BigQueryのベクトル検索で文書検索APIを作る
BigQueryでベクトル検索を利用できるようになっており学習用に使ってみました。 2024年6月6日現在はプレビュー版です。
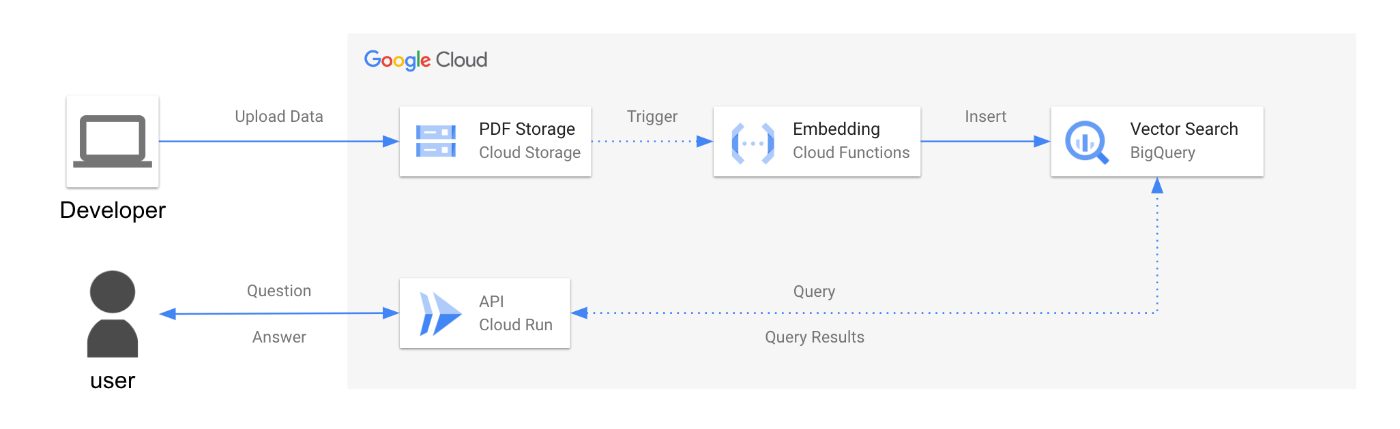
構成図
・Cloud Functions
GCSにpdfを格納するとエンべディングデータを作成しBig Queryにインサートする。
・Cloud Run
質問するとBigQueryにベクトル検索で文書検索し、検索情報を基に回答するAPI。
使用したデータ
Wikipediaをpdf化したデータを使用しました。
リンゴ
オレンジ
Wikipediaの「ツール」→「pdf形式でダウンロード」からダウンロードしています。
ソースコード
テーブルスキーマ
ベクトル検索するVector Search関数はArray<float>型に対応しています。

Embeddingデータの作成
Cloud Functionの処理です。
- pdfを読み込み
- pdfの文章をEmbedding
- EmbedingデータをBigQueryにインサート
をしています。
pdfを分割しEmbeddingデータを作成します。
pdfを文字数単位で分割しています。
def gen_summarize_pdf(bucket_name:str, name:str, local_path:str):
# Generate summary of the pdf
loader = PyPDFLoader(local_path)
document = loader.load()
llm = VertexAI(
model_name="text-bison@001",
max_output_tokens=256,
temperature=0.1,
top_p=0.8,
top_k=40,
verbose=True,
)
qa_chain = load_qa_chain(llm, chain_type="map_reduce")
qa_document_chain = AnalyzeDocumentChain(combine_docs_chain=qa_chain)
description = qa_document_chain.run(
input_document=document[0].page_content[:5000],
question="何についての文書ですか?日本語で2文にまとめて答えてください。")
# Load pdf for generate embeddings
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n", "。"],
chunk_size=512,
chunk_overlap=128,
length_function=len,
)
pages = loader.load_and_split(text_splitter=text_splitter)
分割したデータをEmbeddingしBigQueryにインサートします。
# Create embeddings and inser data to BigQuery
embeddings = VertexAIEmbeddings(model_name="textembedding-gecko-multilingual@latest")
for page_num, page in enumerate(pages[:100]): # Limit the nubmer of pages to avoid timeout.
embeddings_data = embeddings.embed_query(page.page_content)
logger.info(embeddings_data)
# Filtering data
filtered_data = page.page_content.encode("utf-8").replace(b'\x00', b'').decode("utf-8")
# await insert_doc(name, filtered_data, page.metadata, user_id, embeddings_data)
logger.info("{}: processed chunk {} of {}".format(name, page_num, min([len(pages)-1, 99])))
# bq insert
bq_insert(page_num, page.metadata, description, filtered_data , embeddings_data, bucket_name, name)
time.sleep(0.5)
return
def bq_insert(page_num, page_metadata, description, filtered_data, embeddings_data, bucket_name:str, name:str):
from google.cloud import bigquery
# TODO(developer): Set table_id to the ID of table to append to.
table_id = os.getenv('TABLE_ID')
gcs_uri = f'gs://{bucket_name}/{name}'
# Construct a BigQuery client object.
client = bigquery.Client()
rows_to_insert = [
{"page_num":page_num,"page_metadata": json.dumps(page_metadata), "gcs_uri":gcs_uri, "description": description, "embeddings_data": embeddings_data, "filtered_data": filtered_data}
]
errors = client.insert_rows_json(table_id, rows_to_insert) # Make an API request.
if errors == []:
logger.info("New rows have been added.")
else:
logger.error("Encountered errors while inserting rows: {}".format(errors))
このような形でデータが作成されます。

ベクトル検索による文書検索
Cloud Runの処理です。
- 質問内容のEmbeddingデータを作成
- BigQueryから質問に近いEmbeddingデータの文書を抽出する
- 抽出した文書データから質問に対する回答の情報を抽出
をしています。
BigQueryでVector_Serch関数を用いて直接データを取得する方法と、LangchainのBigQueryVectorSearchライブラリを用いて検索する方法を一つのAPIで実行しています。
BigQuery:VECTOR_SEARCH
VECTOR_SEARCH関数の結果でdistanceが低い値ほど質問に関連するデータです。
そのためORDER BY distanceで近い順にSELECTしています。
def create_vector_search_sql(table,embeddings_data):
return f"""
WITH temp_table_with_arrays AS (
SELECT ARRAY<FLOAT64>{embeddings_data} AS float_array
)
SELECT
base.filtered_data as filtered_data,
distance
FROM
VECTOR_SEARCH(
TABLE `{table}`,
'embeddings_data',
TABLE temp_table_with_arrays,
'float_array',
top_k => 5,
distance_type => 'COSINE',
options => '{{"use_brute_force":true}}')
ORDER BY distance
LIMIT 5;
"""
Langchain:BigQueryVectorSearch
docsが配列になっており小さい順に質問に関連するデータです。
metadata_fieldはString型のカラムですが、文字列がjson形式(nullでもOK)である必要があります。検索には関係しませんがカラムを用意する必要があります。
async def search_doc_langchain(requests):
embeddings = VertexAIEmbeddings(model_name="textembedding-gecko-multilingual@latest")
embeddings_data = embeddings.embed_query(requests["question"])
store = BigQueryVectorSearch(
project_id=f"{requests['project']}",
dataset_name=f"{requests['dataset']}",
table_name=f"{requests['table']}",
location="asia-northeast1",
content_field = "filtered_data",
metadata_field = "page_metadata",
text_embedding_field = "embeddings_data",
embedding=embeddings,
distance_strategy=DistanceStrategy.EUCLIDEAN_DISTANCE,
)
docs = store.similarity_search_by_vector(embeddings_data, k=2)
logger.info(f"docs : {docs}")
context = docs[0].page_content
取得したデータから生成AIで質問に関連する箇所を抽出します。
llm = VertexAI(
model_name="text-bison@001",
max_output_tokens=256,
temperature=0.1,
top_p=0.8,
top_k=40,
verbose=True,
)
template = """
###{context}###
###で囲まれたテキストから、"質問:{question}" に関連する情報を抽出してください。
"""
prompt = PromptTemplate(
input_variables=["context", "question"],
template=template,
)
final_prompt = prompt.format(context=context, question=requests["question"])
result = llm(final_prompt)
結果を返します。
結果
BigQueryのVECTOR_SEARCH 関数とLangchainのBigQueryVectorSearchどちらも同じデータから抽出しています。
・Wikipediaからの抜粋

curl -X 'POST' \
'https://bq-vector-search-api-eekf6d7nfq-an.a.run.app/search' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"question": "ネーブルオレンジは特徴は?"}'
{
"search_doc_big_query": {
"answer": "ネーブルオレンジは、頂点で第 2 の果実が膨らんで僅かに突出し、⼈間のへそ(navel)に似ているのが特徴である。様々な理由で⼈間の消費向けに栽培されている。⼀般に、厚い外⽪が⽪をむきやすくしており、果汁は少なめながら、ジュースに不向きな苦味も少ない[29]。搾りたての果汁は美味しいが、時間がたつとすぐに苦味がでる。[58]栽培可能地域の広さと⻑い収穫期間がネーブルオレンジを⾮常に普及させた。 . ⽶国では 11-4 ⽉にかけて収穫可能で 1 ⽉ -3 ⽉が出荷のピークである[59]。",
"metadata": {
"filtered_data": "落果しづらい性質がある。果汁はハムリンの⾊よりも暗い[55]\nネーブルオレンジは、頂点で第 2 の果実が膨らんで僅かに突出し、⼈間のへそ(navel)に似ている\nのが特徴である。様々な理由で⼈間の消費向けに栽培されている。⼀般に、厚い外⽪が⽪をむ\nきやすくしており、果汁は少なめながら、ジュースに不向きな苦味も少ない[29]。搾りたての果\n汁は美味しいが、時間がたつとすぐに苦味がでる。[58]栽培可能地域の広さと⻑い収穫期間がネ\nーブルオレンジを⾮常に普及させた。 . ⽶国では 11-4 ⽉にかけて収穫可能で 1 ⽉ -3 ⽉が出荷のピー\nクである[59]。\n17世紀に 1000 種類の柑橘類を収録した⽬録『ヘスペリデス Hesperides 』の中で、イエズス会神\n⽗のジョバンニ‧バッティスタはこのように述べ ている。\n「このオレンジは、その⽊の多産性を⾒習って、果実の上になんとかもうひとつ果実を実らせ\nようとして失敗している。」[58]\n1917年のアメリカ合衆国農務省による研究によると、ブラジルのバイーア州に植えられたセレ",
"distance": 0.11563823139281648
}
},
"search_doc_langchain": {
"answer": "ネーブルオレンジは、頂点で第 2 の果実が膨らんで僅かに突出し、⼈間のへそ(navel)に似ているのが特徴である。様々な理由で⼈間の消費向けに栽培されている。⼀般に、厚い外⽪が⽪をむきやすくしており、果汁は少なめながら、ジュースに不向きな苦味も少ない[29]。搾りたての果汁は美味しいが、時間がたつとすぐに苦味がでる。[58]栽培可能地域の広さと⻑い収穫期間がネーブルオレンジを⾮常に普及させた。 . ⽶国では 11-4 ⽉にかけて収穫可能で 1 ⽉ -3 ⽉が出荷のピークである[59]。",
"metadata": {
"page_content": "落果しづらい性質がある。果汁はハムリンの⾊よりも暗い[55]\nネーブルオレンジは、頂点で第 2 の果実が膨らんで僅かに突出し、⼈間のへそ(navel)に似ている\nのが特徴である。様々な理由で⼈間の消費向けに栽培されている。⼀般に、厚い外⽪が⽪をむ\nきやすくしており、果汁は少なめながら、ジュースに不向きな苦味も少ない[29]。搾りたての果\n汁は美味しいが、時間がたつとすぐに苦味がでる。[58]栽培可能地域の広さと⻑い収穫期間がネ\nーブルオレンジを⾮常に普及させた。 . ⽶国では 11-4 ⽉にかけて収穫可能で 1 ⽉ -3 ⽉が出荷のピー\nクである[59]。\n17世紀に 1000 種類の柑橘類を収録した⽬録『ヘスペリデス Hesperides 』の中で、イエズス会神\n⽗のジョバンニ‧バッティスタはこのように述べ ている。\n「このオレンジは、その⽊の多産性を⾒習って、果実の上になんとかもうひとつ果実を実らせ\nようとして失敗している。」[58]\n1917年のアメリカ合衆国農務省による研究によると、ブラジルのバイーア州に植えられたセレ",
"metadata": {
"__id": null,
"__job_id": "job_HfUsfeGjQefFPmn2UktXzuxoj55Y"
},
"type": "Document"
}
}
}
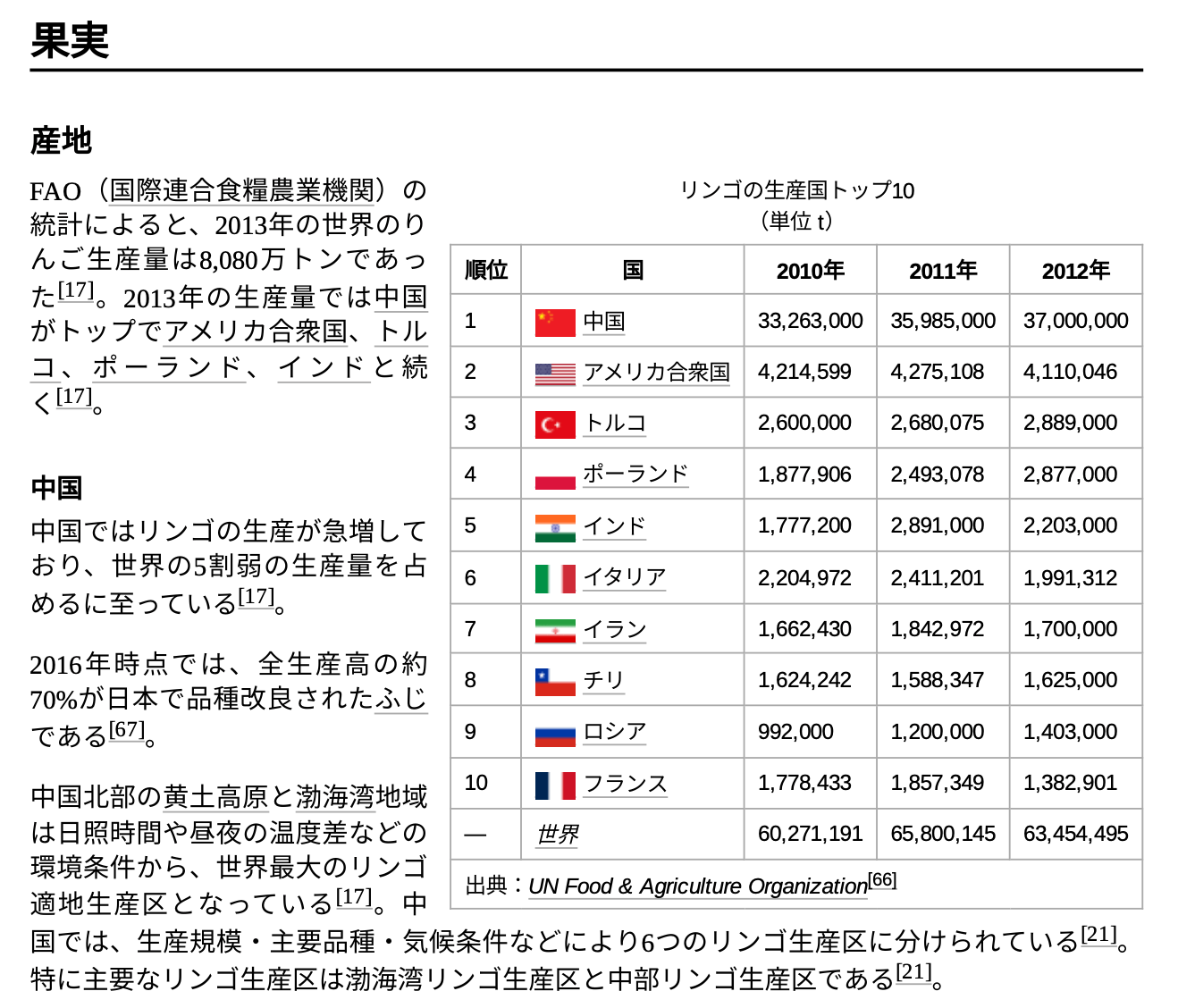
表のデータからも情報を取得できました。
・Wikipediaからの抜粋
curl -X 'POST' \
'https://bq-vector-search-api-eekf6d7nfq-an.a.run.app/search' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"question": "リンゴの生産量が一番の国は?"}'
{
"search_doc_big_query": {
"answer": "中国はリンゴの生産量が世界一です。2010年には33,263,000トン、2011年には35,985,000トン、2012年には37,000,000トンを生産しました。",
"metadata": {
"filtered_data": "リンゴの⽣産国トップ 10\n(単位 t)\n順位 国 2010年 2011年 2012年\n1\n 中国 33,263,00035,985,00037,000,000\n2\n アメリカ合衆国 4,214,599 4,275,108 4,110,046\n3\n トルコ 2,600,000 2,680,075 2,889,000\n4\n ポーランド 1,877,906 2,493,078 2,877,000\n5\n インド 1,777,200 2,891,000 2,203,000\n6\n イタリア 2,204,972 2,411,201 1,991,312\n7\n イラン 1,662,430 1,842,972 1,700,000\n8\n チリ 1,624,242 1,588,347 1,625,000\n9\n ロシア 992,000 1,200,000 1,403,000\n10\n フランス 1,778,433 1,857,349 1,382,901\n—世界 60,271,19165,800,14563,454,495",
"distance": 0.11160841093012142
}
},
"search_doc_langchain": {
"answer": "リンゴの生産量が一番の国は中国です。2010年、2011年、2012年のリンゴの生産量はそれぞれ33,263,000t、35,985,000t、37,000,000tでした。",
"metadata": {
"page_content": "リンゴの⽣産国トップ 10\n(単位 t)\n順位 国 2010年 2011年 2012年\n1\n 中国 33,263,00035,985,00037,000,000\n2\n アメリカ合衆国 4,214,599 4,275,108 4,110,046\n3\n トルコ 2,600,000 2,680,075 2,889,000\n4\n ポーランド 1,877,906 2,493,078 2,877,000\n5\n インド 1,777,200 2,891,000 2,203,000\n6\n イタリア 2,204,972 2,411,201 1,991,312\n7\n イラン 1,662,430 1,842,972 1,700,000\n8\n チリ 1,624,242 1,588,347 1,625,000\n9\n ロシア 992,000 1,200,000 1,403,000\n10\n フランス 1,778,433 1,857,349 1,382,901\n—世界 60,271,19165,800,14563,454,495",
"metadata": {
"__id": null,
"__job_id": "job_n3NJJ4BLME4ree9zBrkeg5IQCoxk"
},
"type": "Document"
}
}
}
以上です。読んでいただきありがとうございました。
参考
・文書検索API
こちらコードを参考にしています。
Google Cloudのgit hubが出している文書検索のソースコード。
PostgreSQLデータベースからベクトル検索しています。
・LangChainのBigQuery Vector Serch
Discussion