ObsidianとLLMでPodcast情報を整理する方法
Obsidianで情報整理
色々調べたり試したりして、使い道がWeb Clipperとしてしか使えてなかったObsidianですが、ようやくObsidianらしい活用ができた気がするのでメモしておきます。
具体的にはPodcastの情報整理です。対象のPodcast番組は、COTEN RADIO(歴史を面白く学ぶコテンラジオ)です。COTEN RADIO自体については、以下記事参照ください。COTEN RADIOのコンテンツは、自分にとっては重要なのですが、本記事の主題ではないので詳細は割愛します。
Podcast番組に対して、流れとしては以下の4ステップを実施します。
- Podcastの音源データ取得
- 音源データの文字起こし
- Obsidian用まとめ記事作成
- まとめ記事同士のつながり(リンク)強化
この4ステップを経ることで、以下のようなまとめ記事とグラフが生成できます。

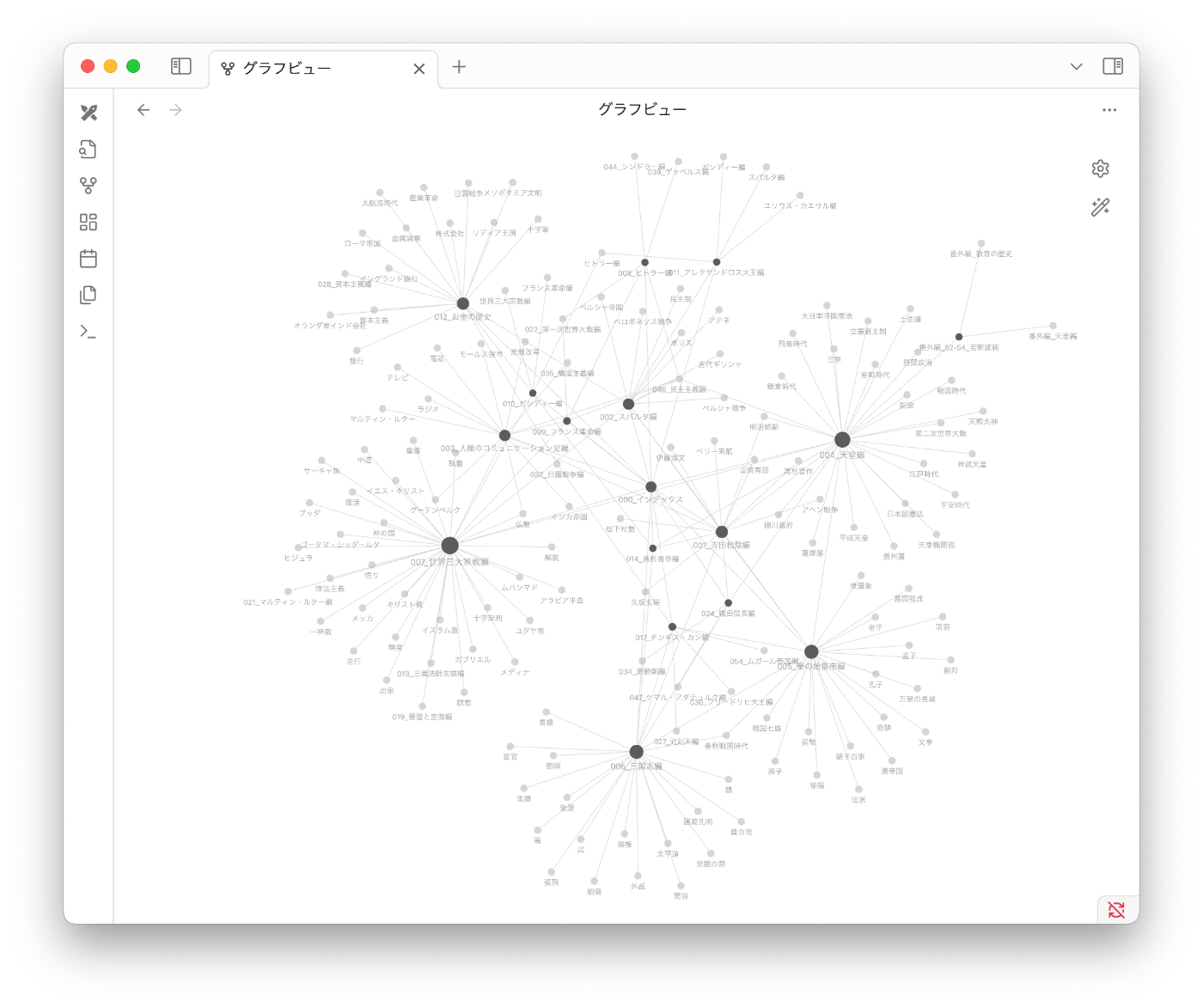
順に説明していきます。
1. Podcastの音源データ取得・2. 音源データの文字起こし
専用のソフト(非公開)を開発して、Podcastの番組の音源をすべてダウンロードし文字起こししています。文字起こしは、fast-whisperを使っています。Largeのモデルを使ったら、全部のデータのダウンロードと文字起こしに2週間くらいかかりました。素直にOpenAIのWhisperとか使ったほうが良かったかもしれません。
API無しでfast-whisperでCPUでの文字起こしを手軽にできるツールは、自作して以下記事で紹介していますので、音源データを1つずつダウンロードすれば同様に文字起こしはできると思います。
文字起こしされたデータは以下のようにエピソード名のファイル名がつけられたマークダウンファイルとして保存して、1つのフォルダにまとめます。
- 【1-1】 吉田松陰が脱藩した衝撃の理由!【COTEN RADIO 吉田松陰編1】.md
- 【1-2】 吉田松陰の「感化力」がすごい!【COTEN RADIO 吉田松陰編2】.md
3. Obsidian用まとめ記事作成
文字起こししたファイルをもとに、Obsidian用のまとめ記事を作成します。Cline(Roo Code)やCursorといったAIコーディングツールを使用します。どちらでもできると思います。AIコーディングツールに関しては以下記事を参照ください。
ルール(.clinerulesや.cursorrules)には、以下のようなルールを記載しています。
# コテンラジオ文字起こしデータのまとめ方
## 基本的な手順
0. README.md でファイルのルールを確認する
1. エピソードシリーズを特定する
```
ls -la transcription_data | grep "【X-" | sort
```
※Xはエピソード番号(例:【1-】、【3-】など)
2. シリーズの各回を読み込む
```
read_file transcription_data/【X-Y】ファイル名.md
```
※X-Yはエピソード番号と回数(例:【1-1】、【1-2】など)
3. 必要に応じて追加情報を調査する
```
<use_mcp_tool>
<server_name>brave-search</server_name>
<tool_name>brave_web_search</tool_name>
<arguments>
{
"query": "検索キーワード",
"count": 10
}
</arguments>
</use_mcp_tool>
```
4. まとめをマークダウンファイルとして作成する
```
<write_to_file>
<path>summary_data/エピソード名.md</path>
<content>
# エピソード名 まとめ
## 基本情報
- **テーマ**:
- **放送日**:
- **出演者**:
## 主な内容
### 第1回
### 第2回
### 第3回
## まとめ
## 関連エピソード
#タグ1 #タグ2 #タグ3
</content>
</write_to_file>
```
## Obsidianに適した形式での整理方法
Obsidianの強力な機能を活用するために、以下の形式でまとめファイルを整理します。
### 1. フロントマターの追加
各ファイルの先頭にYAML形式のフロントマターを追加します:
```
---
title: エピソード名
episode: エピソード番号
date: 放送日
tags:
- タグ1
- タグ2
aliases:
- 別名1
- 別名2
---
```
この状態で、
### 4. 内部リンクの追加
関連する概念や他のエピソードへの参照には内部リンクを使用します:
```
[[ファイル名]] または [[ファイル名|表示テキスト]]
```
例:「このテーマは[[001_吉田松陰編|吉田松陰編]]でも触れられています」
### 3. タグの追加
ファイル末尾にハッシュタグを追加して分類します:
```
#歴史人物 #日本史 #教育 など
```
### 4. 関連エピソードセクションの追加
ファイル末尾に関連エピソードへのリンクを追加します:
```
## 関連エピソード
- [[001_吉田松陰編]] - 関連性の説明
- [[002_スパルタ編]] - 関連性の説明
```
### 5. インデックスファイルの作成
`000_インデックス.md` ファイルを作成して全エピソードへのリンクと説明を提供します。
### 6. README.mdの作成
ナレッジベースの使い方や構造を説明するREADME.mdファイルを作成します。
これらの整理方法により、Obsidianの機能(内部リンク、バックリンク、グラフビュー、タグ検索など)を活用して、エピソード間の関連性を視覚化し、効率的に情報を探索できるようになります。
今の主要なLLMは、Obsidianをかなり理解しているので、特別詳しくObsidianのルールを書かなくても大丈夫と思います(小さいローカルLLMとかだと、具体的に書く必要があるかもしれません)。このルール自体も、一度試行錯誤してまとめ記事を作成した後に、LLMに「いままでの内容をルールとしてまとめて」とお願いして書いてもらっています。
このルールのもとで、以下のようなプロンプトで指示すると、文字起こししたファイルがObsidianのタグなどがついた状態で、いい感じにまとめられます。
@<文字起こしデータを保存したフォルダ名>の 1-x 吉田松陰編のまとめお願いします
4. まとめ記事同士のつながり(リンク)強化
一回まとめただけだと、記事同士のつながりが弱い状況です。

以下のようなプロンプトで記事同士の繋がりを増やしてみます。
@<まとめ記事を保存したフォルダ名> に関してObsidianで関連性が見やすくなるようにリンクを強化してください
LLMがいい感じにファイルを編集してくれます。

以下のようにグラフの繋がりが強化されます。

まとめ
Obsidianを使って情報を整理してみました。LLMは、情報のまとめだったり整理に便利ですね。
Podcastのまとめ記事は、人によっては「何の意味があるの?」という感じかもしれませんが、個人的には、後で内容を復習したいときとか、聞き逃している箇所を確認したいときに大活躍しています(よく新幹線でPodcastを聞いて寝落ちしているので)。
グラフに関しては、パット見は良い感じですが、使い方としては見ながらニヤニヤするくらいでしょうか(笑)よくみると繋がるべきところが繋がってなかったりと間違いは結構あるので、結局最後は人間が修正したくなってくるやつです。
一応グラフみていて「お、これについても調べてみよう」と思ったりするので、何かしら楽しめる人はいるのではないかなと思います。ただ、めっちゃ役に立つとか期待し過ぎない方が良いと思います。
この方法は、コテンラジオ以外のコンテンツでも応用できる気がするので、思いついた方は試してみて教えてもらえると嬉しいです。
Obsidianで“育てる”最強ノート術 —— あらゆる情報をつなげて整理しよう
参考リンク
関連記事
Discussion