ChatGPTに関しての個人的なメモ
ChatGPT全然分からん
ChatGPTに興味があるけど、そもそも基本的なところから分からないところだらけなので、以下3段階に分けて、自分がポイントと思う点をメモしておきます。
- Transformerについて
- GPTについて
- ChatGPTについて
既に分かりやすくまとめてくださっている人がたくさんいるので、特に分かりやすいと自分が思う記事のリンクと個人的メモが中心です。特に新しいことは何も書いていません。個人の感想はなるべく分かるように分けて書くようにしています。内容の正確性は保証できませんのであしからず。
気づいたら修正したり、追記していきます。
Transformerについて
概要
ChatGPTのTはTransformerのTです。トランスフォーマーといっても、コンボイの謎ではありません(一定以上の年齢の人だけがわかるネタ)。Transformerに関しては、以下の資料がかなり分かりやすかったです。
以下は個人的メモです。
Transformerは、特に言語に対して性能が高いと言われているAIモデルで、Attentionというメカニズムが使われています。Attention Is All You Needという論文があまりにも有名で、Transformerのよく見られる以下の構造もこの論文に示されています。
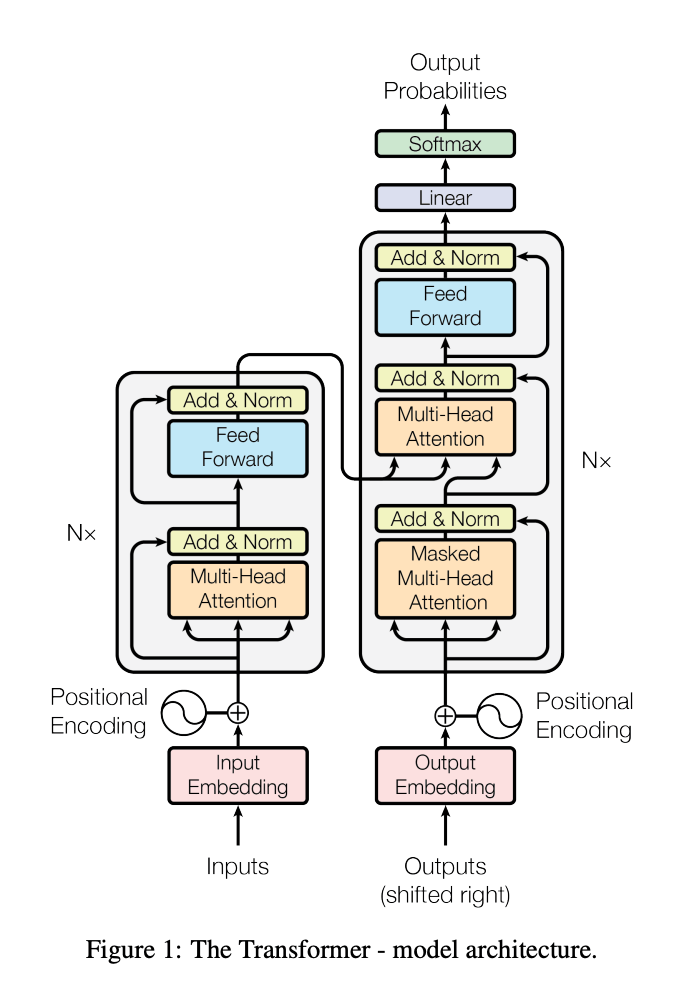
Transformerは自然言語処理の技術としての発展形となります。画像の分野だとAttentionに対応するものとして、CNN(Convolutional Neural Network)が使われます。CNNは局所的な領域の特徴をとるのが得意ですが、言語だと局所的な領域以外の特徴(例えば、長文の最初の方と最後の方)の関係も重要なので、CNNはあまり自然言語の分野には用いられません。
逆に、画像ではTransfomerを使ったViT(Vision Transformer)という技術もありますが、画像に対しては、TransformerはCNNに比べて優位性はないのではないかという議論もあったりします。画像にも自然言語にも使えるということで、かなり汎用的で強力なモデルということは言えるのかなと思います。
スケーリング則(Scaling Law)
Transformer関係の論文で、計算資源とデータ数とパラメータ数に関してべき乗則に従って性能が上がることを示すスケーリング則が有名です。

引用元:Scaling Laws for Neural Language Models
上記のグラフが何を言っているかというと「モデル大きくして学習データ増やすほど、いくらでも性能が上がるぜ!札束で殴れば価値だヒャッハー(超意訳)」という法則です(縦軸はLossなので小さくなるほど良い評価)。
Transformerで示された論文ですが、おそらく他の構造のモデルでも似たようなことが言えるのではないかなと思います。他のモデルで実験した結果がないのは(知らないだけかも)、大規模だとめっちゃお金がかかるからでしょう。
ただ、いくらでも性能が上がるというのは、個人的には疑問があったりします。そもそも、学習できるデータは学習しきってしまっているから、データ量の限界がきてしまうのでは無いかという点と、指標としては難しいのですが、データの質というものをどう考えるかという問題もあると思います。
創発現象/相転移(Emergent Ability)
話題になった(なっている?)興味深い現象として、モデルが一定以上巨大になると、急激に性能が上がる(イメージ的には、今までできなかったことができるようになる)という性質があります。

引用元:Emergent Abilities of Large Language Models
これってスケーリング則と矛盾するのでは?と思ったりしたのですが、そうでもないらしいです。ChatGPTに聞いたら教えてくれました。でもまだちょっと納得できないです。
あと、創発現象って本当?という議論もあったりします。
参考:Are Emergent Abilities of Large Language Models a Mirage?
個人的には、創発現象自体は、ちょっと怪しいというかそこまで大きく騒ぐ必要はない気もしています。大きなモデルだと、小さなモデルだと解けない問題がとけるのは、体感的にも感じられることなので、一般的にはその程度の理解で良いのではないかと思います。
追記:PFNの岡野原さんの著書「大規模言語モデルは新たな知能か」によると、創発現象を説明できる有力な仮説として、以下2つがあるとのことです。
- 宝くじ仮説
- 構成属性文法
あとは、少し関連しそうな現象として、過学習しているようにみえても学習し続けると汎化するGrokkingという現象もあったりします。
ここでは、これらの詳細な説明は割愛しますので、興味ある方は書籍や論文などで調べてみてください。
実装
実際に手を動かして実装してみたいという人に参考になりそうな情報です。自分は、できてないです。
この動画も凄い良さそうです。
GPTについて
概要
GPTはGenerative Pretrained Transformerの略で、Transformerが学習済で何でも(?)生成できちゃうよって意味です(本当か?)。
以下の資料が詳しいです。30分で完全理解できると書かれていますが、私は理解しきれませんでした。Transformerのところの説明は、先程の資料と重なっていますし、スケーリング則と創発現象に関しても詳しい説明があるので、こちらを参考にしたほうがよいです。
Transformerを使ったモデルは、GPT以外にもたくさんあって、実はTransformerのEncoderとDecoderの両方を使っているもの、片方だけを使っているものなどがあったりします。
ざっとまとめると以下となります。
- Encoderのみ:BERT, LUKE…
- Decoderのみ:GPT、GPT-2、GPT-3…
- Encoder-Decoder:BART, T5, UL2…
より詳しくはA Survey of Transformersのサーベイ論文にまとまっています。
以下の樹形図も位置づけが分かりやすくまとまっています。
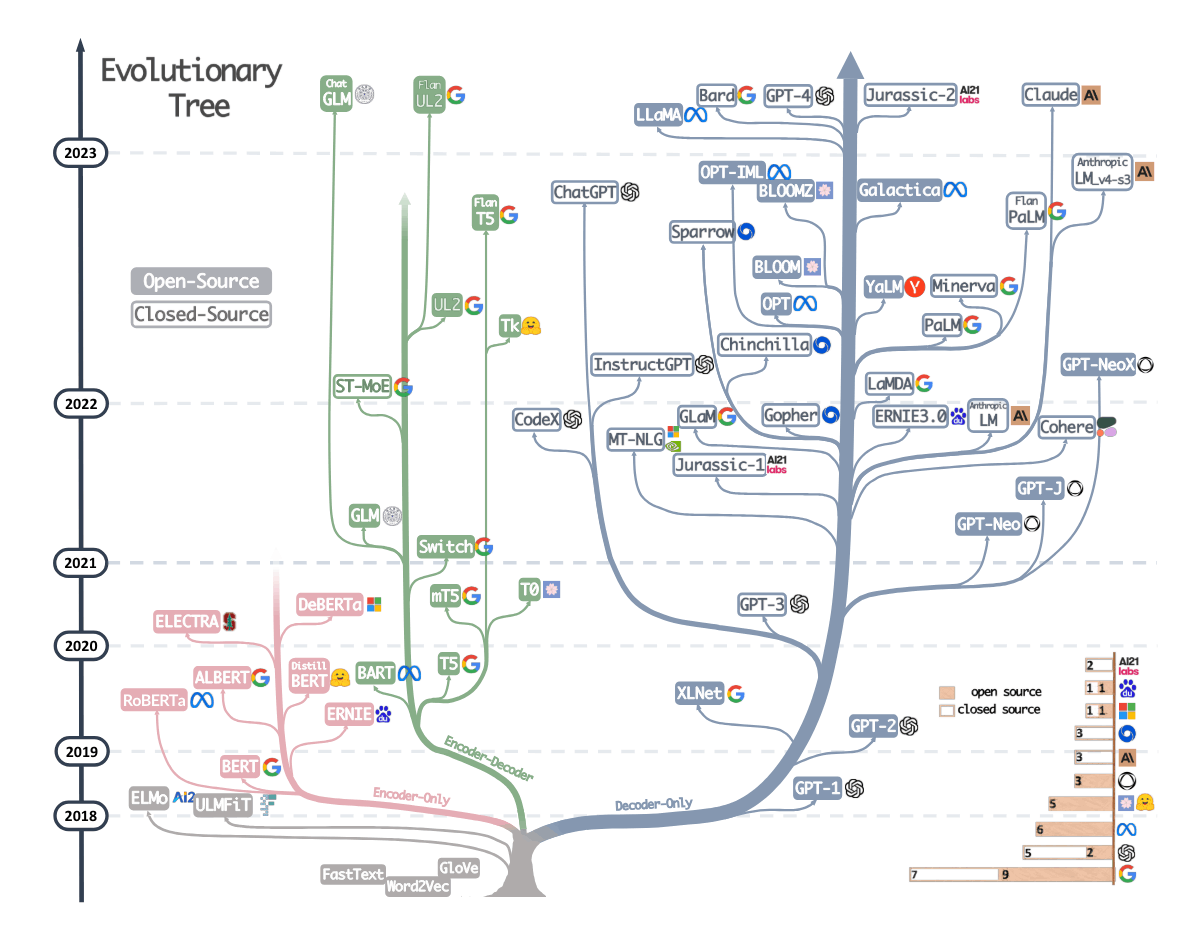
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyondより引用
パラメータ数(GPT1〜GPT3)
GPT、GPT-2、GPT-3では、基本的には学習データ、パラメータが以下のように増えています。
| モデル | 学習データ | パラメータ数 | リリース時期 |
|---|---|---|---|
| GPT-1 | WebText (4.5GB数千冊の本に相当) | 117M (1.17億) | 2018/06/11 |
| GPT-2 | WebText (40GB, 数万冊の本に相当) | 1.5B (15億) | 2019/02/14 |
| GPT-3 | WebText2 (570GB, 45TBからフィルタリング) | 175B (1750億) | 2020/06/11 |
| GPT-3.5 | WebText2 (570GB, 45TBからフィルタリング) | 355B(3550億) | 2022/11/30 |
めっちゃ多いですね(小学生並みの感想)。
GPT-2は構造が公開されていて、可視化すると以下のような感じみたいです(全然分からん)。
ChatGPT(およびそれ以降)に関して
GPTを使ってChatをできるようにしたものです。チャットできるインターフェースに加えて、InstructGPTという手法が使われていると言われています。
InstractGPTは、以下のように人の指示とその対応を教師あり学習(SFT:Supervised Fine-Tuning)と強化学習(RLHF: Reinforcement Learning from Human Feedback)をしています。
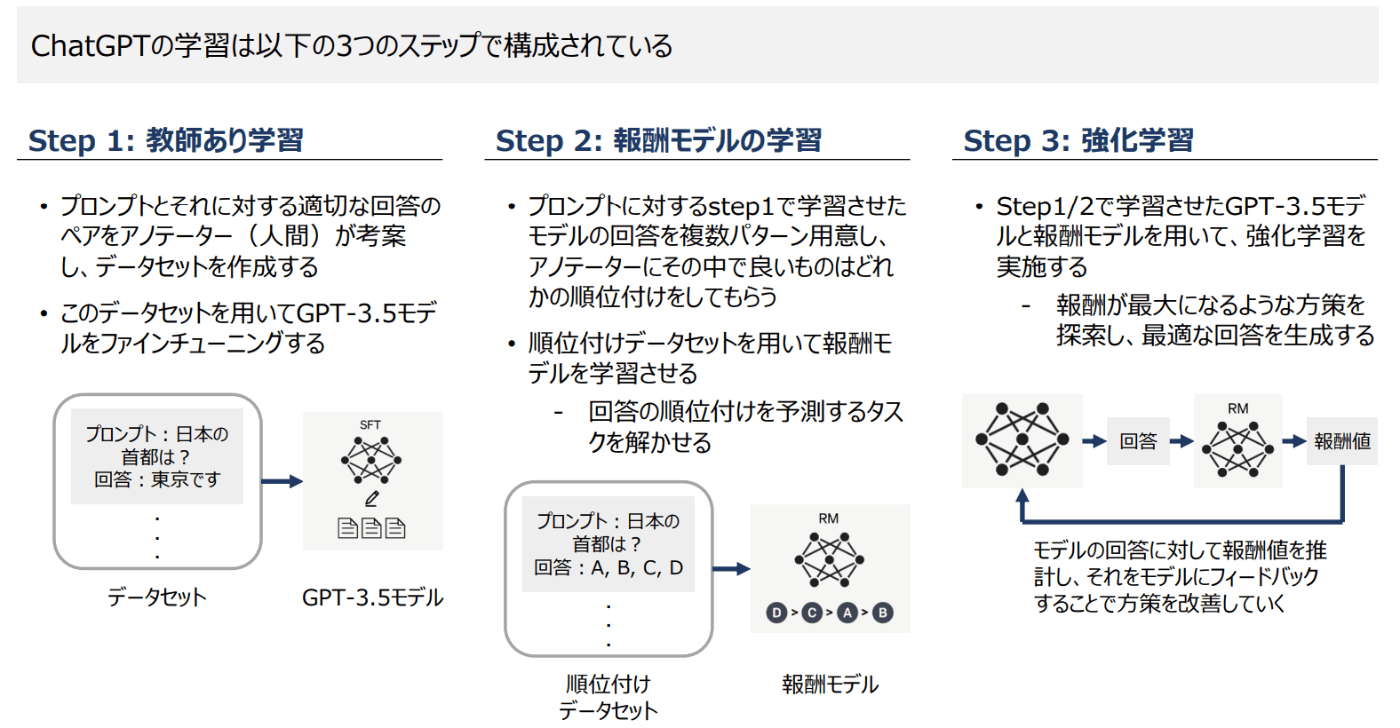
引用元:AIの進化と日本の戦略(PDF)
InstructGPTで性能が上がるのは示されているのですが、その中でも教師あり学習と強化学習がそれぞれどれだけ効いているかは議論があるようです。強化学習はあまり効いてないのでは説もあるとかないとか(どっちなんだ?)
追記:強化学習(RLHF)の効果はOpen AIのTraining language models to follow instructions with human feedback
という論文で示されていました。
RLHFは下図の通り、大きく効果があるという結果です。

MetaのLlama 2の論文でも、以下の通りPPO(RLHFの手法)で効果があることが示されています。
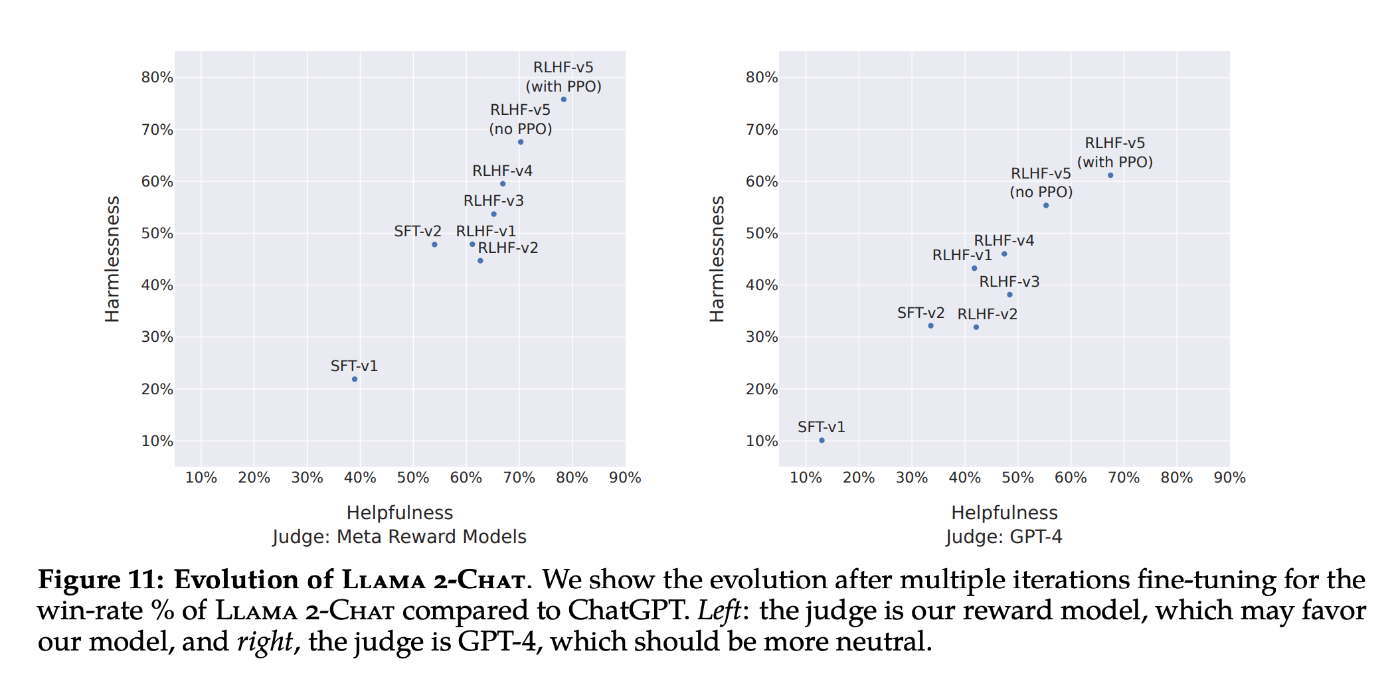
ChatGPTに関しては、以下記事も分かりやすいです。
これ以降のGPT-4も、ほとんど情報は公開されていませんが、性能等からパラメータは1兆は超えていると言われています。
GPT-4登場以降に出てきたChatGPT/LLMに関する論文や技術に関してのまとめは以下記事が参考になります。
まとめ
なんも分からん。
おすすめ書籍
大規模言語モデルは新たな知能か――ChatGPTが変えた世界
参考リンク
JDLA緊急企画!「生成AIの衝撃」~ ChatGPTで世界はどう変わるのか? ~(YouTube)
関連記事
変更履歴
- 2024/05/27 リンク追記
- 2023/08/03 RLHFの効果に関して追記
- 2023/06/25 創発現象に関して追記
Discussion