一番多いものを選ぶという手法です。
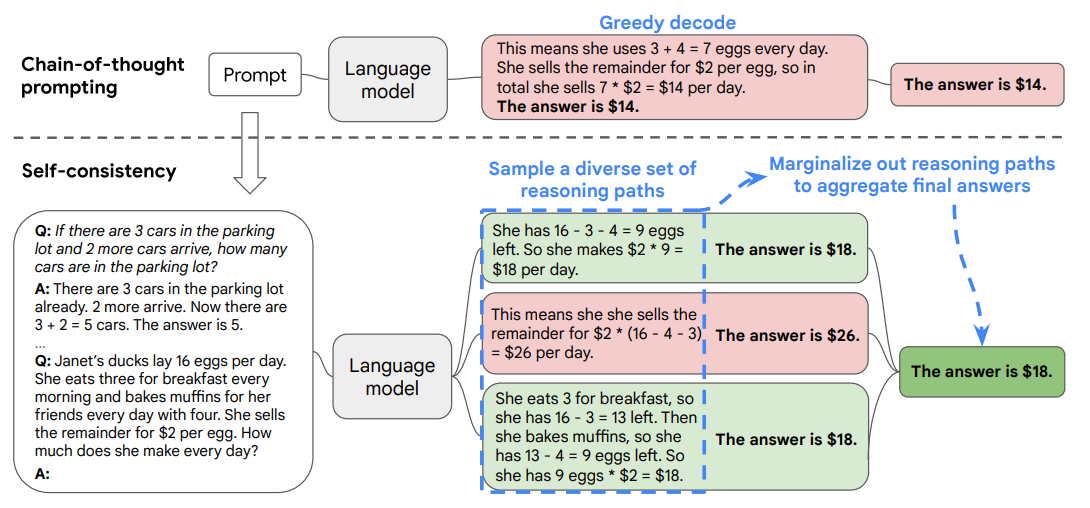
Self-Consistency Improves Chain of Thought Reasoning in Language Models より引用
論文
プロンプトインジェクション
プロンプトを使った攻撃(ハック)に関してです。以下にまとめました。
LLMのプロンプトエンジニアリング(書籍)
プロンプトエンジニアリングで参考になる本です。この本で初めて知った、ちょっと面白かった概念を紹介します。
赤ずきんの原則
赤ずきんの原則とは、LLM(大規模言語モデル)がトレーニングされた「道(=トレーニングデータ)」から外れないようにすることを指します
童話の「赤ずきん」の物語にたとえられています。物語の中で、無邪気な少女は母親に「道を外れないように」と厳しく注意されますが、道から逸れて狼に出会い、悲惨な結末を迎えます。プロンプト作成においても、モデルがトレーニングデータのパターンという「道」から外れないようにしないと、期待通りの結果が得られない可能性があるという比喩です。
チェーホフの銃の誤謬
プロンプトに無関係なコンテキストが含まれている場合、LLMがそれを重要な情報であると解釈しようとしてしまう現象をいうらしいです。この誤謬は、劇作家アントン・チェーホフの物語における不要な要素を排除すべきであるという考え方から来ているそうです。
「第一幕で壁に銃を掛けるのであれば、次の幕でそれを撃たなければならない。もしそうでないのなら、最初からそこに掛けるべきではない」
チェーホフの銃 より引用
まとめ
プロンプトのテクニック、色々あるので、網羅的にまとめようと思ったのですが、In-Context Learning周りの代表的なものだけで限界でした。またここに追記するか、別記事で別観点でまとめてみたいと思います。
もっと知りたい方は、参考リンクあたりをみていただけたら幸いです。あと、間違いに気づかれた方はそっと優しく教えていただけると嬉しいです。
参考リンク
ガイド
プロンプト集
OpenAI
Google Gemini用のプロンプト集
Googleが学校の教員のための公開しているプロンプト集「学校のためのプロンプトライブラリ」
Anthropic
Microsoft
その他
デジタル庁のプロンプト集
システムプロンプト集
論文
ツール
関連記事
変更履歴
- 2025/08/12 In-Context Learningについて修正
- 2025/05/25 LLMのプロンプトエンジニアリングの書籍について追記
- 2025/04/13 Self-Consistencyを修正
- 2024/07/01 プロンプト集追記
- 2023/07/27 Self-Consistency、Groundingに関して追記
- 2023/07/18 全体感を追記
Discussion
興味深い記事をありがとうございます
個人的に大量のLLM系の論文を表形式にまとめています
この表に載っていないおすすめの論文があれば教えてください