おうちで拡散言語モデル「Dream 7B(4bit)」を試す
おうちで拡散言語モデル「Dream 7B(4bit)」を試す
Google I/OでのGemini Diffusion発表を皮切りにDiffusion系の言語モデルが話題になっています.
流れに乗ってDiffusion系の言語モデルを家で試してみたいけど, 一般的にDiffusion系の言語モデルはGPUのVRAMを大量に消費するため, 手元のPCでは試すことはTransformaer系の言語モデルと比較して難しいようです.
この記事では一般?のご家庭にあるPC(VRAMが10GB程度)で試しやすい, 拡散言語モデルDream 7Bを4bit量子化したDream 7B(4bit)を動かす手順を説明します. 動かすほとんどのスクリプトは本家を流用しています.
(ローカルで動かさずともHugginfaceでDreamを試せますが, それを言ってしまうとおしまいです. )
動かすとこんな感じ.
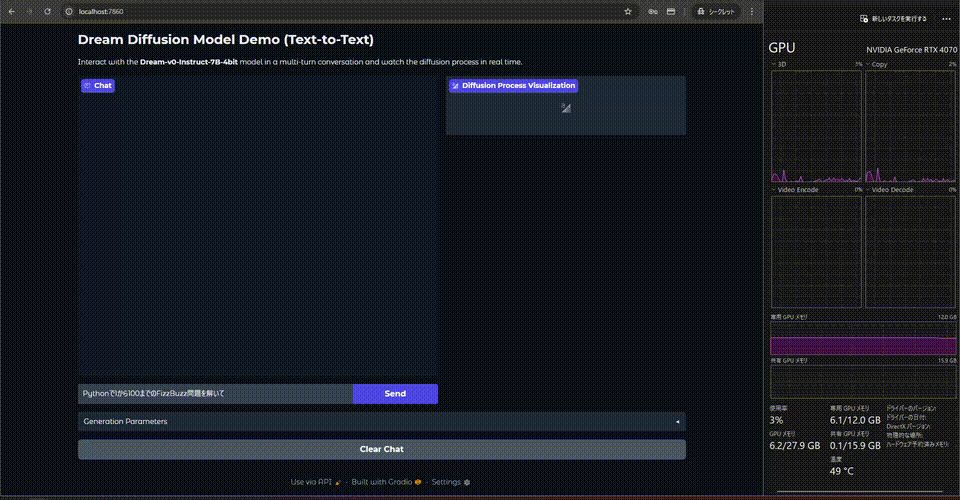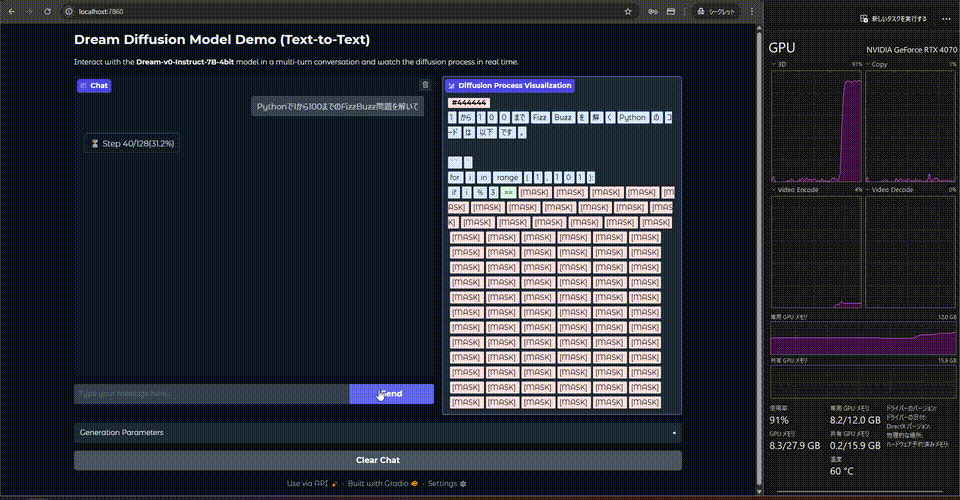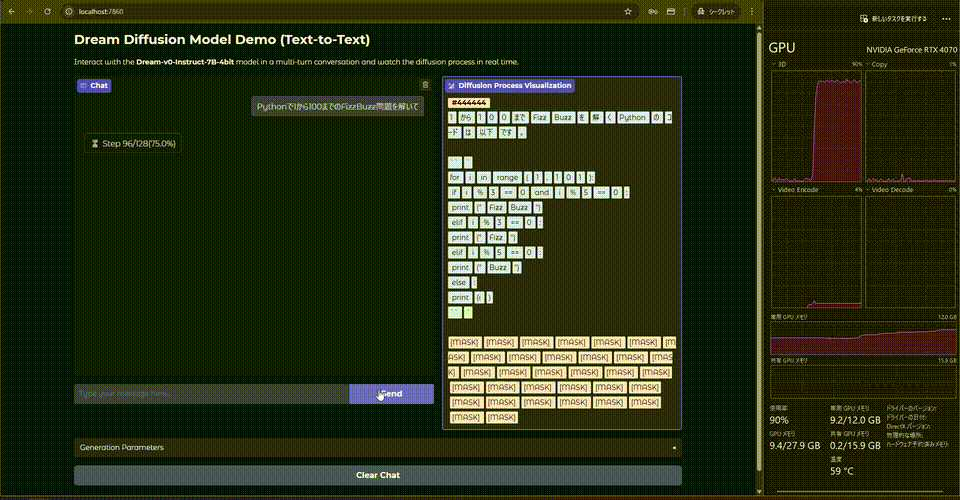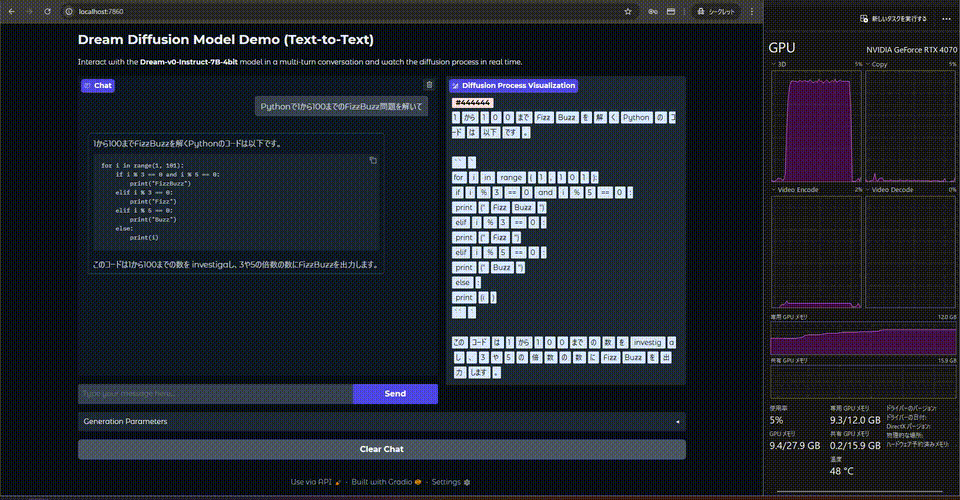
等倍です. あれ, 生成速度が遅い....
この点も後ほど考察します.
🚀起動方法
Dockerを使い起動する手順をこちらまとめました.
この記事ではDockerを使った起動方法を説明します.
- リポジトリをクローン
git clone https://github.com/atsuyaide/Dream-4bit.git
- クローンしたディレクトリに移動
cd Dream-4bit
- (UID/GIDが1000でない場合)
.envファイルにUID/GIDを書き込み
この手順は, Huggingfaceのキャッシュをホスト側と同じUID/GIDでマウントするために必要です.
echo "UID=$(id -u)" >> .env
echo "GID=$(id -g)" >> .env
例えばこのようになります.
UID=1001
GID=1001
- Dockerイメージをビルド&起動
docker compose up --build
ビルドとモデルのダウンロードなどもあるので10分程度はかかります.
- ブラウザで
http://localhost:7860にアクセスします
画面下部にパラメータの設定項目があるので, 設定を変えながら試してみてください.

🤔考察
なぜ遅いのか?
実際に動作させてみると, 思ったよりも遅いことに気づくと思います. なぜGemini Diffusionは爆速なのか!?と思いましたがGoogleの公式情報はまだ公開されておらず, 様々な憶測が飛び交っています.
正確な情報はGoogleから公式に内部構造などが公開されるのを待つしかありませんが, ここでは一つの仮説を紹介します.
仮説: 少ないステップ数で高品質な出力を得るための工夫がされている
自己回帰モデルと比較して, 拡散モデルの一つの利点は複数のトークンを一括で予測できることなので, 少ないstepで大量のトークンを予測できれば推論速度が改善します.
しかし, ステップ数と性能にはトレードオフの関係があることが指摘されており, Gemini Diffusionはそのトレードオフをうまく解決していることが予想できます.
せっかくDreamが動く環境があるので, (極端な例ですが)step数を1と128を比較してみます.
| ステップ数 | steps=1 | steps=128 |
|---|---|---|
| 推論時間 | 0.48秒 | 41.07秒 |
| 出力品質 | 低い | 高い |
PythonBuzz問題の1111, 511 1111111 i51 i111 i1 if if51
i0005 i01 5 if % % %00 i0 i i % %izz % % %00 %izz 30"15
0 %301 i ==を % for %
"
51 1501 3``1 11 ``5 31 i5``1
です
めちゃくちゃですね.
PythonでFizzBuzz問題を解くには、以下のようなコードを用います。
```
def fizz_buzz(n):
result = []
for i in range(1, n + 1):
if i % 3 == 0 and i % 5 == 0:
result.append("FizzBuzz")
elif i % 3 == 0:
result.append("Fizz")
elif i % 5 == 0:
result.append("Buzz")
else:
result.append(str(i))
return result
print(fizz_buzz(15))
```
それらしい出力が得られました.
もしも数ステップで128ステップのような出力が得られるなら, 大量のトークンを一括で予測できる拡散モデルの利点を活かせるため, 推論速度が大幅に改善されることが期待できます.
実行ログから処理時間を確認できます.
steps=1のログ
INFO:__main__:Parameters: max_new_tokens=128, steps=1, temperature=0.5, top_p=0.95, top_k=0, delay=0.02, alg=entropy
INFO:__main__:Formatted messages for model: [{'role': 'user', 'content': 'PythonでFizzBuzz問題を解いて'}]
INFO:__main__:Prompt length: 27, input_ids device: cuda:0
INFO:__main__:Model generation completed in 0.48 seconds.
steps=128のログ
INFO:__main__:Parameters: max_new_tokens=128, steps=128, temperature=0.5, top_p=0.95, top_k=0, delay=0.02, alg=entropy
INFO:__main__:Formatted messages for model: [{'role': 'user', 'content': 'PythonでFizzBuzz問題を解いて'}]
INFO:__main__:Prompt length: 27, input_ids device: cuda:0
INFO:__main__:Model generation completed in 41.07 seconds.
なぜ前から生成されるのか?
マスクを外すアルゴリズムとしてentorypyを使用しているためです. originとするとランダムな順序で生成されます.
アルゴリズムがoriginの場合

自己回帰モデルは次のトークンを予測するのに対して, 拡散モデルは任意の場所のトークンを予測できます. しかし, どのトークンを確定させるかはアルゴリズムによって異なり, entropyは最もエントロピーが高いトークンから優先的にマスクを外します.
Dreamが自己回帰モデル(Qwen-2.5 7B)からウォームスタートしているため左から右への予測する知識が残っており, 前方から生成される傾向にあると解釈できます.
🎯まとめ
Dream 7B(4bit)を動かす手順を説明し, 疑問点を簡単に考察しました.
拡散言語モデルはまだ発展途上の技術であり, 今後の研究や実装の進展により, より高速で高品質な生成が可能になることが期待されます.
📚参考情報
- https://github.com/HKUNLP/Dream
- Diffusion reasoningモデル「Dream 7B」を試す
- Exploring the Architecture Behind Google’s Gemini Diffusion
では!!
Discussion