Google データポータルの塗り分けマップで都道府県と市町村のデータを可視化
Google データポータルのマップ機能がよさそうで、市町村のデータを可視化できるようなので試してみました。
今回、作成したダッシュボードは以下になります。

利用するデータ
人口動態統計特殊報告の人口動態保健所・市区町村別統計で公開されている標準化死亡比(ベイズ推定値)のデータをダウンロードして利用します。
標準化死亡比 (Standardized Mortality Ratio: SMR)
標準化死亡比について
死亡率は通常年齢によって大きな違いがあることから、異なった年齢構成を、 持つ地域別の死亡率を、そのまま比較することはできない。比較を可能にするためには 標準的な年齢構成に合わせて、地域別の年齢階級別の死亡率を算出して比較する必要がある。
標準化死亡比は、基準死亡率(人口10万対の死亡数)を対象地域に当てはめた場合に、 計算により求められる期待される死亡数と実際に観察された死亡数とを比較するものである。 我が国の平均を100としており、標準化死亡比が100以上の場合は我が国の平均より死亡率 が多いと判断され、100以下の場合は死亡率が低いと判断される。
標準化死亡比は、基準死亡率と対象地域の人口を用いれば簡単に計算できるので地域別の比較に よく用いられる。
以下では標準化死亡比をSMRと表記しています。
データ処理
ダウンロードしたエクセルファイルのデータをpandasのDataFrameに変換します。
import re
import openpyxl
import pandas as pd
from tqdm.notebook import tqdm
workbook = openpyxl.load_workbook('hyo5_h2529.xls')
sheet = workbook.worksheets[0]
# 死因
causes = []
index = 1
for i in range(2, 38, 2):
if sheet.cell(6, i).value:
category = sheet.cell(6, i).value.replace(' ', '').replace(' ', '')
category = category.replace('<腫瘍>', '').replace('(高血圧性を除く)', '')
if sheet.cell(7, i).value:
sub_category = sheet.cell(7, i).value.replace(' ', '').replace(' ', '')
causes.append('%02d_%s:%s' % (index, category, sub_category))
index += 1
else:
causes.append('%02d_%s' % (index, category))
index += 1
# SMR
smrs = pd.DataFrame()
for i in tqdm(range(10, sheet.max_row+1)):
label = sheet.cell(i, 1).value
code = re.sub(r'\D', '', label)
if len(code) == 2:
code = code + '000'
prefecture = re.sub(r'\d', '', label).replace(' ', '').replace(' ', '')
name = prefecture
elif len(code) == 5:
city = re.sub(r'\d', '', label).replace(' ', '').replace(' ', '')
name = prefecture + city
else:
continue
for j, cause in enumerate(causes):
try:
smrs = smrs.append({
'自治体コード': code,
'自治体': name,
'性別': '男性',
'死因': cause,
'SMR': float(sheet.cell(i, j*2+2).value),
}, ignore_index=True)
smrs = smrs.append({
'自治体コード': code,
'自治体': name,
'性別': '女性',
'死因': cause,
'SMR': float(sheet.cell(i, j*2+3).value),
}, ignore_index=True)
except:
pass
マップを塗り分ける際に都道府県と市町村でデータを区別するために、それらを判定する列を追加します。
# 都道府県の判定
smrs['都道府県'] = 1
smrs['都道府県'].where(smrs['自治体コード'].str.endswith('000'), 0, inplace=True)
マップを塗り分ける判定基準となる列を追加します。pandasのqcut()を利用して集計単位ごとに7分割しています。
# ビン分割
df = pd.DataFrame()
for category in range(2):
for sex in smrs['性別'].unique():
for cause in smrs['死因'].unique():
tmp_df = smrs.copy()
tmp_df = tmp_df[(tmp_df['都道府県'] == category) & (tmp_df['性別'] == sex) &
(tmp_df['死因'] == cause)].reset_index()
tmp_df['ビン'] = pd.qcut(tmp_df['SMR'], 7, labels=[1, 2, 3, 4, 5, 6, 7])
df = df.append(tmp_df, ignore_index=True)
マップの吹き出しに表示するツールチップの文字列を追加してエクセルファイルに出力します。
df['ツールチップ'] = df['自治体'] + ' (' + df['SMR'].astype(str) + ')'
df.to_excel('smr.xlsx', index=False)
df
作成したエクセルファイルをGoogle ドライブにアップロードして、Google スプレッドシートとして保存します。
塗り分けマップの作成
Google データポータルにログインします。
レポートを作成して、作成したGoogle スプレッドシートのデータを指定します。
都道府県を塗り分け
まずSMRを都道府県で塗り分けるマップを作成します。「グラフを追加」から塗り分けマップを選択して、データの表示について設定していきます。

「位置」には自治体の名称が格納された列を指定して、タイプには「地方行政区画(第1レベル)」を指定します。
このマップでは都道府県を表示するため、以下のようなフィルタを作成して適用します。

最後に「死因」と「性別」を単一選択するコントロールを追加して完成です。
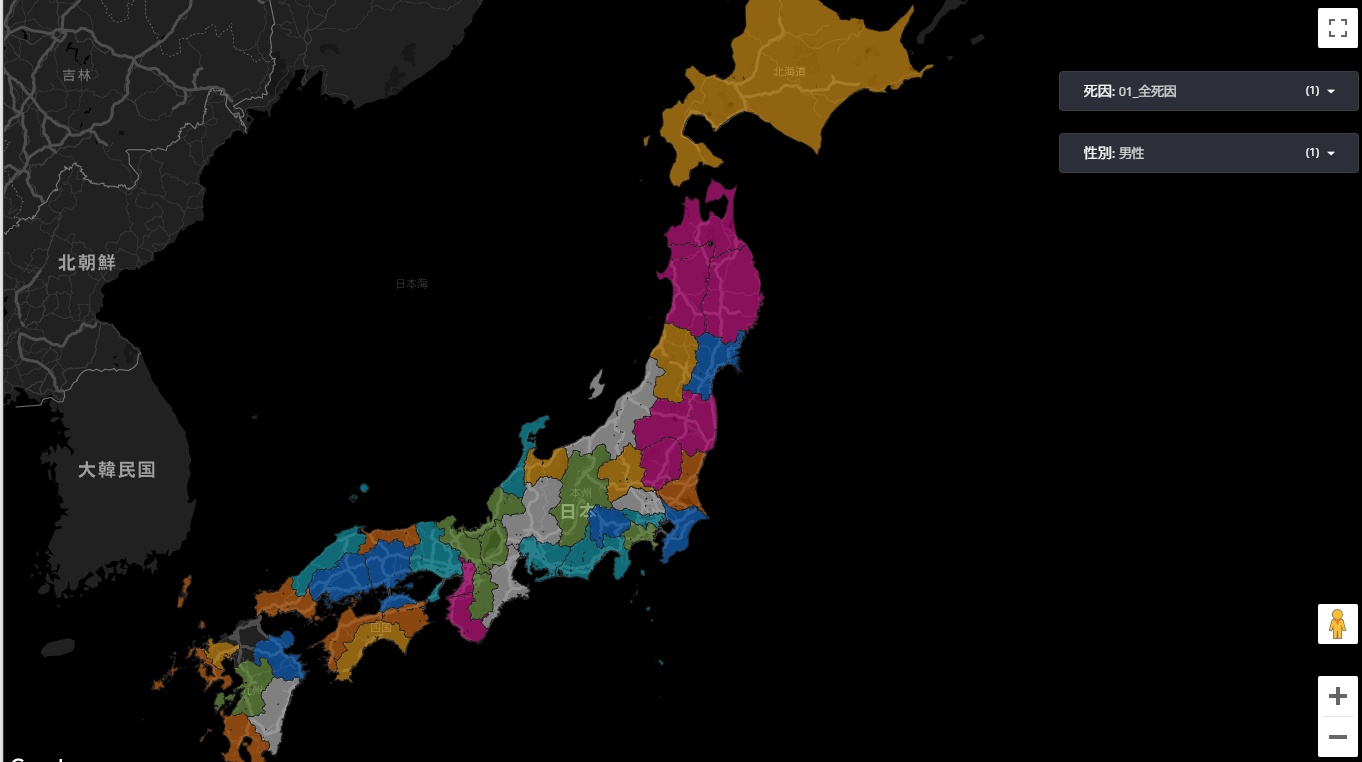
市町村を塗り分け
Google データポータルのメニューから「ページの複製」を選択して都道府県のページを複製します。
「位置」のタイプには「地方行政区画(第2レベル)」を指定します。
マップで市町村を表示するためのフィルタを作成して適用します。都道府県の列が0である条件に加えて、「東京都の区部」全体を除外する条件を追加します。
また、Google データポータルの地方行政区画(第2レベル)では政令市の区を表示できないため、政令市の区を除外する条件を以下の正規表現で指定します。
.+市.+区$

これでSMRを市町村で塗り分けたマップが表示されました。
有意水準(2021年10月1日追記)
標準化死亡比で地図を塗り分けている例を見ると有意水準を基準として塗り分けていましたので、今回作成するダッシュボードでもそのように変更しました。
有意水準の計算については厚生労働科学研究費補助金(循環器疾患・糖尿病等生活習慣病対策総合研究事業)健診・医療・介護等データベースの活用による地区診断と保健事業の立案を含む生活習慣病対策事業を担う地域保健人材の育成に関する研究の平成26年度総括・分担研究報告書を参照しました。
厚生労働省の人口動態特殊報告「平成20~24年人口動態保健所・市区町村別統計」の「第3表 死亡数,主要死因・性・都道府県・保健所・市区町村別(平成20年~24年)」および「第5表 標準化死亡比,主要死因・性・都道府県・保健所・市区町村別(平成20年~24年)」を用いて、男女別に市区町村別(川崎市と熊本市を除く政令指定都市は行政区別)の総死亡および死因別SMR を以下の5区分に分けて地図化した。
- 有意に高い
- 高いが有意でない
- 低いが有意でない
- 有意に低い
- 0(検定不能)
ここで、「有意に高い(低い)」は、市区町村別SMRを次式により有意水準5%で両側検定して区分した。すなわち、
Z = \frac{|x-E|-0.5}{\sqrt{E}} > Z(0.05/2) = 1.96 ならば有意とする。ここで、は観測死亡数、Eは期待死亡数である。
観測死亡数とSMRから期待死亡数を算出
期待死亡数の計算については以下のように示されていました。
ただし、上記人口動態特殊報告では期待死亡数が公表されていないため、第3表の観測死亡数を第5表の標準化死亡比で除して期待死亡数を算出した。そのため、観測死亡数が0の場合には期待死亡数が算出できず、0(検定不能)に区分した。そのため、観測死亡数が0の場合には期待死亡数が算出できず、0(検定不能)に区分した。
これは以下のような計算になります。
観測死亡数の読み込み
人口動態統計特殊報告の人口動態保健所・市区町村別統計のhyo3_h2529.xlsxから観測死亡数を読み込みます。
import re
import openpyxl
import pandas as pd
from tqdm.notebook import tqdm
workbook = openpyxl.load_workbook('hyo3_h2529.xlsx')
sheet = workbook.worksheets[0]
# 死因
causes = []
index = 1
for i in range(2, 38, 2):
if sheet.cell(5, i).value:
category = sheet.cell(5, i).value.replace(' ', '').replace(' ', '')
category = category.replace('<腫瘍>', '').replace('(高血圧性を除く)', '')
if sheet.cell(6, i).value:
sub_category = sheet.cell(6, i).value.replace(' ', '').replace(' ', '')
causes.append('%02d_%s:%s' % (index, category, sub_category))
index += 1
else:
causes.append('%02d_%s' % (index, category))
index += 1
# 観測死亡数
deaths = pd.DataFrame()
for i in tqdm(range(9, sheet.max_row+1)):
label = sheet.cell(i, 1).value
code = re.sub(r'\D', '', label)
if len(code) == 2:
code = code + '000'
prefecture = re.sub(r'\d', '', label).replace(' ', '').replace(' ', '')
name = prefecture
elif len(code) == 5:
city = re.sub(r'\d', '', label).replace(' ', '').replace(' ', '')
name = prefecture + city
else:
continue
for j, cause in enumerate(causes):
try:
death = float(sheet.cell(i, j*2+2).value)
except:
death = 0
deaths = deaths.append({
'自治体コード': code,
'自治体': name,
'性別': '男性',
'死因': cause,
'観測死亡数': death,
}, ignore_index=True)
try:
death = float(sheet.cell(i, j*2+3).value)
except:
death = 0
deaths = deaths.append({
'自治体コード': code,
'自治体': name,
'性別': '女性',
'死因': cause,
'観測死亡数': death,
}, ignore_index=True)
期待死亡数の計算
df = pd.merge(deaths, smrs, on=['自治体コード', '自治体', '性別', '死因'])
df['期待死亡数'] = df['観測死亡数'] / (df['SMR'] / 100)
検定
import numpy as np
df['Z'] = (abs(df['観測死亡数'] - df['期待死亡数']) - 0.5) / np.sqrt(df['期待死亡数'])
マップで塗り分ける際に判定基準となる列を作成します。
df['検定'] = ''
df['検定'].mask((df['Z'] > 1.96) & (df['SMR'] > 100.0), '有意に高い', inplace=True)
df['検定'].mask((df['Z'] <= 1.96) & (df['SMR'] > 100.0), '高いが有意でない', inplace=True)
df['検定'].mask((df['Z'] <= 1.96) & (df['SMR'] <= 100.0), '低いが有意でない', inplace=True)
df['検定'].mask((df['Z'] > 1.96) & (df['SMR'] <= 100.0), '有意に低い', inplace=True)
df['検定'].mask(df['Z'] == -float('inf'), '検定不能', inplace=True)
まとめ
Google データポータルの塗り分けマップを利用して、都道府県と市町村の単位でデータを可視化しました。市町村では一部で表示されなかったり重なっていたりするデータがありましたが、大半のデータは正常に表示されました。
私はこれまで地図上にデータを表示する方法としてはGoogle Maps APIやGoogleのマイマップを使っていたのですが、Google データポータルは地図上への表示と同時に関連するグラフを簡単に表示することが可能なので、これからはGoogle データポータルも利用していきたいと思います。
Discussion