Streams APIを活用したCSVパーサ開発とプロパティベーステスト入門
はじめに
最近、OSS で Web Streams API で CSV を取り扱うライブラリを TypeScript で作り始めました。
その際、初めてプロパティベーステスト(Property-based Testing)というテスト手法に触れ、ライブラリの品質を上げることができたので紹介します。
CSV パーサ開発のきっかけ
システム運用中に CSV ファイルの取り扱いに関連する複数の問題が発生しました。
ひとつは、CSV のストリーム処理に由来するパースの不具合。もうひとつは、CSV 仕様の解釈ミスによるものでした。
一見シンプルそうな CSV 仕様にも、予想外の落とし穴が潜んでいると感じ、ストリーミング処理にも対応した堅牢な CSV パーサを自作することを考えはじめました。
また、Node.js の新バージョン(21.x)で Web Streams API が安定版として導入されました[1]。
この新しい潮流を踏まえ、Streaming API などの Web API に対応した開発をはじめました。
CSV ライブラリを作るにあたっての前提知識
CSV の仕様について
CSV の仕様は、RFC 4180 で定義されています。
この仕様では、カンマ(,)で区切られたフィールドと改行コード(CRLF)で区切られたレコードが定義されています。
aaa,bbb,ccc CRLF
zzz,yyy,xxx CRLF
↓ パース
[
['aaa', 'bbb', 'ccc'],
['zzz', 'yyy', 'xxx']
]
ただし、フィールドをダブルクオートで囲む場合の特別なルールも存在します。
次の例で、1 行目の"b""CRLF から 2 行目の bb" にかけてがひとつのフィールドとして扱われます。
JavaScript ではこの値を b"\r\nbb として扱えるようにする必要があります。
"aaa","b"" CRLF
bb","ccc" CRLF
↓ パース
[
['aaa', 'b"\r\nbb', 'ccc']
]
ライブラリのスコープについて
TSV などの CSV 拡張仕様について
CSV は汎用的なデータフォーマットですが、CSV の派生として TSV などもあります。
これらは、CSV のフィールドの区切り文字などを変えた派生の仕様ですが、これらの拡張仕様に関して RFC では言及されておらず、 デファクト・スタンダード的な扱いになっています。
他のライブラリでも区切り文字などの変更はして、これらの派生仕様に作られているものが多いため、今回作るライブラリでもユーザーがこれらの仕様拡張を扱えるように拡張性をもたせられるようにします。
Web Streams API とトランスフォーマー
Web Streams API は、データをチャンクに区切って処理することにより、非同期でメモリ効率のよい形でデータを処理できるようにする API です。

この API におけるトランスフォーマーは、データを変換する役割を持ちます。
今回は、CSV データをパースする Transformer を開発し、効率的なデータ処理を目指します。
Streams API を使うことで、大きな CSV も効率的に扱うことができます。
CSV ストリーミングパーサの設計
今回は 2 つの Transformer を実装します。
CSV パーサの設計では、LexerTransformer と ParserTransformer の 2 つのトランスフォーマーを実装します。
LexerTransformer は文字列をトークン化し、ParserTransformer はトークンストリームを JavaScript オブジェクトに変換します。
LexerTransformer の役割
- チャンクされた文字列をトークン化する。
- フィールド内の改行やクオートを正確に把握する必要があるため。
- トークンはフィールド、フィールドデミリター、レコードデミリターの 3 種類。
- 処理できていないチャンクをバッファリング。
ParserTransformer の役割
- トークンのストリームをもとに、JavaScript オブジェクトに変換する。
- ヘッダ情報をもとにレコードへと変換する。
- 処理できていないトークンのバッファリング。
全体像
さきほどの図に当てはめると下記のようになります。
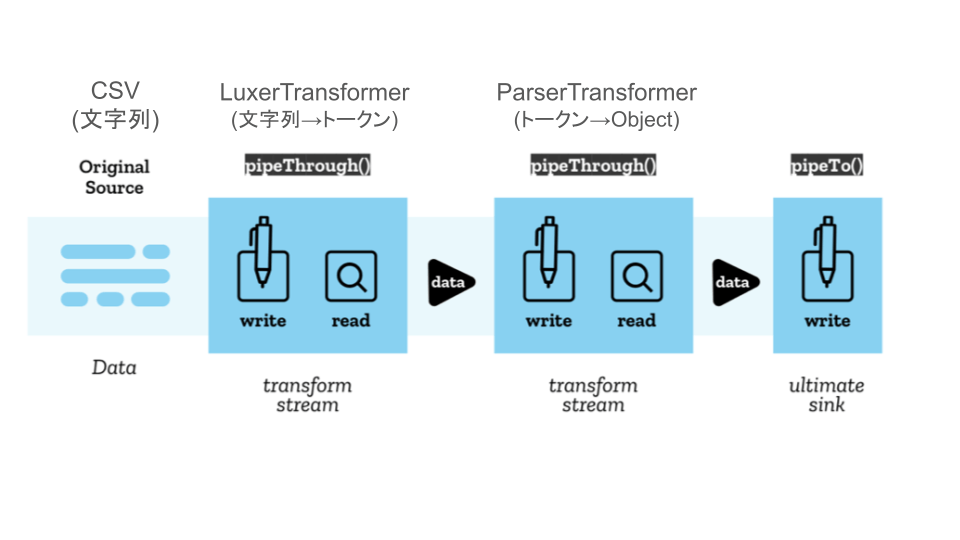
データは下記のように変換されていきます。
# CSV
aaa,bbb,ccc CRLF
zzz,yyy,xxx CRLF
# LexerTransformer での変換後
{ type: Field, value: 'aaa' }
{ type: FieldDelimiter, value: ',' }
{ type: Field, value: 'bbb' }
{ type: FieldDelimiter, value: ',' }
{ type: Field, value: 'ccc' }
{ type: RecordDelimiter, value: '\r\n' }
{ type: Field, value: 'zzz' }
{ type: FieldDelimiter, value: ',' }
{ type: Field, value: 'yyy' }
{ type: FieldDelimiter, value: ',' }
{ type: Field, value: 'xxx' }
{ type: RecordDelimiter, value: '\r\n' }
# ParserTransformerでのパース後
[
{ aaa: 'xxx', bbb: 'yyy', ccc: 'xxx' }
]
LexerTransformer では扱いが難しいフィールドを正確に判定しつつ、ユーザーがデータを使いやすくするためのヘッダ処理などを ParserTransformer に委ねています。
これにより保守がしやすいコードを目指しています。
プロパティベーステスト入門
前置きが長くなってしまいましたが、本題のプロパティベーステストについて紹介します。
そもそも プロパティ とは
プロパティベーステストにおける「プロパティ」とは、ソフトウェアが満たすべき特定の性質や振る舞いのことを指します。
たとえば、CSV パーサでは下記のようなプロパティを保証するようにします。
- どのようなテキストが渡ってきても例外やエラーを投げずに処理を完了すること
- フィールド内のテキストを適切に処理できること
- 設定されたデリミタやクオートがどのような文字種でも柔軟に対応できること
- ヘッダを適切に取り扱いできること
- 大規模データになっても正確に取り扱いできること
- 入力されるテキストがどのようにチャンクわけされても正しくパースされること
プロパティベーステストとは
プロパティベーステストは、ランダム値を用いてソフトウェアが特定のプロパティ(性質)を満たすかどうかを検証するテスト手法です。
従来の自動ユニットテストでは、特定の入力に対する期待される出力を確認することに焦点を当て、要件を満たしていることを確認する目的としていました。
これは既知の動作を確認するのには有効でしたが、未知のバグや不具合を探索するようなテストには不向きでした。
プロパティベーステストでは、ランダムに生成された入力に対し、特定のプロパティや振る舞いが維持されるかを確認します。
これにより、あらゆる可能な入力に対して一貫して正しい動作をするかを確認することを目的として、不具合や想定外がないかを探索できます。
| アプローチ | 観点 | 効果 | |
|---|---|---|---|
|
従来の自動ユニットテスト (プロパティベーステストと比較のために例ベーステストと呼ばれる) |
固定された入力に対して出力の検証 | 特定のケースでの動作確認 | 既知のシナリオでの信頼性確保 (仕様を満たしていることの Check) |
| プロパティベーステスト | ランダム生成された多様な入力で動作を検証 | さまざまな状況での動作確認 | 幅広いケースでの対応力と未発見の問題点の発見 (不具合・想定外などがないかの Explore) |

例ベーステストとプロパティベーステストの関係イメージ図
これらは補完的な関係で、従来の自動ユニットテストを置き換えるのではなく、品質向上のためにプロパティベーステストを導入する形になります。
プロパティベーステストの導入
今回の開発においては、従来のユニットテストではカバーしにくいエッジケースや予期しない入力パターンを検出するためにプロパティベーステストを導入しました。
Node.js では fast-check というプロパティベーステストのフレームワークが有名だったのでこれを採用しました。別途、vitest というテストフレームワークも使用しました。
プロパティベーステストのフレームワークは下記のような機能を提供しています。
- ランダム入力の生成: フレームワークは、さまざまなタイプのデータ(文字列、数値、複合データ構造など)のランダムな入力を自動的に生成します。これにより、開発者は手動で多数のテストケースを考案する手間を省くことができます。
- 入力データの多様性: フレームワークは、予期しないエッジケースや特殊な入力値を含む多様なテストデータを生成します。これにより、手動でテストを書く場合に見落としがちなケースをカバーできます。
- Shrinking(縮小)機能: 多くのフレームワークには、テストが失敗した際に最小の失敗ケース(最小反例)を見つける Shrinking 機能があります。これにより、問題の原因を特定しやすくなり、デバッグプロセスが効率化されます。
- テストの再現性: ランダム性にもかかわらず、ほとんどのフレームワークではシード値を使用してテストの実行を再現できます。これにより、特定のシナリオを確実にデバッグできます。
- 統合と拡張性: 多くのフレームワークは既存のテストフレームワークや CI/CD パイプラインと容易に統合でき、カスタムジェネレータやアサーションの拡張もサポートしています。
- 品質保証の向上: ランダム生成されたテストデータを使用することで、ソフトウェアが予期しない入力に対しても正しく動作することを確実にします。これは、品質保証のプロセスを強化し、信頼性の高いソフトウェア開発に寄与します。
総じて、プロパティベーステストのフレームワークは、テストの幅と深さを増やし、開発者がより堅牢で信頼性の高いソフトウェアを作る手助けをします。
プロパティベーステストの実践
「フィールド内のテキストを適切に処理できること」を分解すると、「フィールドはデフォルトで、カンマ区切りで分割される」というプロパティがあります。
今回はこのプロパティの検証を例にとって見ましょう。
下記のようにテストを書くことができます。
import { expect, test } from "vitest";
import { fc } from "@fast-check/vitest";
test("デフォルトでカンマ区切りで分割される", async () => {
await fc.assert(
fc.asyncProperty(
// ランダムなテストデータを生成するジェネレータ。
fc.gen().map((g) => {
// フィールド1は、「1文字以上の文字列」と性質を定義
const field1 = g(fc.string, { minLength: 1 });
// フィールド2は、「1文字以上の文字列」と性質を定義
const field2 = g(fc.string, { minLength: 1 });
// `${field1},${field2}` の文字列を内部で細切れのチャンクに分ける
// e.x. field1="aaa", field2="bbb"なら、 ["a", "aa,b", "", "bb"] などのように分割される
const chunks = autoChunk(g, `${field1},${field2}`);
const ecpected = [
{ type: Field, value: field1 },
{ type: FieldDelimiter, value: "," },
{ type: Field, value: field2 },
];
// テストで使うデータを返却する
return { chunks, ecpected };
}),
async ({ chunks, ecpected }) => {
const tokens = await transform(new LexerTransformer(), chunks);
expect(tokens).toStrictEqual(ecpected);
}
)
);
});
このテストを実行すると、ルールにもとづてランダム値が大量(fast-check のデフォルト値は 100 件)に生成され、すべてのケースで通るかが検証されます。
console.log を仕込み実際に検証される値を出しました。
考慮漏れの起こりやすい記号がありフレームワーク側の考慮が伺えます。
下記の例には含まれていませんが、JavaScript 固有で取り扱いに考慮が必要なprotptypeや __proto__ 、 define などがテストケースに含まれていることもありました。
{field1:"0&#\" 8}#E",field2:"6tI^c;~jTSI",chunks:["0&#","\" 8}#E,6tI^c;~jTSI"],ecpected:[{"value":"0&#\" 8}#E"},{"value":","},{"value":"6tI^c;~jTSI"}]}
{field1:"chpxZq=gA4l",field2:"$%/d!",chunks:["chp","","xZ","q","=g","A","4l,$%/","","","d!"],ecpected:[{"value":"chpxZq=gA4l"},{"value":","},{"value":"$%/d!"}]}
{field1:"p`/T=",field2:"\"||",chunks:["p`/","T=,\"|","|"],ecpected:[{"value":"p`/T="},{"value":","},{"value":"\"||"}]}
{field1:"pI!%!9R4",field2:"ref",chunks:["pI","!%!","9R","4,","r","ef"],ecpected:[{"value":"pI!%!9R4"},{"value":","},{"value":"ref"}]}
{field1:"#&y{",field2:"=!'s1m9>",chunks:["#&y{,=!","","'s1","m9>"],ecpected:[{"value":"#&y{"},{"value":","},{"value":"=!'s1m9>"}]}
{field1:"6X6`",field2:"i-J?|vF*5N'",chunks:["6X6`",",i-J?|vF*","5N'"],ecpected:[{"value":"6X6`"},{"value":","},{"value":"i-J?|vF*5N'"}]}
{field1:"y\\[3.>7Sk<wh",field2:"8",chunks:["y\\[","","3.>7Sk<wh,","","","","","8"],ecpected:[{"value":"y\\[3.>7Sk<wh"},{"value":","},{"value":"8"}]}
{field1:"{$\"|{xc}9Q",field2:"}n%`u&!U~Kz ",chunks:["{$\"|{xc}9Q,}n%`u&!U~","Kz "],ecpected:[{"value":"{$\"|{xc}9Q"},{"value":","},{"value":"}n%`u&!U~Kz "}]}
{field1:"|",field2:"xzVo&y ms!1I",chunks:["|,xzVo&y ms","","","","!","","1I"],ecpected:[{"value":"|"},{"value":","},{"value":"xzVo&y ms!1I"}]}
{field1:"NP",field2:"zM",chunks:["NP",",z","M"],ecpected:[{"value":"NP"},{"value":","},{"value":"zM"}]}
{field1:"|wGOp",field2:"\"F3o|yz!",chunks:["|","wGOp,\"F3","o|y","","z!"],ecpected:[{"value":"|wGOp"},{"value":","},{"value":"\"F3o|yz!"}]}
{field1:"]o&!cSKMzOF",field2:"Jg",chunks:["]o&!cSK","","MzOF,J","g"],ecpected:[{"value":"]o&!cSKMzOF"},{"value":","},{"value":"Jg"}]}
{field1:"rfYcp07#e",field2:"Up B:=-RueF",chunks:["rfYcp07#e,Up B:=-","Ru","e","F"],ecpected:[{"value":"rfYcp07#e"},{"value":","},{"value":"Up B:=-RueF"}]}
{field1:"]vRKK6He",field2:"*no6~$",chunks:["]v","RKK6He,*no","6","~","","$"],ecpected:[{"value":"]vRKK6He"},{"value":","},{"value":"*no6~$"}]}
{field1:"%N!<",field2:"R^)",chunks:["%N","!<,","R^)"],ecpected:[{"value":"%N!<"},{"value":","},{"value":"R^)"}]}
{field1:" ",field2:"Ua[hUWLmA3|",chunks:[""," ,Ua[hUW","LmA3","|"],ecpected:[{"value":" "},{"value":","},{"value":"Ua[hUWLmA3|"}]}
{field1:"5.Qw%W9;3_>",field2:"oF:].ud*Y\\?",chunks:["","5.Qw%W9",";3_>,oF",":","].u","d","*Y\\?"],ecpected:[{"value":"5.Qw%W9;3_>"},{"value":","},{"value":"oF:].ud*Y\\?"}]}
{field1:"rC2",field2:"&",chunks:["","","rC2,","","","","&"],ecpected:[{"value":"rC2"},{"value":","},{"value":"&"}]}
{field1:"!e3]i@ {",field2:"a!<7\\",chunks:["!","e3]i@ {,a!<7","","","\\"],ecpected:[{"value":"!e3]i@ {"},{"value":","},{"value":"a!<7\\"}]}
{field1:"nst",field2:"uC",chunks:["","","nst,","u","","","C"],ecpected:[{"value":"nst"},{"value":","},{"value":"uC"}]}
{field1:"FEnU@/i3]",field2:"GAmMk7",chunks:["FEnU@/i3],","","GAmMk","7"],ecpected:[{"value":"FEnU@/i3]"},{"value":","},{"value":"GAmMk7"}]}
{field1:"U0n8W<1964<",field2:"pMKi2Os",chunks:["U0n8W<1964<,pMKi","2O","","","","s"],ecpected:[{"value":"U0n8W<1964<"},{"value":","},{"value":"pMKi2Os"}]}
{field1:"Gwa|K~?OqQ",field2:"m&8`mb{9|",chunks:["Gwa|K~?OqQ,m&8`mb","{9|"],ecpected:[{"value":"Gwa|K~?OqQ"},{"value":","},{"value":"m&8`mb{9|"}]}
{field1:"Ze Xjj.<JS2$",field2:"/[U!YV",chunks:["Ze Xjj.<J","S2","$,/[U!YV"],ecpected:[{"value":"Ze Xjj.<JS2$"},{"value":","},{"value":"/[U!YV"}]}
{field1:"tA! z=PP_",field2:":9",chunks:["tA! z=PP_,:","9"],ecpected:[{"value":"tA! z=PP_"},{"value":","},{"value":":9"}]}
{field1:"WeRSKPBo.",field2:"Q!",chunks:["WeRSKPBo.,Q","","!"],ecpected:[{"value":"WeRSKPBo."},{"value":","},{"value":"Q!"}]}
{field1:"#__d",field2:"yC] !coz__",chunks:["#__d,yC] !coz","_","_"],ecpected:[{"value":"#__d"},{"value":","},{"value":"yC] !coz__"}]}
{field1:" \"",field2:"/",chunks:[" \",","","","/"],ecpected:[{"value":" \""},{"value":","},{"value":"/"}]}
{field1:"s",field2:"*",chunks:["s,","*"],ecpected:[{"value":"s"},{"value":","},{"value":"*"}]}
{field1:"j_rR",field2:"*",chunks:["j_","rR",",","*"],ecpected:[{"value":"j_rR"},{"value":","},{"value":"*"}]}
{field1:"E]|$=RN",field2:"GkqL,>$|u>M\"",chunks:["E]|$=","RN,GkqL,>$|u",">M\""],ecpected:[{"value":"E]|$=RN"},{"value":","},{"value":"GkqL,>$|u>M\""}]}
{field1:"Pz `#T",field2:"5&~>XE",chunks:["Pz `#T,","5&~>X","","E"],ecpected:[{"value":"Pz `#T"},{"value":","},{"value":"5&~>XE"}]}
{field1:"~]|",field2:"1 _yNvI",chunks:["~","]|,1",""," ","_yNvI"],ecpected:[{"value":"~]|"},{"value":","},{"value":"1 _yNvI"}]}
{field1:"R$z\"bp!zIx9Y",field2:"\\iI}[z0w&",chunks:["R$z\"bp!zIx9Y,\\iI}[z0","","","w&"],ecpected:[{"value":"R$z\"bp!zIx9Y"},{"value":","},{"value":"\\iI}[z0w&"}]}
{field1:"Ot_ibFT6k",field2:"mjU\"ol",chunks:["Ot_ibFT","6k,mjU\"","o","","l"],ecpected:[{"value":"Ot_ibFT6k"},{"value":","},{"value":"mjU\"ol"}]}
{field1:"}y",field2:"|",chunks:["}y","",",","","","","|"],ecpected:[{"value":"}y"},{"value":","},{"value":"|"}]}
{field1:"NArq.AO5",field2:"hQ4BAW",chunks:["NArq.AO5,hQ4BA","","W"],ecpected:[{"value":"NArq.AO5"},{"value":","},{"value":"hQ4BAW"}]}
{field1:"}/YA12/~!}N",field2:"M=!N!wt",chunks:["}/YA","12/~!","}N,M=!N!w","","t"],ecpected:[{"value":"}/YA12/~!}N"},{"value":","},{"value":"M=!N!wt"}]}
{field1:"`!Y",field2:"v~HL\"[0pr",chunks:["`!Y,v~HL\"","[","0p","","","","r"],ecpected:[{"value":"`!Y"},{"value":","},{"value":"v~HL\"[0pr"}]}
{field1:"xa ,y#%l5K",field2:"z&n",chunks:["xa ,y#%l5K",",z&n"],ecpected:[{"value":"xa ,y#%l5K"},{"value":","},{"value":"z&n"}]}
{field1:"xv\"p",field2:"cnz\"N<|iz",chunks:["xv","\"p,cn","z\"N<|","i","","z"],ecpected:[{"value":"xv\"p"},{"value":","},{"value":"cnz\"N<|iz"}]}
{field1:"Y@iis",field2:"MC",chunks:["Y@ii","s",",M","","","","C"],ecpected:[{"value":"Y@iis"},{"value":","},{"value":"MC"}]}
{field1:">H9 vS",field2:"Tt24:h6bI",chunks:[">H9"," vS,Tt2","4:","h6","b","I"],ecpected:[{"value":">H9 vS"},{"value":","},{"value":"Tt24:h6bI"}]}
{field1:"!~l,g=hv&\\",field2:"J65bt",chunks:["!~l,g=hv&\\,","J65","b","t"],ecpected:[{"value":"!~l,g=hv&\\"},{"value":","},{"value":"J65bt"}]}
{field1:"*3iU",field2:"IbGR<T~n",chunks:["*3iU,IbGR<T~n"],ecpected:[{"value":"*3iU"},{"value":","},{"value":"IbGR<T~n"}]}
{field1:"9&r&3#8J\"O",field2:"vK",chunks:["9&r","&3#8J\"O,v","K"],ecpected:[{"value":"9&r&3#8J\"O"},{"value":","},{"value":"vK"}]}
{field1:"8<*",field2:"#r",chunks:["8","<*,#r"],ecpected:[{"value":"8<*"},{"value":","},{"value":"#r"}]}
{field1:"*\\Y<E.9I-4i",field2:"P+JQ]{,!h",chunks:["*\\","Y<E.9I-4i,P+JQ]{",",","!","","h"],ecpected:[{"value":"*\\Y<E.9I-4i"},{"value":","},{"value":"P+JQ]{,!h"}]}
{field1:"z+s.n&L",field2:"]JzsfZrE(ag",chunks:["","","z+","s.n&L,]Jz","s","fZrE(a","g"],ecpected:[{"value":"z+s.n&L"},{"value":","},{"value":"]JzsfZrE(ag"}]}
{field1:"SCT",field2:"1atmE",chunks:["S","C","T,1at","m","","","E"],ecpected:[{"value":"SCT"},{"value":","},{"value":"1atmE"}]}
実はこのテストは失敗します(※ランダムなのでタイミング次第ですが大概失敗します)
❯ LexerTransformer (1)
× デフォルトでカンマ区切りで分割される
⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯ Failed Tests 1 ⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯
FAIL src/path/to.test.ts > デフォルトでカンマ区切りで分割される
Error: Property failed after 4 tests
{ seed: -1222658191, path: "3", endOnFailure: true }
Counterexample: [{"chunks":["+\"l{,~~,(-w","&","!","","!"],"ecpected":[{"type":Symbol.for("web-streams-csv.Field"),"value":"+\"l{"},{"type":Symbol.for("web-streams-csv.FieldDelimiter"),"value":","},{"type":Symbol.for("web-streams-csv.Field"),"value":"~~,(-w&!!"}]}]Shrunk 0 time(s)
Counterexample に記載があるように、フィールド内で , が含まれているケースで失敗してしまったようです。
このほかにダブルクオートや改行コードなどが含まれるケースでテストを満たせないはずですので、対応するケースを正しく出力できるように修正しましょう。
const exludeChars = [",", '"', "\r", "\n"];
// フィールド1は、「カンマ、ダブルクォート、改行コードの含まれない1文字以上の文字列」と定義
const field1 = g(() =>
fc
.string({ minLength: 1 })
.filter((v) => exludeChars.every((char) => v.includes(char) === false))
);
// フィールド2は、「カンマ、ダブルクォート、改行コードの含まれない1文字以上の文字列」と定義
const field2 = g(() =>
fc
.string({ minLength: 1 })
.filter((v) => exludeChars.every((char) => v.includes(char) === false))
);
これにより、テストが通過します。
✓ src/path/to.test.ts (1)
✓ デフォルトでカンマ区切りで分割される
ただし、ランダムなので厳密にさきほどのケースが確認できているかが不明です。
ここでエラーメッセージなどにたびたび出現している seed が役に立ちます。出力された seed やパスなどの情報をそのまま渡します。
{ seed: -1222658191, path: "3", endOnFailure: true }
失敗したケースを再現するには、テストにシード値を追加して実行します。
test("デフォルトでカンマ区切りで分割される", async () => {
await fc.assert(
fc.asyncProperty(/** 同じ */),
// fc.assertの第2引数に先程のシード値を追加
{ seed: -1222658191, path: "3", endOnFailure: true }
);
});
✓ src/path/to.test.ts (1)
✓ デフォルトでカンマ区切りで分割される
これにより、元のテストも成功し CSV パーサのプロパティが保証できました。
このように、テストが失敗した際に、問題の原因を特定しやすくするために、テストケースをより単純な形に縮小するプロセスを Shrink といいます。
プロパティベーステストでは、Shrink を繰り返すことによりプロパティの具体化し、問題の特定やデバッグの効率化を実施しています。
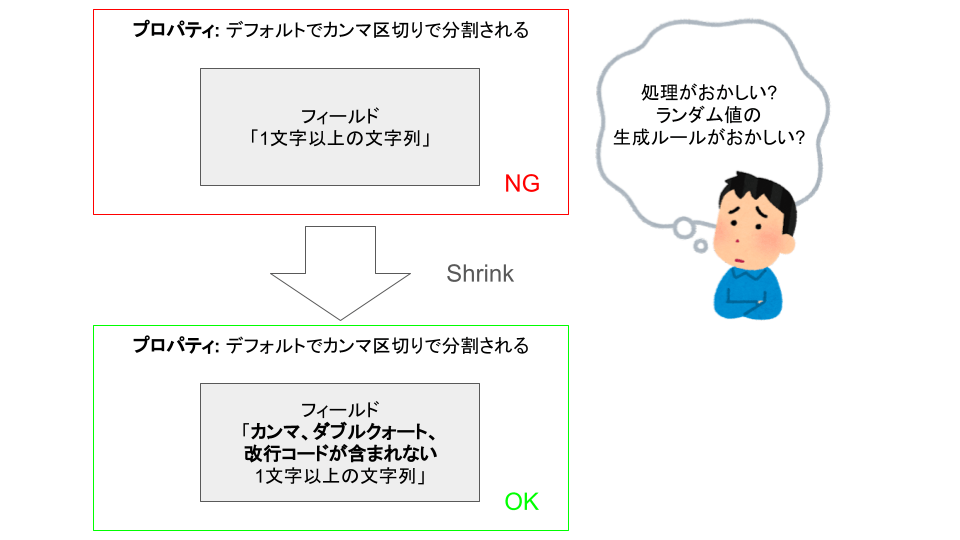
Shrink のイメージ
カスタムジェネレータ
CSV の複雑な仕様を網羅的にテストするために、カスタムジェネレータを作成しました。
カスタムジェネレータの役割
CSV フォーマットは、単純なカンマ区切りのデータから、ダブルクオートで囲まれたフィールド、特殊文字やエスケープシーケンスを含む複雑な構造まで、多様なパターンを持っています。
標準的なデータジェネレータだけではこれらのすべてのケースをカバーすることは難しいため、CSV の仕様に特化したカスタムジェネレータを開発しました。
このジェネレータは、フレームワーク標準のジェネレータで表現できないような CSV の要素を表現するようにカスタマイズされています。
- フィールド内に改行やカンマが含まれるケース
- エスケープされたクオート文字を含むフィールド
- 異なる長さのレコードや空のフィールド
- UTF-16 を含むマルチバイト文字の取り扱い
実装中に発覚した不具合の例
カスタムジェネレータの改善や Shrink のプロセスにより、さまざまな不具合が発覚しました。
プロパティベーステストだからこそ気付けたような事例をいくつか紹介します。
2 バイト以上の文字扱う際にエラーになる
JavaScript は文字コードとして Unicode を採用し、エンコード方式として UTF-16 を採用しています。

(引用: https://jsprimer.net/basic/string-unicode/)
「🍎」のような 16bit の文字列を扱う際には、見た目上の文字数と .length の値が変わってしまうので注意が必要です。
console.log("🍎".length); // => 2
テストケースを作る際に、JavaScript の言語仕様を深く知っていたり、文字のバイト数周りで困った経験がないと、ユニットテスト時にこのようなケースを考慮するのは難しそうです。
Unicode の「ゼロ幅スペース」がフィールドに含まれた時
名前から分かるように見えない空白文字(非印字文字)です。
LexerTransfomer の内部処理で正規表現を使っており、もともとあった不具合を修正中、どうしても抜けられないケースがあり、調べてみると見えない文字が入っていました。
console.log("\uFEFF"); // 何も表示されない
JavaScript の正規表現の空白文字( \s )は、下記にしかマッチしないようで、 U+FEFF 別途対応する必要があったようです。(仕様: https://tc39.es/ecma262/#sec-compiletocharset)
| Code Point | Unicode Name | Abbreviation |
|---|---|---|
| U+000A | LINE FEED (LF) | <LF> |
| U+000D | CARRIAGE RETURN (CR) | <CR> |
| U+2028 | LINE SEPARATOR | <LS> |
| U+2029 | PARAGRAPH SEPARATOR | <PS> |
このようなケースも事前知識がないとテストケースに入れないですね。
フィールド囲み文字に $ が含まれる文字列を指定したときに正しくフィールド囲みできなくなる
フィールド囲み文字(デフォルトでダブルクオート)に $が使われているときに、フィールドの値に $ が入っていたときに正しく動作しなくなる事象がありました。
- 値:
$, フィールド囲み文字:$ - 期待値:
$$$$ - 出力値:
$$$
他の文字では再現せず、 $ だけが異常値を示しました。
これは、文字列の置換に使用していた replace メソッドの仕様で、置換後の文字列を指定する際に $ が特殊な動きをする仕様のためでした。
これは知っていたので気付ける要素はありましたが、さすがに初手では気付けませんでした。
実際のプロパティベーステストの記載例
parseString 関数のテスト例
parseString 関数は string 型で与えられる CSV をパースします。
ライブラリ内では比較的高レイヤの関数ですので、ランダムに生成された CSV データから CSV 文字列を作成し、出力された値が期待値を満たすかを検証します。
parseBinaryStream 関数のテスト例
BOM や圧縮形式の解凍、エンコーディングなどのバイナリ操作しています。
JavaScript では、16bit 文字列のデコードは対応していません。
テストケースの生成時に、16bit 文字が生成されないようにテストケースを抑制するなどの考慮がされています。
感想と今後の展望
プロパティベーステストの効果
- プロパティベーステストにより、開発時に想定していなかった複数の不具合が検出でき、未知の不具合を検出できる効果がありました。
- CSV というわかりやすい仕様でも、初期開発で不具合が発生してしまうため、普段の開発でも気を付けていきたいと思いました。
プロパティベーステストを使った品質改善の展望
-
fast-check のドキュメントを読むと、レースコンディションの検知や Fuzzing もできるようですので、今後導入していきたいと思いました。
-
今回作成しているものをモデル実装として、WASM や Worker を使ったパフォーマンスの改善なども挑戦していきたいと思いました。
-
現状はパーサしか対応できていないが、フォーマッターにも対応して、対称性のプロパティを検証することも実施してみたいと思いました。
イメージtest("対称性", async () => { await fc.assert( fc.asyncProperty( fc.gen().map((g) => { // ランダムなデータを生成する // e.x. [{a: '1', b: '2'}, {a: '3', b: '4'}] const data = g(CSV); return { data }; }), async ({ data, ecpected }) => { const csv = await stringify(data); const actual = await parse(csv); expect(actual).toStrictEqual(data); } ) ); })
謝辞
2023 年 12 月 20 日に開催された「t-wada さん、ymotongpoo さんに聞くテスト戦略最前線」イベントに深く感謝します。
このイベントの抽選で本をいただいたことは、私のプロジェクトにおける重要な資料としてたいへん有益でした。
主催者の皆様、講演者の t-wada さん、ymotongpoo さんに心から感謝申し上げます。
付録
開発中のライブラリ
web-csv-toolbox という名前で下記のテーマで開発しています。
「Property-based Testing の位置付け / Intro to Property-based Testing」
2023 年 12 月 20 日に行われた「t-wada さん、ymotongpoo さんに聞くテスト戦略最前線」のイベントの@t-wada さんの発表資料です。
AI に作らせた「プロパティベーステストの歌」
-
Node.js 21.x のリリースブログ
https://nodejs.org/en/blog/announcements/v21-release-announce#stable-fetchwebstreams ↩︎
Discussion