ChatGPTによるDALL・Eでの画像生成のプロンプトついての補足
ChatGPTによる画像生成の仕組み
面倒なことはChatGPTにやらせようという書籍を書いています。
サポートサイトから加入できる書籍のコミュニティ(ChatGPTにやらせ隊)があるのですが、そこでの議論で話題になったので、ChatGPTでの画像生成に関して、書籍では触れなかった点について少し補足をしておきたいと思います。なお、自分が知る限り、このあたりのオフィシャルな仕様は公開されていないので、ChatGPTの挙動とDALL・Eおよび一般的な画像生成AIの仕様から推測したものになり、誤っている可能性あることはご了承ください。
ChatGPTによる画像生成のプロンプト
ChatGPTでは、絵を生成することができます。内部ではDALL・Eという画像生成AIが動いています。
例えば以下のように「からあげの絵を描いてください」というプロンプトを使うと、からあげの絵が生成されます。

実は、このときDALL・Eには「からあげ」という単語がそのままプロンプトとして使われておらず、DALL・E用のプロンプトに(おそらく)変換されています。
DALL・E用のプロンプトは、画像をクリックして丸の中にiが入っているボタンを押すと表示されます。

「からあげ」という短い単語から、表現力豊かな長文プロンプトが生成されているされていることがわかります。GIGAZINEさんが『AIを操る「プロンプトエンジニア」がAIによって駆逐されつつある』と、ちょっと煽り気味のタイトルの記事を書いていますが、要はこういうことです。画像生成では割と以前から行われていたテクニックだった記憶です。
簡単に図にすると、以下のような感じです。

画像生成を細かく指示したいときは、DALL・E用のプロンプトを修正して「このプロンプトで絵を描いて」とすると、細かく制御できるかもしれません。
また、AIでプロンプトを生成してほしくないときは、以下のように指示すればOKです。「プロンプトは一切変えないでください」とか強く要求しないと、勝手にプロンプト変えるので注意しましょう。
次のプロンプトの絵を描いてください。
プロンプトは一切変えないでください。
"""
karaage
"""

ChatGPTで全く同じ絵の生成は難しい
DALL・E用のプロンプトを使えば、ChatGPTで全く同じ絵を生成できそうですが、自分が試した限りは、セッションを変えたら(違う会話にすると)できませんでした。同じプロンプトでも毎回少し違う絵が生成されます。
そもそも、同じ画像をするには、その仕組から知る必要があります。DALL・Eは、恐らくその画質や挙動から拡散モデルと呼ばれる方式で画像生成していると思われるのですが(多分、これも正式には公開されていないです)、拡散モデルは仕組み的に、ランダムなノイズからノイズを除去する操作を繰り返すことで画像を生成します。
拡散モデルを使ったオープンソースの画像生成AIとして有名なStable Diffusionの仕組みを図にすると以下のような感じです(論文を参考に簡略化した図です)。図の左下のrandnってやつがランダムなノイズです。
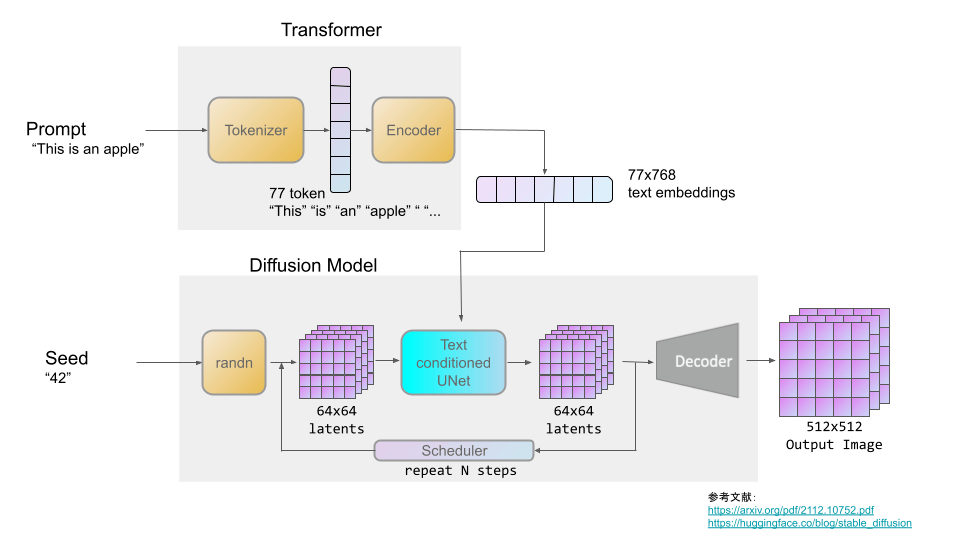
同じ画像を生成するためには、このランダムなノイズを生成するための基準となるSeed値を固定することが必要となります。拡散モデル(少なくともStable Diffusion)では、プロンプトとSeed値を固定することで、同じ画像を生成することができます。 このあたりは、以前shi3zさんや深津さんを巻き込んで議論して検証したこともあります。よろしければ以下記事参照ください。
なのでSeed値を固定すればよさそうなのですが、それがどうもできないようです。Seed値をChatGPTに聞くと、それらしい値を教えてくれるのですが、セッションを変えて(別の会話で)、同じプロンプトと同じSeed値で画像生成すると、違う画像が生成されます。
以下試してみた例です。



そもそも、Seed値が正しく設定されているかも分からないので、深追いが難しいです。
このあたりをもっと細かくコントロールしたい場合は、ソースコードが公開されているStable Diffusionを使うのがオススメです。以下記事など参考にしていただければ幸いです。
まとめ
ChatGPTでの画像生成に関して、書籍では触れなかった補足をしました。簡単に書くつもりが思ったより長文になってしまいました…
書籍で触れなかった理由としては、公式な仕様が公開されていないため、憶測の部分が多くなることと、書籍のターゲット層に対してはだいぶマニアックな話になること。そして、そこまで応用性がない(知っていることの嬉しさが小さい)ということです。
実際、自分もChatGPTで画像生成をするとき、このあたりを意識することは少なくて、細かく制御する場合はStable Diffusionを使います。AIも使い分けが大事ですね。
ということで、実践的なChatGPTの使い方を書いた面倒なことはChatGPTにやらせよう。絶賛発売中ですのでよろしくお願いいたします!
また書籍限定コミュニティ(#ChatGPTにやらせ隊)では、この記事のような少し深い使い方に関してもディスカッションをしていますので、是非書籍サポートサイトから加入ください!
Discussion