[JOAI] 第一回日本人工知能オリンピックで金賞を受賞しました!!

この度、日本人工知能オリンピック(JOAI)に参加 し、金賞を受賞することができました!! 🏅
今回のコンペティションを通して様々なことを学ばせていただいたので、その記録をしておきたかったのと、これから人工知能オリンピックに参加される皆様の参考になれば良いな と思い、この記事を書くことにしました。ぜひご一読下さい...!! 🤖✨
日本人工知能オリンピック(JOAI)について
概要
JOAI の概要はホームページで以下のように紹介されています。主な目的としては、IOAI(国際人工知能オリンピック)の代表選手の選抜になります。
日本人工知能オリンピック(JOAI)は、国際科学オリンピックの一つである「国際人工知能オリンピック (International Olympiad in Artificial Intelligence; IOAI)」の日本代表選手選考を兼ねています。
第1回大会では、2025 年 8 月に中国・北京で開催される第2回国際人工知能オリンピック (International Olympiad in Artificial Intelligence 2025; IOAI2025) の代表選手を選抜します。
出典:JOAI2025 受験案内
応募資格
JOAI では IOAI への選抜を目的とした選抜枠 の他に、誰でも参加可能なオープン枠 が設けられています。人工知能の勉強を始めたいと考えている人達がにきっかけを与える目的もあるようです。(私は大学生ですので、オープン枠にて参加しました。)
- 【選抜枠】(IOAI日本代表選抜対象)
日本国籍を有する、または日本国内の学校に在籍するもので、応募時点で13歳以上であり、2025 年 8 月 2 日(土)の 国際人工知能オリンピック (IOAI2025) 開催初日時点で20歳未満、かつ、大学教育ないしそれに相当する高等教育を受けていないこと(高専の場合は本科 3 年生以下)- 【オープン枠】(IOAI日本代表選抜非対象)
参加制限なし(年齢・学歴・国籍問わず、どなたでもご参加いただけます)
これを機に人工知能の勉強を始めてみたい大学生・社会人の方からのご応募をお待ちしております。
出典:JOAI2025 受験案内
開催期間
開催期間は以下のようになります。まず、コンペティションの期間が 一週間 用意されており、そこで選抜枠上位になった人は面接が行われます。
(1) コンペティション(選抜枠・オープン枠共通):2025年4月25日(金) 19:00 〜 2025年5月2日(金) 23:59 (JST)
開会式に参加できない方のために、開会式と説明会の映像はアーカイブとして受験者に配信いたします。
(2) 面接(選抜枠のみ):5月上旬〜中旬実施予定
出典:JOAI2025 受験案内
開催方式
(1) コンペティション(選抜枠・オープン枠共通)
Kaggle を用いて、いわゆるデータサイエンスのコンペティションを行います。
Kaggle プラットフォームを利用したコンペティションにご参加いただきます。
コンペティションでは主催者から配布されるデータを分析し、課題に対して予測を作成し、特定の評価指標を競います。
出典:JOAI 2025 受験案内
(2) 面接・代表決定(選抜枠のみ)
選抜枠で良い成績を収めた人を対象に面接が行われ、IOAI の代表が決定します。
選抜枠参加者のうち、コンペティションでの成績優秀者には、コンペティション後に解法説明資料(自由形式)とソースコードの内容を提出していただきます。
そのうえで、IOAI2025へ派遣する代表を決定するため、下記の通り面接を実施します。
- 内容:
- コンペティションでの取り組み方の説明
- シラバス掲載の知識に関する質問応答
- IOAI2025 参加に対する意気込み
- 形式:
- オンライン面接で、自宅や在学校のコンピュータ教室などから参加
- 1 人 30 分程度
コンペティションの結果と、解法説明資料及び面接の結果を総合的に判断して、最終的な日本代表(4名程度)を決定いたします。
出典:JOAI 2025 受験案内
表彰
参加者のうち上位何%に入っているかで、入賞が決まります。
選抜枠とオープン枠のそれぞれの参加枠ごとに、コンペティションの結果に合わせて、賞の授与が決定します。
入賞された方には、後日賞状を贈呈します。
出典:JOAI 2025 受験案内

受験料
受験料については、以下のとおりです。
JOAI2025参加に伴い、以下の受験料が必要となります。
受験料:2,500円(税・手数料込)
受験料は IOAI2025 参加にかかる登録費(現地での宿泊代・食費などを含む)ならびに渡航費(航空券代・旅行保険・引率代などを含む)、JOAI開催およびIOAI日本代表選抜に係る諸経費の財源となります。
出典:JOAI 2025 受験案内
今回の課題
概要
今回のコンペティションの概要です。表・画像・テキストの情報を用いてガスの分類を行うタスク になります。
このコンペティションでは、表・画像・テキストのマルチモーダル情報から、ガスに関する分類タスクに取り組んでいただきます。各データは、ガスセンサによる2つの測定値と、同時に赤外線カメラで撮影された画像、および画像を説明したテキストから成ります。ガスは「Perfume」「Smoke」の2種類存在し、それぞれの有無を考慮した4つのラベルが存在します。(Perfume, Smoke, Mixed, NoGas)
(Kaggle のコンペティションページからの引用)
データ
データ数
データ数は、以下のとおりです。test データのうち 50% が Public、残り 50% が Private データ となります。コンペ期間中は Public の結果が表示されており、コンペ終了後に Private の結果が表示され、そのスコアによって入賞が決まります。
- train: 5760件
- test: 640件(Public, Private で 50% ずつ)
特徴量
入力として用いる特徴量は、センサに関する測定値が2種類、赤外線画像、そしてその画像を説明したテキスト の 4 種類になります。そして、正解ラベルが用意されています。
- MQ8 - ガスセンサによる測定値。
- MQ5 - ガスセンサによる測定値。
- Caption - 画像を説明したテキスト。本コンペティションで提供している画像は一部を切り抜いているが、このテキストは切り抜き前の画像を基に生成した。
- image_path_uuid - images フォルダ内の対応する画像。
- Gas - 正解ラベル。
使用可能な事前学習済みモデル
今回のコンペでは、公平性の観点から使用可能な事前学習済みモデルが定められていました。
| 種別 | モデル名 | 呼び出し | リンク |
|---|---|---|---|
| 画像 | resnet50.a1h_in1k | timmで指定可能 | https://huggingface.co/timm/resnet50.a1h_in1k |
| 言語 | FacebookAI/roberta-base | transformersのAutoModelで指定可能 | https://huggingface.co/FacebookAI/roberta-base |
| 言語 | microsoft/deberta-base | transformersのAutoModelで指定可能 | https://huggingface.co/microsoft/deberta-base |
| マルチモーダル | openai/clip-vit-base-patch32 | transformersのCLIPModelで指定可能 | https://huggingface.co/openai/clip-vit-base-patch32 |
ルール
主なルールは、以下のようになります。
- 使用言語:Python
- ChatGPT、Cursor などの生成 AI ツールの利用は可能
- 個人戦
- 開催期間中は、当該コンペティションの内容に関して SNS などでの情報発信は禁止
- 競技性の担保のため、開催期間中は参加者からのコードや知見の公開も禁止する
評価方法
提出した予測値の Private スコアで評価が行われます。
- コンペティションにおける提出スコアによって、順位と表彰が決定されます。
実戦
ここからは実際に、私がどのようにタスクに取り組み、スコアを上げていくことができたか紹介していきます。
0. まずはデータ分析から!!
今回の大会では、チュートリアルコードが配布 されました。JOAI は単に IOAI の選抜を行う目的だけでなく、人工知能の勉強を始めてみたい人にそのきっかけを与える目的も持っているため、初心者でもスコアが出せるように、最低限のコードを用意してくれています。
チュートリアルコードには、2 種類ありました。1 つ目は探索的データ解析(EDA)用のコード、2 つ目は学習・推論用のコード です。EDA とはデータの分析を行うことで、初期段階にデータの概要を把握したり、モデルを改善する段階でデータの可視化を行なったりするために行います。まずはこのコードを用いて、簡単なデータの分析を行います。
最初に確認するべきは、ラベルごとのデータの分布です。データの分布に偏りがある場合は、それに応じた工夫が必要になります。しかし、5,760 件ある train データの分布は 1,440 件ずつ均等にあるようなので特に気にしなくてよさそうです。
| NoGas | Perfume | Mixture | Smoke |
|---|---|---|---|
| 1,440 | 1,440 | 1,440 | 1,440 |
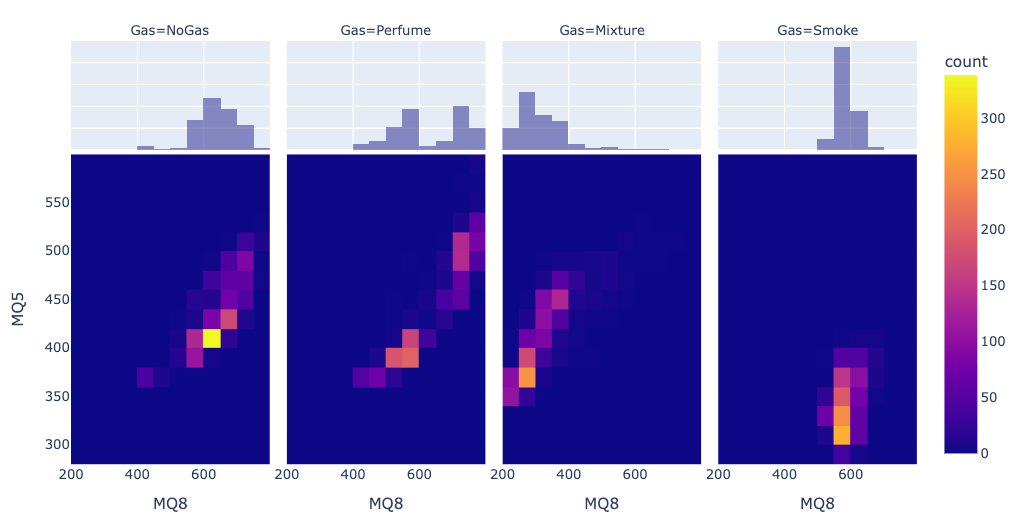
テーブルデータ については、画像やテキストデータと違って、直接ラベルとの関係を見ることができる ので、最初に確認しておくと良いでしょう。ラベルごとのヒートマップ(↓)を見ると、ラベルごとにまとまったクラスターになっていることがわかります。特に、"Mixture"、"Smoke" は独立した位置に固まっているのでテーブルデータだけでも十分に予測できそうです。一方で、"NoGas"、"Perfume" は近い位置に分布しているため、他の特徴量で補わない限りこれらを区別するのは難しいでしょう。
最後に、画像・テキストデータがどんなものか見ておきましょう。 以下は、"Perfume" ラベルの例です。温度情報を表す赤外線画像とその画像を説明するテキスト情報がセットになっています。テキストでは、熱源や冷たい領域の存在、色や温度について言及されています。

クラス: Perfume、対応するテキスト: Thermal image shows a scene with varying temperatures, ranging from 25°C to 36°C. Hotter areas (red/orange) are present, likely indicating heat sources or objects, alongside cooler areas
(blue/green). The image is unclear as to what specific objects are being imaged.
1. 用意されているチュートリアルコードを実行してみる
学習・推論用のコードでは、AI についての簡単な説明や python の使い方から始まり、実際に学習や推論を行なってスコアを出すところまで実装 してくれています。(ここでは、学習データのうち画像データのみを入力として "resnet50.a1h_in1k" による学習を行うコードが実装されていました。)CV(クロスバリデーション)[1]まで実装されていたり、どういうところを試すと良いかといったことまで書かれているため、初心者でも取りかかりやすくなっています。
チュートリアルコードを用いて学習・推論した結果を見てみたところ、その時点で F1 スコアが 0.89 まで出ました。その値を基準に少しでも高いスコアを出すことが目標になります。(チュートリアルの時点で高い値が出ていたので、かなりシビアな戦いになるだろうなと感じていました。)
2. テーブルデータとテキストデータを追加する
2.1. テーブルデータの処理を追加
学習データの特徴量は 4 種類あります。センサーの計測値のテーブルデータ、赤外線カメラで撮影された画像データ、そしてその画像を説明したテキストデータです。いわゆるマルチモーダル学習というやつですね..。これら、"形式の異なるデータをどのように統合して処理するか" がカギになってきます。
チュートリアルコードで既に画像データを学習するモデルが用意されているので、そこに追加する形でテーブルデータの処理部分を実装 しました。ここでの実装は、単純に MLP[2] を利用してテーブルデータを処理するものです。(最もシンプルな構造で試してみて、結果を見て改善していくというのが堅実だと思います。)
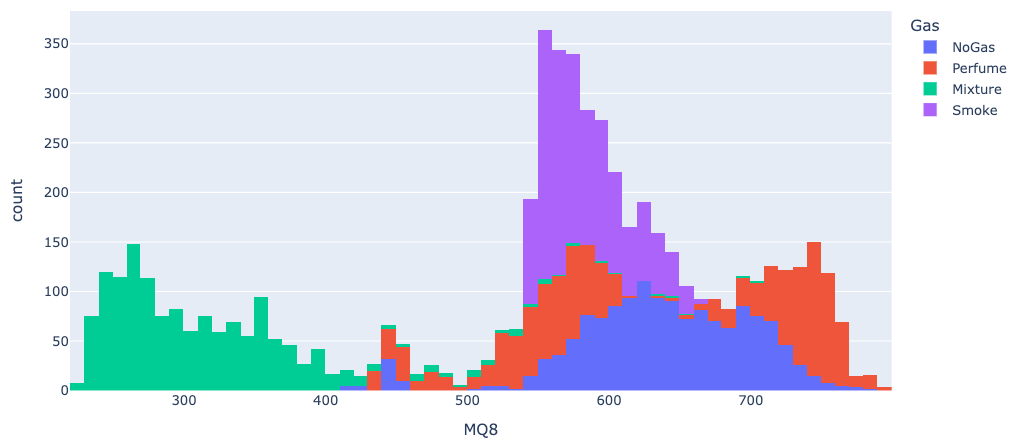
train データにおける MQ8 の分布(ラベルごとに偏りが見られる)
2.2. テキストデータの処理を追加
さらにテキストデータの処理部分を実装していきます。言語モデルとしては、以下の 3 種類の事前学習済みモデルの使用が認められています。
- "FacebookAI/roberta-base"
- "microsoft/deberta-base"
- "openai/clip-vit-base-patch32"
まず CLIP は画像と言語を同時に扱うことができるマルチモーダルモデルです。画像と言語の情報を同じ特徴空間にマッピングするように学習を行っています。しかし、チュートリアルコードで既に実装されている "resnet50.a1h_in1k" を利用したかったことから、CLIP の使用は一旦後回しにします。
二つの言語モデルについては、RoBERTa のモデル構造を改善したのが DeBERTa であるため、"microsoft/deberta-base" を使用することにします。前節で実装したモデルに DeBERTa の出力を追加して、テーブルデータ、画像データ、テキストデータ全ての情報を元に分類が行われるようにしました。

テキストデータのトークン数の分布(意図せぬ切り捨てが発生しないよう確認しておく)
2.3. テーブル、画像、テキストデータの統合
モデル構造としては、画像を入力とした ResNet-50 の出力、テーブルデータを入力とした MLP の出力、テキストデータを入力とした DeBERTa の出力を MLP に入力して 4 値の分類を行えるようにしました。epoch 数は 30 程度で学習を回しました。

学習を試してみたところ、0.95 ~ 0.97 程度のスコアが出ました!
画像データだけでも 0.89 あったので当然と言えば当然なのですが、自分で実装したモデルでスコアが上がると嬉しいものです..。
2.4. CLIP も試してみたが..。
今度はCLIPを使って、画像、言語を同時に扱ってみます。
先ほども説明したように CLIP は画像と言語を同時に扱うことができるマルチモーダルモデルです。画像と言語の情報を同じ特徴空間にマッピングするように学習 を行っています。画像と言語を同じように扱えることから精度向上が期待できます。

出典:OpenAI CLIP
しかし、実際に実装して学習してみると、スコアは 0.95 前後となり、改善は見られませんでした。スコアが上がらなかった原因を、以下のように考えました。
CLIP は通常のカメラで撮影された自然画像を主対象とする
→(おそらくだが、、)赤外線画像などは学習データに含まれない
→ 赤外線画像とその説明をしたテキストという状況に効果を発揮できない
チューニング次第で精度が向上する可能性はありますが、現状として、ResNet-50、DeBERTa を使ったモデルの方が精度が出ているため、とりあえずそっちの方針で行くことにします。
3. 順調だったのは、ここまでだった...
ここまで順調にスコアが上がってきましたが、ここからが大変でした。自分なりに色々考えて試してみるのですが、スコアの変動は多少あれど 決定的な精度の向上が見られない状態が続きます。 結果としては、ここから最終日前日まで特に改善ができず停滞することになります。
試してみたことは、大雑把にこんな感じです。
-
データ拡張:画像をランダムに切り抜く、ランダムにノイズを加えるなど
→ 明確な違いは確認できず。とりあえず採用。 -
学習率:初期学習率とスケジューラの設定
→ 初期学習率を 1e-4、スケジューラを CosineAnnealingLR とするのがよさそう。 -
モデル構造の変更:NN の層を増やす、Attention 機構の導入など
→ 特に精度は変わらず。 -
その他パラメータの変更:正則化における weight_decay、バッチ数など
→ 色々試して良さげなものを設定。大きな精度向上は見られず。
モデル構造の変更が一番効果を発揮すると考えていたのですが、なかなか精度は上がりませんでした。今回は データがかなり綺麗なため、現状のシンプルなモデルで十分特徴が捉えられる ということなのでしょう。ということは、ここから精度を上げるためには、モデル構造よりも もっと根本的な学習の仕方に関わる部分 に注目するべきなのでは..?と考えました。
4. 起死回生の一手!!
4.1. テキストデータ使う意味なくない??
ここで、どのようなデータが間違っているのか確かめてみましょう。調べてみると、やはり "NoGas" 、"Perfume" の 2 つの分類の誤りが多いようでした。そこで、"NoGas" ラベルで予測を誤っているデータを見てみます。

クラス: NoGas、対応するテキスト: Thermal image shows a gas leak indicated by a plume of warmer temperatures (yellow/red) rising vertically. Surrounding area is cooler (green/blue). Temperature range is 20-31°C.
...........!!
Thermal image shows a gas leak(熱画像にはガス漏れの様子が確認できます)...??
"NoGas" なのに、ガス漏れしてると断言している...??
試しに、"gas" という文字列が含まれているデータ件数をラベルごとに調べてみると、次のようになりました。(各ラベルのデータは 1,440 件ずつ)
| Perfume | Smoke | NoGas | Mixture |
|---|---|---|---|
| 258 | 236 | 108 | 20 |
"NoGas" ラベルでもそれなりに "gas" という文字列を含むデータがあることがわかります。
実際にテキストを確認してみると、"Possible gas leak indicated by warmer areas."(温度の高い領域が、ガス漏れの可能性を示唆しています)のように断言はしていないものもありますが、それでもこの情報によってバイアスはかかってしまうでしょう。
こうなってくると、"テキスト情報に意味があるのか" 考える必要が生じます。そもそもテキストデータは画像データの内容を説明したものになります。つまり、テキストデータを追加することで情報量が大きく増えるわけではありません。しかし、その情報が 予測結果に対して良くないバイアスをかけている可能性 があるということです。
以上より、このタイミングでテキストデータを使用することをやめました。 その結果としては、スコアは少しよくなった??程度でしたが、バイアスが除かれて安定感は増しているようにも感じました。(希望的観測含む)
4.2. 汎化性能の "低下" を図る!!
テキストデータの排除は、目に見える大きな変化は生み出せませんでした。
しかし、ここで決定的な分岐点を迎えます。
4.2.1. 学習し続けても精度が悪化しない...?
学習している際の loss の変化として、↓のような画像をよく見ます。
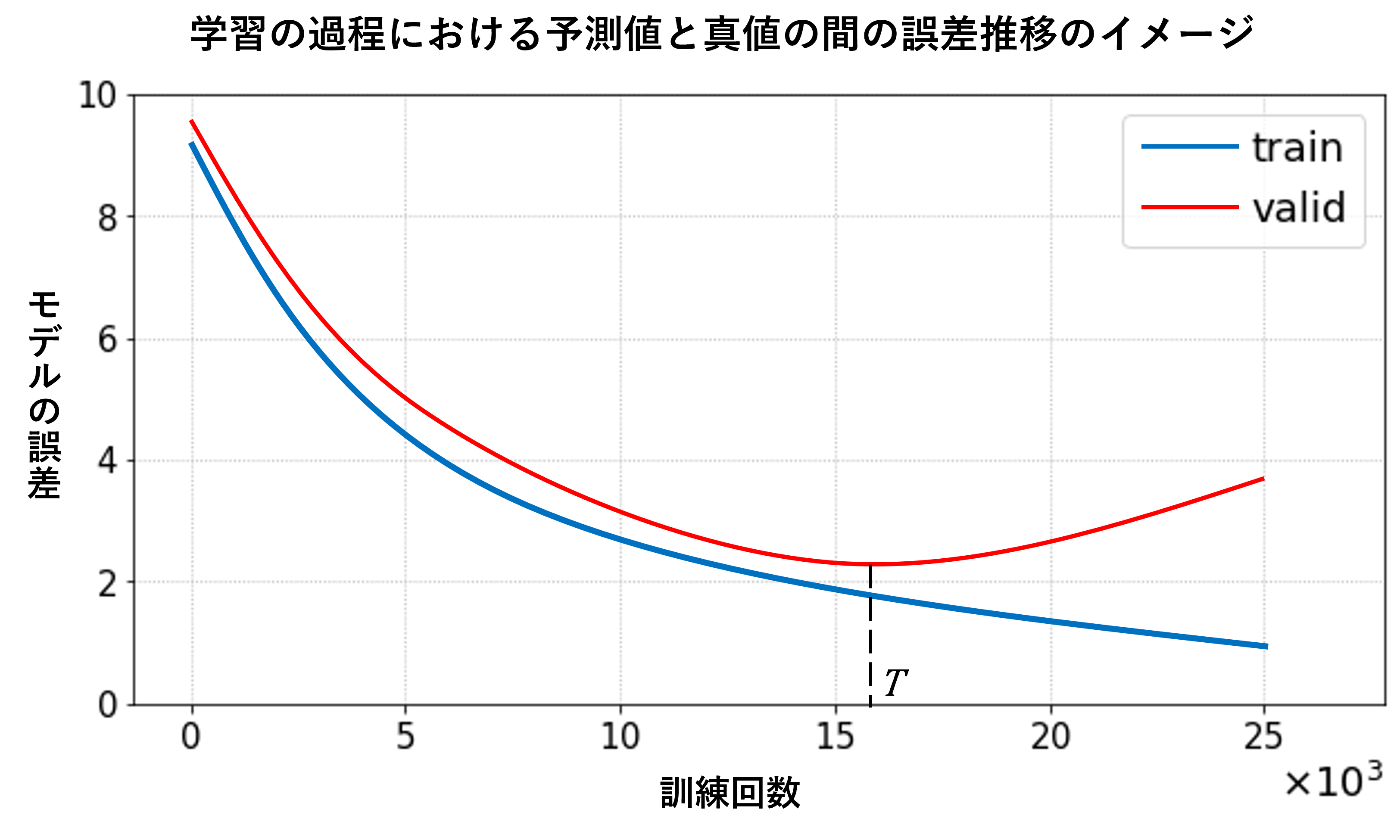
){kind=link}
「訓練データの loss は学習するにつれて下がっていくが、評価データの loss は一定まで学習した後に上がっていく。これが過学習 であり、その一番下がったタイミングが程よく学習が進みつつ、汎化性能も保証されている状態である。」これは一般的に 機械学習のトレードオフ の説明で語られる内容です。
しかし、今回のタスクにおいて、学習曲線は↓のようになっていました。

訓練データの loss は学習するにつれて下がっている一方、評価データの loss、F1 スコアは停滞してはいるものの悪化しているという感じでもなかったのです。
「学習を続けたら必ず過学習を起こして、評価データに対する精度は悪くなっていく」、そのように理解していたのですが、今回のデータみたいに綺麗なデータであれば過学習を起こさない(あるいは起こしづらい)ということにここでようやく気づきました。
そうなると、ここまで当然のように 過学習を起こさない対策(データ拡張、Dropoutなど) をしていたのですが、それがむしろ 表現力を削いでいた のではないかという考えに至ります。そこで、ここからはそれらの手法について改めて吟味することにします。
(学習曲線の形ごとの原因や対策について、↓ の記事がとても参考になりました。もっと早くこの記事を見ておきたかった...)
4.2.2. 汎化能力を上げるためにやっていたことを選別する
汎化能力を上げるために行なっていたことは主に以下のようになります。
- データ拡張
- 正則化
- Dropout
まず データ拡張 についてです。データ拡張で行っていたのは、
- RandomResizedCrop():ランダムに画像を切り抜く
- RandomHorizontalFlip():左右反転
- ノイズの追加
の 3 つです。このうち切り抜き処理や左右反転については、画像のパターンを増やす意味で残しておくとして、ノイズの追加は、言葉通り学習におけるノイズになっていると判断し排除しました。
次に、正則化[3] です。正則化をすることで表現力が落ちていると考えて、一旦排除してみました。しかし、その結果スコアが安定しなくなってしまったので、色々試してみたところ、正則化のパラメータ weight_decay を 1e-4 にしたときに最もスコアが安定したので、その値を採用しました。
最後に、Dropout[4] です。このテクニックはニューロンをランダムに無効化するのですが、学習の途中でノイズを加えるような処理なので、これについても学習におけるノイズになっていると判断しました。
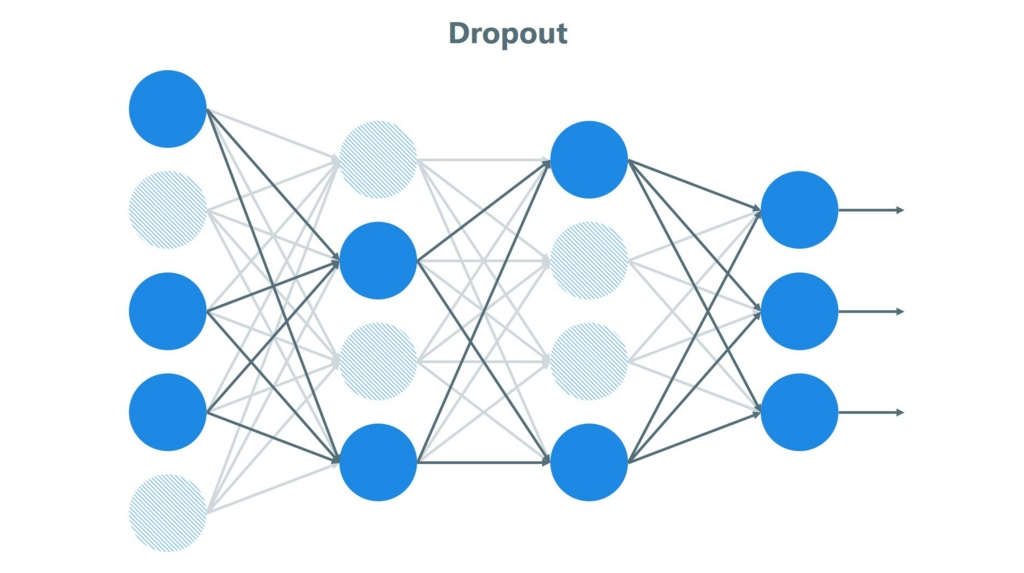
出典:Hatena Blog 過学習とDropoutについて
実際に少しずつ Dropout する割合を減らしていくと、徐々にスコアが上昇しました。最終的に 完全に Dropout を排除することで、スコアが上昇して、かなり安定 するようになりました!(この時点で0.98台が出てくるようになりました。
5. ここで最終調整のフェーズに入る...
Dropout を省いてノイズを減らすことによって精度が高くなり安定してきたので、あとは パラメータや epoch 数の調整 に入る段階になります。
パラメータについては、少し変えたくらいでは大きな影響はないので、いろいろ試してみてなんとなく良さげだと感じたものを選ぶくらいでも良い思います。(optuna などのライブラリを用いてパラメータ探索することもできますが、かなり時間はかかります。)
epoch 数については、とりあえずこれまでやってきた通りに 30 epoch で学習をしてみたところ学習曲線が以下のようになりました。loss は順調に下がっていますが、F1 スコアがまだ少し不安定に振動しているように見えます。過学習が起きないのであれば、さらに epoch 数を増やして精度の上昇、安定を目指す のがよさそうです。

ということで 100 epoch で学習を回してみた結果 が以下になります。Valid Loss、F1 スコアの変動を見ると、60 epoch を超えたあたりから安定 している様子が見られます。このグラフはCV における 1 回の学習によるものですが、CV 全体の平均の F1 スコアも 0.9906 と高い値になり、良い学習が行えたと言えるでしょう。最終的には、CV で学習した 5 つのモデルをアンサンブルした予測を行い、提出しました。

6. 結果!!
まず Public の結果ですが、コンペ終了時点で 3 位に入っていました!!
このまま逃げ切りたいところですが、もちろんテストデータが変わると結果も変わってくるので不安は残ります..。

プライバシー保護の観点から、他の参加者の情報は伏せています。
そして、運命の結果発表...!!
結果は...!!
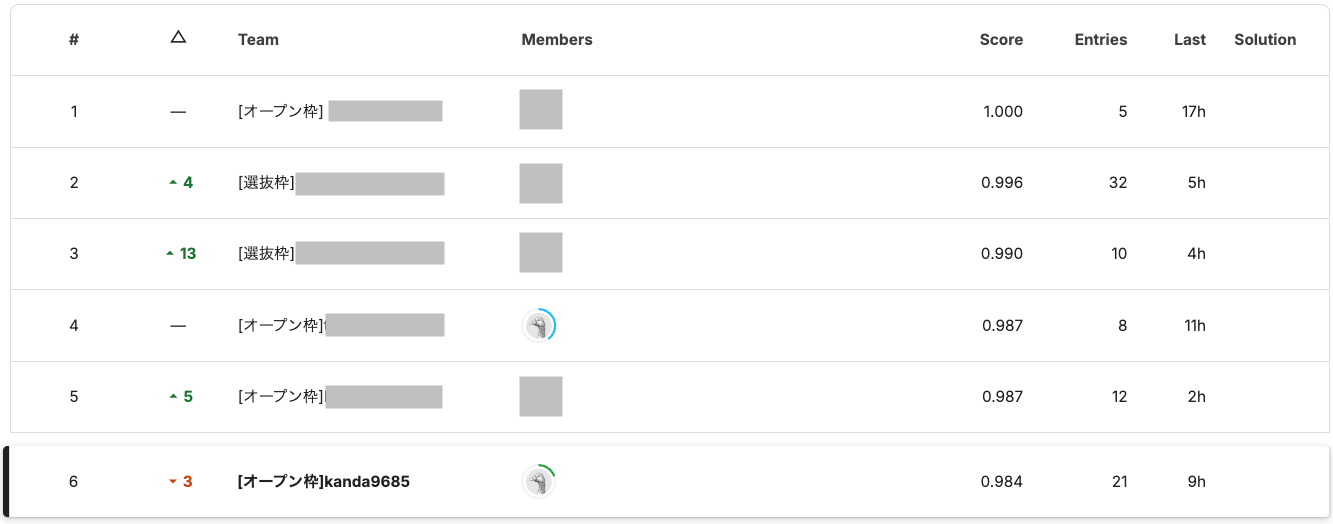
...6 位でした!!!(オープン枠では 4 位!!)
Public に比べて少しスコアも落ちて、順位も落ちましたが許容範囲でしょう..。
今回の参加者は、選抜枠が 51 名で、オープン枠が 71 名でした。
オープン枠で上位 10% に入っているので、金賞です!!
それはそうと、1 位の方は Public、Private でともに 1.000 を出しているようです。 640 件あるデータ全てに対して全問正解...恐ろしいですね。
まとめ
...ということで改めて、第一回人工知能オリンピックにて金賞をいただくことができました!! 🎉
これまで機械学習や Deep Learning というトピックに興味を持って個人的に勉強をしてきましたが、ここまで実践的にモデルを組んで精度向上に取り組んだのは初めての経験でした。やはり実際に自分なりに色々考えて実装してみることで、テキストに書いてある知識からは得られない経験 が得られるなと感じました。
また今回、選抜枠で参加している高校生や高専生の方がたくさんいて(というかむしろ彼らが主役なのですが..)良い刺激を受けることができました。私が人工知能に興味を持ったのは大学生に入ってからなので、高校生のうちから 難しい分野に興味を持って、コンペティションに挑戦してみようと思える挑戦心 が素晴らしいなと感じました。しかも、高いスコアを出している選抜枠の方も多くいて、本当に感心しました。
最後に、このような貴重な機会を提供してくださった関係者の皆さま、本当にありがとうございました。 JOAI は、年齢や経験に関係なく、挑戦したいという気持ちがあれば誰でも参加できる素晴らしいコンペティションだと感じました。今回参加された皆さん、そしてこれから挑戦を考えている方々にとっても、この経験が新たな一歩になるだろうと思っています。
また、日本代表に選抜された皆さんの健闘を心よりお祈りしています。世界の舞台でも存分に力を発揮されることを願っています...!! 🌍🔥🎌
Discussion