LLMでマリオをプレイ「Large Language Mario」を作って試してみました

LLMのチャット以外の可能性
ChatGPTなどで話題のLLM(Large Language Model)、用途としてはチャットボットとしての使われ方が多いですが、チャット以外にも使える可能性を秘めています。
具体的には、生成AIでロボット制御をする「RT-1」や、マインクラフトをプレイする「Voyager」などがあります。これらの詳細の解説は以下記事参照ください。
今回は、夏休みの自由研究(と呼べるほど高尚なものではないですが)として、手軽に分かりやすい例として、LLMでマリオをプレイできるか試してみることにしました。
LLMでマリオをプレイ
マリオに関しては、以前に深層強化学習で全ステージクリアにチャレンジしたことがあります。
複数人の有志の協力があり、ループを多用する8-4を除いたステージを全てクリアすることができました。ただ、ステージごとにシミュレータで半日以上かけて学習させる必要があり、ステージによっては職人芸的な報酬設計やハイパーパラメータ調整をする必要がありました。
ここで、LLMは膨大な量のデータを学習していて、ある程度マリオのことを理解している可能性があります。そうであれば、こういった学習無しである程度マリオがプレイできてしまうのではないか?という仮説に基づき、LLMにマリオをプレイさせてみることにしました。名付けてLarge Language Marioです。
LLMでマリオをプレイさせる方法
Google Colaboratory(Google Colab)でLarge Language Marioを作ってみました。
強化学習のときと同様、OpenAI Gymを使っています。マリオの強化学習に関しては、PyTorchの公式チュートリアルの強化学習の箇所を参考にしています(この箇所に関しては、日本語訳に対して少し協力しています)。
強化学習では、一般的に以下のように、エージェントが環境の状態(State)と報酬(Reward)をもとに、行動(Action)をするということを繰り返す、エージェントと環境が相互作用するシステムで行われます。OpenAI Gymのインターフェースもこのようになっています。
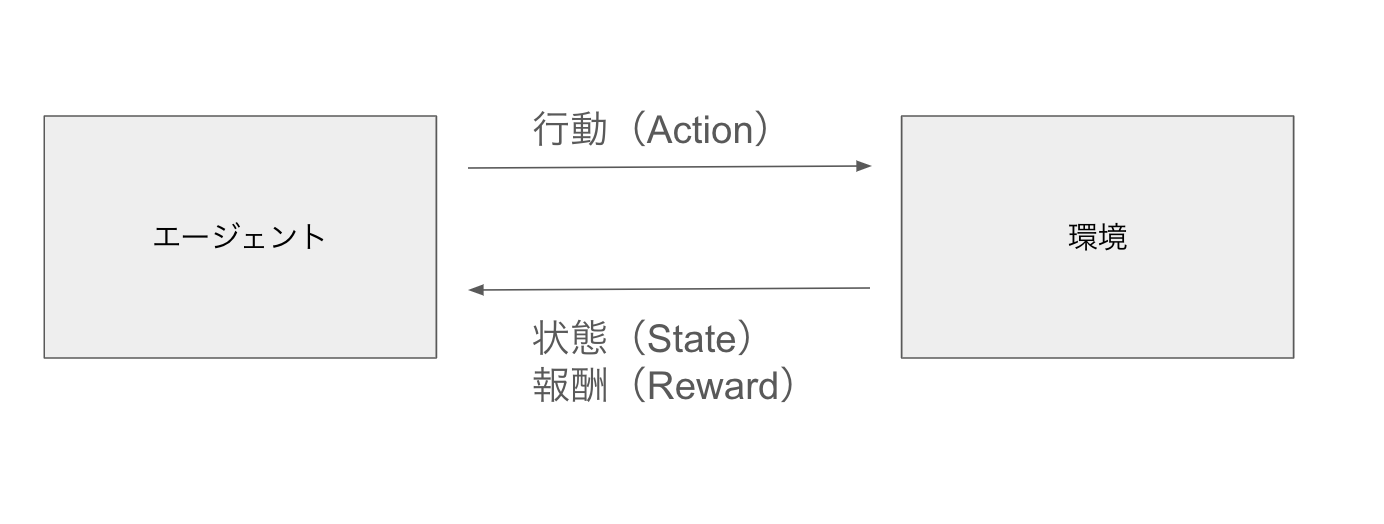
今回も、この仕組みにのっとり、OpenAI Gym上で取得した環境の状態(今回は、状態はマリオのプレイ画像になります)をエージェント(GPT-4o)に読み込ませて、GPT-4oにとるべきアクションを回答させます。あとは、そのアクションをOpenAI Gym上で実行するだけです。これを繰り返すことでLLMがマリオをプレイします。
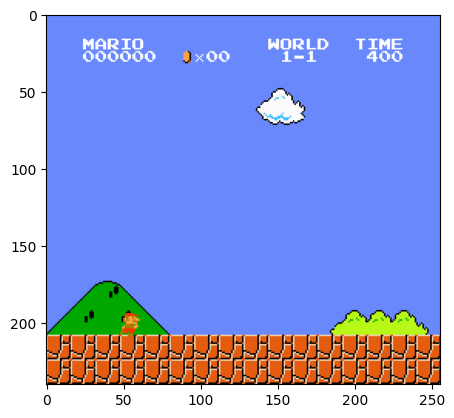
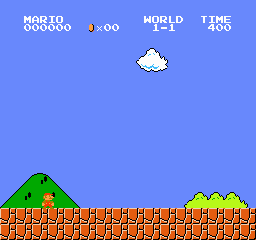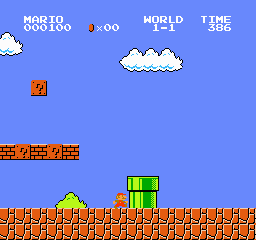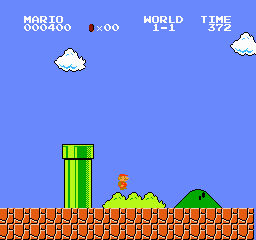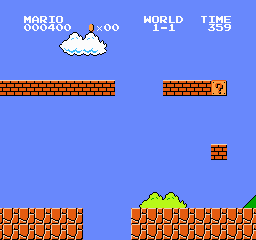
環境の状態(State)。単純な画像です
GPT-4oのプロンプトは以下のとおりです。ポイントは、最低限の操作するためのルール以外には、評価関数などを一切与えていない点です。マリオの学習も、動作例も与えていないので、ほとんどZero-Shot(ゼロショット:学習無し)の状態になります。よって、通常学習に使用される報酬も、今回はエージェントは一切使っていません。
この画像はゲーム、スーパーマリオのプレイ画面です。
画面に応じて、以下の7つのボタン操作ができます。ボタン操作は以下の7つからどれかを選んでください
NOOPが操作しない。Aがジャンプ。Bがダッシュです。
0 = 'NOOP'
1 = 'right'
2 = 'right', 'A'
3 = 'right', 'B'
4 = 'right', 'A', 'B'
5 = 'A'
6 = 'left'
以下の通りjson出力してください。日本語でお願いします。
explanation: 画面の説明
reason: ボタン操作の理由
action: ボタン操作の種類
LLMのマリオのプレイ結果
Google Colabでコードを実行すると、LLMが操作したマリオが動き出します。
ちゃんと周囲を理解しながら適切な動作をとろうとしているのが分かります。


何回かプレイしたら、ある程度ステージを進めることができました。
LLMのコスト
気になるコストについても触れておきたいと思います。OpenAIのコスト情報をもとに画像サイズを入力して計算すると、0.000638ドルなので大体0.1円くらいですね。
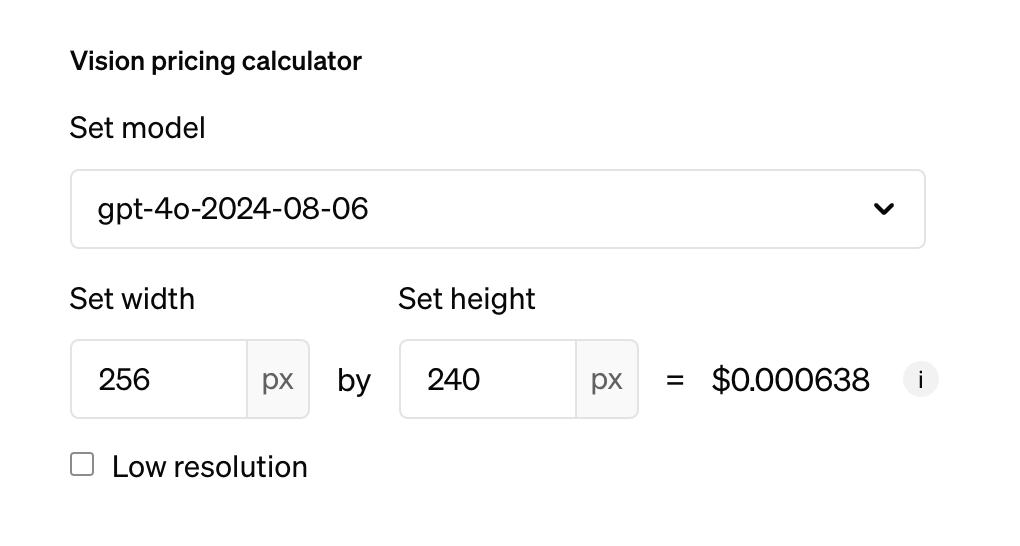
マリオのプレイに必要なLLMの推論回数は、条件によって変わりますが、1000回使ったとしても100円程度なので、数回プレイする程度ならそこまでお金はかからないと思います。
ただ、調子に乗って1日中プレイしたら、あっという間に凄いお金になるかもしれません。あと、私が大いに計算間違いをしている可能性も否定できません。
気になる人は、コードを改変してChatGPTでなく、オープンなモデルを使用することで、お金を気にせず思う存分LLMをプレイできるようになると思います。
Claude 3.7 Sonnetの結果
他の方のチャレンジ例
派生コード
Claude, Geminiに対応したコード
MobileVLMに対応したColabノートブックです。
large_language_mario_mobile_vlm_v2.ipynb
OpenAIのAPI Keyなしで無料で楽しめます。
まとめ
LLMでマリオをプレイするLarge Language Marioを作って試してみました。
仮説通り、ゼロショット(学習無し)である程度マリオをプレイすることができました。プロンプトチューニングしたり、いくつか画像をFew-shotで与えてやることで、何度もプレイすると1-1ならクリアできる可能性もありそうですね。
あとは、やはりLLMは肉体がないので、ボタンとマリオの動作の対応に関しては、全然理解できていないように見えます。このあたりの根本的な改善には、ゲーム専用の学習が必要かなと感じました。
うまくこのあたりの学習とリアルタイム性の向上ができれば、実機のゲームをプレイするLLMを作ることもできなくはなさそうですね。
興味を持った方は、プロンプトチューニングやファインチューニング、オープンなモデルの対応、実機対応など試して、教えてもらえると嬉しいです。
参考リンク
関連記事
変更履歴
- 2024/08/17 他の方のチャレンジ例を追記しました
Discussion