Cloudflare Workers/ Bindings と Service Bindings / JavaScript RPC について
今日はCloudflare Workers から Workers を呼び出すベストプラクティスとして、Service Bindings という機能が提供されており、その機能について纏めていきます。
Bindings
Cloudflare Workers は関数からデータベースへのアクセスにおいて例えば AWS の IAM に相当する認証機構は提供されておりません。その代わり、S3互換インターフェースを持つオブジェクトストレージのR2を除くとCloudflareのその他ストレージ、データベース系のサービスはWorkersからのみ呼び出すことが可能になっています。それを実現しているのがBindingsです。例えばWorkersの設定ファイルであるwrangler.tomlに以下のように設定した場合
kv_namespaces = [
{ binding = "KV", id = "xxxxxxxxxxxx" }
]
Workersのソースコードから以下のようにアクセスが可能になります。
await env.KV.put("KEY", "VALUE");
envという環境変数にKVへのアクセスが格納されるため、個別のログインや認証を書かなくても直接アクセスが可能となります。このため便利な一方で、Cloudflareのストレージ、データベースへのアクセスは、同じゾーンにある関数であれば全てデータソースへアクセスが行えるという点は注意点です。例えば
workeraとworkerbという2つの関数がある場合、workeraにだけ特定のKVにアクセスをさせたいという制御は行えません。workerbの開発者がwrangler.tomlにKVへのアクセス用にbindingを設定してしまえばアクセスが可能となります。一方ユーザー視点ではworkerbの設定ファイルにKVへのbindingが設定されていなければ何をどうやってもKVへのアクセスが行えない、という意味で万が一クレデンシャルが漏洩しても安全です。(Workers開発者向けクレデンシャルが漏洩した場合、その限りではないです・・・)
Service Bindings と多段の Worker 関数 / JavaScript RPC
このBindingの仕組みを活用してWorker関数から別のWorker関数を呼び出すのがService Bindingsです。一つのコードの処理を複数に分割することで、分割された単位でのモジュール更新などが可能となりメンテナンス性が向上します。例えば、ログイン処理と認証処理を分ける、HTTPのヘッダやレスポンス用とアプリケーションロジック用関数を分ける、等使い方は様々です。
呼び出し方式は2種類ありますRPCとHTTPです。
RPC方式
JavaScriptによるNativeなRPCがWorkersランタイムで実装されているため、利用にあたってRPCの知識は一切不要です。Classとして宣言された関数がまるでそこにあるかのように使えます。デフォルトでは同じサーバの別スレッドとして起動するため通信のレイテンシは極小化されます。また通信は公衆インターネット網を通らないため高速です。
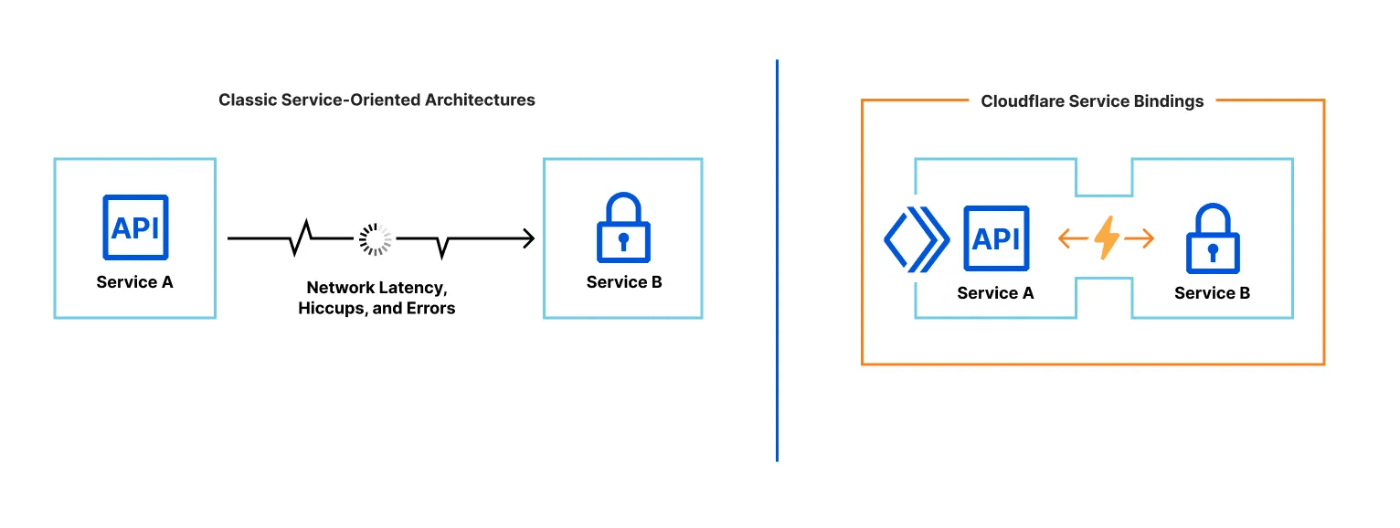
Cloudflareが推奨しているのはこのRPC方式です。
HTTP 方式
fetchを用いてHTTPのリクエストとレスポンスでやり取りを行います。RPCが推奨されていますが、例えば用いているライブラリがデフォルトでHTTPを使う場合などに適しています。この場合でも通信は公衆インターネット網を通らないため高速です。また同じゾーン(ドメイン)間でWorker関数が別Worker関数にfetchを行うことはセキュリティの理由上、Workers基盤では禁止されていますが、このService Bindingを使うとそれが可能になります。
RPC 方式をやってみる
こちらを参考に2つの関数をHello Worldまで作成します。workeraとworkerbとします。
その後以下のコードをDeployします。
#:schema node_modules/wrangler/config-schema.json
name = "workera"
main = "src/index.js"
compatibility_date = "2024-08-21"
compatibility_flags = ["nodejs_compat"]
services = [
{ binding = "WORKER_B", service = "workerb" }
]
export default {
async fetch(request, env) {
const result = await env.WORKER_B.add(1, 2);
return new Response(result);
}
}
#:schema node_modules/wrangler/config-schema.json
name = "workerb"
main = "src/index.js"
compatibility_date = "2024-08-21"
compatibility_flags = ["nodejs_compat"]
import { WorkerEntrypoint } from "cloudflare:workers";
export default class extends WorkerEntrypoint {
async fetch() { return new Response("Hello from Worker B"); }
add(a, b) { return a + b; }
}
Deployの際、必ずworkerbからデプロイを行う必要があります。なぜならworkeraのデプロイを先に行うと以下のworkerbを認識できずにエラーで止まるためです。
services = [
{ binding = "WORKER_B", service = "workerb" }
]
デプロイが完了したらworkeraにアクセスしてください。以下の実行結果が3として戻ります。
const result = await env.WORKER_B.add(1, 2);
Service Bindingの仕様により、宣言なくenv.WORKER_B.addでworkerbの以下のclassが呼び出されていることがわかります。
add(a, b) { return a + b; }
ちなみにprivateで宣言されたclassは参照不可能です。
尚以下の部分は実際には使われていませんが、通常のworkerではdefaultのasyncは必要となるためデプロイがエラーで停止してしまうため入れています。
async fetch() { return new Response("Hello from Worker B"); }
smartplacement
worker関数からworker関数を呼び出すService Bindingを使う場合、Smartplacementの機能をオンにしておくことをお勧めしています。上記の例でいうとworkerbにこの機能をオンにしておきます。
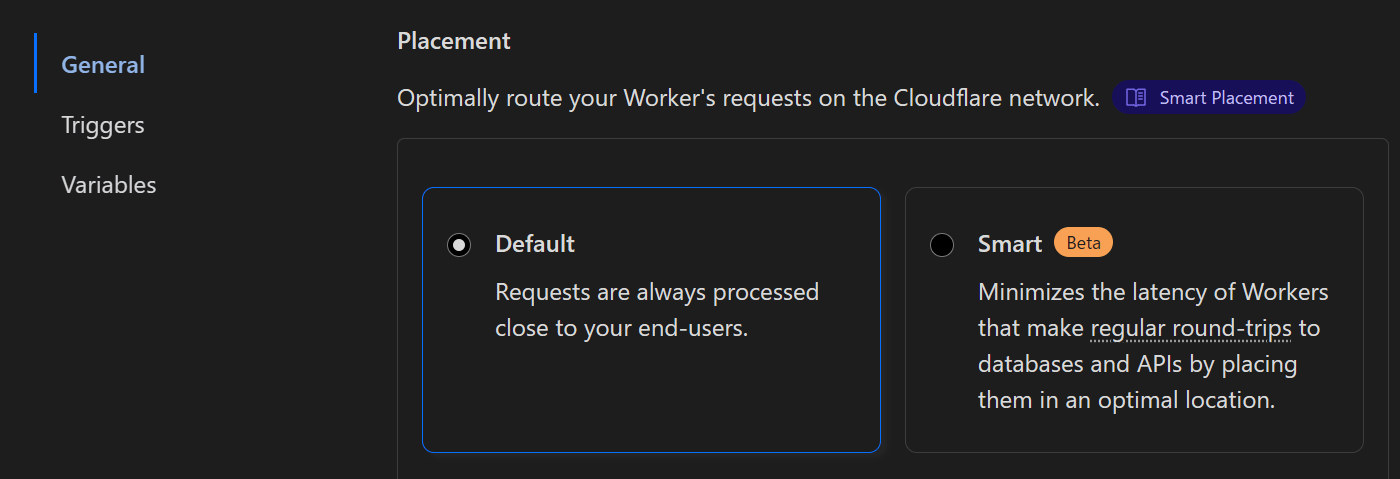
例えば以下の図の場合
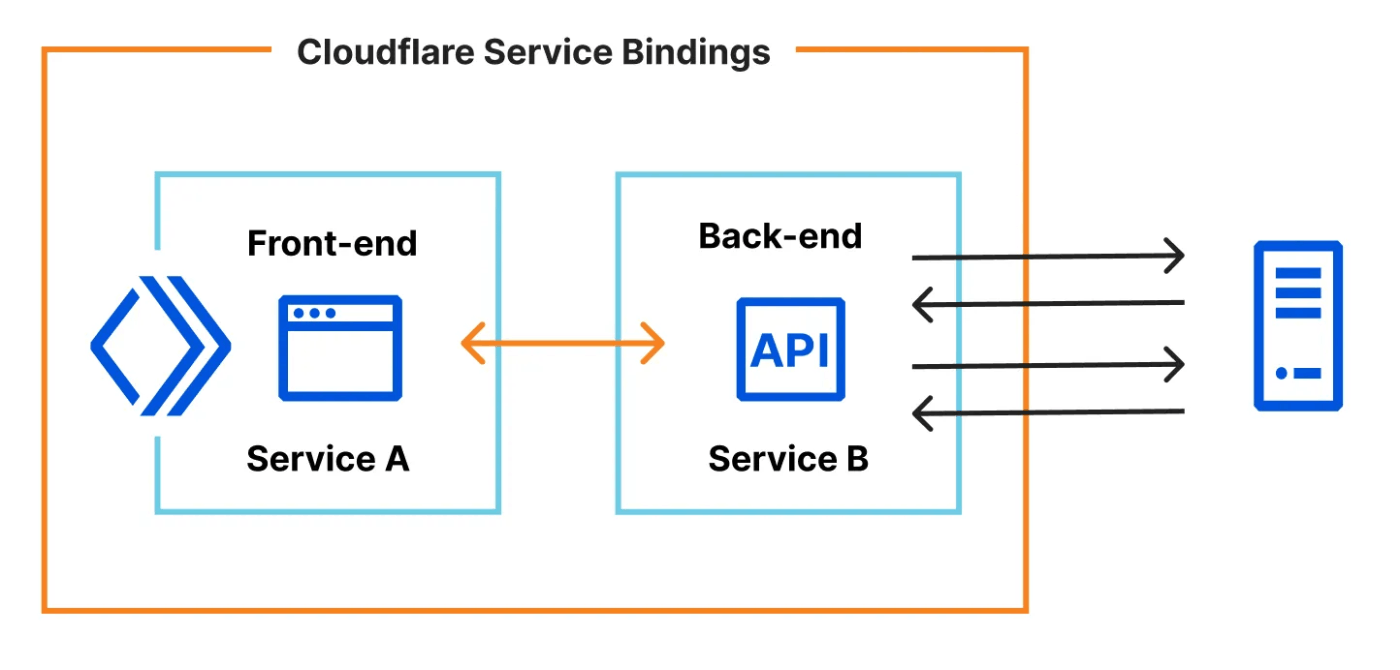
workerbにとってworkeraとの通信と、図でいう右側の何某かのへの通信と、どちらのレイテンシを極小化させた方がトータルとして早くなるのか、はケースバイケースです。Smartplacementをオンにしておくと自動でこれを判断してworkerbの起動場所を調整してくれます。これにより時にはworkeraと別の場所でworkerbが起動するケースも出てきます。
ステートレス基盤の多重起動は大丈夫?
Worker関数からWorker関数を呼び出した場合両方ステートレスになるため基盤の障害時やアプリケーションの異常終了時のデバッグやデータのロールバックが難しくなっていきます。このため、Service Bindingで連携する2つの関数が両方とも何某かのデータを変更させる場合、間にCloudflare Queueを挟んだ方が異常時の可観測性や運用性は向上するかもしれません。個人的にはステートレス基盤が直接ステートレス基盤を呼ぶ一連のワークフローを組む場合、データの変更は1か所にとどめるべきと考えています。(feature flag等永続性が求められないものは除く)
また調査目的としてログ専用のWorkerであるTail Workerを付けておくのも良いかもしれません。
またこのWorker Service Bindingの技術特性として、呼び出された関数は、呼び出した関数とメモリを共有します。このため処理が128MBのメモリを超える場合やはりQueueを挟むなどで2つの関数を明示的に分離する必要があります。
Discussion