合格発表の瞬間に内容をLINEへ送りたかった話
初記事です。よろしくお願いします。
Introduction
大学入試が終わって合格発表を待ってる期間って暇ですよね。それで、せっかくなので高校生最後の思い出になるものを作りたいと思って、こんなことを考えていました。
- 合格発表ページ (番号が一覧で掲示されるタイプ) をスクレイピングし合格した番号のリストと自分の合否を取得するコードを書く
- 1のデータを返すAPIを作る
- 2のAPIを叩いてデータを取得し、メッセージとしてLINEに送る仕組みを作る
で、合格発表時刻 (3/10 12:00) ちょうどに自動で1・2・3が実行されるようにしておけば、他の人間たちがアクセスしてページが重くなる前に合格発表に関する情報を取得して、ゆっくりLINEで眺めることができるというわけです。ちなみに、1でデータを取得したならそのまま直接 LINE Messaging API を叩けばいいところですが、それぞれ「1:Go 入門として Go でスクレイピングしてみたい」「2:API 作ってみたい」「3:Messaging API 使ってみたい」という動機があり、2で API (ごく簡単なものですが) を作る経験をするためにこの構成にしました。
対象ページは京大工学部の合格発表ページです。また、2のホスティングには Heroku 、3には GAS を採用しました。
GAS も初めて触りましたが、これはほぼ JS でそこまで困ることなく書けたので、この記事では解説は最小限に留め、1のスクレイピングに焦点を当てたいと思います。以下が GAS のコード Ver.1 になります。
let apiURL = PropertiesService.getScriptProperties().getProperty('API_URL')
let userID = PropertiesService.getScriptProperties().getProperty('USER_ID')
let accessToken = PropertiesService.getScriptProperties().getProperty('CHANNEL_ACCESS_TOKEN')
function main() { // 3/10 12:00 実行
// 確実にスクレイピング完了まで待つ (ちょっと長めに)
Utilities.sleep(3 * 1000)
let jsonData = GetJSONdata(apiURL)
let idList = jsonData["id_list"]
let message = idList.join("\n")
PushMessage(message)
// 合格or不合格
let passed = jsonData["passed"]
let result = "undifined"
if (passed) {
result = "合格"
} else {
result = "不合格"
}
PushMessage(result)
}
function AwakeHeroku(){ // 3/10 11:45 実行
// 事前に Heroku をスリーブから叩き起こす
UrlFetchApp.fetch(apiURL)
}
function GetJSONdata(url){
let res = UrlFetchApp.fetch(url).getContentText()
return JSON.parse(res)
}
function PushMessage(messageText){
let url = 'https://api.line.me/v2/bot/message/push'
let headers = {
'Content-Type': 'application/json; charset=UTF-8',
'Authorization': 'Bearer ' + accessToken,
}
let postData = {
'to': userID,
'messages': {
'type': 'text',
'text': messageText,
}
}
let options = {
'method': 'post',
'headers': headers,
'payload': JSON.stringify(postData),
}
return UrlFetchApp.fetch(url, options)
}
Scraping
情報収集
では本題に入ります。早速ですが、重大な問題があります。勘のいい方 or 京大の先輩方は気づいたかもしれませんが、合格発表前はそもそも対象ページがWeb上に存在しないのです。ページ自体が合格発表のタイミングで公開されるので、事前にURLも分かりませんし、HTMLの構造も当然分かりません。これでは話が進まないので、YouTubeで京大の合格発表ページが写り込んでいる動画を探しまくって情報収集しました。その結果分かったことは、
- 発表時刻に、このページに各学科名のリンクが並ぶ (:Aページとする)
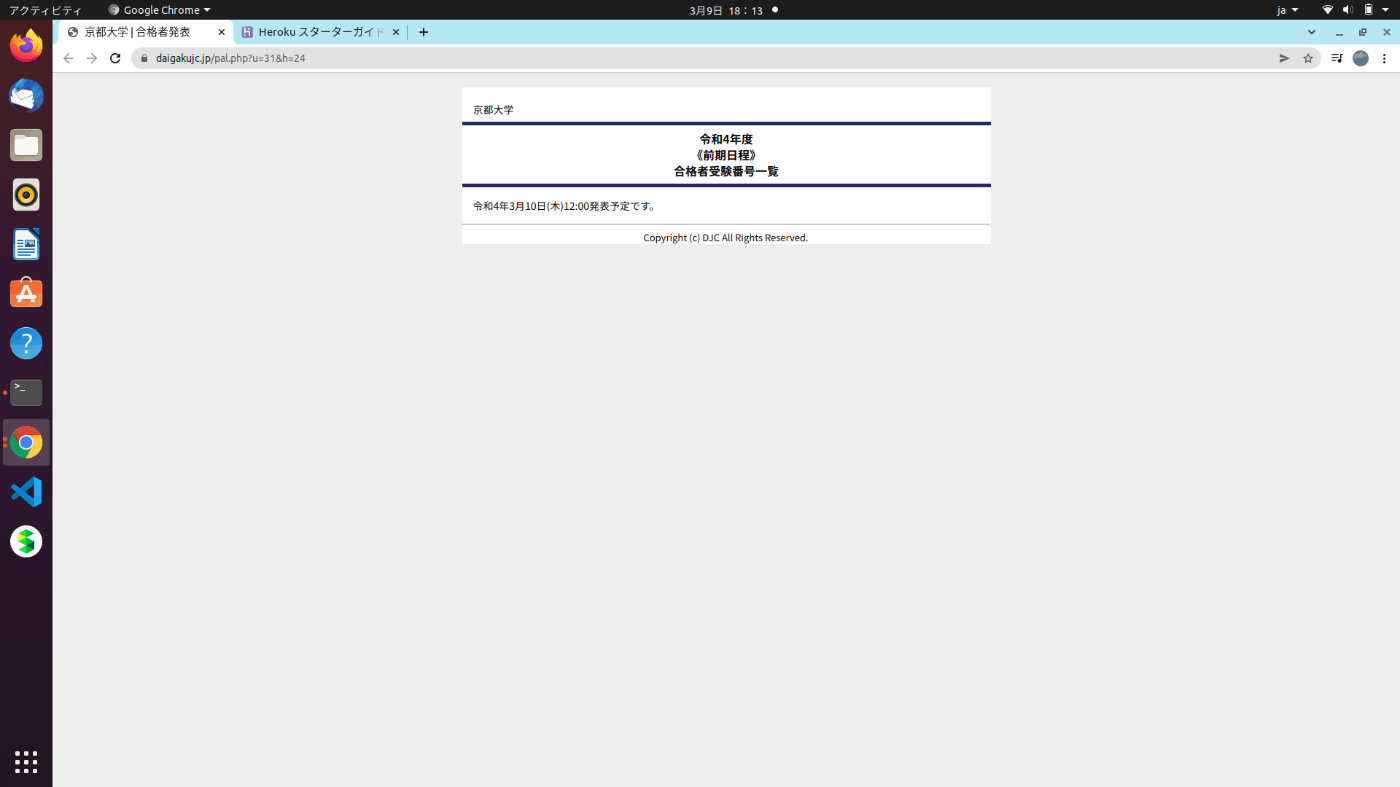
発表前 - 工学部のリンクで飛んだ先が工学部の発表ページ。そのURLは上記ページのURLにクエリパラメータがくっついた形をしているが、工学部のパラメータが毎年同じとは限らないかもしれないとなると、予想がつかない
- 発表ページ自体は、簡単な説明と縦に並んだ番号があるだけ (:Bページとする)
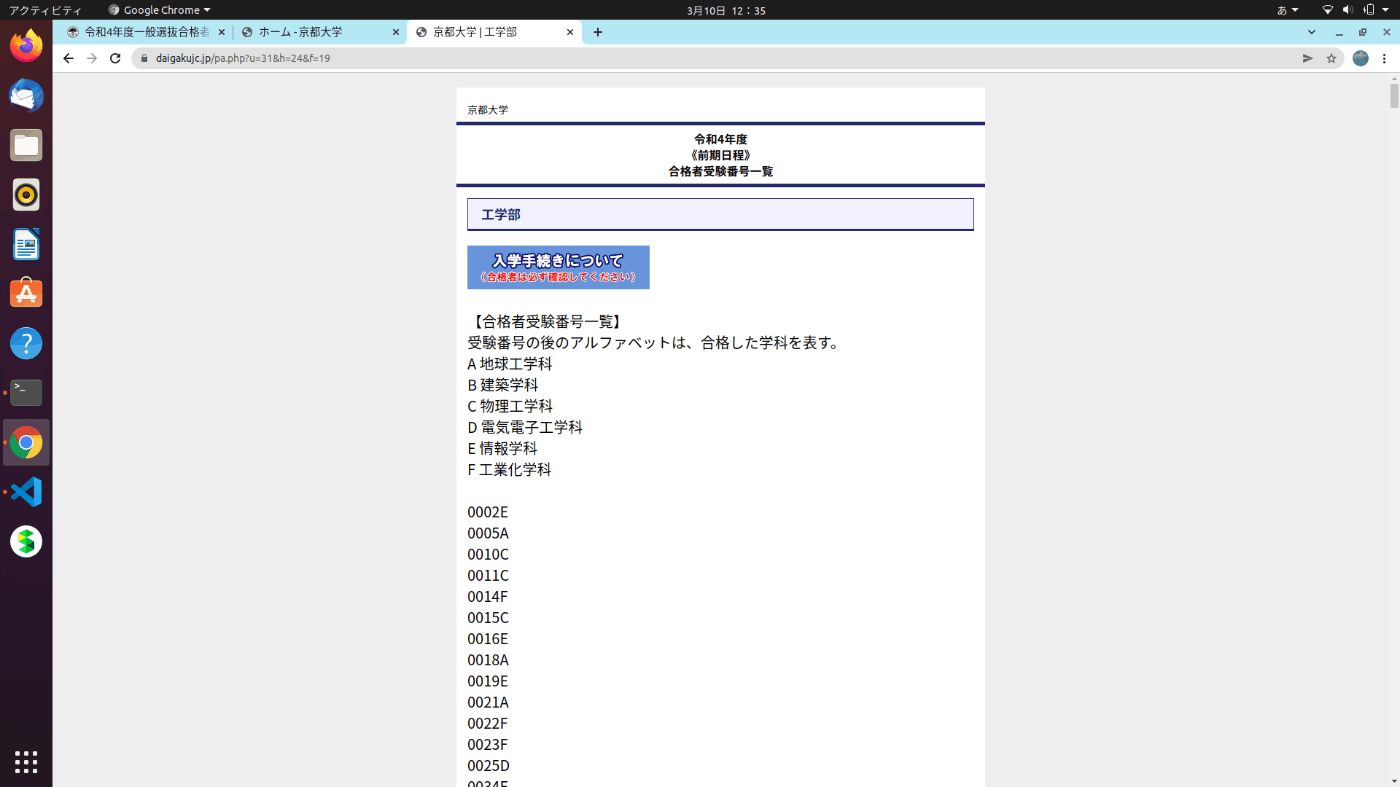
これは発表後に撮った実際の写真だが、こんな感じなのは動画で事前に確認できた
くらいです。この条件で、発表の瞬間にBページから
- 合格した「番号+アルファベット」(:ID とする) (Bページ画像参照) の一覧
- 自分の合否
を取得するのが目標です。前者ができれば後者は容易なので、前者をなんとかすることを考えることになります。Go の基礎文法をざっと勉強してから、Go でのスクレイピングにはどんな package が使えるか調べてみたところ、goquery という package が、GitHub のスター数が十分多く、最終更新が去年の10月 (執筆時点) で安定してそう、かつネット上の日本語記事数の点では頭一つ抜けているように感じたので、今回はこれを採用することにしました。
構想
ということで、goquery に慣れるべくいろいろ書いてみながら、今回の目標を達成するために次のような方針を立てました。
- Aページをスクレイピングし、「 text が工学部となっている a タグの href 」を取得する。
- 必要なら href を"https://〜"の形に加工する。このURLを使うことでBページをスクレイピングすることができる。
- Bページをスクレイピングし、合格した ID のリストを取得する。
ただし、最初に書いたようにBページのHTMLが事前に分からないため、ここは想像に頼るしかないです。当然テストも不可能です。僕は、先程の写真のイメージから以下のような感じのHTMLを想定しました。
<!--略-->
<body>
<hN class="school">工学部</hN>
<div class="explanation">
<p>[合格者番号一覧]</p>
<p>受験番号の後のアルファベットは、合格した学科を表す。</p>
<p>A 地球工学科</p>
<p>B 建築学科</p>
<p>C 物理工学科</p>
<p>D 電気電子工学科</p>
<p>E 情報学科</p>
<p>F 工業化学科</p>
</div>
<div class="passed-ids">
<p>0007C</p>
<p>0010E</p>
<p>0013C</p>
<p>0014B</p>
<p>0016F</p>
<p>0019B</p>
<p>0020F</p>
<p>0023C</p>
<p>0025A</p>
<!--ID は適当-->
<!--以下略-->
</div>
</body>
</html>
自分が React 好きなのもあり、 ID 部分 (930個くらい) は「Array を map でバラして作った JSX」のようなイメージを無意識に持っていましたが、今にして思えばこの思い込みがダメでした。
それはともかく、このHTMLを想定して書いた Go のコードを以下に示します。
package main
import (
"log"
"regexp"
"strings"
"github.com/PuerkitoBio/goquery"
"golang.org/x/text/encoding/japanese"
"golang.org/x/text/transform"
)
type scrapeInfo struct {
baseURL string
preScrapePath string
examCategory string
examNumber string
}
func scrape(si scrapeInfo) ([]string, bool) {
var (
baseURL = si.baseURL
preScrapePath = si.preScrapePath
myExamCategory = si.examCategory
myExamNumber = si.examNumber
)
var (
preScrapeURL = baseURL + preScrapePath
myCategoryURL string
)
// 1.
href := findHrefOf(myExamCategory, preScrapeURL)
// 2.
if href[0:5] == "https" {
myCategoryURL = href
} else {
myCategoryURL = baseURL + href
}
// 3.
passedIDs := findPassedIDsFrom(myCategoryURL)
iHasPassed := false
for _, id := range passedIDs {
if id[0:4] == myExamNumber {
iHasPassed = true
break
}
}
return passedIDs, iHasPassed
}
func findHrefOf(targetWord, targetURL string) string {
// ページ全体をドキュメントとして読み込む
doc, err := goquery.NewDocument(targetURL)
if err != nil {
log.Fatal(err)
}
var targetHref string
// a タグを調べ上げる
doc.Find("a").EachWithBreak( func(i int, s *goquery.Selection) bool {
href, exists := s.Attr("href")
isTargetTag := (s.Text() == targetWord)
if exists && isTargetTag {
targetHref = href
}
return !isTargetTag
// EachWithBreak ... Each(func) しつつ、func の返り値が false のとき break
// この場合 isTargetTag が true なら break
})
return targetHref
}
func findPassedIDsFrom(targetURL string) []string {
doc, err := goquery.NewDocument(targetURL)
if err != nil {
log.Fatal(err)
}
var (
wordList = strings.Split(doc.Text(), "\n")
// doc.Text()...ドキュメント全体の text を string で返す
// それを \n で Split して配列にしている
passedIDs []string
idPattern = regexp.MustCompile(`[0-2]\d{3}[A-F]`)
// (0001〜2569) + (A〜F) なのでとりあえずこれで
)
for _, word := range wordList {
id := strings.TrimSpace(word)
if idPattern.MatchString(id) {
passedIDs = append(passedIDs, id)
}
}
return passedIDs
}
func main() が入った main.go は別ファイルですが、これは時間管理して実際のデータで scrape() してサーバー立ててるだけなので、ここではわざわざ立ち入らないことにします。一応 Github のリンクをおいておくので、気になる方は覗いてください。
findHrefOf は適当な a タグのあるサイトを使わせていただいて、findPassedIDsFrom はさっきのHTMLをそれっぽくスタイリングしたものを localhost して、それぞれ疑似的に単体テストしながら書いてき、BページのHTMLがあれで合っていればこのコードでいけそうだ、という段階まで来ました。
文字コード問題
ある時、試しに FindHrefOf の内容をいじって ( a タグではなく div タグを探し、内容によらず text を全て出力させる) 、AページのURLで実行してみたところ、漢字・ひらがなの出力が「工」以外文字化けしてしまいました。nkf で文字コードを確認したところ、ShiftJIS とのこと。実はこのサイトは文字コードが ShiftJIS なのでした。そこで、
あたりを参考に次の関数を作成しました。変換時のエラーは返り値にしない形をとっています。
func convertUTF8toSjis(utf8Str string) string {
encoder := japanese.ShiftJIS.NewEncoder()
sjisStr, _, err := transform.String(encoder, utf8Str)
if err != nil {
log.Fatal(err)
}
return sjisStr
}
おそらくないとは思われますが、万が一「Aページは ShiftJIS だけど、Bページは UTF-8 だった」となっても対応できるように、最初に文字コードの判定をいれて処理を分ける形で findHrefOf を以下のように編集しました。
func findHrefOf(targetWord, targetURL string) string {
doc, err := goquery.NewDocument(targetURL)
if err != nil {
log.Fatal(err)
}
+ var (
+ isUTF8site bool = false //default
+ targetCode string
+ )
+ doc.Find("meta").EachWithBreak(func(i int, s *goquery.Selection) bool {
+ charset, exists := s.Attr("charset")
+ if exists {
+ isUTF8site = (charset == "utf-8" || charset == "UTF-8")
+ }
+ return !exists // meta タグに chrset の記載があったら break
+ // なければ全ての meta タグを探すことになり、isUTF8site = false のまま終了
+ // まともな UTF-8 ページにはこの記載があるはずなので・・・という判断
+ // (ほんとはもっとちゃんと判定すべきかも)
+ })
+ if isUTF8site {
+ targetCode = targetWord
+ } else {
+ targetCode = convertUTF8toSjis(targetWord)
+ }
var targetHref string
doc.Find("a").EachWithBreak(func(i int, s *goquery.Selection) bool {
href, exists := s.Attr("href")
- isTargetTag := (s.Text() == targetWord)
+ isTargetTag := (s.Text() == targetCode)
if exists && isTargetTag {
targetHref = href
}
return !isTargetTag
})
return targetHref
}
これで文字化け問題も解決し、思いつく限り意味のありそうな疑似テストが全てパスするようになったので、たぶんこれでいけるだろうということで Heroku に投入しました。
// +heroku goVersion go1.17
go 1.17
というコメントをいれないと勝手に Heroku デフォルトバージョンの Go をインストールされてしまうなど、定番 (?) の罠に引っかかりながらも、適宜ググって解決し、無事デプロイ・実行まで辿り着きました。その後 GAS の方も (Ver.1 の) 実装が間に合い、あとは発表の瞬間を待つのみとなりました (発表前日の深夜) 。
そして迎えた翌朝、案の定寝過ごして 13:00 くらいに起き出して LINE を見ると・・・
撃沈
何のメッセージも表示されておらず、見事に撃沈してしまいました (テストしていない以上、覚悟はしてましたが) 。ちなみに入試の結果は合格でした。
まず GO の方をざっと調べてみたところスクレイピング自体がうまくできてなさそうだったので、findHrefOf と findPassedIDsFrom の返り値をそれぞれ出力してみると、後者が想定外で
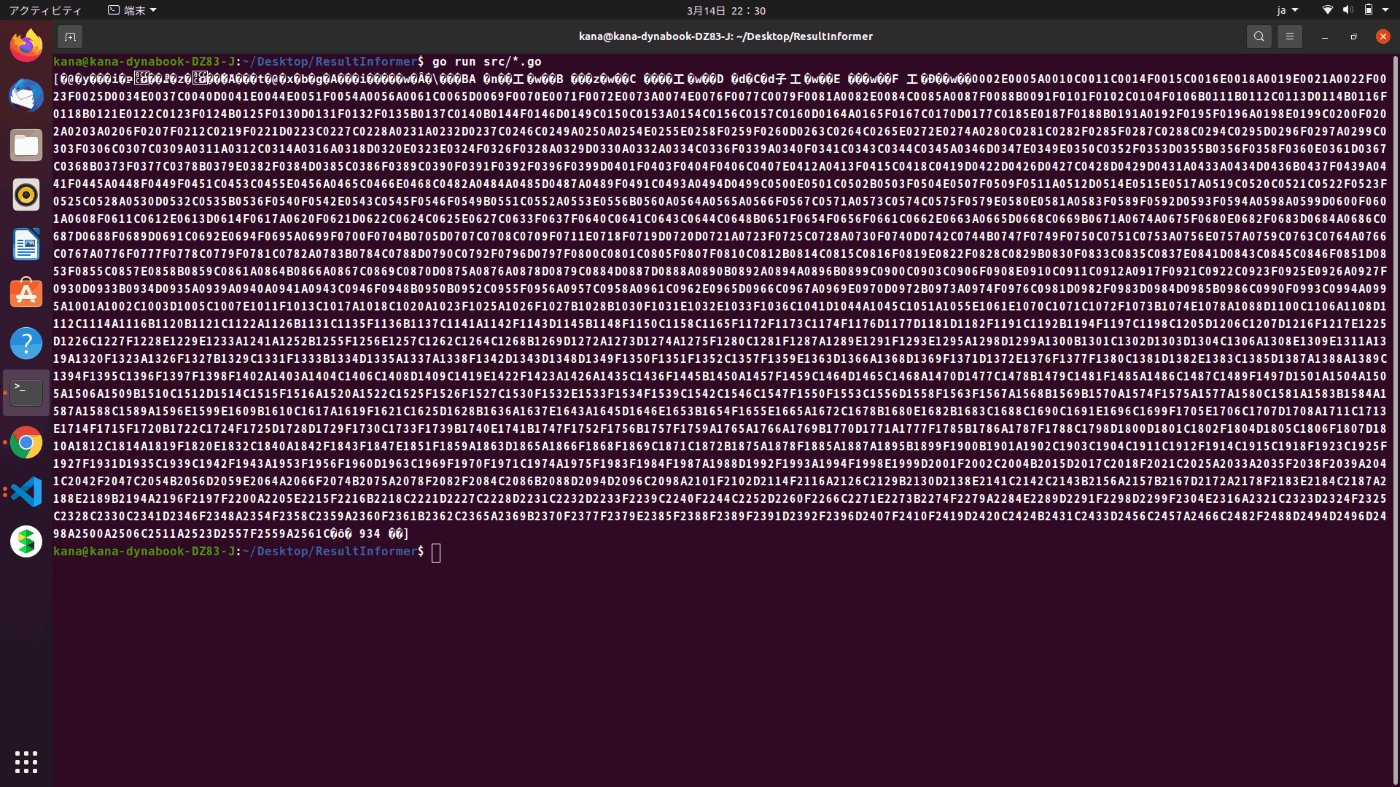
\n で Split したはずなのにされてない 、従って巨大な1つの string ができているという問題が起きていることが判明しました。
解決
Bページが公開されたので、HTMLの答え合わせをしましょう。
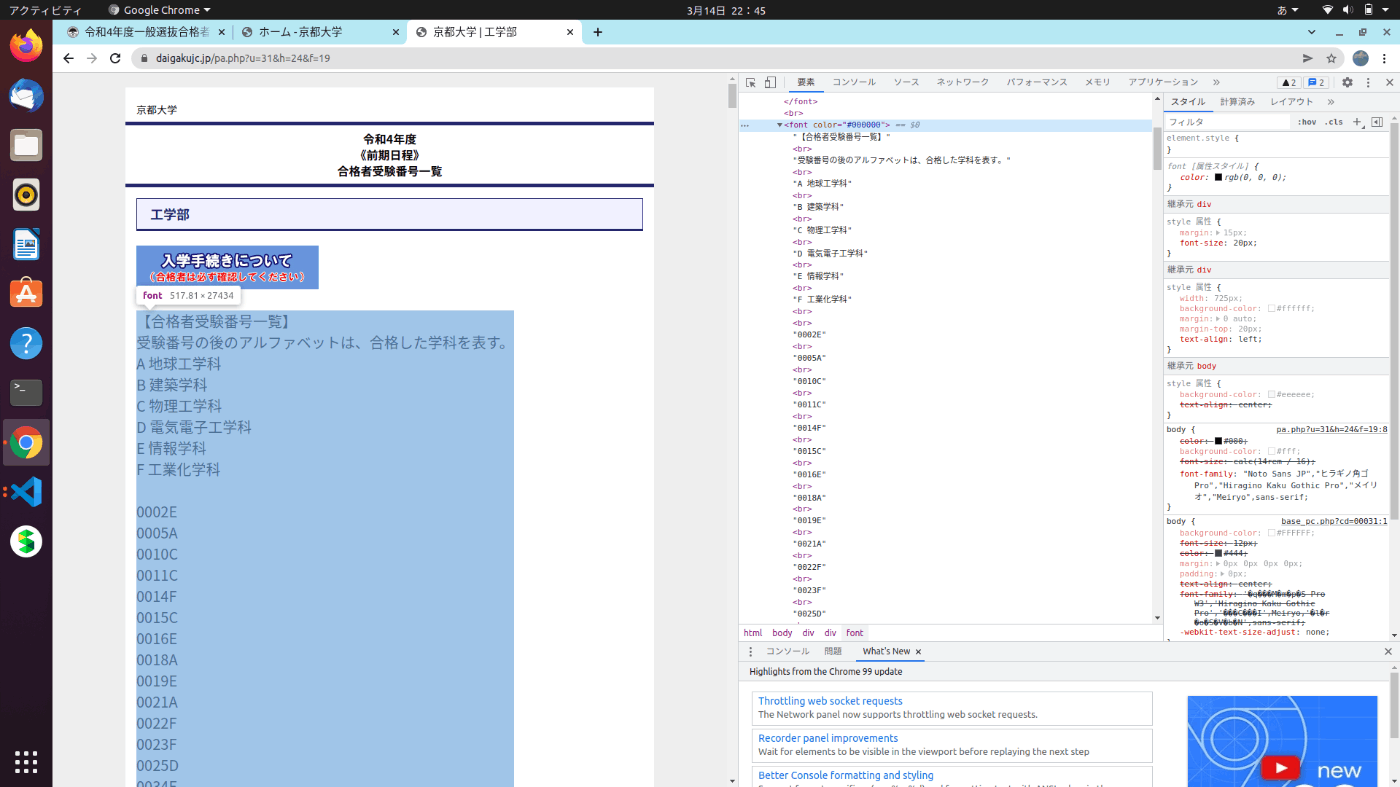
これは!!?
ということで、正解は
<!--略-->
<font color="#000000">
"[合格者受験番号一覧]"
<br>
"受験番号の後のアルファベットは、合格した学科を表す。"
<br>
"A 地球工学科"
<br>
"B 建築学科"
<br>
"C 物理工学科"
<br>
"D 電気電子工学科"
<br>
"E 情報学科"
<br>
"F 工業化学科"
<br>
<br>
"0002E"
<br>
"0005A"
<br>
"0010C"
<br>
"0011C"
<br>
<!--以下略-->
"以上 934 名"
</font>
<!--以下略-->
でした 。。。( ちなみに、<font> と入力するとエディタ上では "font" の部分が赤字で表示されています )
これは予想外でした...。現象としては、<font></font> で囲まれたテキスト全てが、<br> を除いて1つに連結した巨大な文字列になっていて、それは (当然 ID を (930 個くらい) 含むため) idPattern にマッチするので、 findPassedIDsFrom の返り値としてそれが返ってきている、ということのようです (@"_")
この分析をもとに findPassedIDsFrom を書き直します。もとの findPassedIDsFrom
func findPassedIDsFrom(targetURL string) []string {
doc, err := goquery.NewDocument(targetURL)
if err != nil {
log.Fatal(err)
}
var (
wordList = strings.Split(doc.Text(), "\n")
passedIDs []string
idPattern = regexp.MustCompile(`[0-2]\d{3}[A-F]`)
)
for _, word := range wordList {
id := strings.TrimSpace(word)
if idPattern.MatchString(id) {
passedIDs = append(passedIDs, id)
}
}
return passedIDs
}
の返り値があの巨大文字列なので、この文字列をさらに加工することで欲しい配列
{"0002E", "0005A", "0010C", "0011C", /*以下略*/}
を得る方針でいきます。
func findPassedIDsFrom(targetURL string) []string {
doc, err := goquery.NewDocument(targetURL)
if err != nil {
log.Fatal(err)
}
var (
idPattern = regexp.MustCompile(`[0-2]\d{3}[A-F]`)
targetText string
)
// 最初から font タグを探して効率よく巨大文字列を得る
doc.Find("font").EachWithBreak(func(i int, s *goquery.Selection) bool {
str := s.Text()
targetText = str
return !idPattern.MatchString(str)
// 返り値が false になったら (str が idPattern にマッチしたら) 終了
// そもそも1つ (巨大文字列) しかマッチしないのでこれでよい
})
var idStartAt int
// ID が巨大文字列のどこから現れ始めるか調べる
// ごく最初の方から始まるはずなので、単純に前から見ていく
for i, rune := range targetText {
if string(rune) == "0" /* 0002E の 0 */ {
idStartAt = i
break
}
}
var (
idBuilder strings.Builder
passedIDlist []string
)
// const idLen = 5
// 今いるのが ID の何文字目か (0,1,2,3,4) 数えながら繋げていく
// 5 文字繋がるごとに passedIDlist に入れ、0 文字目から数え直す
position := 0
for i, rune := range targetText {
if i >= idStartAt {
// 終了条件 (そこからは ID じゃない条件)
// (最後の「以上〜名」という漢字で引っかかる)
if rune > 'F' /* >'E'> ... >'2'>'1'>'0' */ {
break
}
idBuilder.WriteRune(rune)
if position == 4 {
passedIDlist = append(passedIDlist, idBuilder.String())
idBuilder.Reset()
position = -1
}
position++
}
}
return passedIDlist
}
けっこう試行錯誤した結果ですが、これでそれなりにきれいにまとまってると思います。
完成
これで heroku に再 push し、ようやく GAS の方を見て、問題に気が付きました。冒頭で出した Ver.1 の PushMessage
function PushMessage(messageText){
let url = 'https://api.line.me/v2/bot/message/push'
let headers = {
'Content-Type': 'application/json; charset=UTF-8',
'Authorization': 'Bearer ' + accessToken,
}
let postData = {
'to': userID,
'messages': {
'type': 'text',
'text': messageText,
}
}
let options = {
'method': 'post',
'headers': headers,
'payload': JSON.stringify(postData),
}
return UrlFetchApp.fetch(url, options)
}
で、postData の中の 'messages' の value は message オブジェクトの配列でなければならないのですが、message オブジェクトそのものになっています。メッセージは1つですが
let postData = {
'to': userID,
- 'messages': {
- 'type': 'text',
- 'text': messageText,
- }
+ 'messages': [{
+ 'type': 'text',
+ 'text': messageText,
+ }]
}
と書きます (Ver.2) 。
これで完成......かと思いきや、今度は別のエラーが出てきました。これが今回のラスボス、文字数制限です。これは1メッセージあたり text は 5000 文字以下でなければならないという制限で、passedIDlist を一度に送ると
ID 1つあたり ID + \n で
5 + 1 = 6 (文字)
なので、全体で
6 * 934 > 6 * 900
= 5400
> 5000 (文字)
となり引っかかってしまいます。ID を何個かずつくっつけて1行に入れることで \n を削減して文字数を抑える、といった方法も考えましたが、見づらくなるので、最終的には単純に適当なところで分割して2回送ればいいだろうと考え、
function main() { // 3/10 12:00 実行
// 確実にスクレイピング完了まで待つ (ちょっと長めに)
Utilities.sleep(3 * 1000)
let jsonData = GetJSONdata(apiURL)
let idList = jsonData["id_list"]
- let message = idList.join("\n")
- PushMessage(message)
+ // MessagingAPI の文字数制限 (5000文字) のため2回にわけて送る
+ let message1 = idList.slice(0,501).join("\n")
+ PushMessage(message1)
+ let message2 = idList.slice(501).join("\n")
+ PushMessage(message2)
// 合格or不合格
let passed = jsonData["passed"]
let result = "undifined"
if (passed) {
result = "合格"
} else {
result = "不合格"
}
PushMessage(result)
}
としました (Ver.3) 。すると...

やった!!
ということで、ようやく成功しました。拙いところもあったかと思いますが、最後まで読んでいただいてありがとうございます。
Discussion