ScalarDB Getting Started !!
ScalarDBとは複数のデータベースに対応したHTAPエンジンです。データベースのミドルウェアとして稼働し複数のデータべースを抽象化しACIDトランザクションとリアルタイム分析を両立させます。
HTAP とは
2014年にガートナーにより提唱された言葉で、昨今のデータベースにおける潮流の一つであり、Hybrid Transaction/Analytical Processingの略です。一般的に、データベース管理システム上の処理には、オンラインのトランザクション処理を行うOLTPとオンライン分析処理を行うOLAPがあります。
従来は、OLTPで作られたデータをDWHやData Lakeに移送してOLAPを行うことが一般的でしたが、最近ではOLTPとOLAPを行うHTAPに対応したデータベースも登場してきています。
HTAPが可能なデータベースとしては、PingCAP社のTiDBが有名です。
HTAPに対応したデータベースを利用することで、OLAPのために、データを移送する必要がなくなるため、リアルタイムな分析を行うことが可能になります。
ScalarDB と HTAP へのアプローチ
HTAPは、リアルタイムな分析を実現しますが、企業には多くのデータベース・インスタンスが存在するため、複数のデータベースをまたがった分析クエリを実行することができないという課題があります。また、NoSQLデータベースのようなHTAPに対応していないデータベースなども多数存在します。
ScalarDBは、この課題に対して、各データベースを抽象化するアダプタを提供し、複数のデータベースを仮想的に統合することで、HTAPを実現しています。

サポートしているデータベースは2024年6月現在で以下です。
- Oracle Database、Microsoft SQL Server、MySQL、PostgreSQL、SQLite などの JDBCをサポートするリレーショナルデータベース
- MariaDB、Amazon Aurora、Google AlloyDB、PingCap TiDB、Yugabyte YugabyteDBなどの MySQL, PostgreSQLと互換性のあるデータベース
- Amazon DynamoDB、Azure Cosmos DB、Apache Cassandraなどの NoSQLデータベース。
対応しているデータベースとしては、以下のドキュメントをご覧ください。
ACID特性を持つRDBMSだけでなく、ACID特性が限定的なNoSQLデータベースにも対応して、ACID特性を付与していることも特長です。
従来の類似のソフトウェアやサービスは、分析クエリには対応していますが、異種データベースへのトランザクション処理には課題がありましたが、ScalarDBではその課題を解決しています。
さっそくやってみる
では難しい話はこれぐらいにして触っていきます。
ScalarDB は様々なデータベースに対応していますが、今日は Amazon DynamoDBを使います。クライアントにはAmazon Linux 2023 を使っていますが、ScalarDB には、オープンソース版と商用版があり、今回はオープンソース版を試してみます。
オープンソース版は、クライアントのライブラリとして動作し、このクライアントライブラリは Java 実行環境で動作します。このため、ScalarDB を使ったJava実行環境は、以下に対応しているものであれば問題ありません。
- OpenJDK LTS バージョン (8、11、または 17)
- Oracle JDK LTS バージョン (8、11、または 17)
JDK のインストール
AWSはAmazon CorrettoというOpenJDKを配布しているのでそちらを用います。
sudo yum update -y
sudo yum install -y java-11-amazon-corretto
java -version
以下のように表示されればインストールが完了です。
openjdk version "11.0.23" 2024-04-16 LTS
OpenJDK Runtime Environment Corretto-11.0.23.9.1 (build 11.0.23+9-LTS)
OpenJDK 64-Bit Server VM Corretto-11.0.23.9.1 (build 11.0.23+9-LTS, mixed mode)
git のインストール
次にScalarDBのサンプルをGitレポジトリからダウンロードするためgitをインストールします。
sudo dnf update -y
sudo dnf install -y git
git --version
以下のように表示されればインストールが完了です。
git version 2.40.1
レポジトリをクローンします。
git clone https://github.com/scalar-labs/scalardb
.
├── build.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
├── scalardb.properties
├── settings.gradle
└── src
└── main
└── java
└── sample
├── ElectronicMoney.java
└── ElectronicMoneyMain.java
以下のフォルダに移動します。
cd scalardb/docs/getting-started
scalardb.propertiesをviなどで開き以下に置換します。
# The DynamoDB storage implementation is used for Consensus Commit.
scalar.db.storage=dynamo
# The AWS region.
scalar.db.contact_points=<REGION>
# The AWS access key ID and secret access key to access the database.
scalar.db.username=<ACCESS_KEY_ID>
scalar.db.password=<SECRET_ACCESS_KEY>
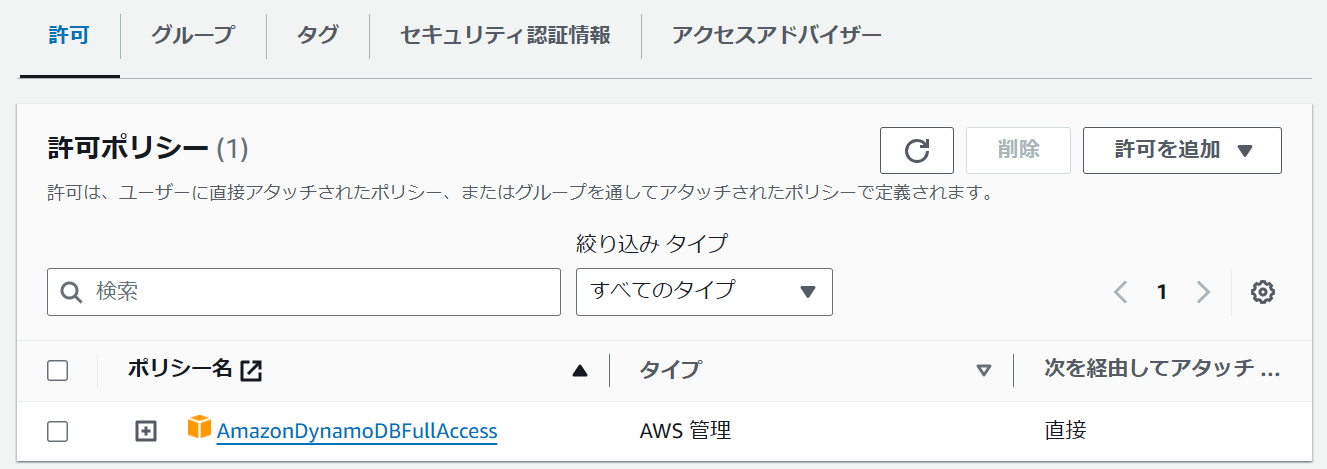
<REGION>は東京リージョンの場合ap-northeast-1になります。<ACCESS_KEY_ID>と<SECRET_ACCESS_KEY>にはそれぞれIAMユーザーの値を記載します。
このIAMユーザーの権限を使用してScalarDBはDynamoDBにアクセスをしますので、DynamoDBへの権限を付与しておく必要があります。
次にemoney.jsonというファイルを新規にします。
{
"emoney.account": {
"transaction": true,
"partition-key": [
"id"
],
"clustering-key": [],
"columns": {
"id": "TEXT",
"balance": "INT"
}
}
}
ここではデータベーススキーマを規定しています。サンプルは非常に単純でパーティションキーとなるTEXT型のid、INT型balanceの2つのカラムが設定されています。このファイルを用いてスキーマをDynamoDBに定義していきますが、所定のスキーマローダーを使います。後ほど説明しますが、DynamoDBに単純に上記スキーマのテーブルができるわけではなくScalarDBが解釈可能な形でのテーブルを作成する必要があります。
wget https://github.com/scalar-labs/scalardb/releases/download/v3.12.2/scalardb-schema-loader-3.12.2.jar
スキーマローダーをダウンロードした後以下のコマンドで実行します。
java -jar scalardb-schema-loader-3.12.2.jar --config scalardb.properties --schema-file emoney.json --coordinator
[main] INFO com.scalar.db.schemaloader.command.SchemaLoaderCommand - Config path: scalardb.properties
[main] INFO com.scalar.db.schemaloader.command.SchemaLoaderCommand - Schema path: emoney.json
[main] INFO com.scalar.db.schemaloader.SchemaOperator - Creating the table account in the namespace emoney succeeded
[main] INFO com.scalar.db.schemaloader.SchemaOperator - Creating the coordinator tables succeeded
エラーが出た場合は先ほど編集した2つのファイルscalardb.propertiesとemoney.jsonを見直してください。
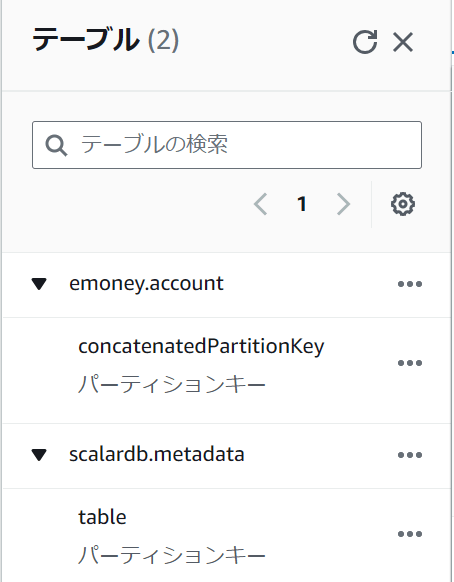
DynamoDB の状況
2つのテーブルが作成されています。

ではサンプルで提供されているアプリケーションをもとにチュートリアルを進めていきます。サンプルは簡単な電子マネーアプリによる資金移動となっており、gradlewというシェルスクリプトで提供されています。
customer1というアカウントを残高500で作成します。
./gradlew run --args="-action charge -amount 500 -to customer1"
初回実行時のみ必要ライブラリのインストールが発生します。
以下のアイテムがDynamoDBに書き込まれています。
| tx_prepared_at | balance | tx_committed_at | tx_state | tx_id | tx_version | id | concatenatedPartitionKey |
|---|---|---|---|---|---|---|---|
| 1718495702535 | 500 | 1.7185E+12 | 3 | ac968f0e-3eca-445f-8cc7-682e8327468d | 1 | customer1 | Y3VzdG9tZXIxAA== |
idとbalance以外にもScalarDBが必要とするカラムが増えていることがわかります。
では次に残高が0であるmerchant1も作成します。
./gradlew run --args="-action charge -amount 0 -to merchant1"
| tx_prepared_at | balance | tx_committed_at | tx_state | tx_id | tx_version | id | concatenatedPartitionKey |
|---|---|---|---|---|---|---|---|
| 1718496193948 | 0 | 1718496194094 | 3 | fd959b26-0ec3-40bc-b0fc-af4a323ee3bf | 1 | merchant1 | bWVyY2hhbnQxAA== |
| 1718495702410 | 500 | 1718495702565 | 3 | ac968f0e-3eca-445f-8cc7-682e8327468d | 1 | customer1 | Y3VzdG9tZXIxAA== |
にはその後の資金移動などの手順があるのでやってみて下さい。やらなくても以下の手順は実行できます。
customer1の資金残高を確認するコマンドを実行すると面白いことがわかります。
./gradlew run --args="-action getBalance -id customer1"
[main] INFO com.scalar.db.storage.dynamo.Dynamo - DynamoDB object is created properly
The balance for customer1 is 500
何かが作成されたようです。DynamoDBを見てみるとテーブルが一つ増えています。

coordinator.stateです。
| tx_created_at | tx_state | tx_id | concatenatedPartitionKey |
|---|---|---|---|
| 1718496382343 | 3 | 8278d22d-c22e-469b-bee0-53eadec39b0d | ODI3OGQyMmQtYzIyZS00NjliLWJlZTAtNTNlYWRlYzM5YjBkAA== |
| 1718496194062 | 3 | fd959b26-0ec3-40bc-b0fc-af4a323ee3bf | ZmQ5NTliMjYtMGVjMy00MGJjLWIwZmMtYWY0YTMyM2VlM2JmAA== |
| 1718495702535 | 3 | ac968f0e-3eca-445f-8cc7-682e8327468d | YWM5NjhmMGUtM2VjYS00NDVmLThjYzctNjgyZTgzMjc0NjhkAA== |
各カラムは実際のデータが保持されているemoney.accountテーブルと呼応していることがわかります。もう1回同じ集計コマンドを実行するとさらに項目が一つ増えて4つになることがわかります。これこそがScalarDBの肝でありトランザクションマネージャーの役割を果たしていることがわかります。
こちらについては後日別の記事で触れていきたいと思いますが、以下のスライドがその全容です。
Discussion