Cloudflare Workers Browser Rendering API (Open Beta)を試す
今日は、先日リリースされたCloudflare Workers Browser Rendering APIを試してみます。この機能は現在OpenBeta版であり、どなたでも利用が可能ですが、まだまだこれからの進化のため多くのフィードバックを必要としています。
Browser Rendering API とは
WorkersはマイクロVMやコンテナを持ちいずChroniumがエッジで動作するため、ゼロレイテンシを実現できています。Browser Rendering APIでは、さらに専用の Chromium ブラウザ インスタンスと対話するための認証済みエンドポイントが提供されます。Puppeteerを用いることでスクリプト実行時に指定された任意のURLにアクセスを行い、その時にブラウザに表示されている内容をjpeg画像として保存します。
何に使うか
色々な使い方が考えられますが、その時にブラウザに何が表示されていたか?を画像として保存することになるので、外形監視が一般的です。ただし現時点ではBrowser Rendering APIは外形監視でとよく使われるHARファイルを作成せず、jpegだけが作成されることに注意してください。HARファイルとは例えばChromeブラウザの場合、デベロッパーツールで特定サイトへのアクセスを行った際にNetworkタブで取得可能な情報をjsonとして保存したものです。これとjpegをセットで保存しておくことで、後から、その時点でのウェブサイトはどう見えていたか?その時のブラウザ側のアクセス状況はどうだったか?と調べることができます。この辺りは今後のサービスアップデートに期待ですね。
早速やってみる
この手順をまずは試してみます。(例のごとく少しカスタマイズしています)
mkdir brapi
cd brapi
npm init -f
npm install wrangler --save-dev
npm install @cloudflare/puppeteer --save-dev
特に
npm install @cloudflpuppeteer --save-dev
は重要でオープンソース化されているWorkers専用Purppeteerを読み込んでいます。
次にjpegを保存するKV名前空間を以下で作成します。
npx wrangler kv:namespace create BROWSER_KV_DEMO
wrangler.tomlを以下に書き換えます。
name = "browser-worker"
main = "src/index.ts"
compatibility_date = "2023-03-14"
node_compat = true
workers_dev = true
browser = { binding = "MYBROWSER", type = "browser" }
kv_namespaces = [
{ binding = "BROWSER_KV_DEMO", id = "xxxxxxxxxxx" }
]
browser = { binding = "MYBROWSER", type = "browser" }
部分がWorkersにBrowser Rendering 専用環境エンドポイントをバインドするコマンドです。
xxxxxxxxx部分はKVのnamespaceIDが1個前の手順で出力されていますので、置換しておきます。
TypeScriptでwrangler init brapiを実行した後、wrangler.tsを以下に置き換えます。
import puppeteer from "@cloudflare/puppeteer";
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { searchParams } = new URL(request.url);
let url = searchParams.get("url");
let img: Buffer;
if (url) {
url = new URL(url).toString(); // normalize
img = await env.BROWSER_KV_DEMO.get(url, { type: "arrayBuffer" });
if (img == null) {
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
await page.goto(url);
img = (await page.screenshot()) as Buffer;
await env.BROWSER_KV_DEMO.put(url, img, {
expirationTtl: 60 * 60 * 24,
});
await browser.close();
}
return new Response(img, {
headers: {
"content-type": "image/jpeg",
},
});
} else {
return new Response(
"Please add an ?url=https://example.com/ parameter"
);
}
},
};
ファイルを保存してwrangler publishを実行してください。以下が表示されていればPublish完了です。

スクリーンショットを取得したいURLを以下のように指定します。
https:/?url=https://www.cloudflare.com/
こんな感じで画面にjpegが出力されます。

エラーが出る場合は、WorkersにKVがバインドされていないケースがあります。
マネージメントコンソールのKV画面から正しく名前空間ができているかを確認します。


できていればWorkersのSettingsタブのVariablesからKVがバインドされているかを確認してください。


ここが空欄の場合、設定を手で追加し再度テストを行います。
正しく動作すればKVの中にjpegが保存されます。


Downloadボタンを押し拡張子を.jpegに変更すると確認できます。
Cloudflareドキュメントのサンプルはこれで完了ですが、このサンプルだとKVに保存されるアイテムのキーがhttps://www.cloudflare.com/となっています。これではアクセスの都度新しい画像が上書き保存されるためあまりよろしくありません。以下のようにコードを書き換えてしまいましょう。
import puppeteer from "@cloudflare/puppeteer";
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { searchParams } = new URL(request.url);
let url = searchParams.get("url");
let img: Buffer;
if (url) {
let now = new Date();
let year = now.getFullYear();
let month = now.getMonth() + 1;
let date = now.getDate();
let hour = now.getHours();
let minute = now.getMinutes();
let second = now.getSeconds();
let str = year + '/' + month + '/' + date + ' ' + hour + ':' + minute + ':' + second;
url = new URL(url).toString(); // normalize
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
await page.goto(url);
img = (await page.screenshot()) as Buffer;
await env.BROWSER_KV_DEMO.put(url + str, img, {
expirationTtl: 60 * 60 * 24,
});
await browser.close();
return new Response(img, {
headers: {
"content-type": "image/jpeg",
},
});
} else {
return new Response(
"Please add an ?url=https://example.com/ parameter"
);
}
},
};
これにより毎回異なるキーでアイテムを作成します。


注意点ですがWorkersではGlobalでnew Date();を宣言した場合、常に1970/01/01が戻ってきますので、fetchの中で宣言させる必要があります。
では最後にcron起動型にこのスクリプトを変更しましょう。監視対象のURLはソースコードに埋め込んでおきます。
import puppeteer from "@cloudflare/puppeteer";
export default {
async scheduled(request: Request, env: Env, ctx: Ctx): Promise<Response> {
let url = "https://www.coudflare.com"
let img: Buffer;
if (url) {
let now = new Date();
let year = now.getFullYear();
let month = now.getMonth() + 1;
let date = now.getDate();
let hour = now.getHours();
let minute = now.getMinutes();
let second = now.getSeconds();
let str = year + '/' + month + '/' + date + ' ' + hour + ':' + minute + ':' + second;
url = new URL(url).toString(); // normalize
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
ctx.waitUntil(await page.goto(url));
img = (await page.screenshot()) as Buffer;
await env.BROWSER_KV_DEMO.put(url + str, img, {
expirationTtl: 60 * 60 * 24,
});
await browser.close();
return new Response(img, {
headers: {
"content-type": "image/jpeg",
},
});
} else {
return new Response(
"Please add an ?url=https://example.com/ parameter"
);
}
},
};
async scheduled(request: Request, env: Env, ctx: Ctx): Promise<Response>
ctx.waitUntil(await page.goto(url));
が変更点です。wrangler.tomlに以下を書き込むと1分起動型Cronになります。
[triggers]
crons = ["*/1 * * * *"]
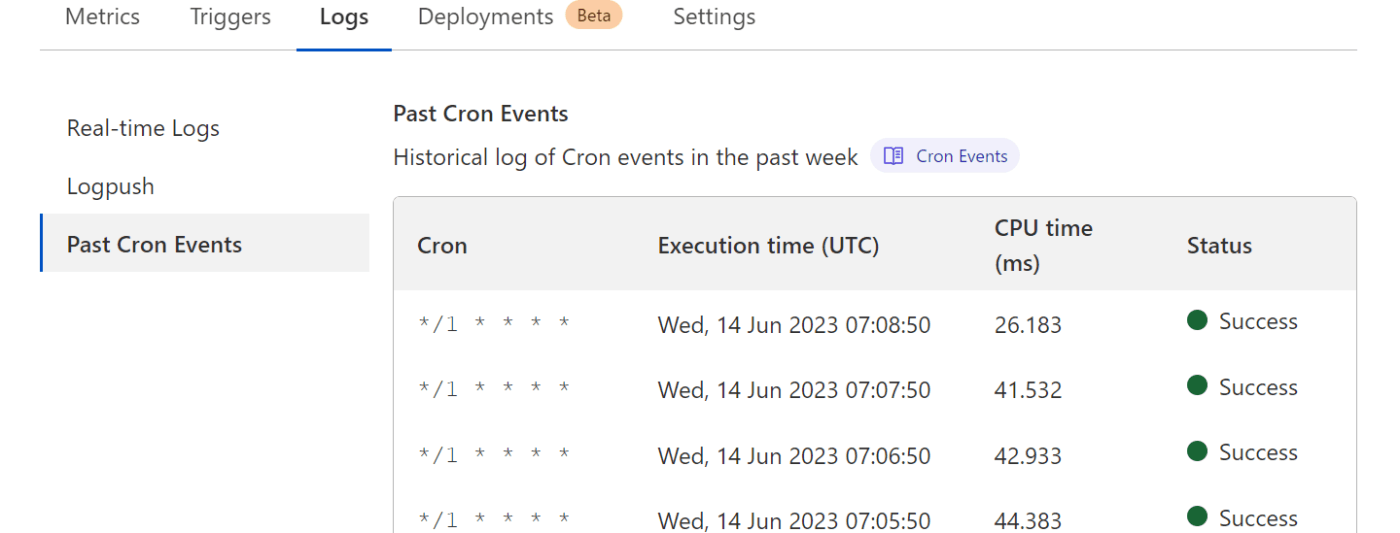
以下の通りcron triggerがセットされています。
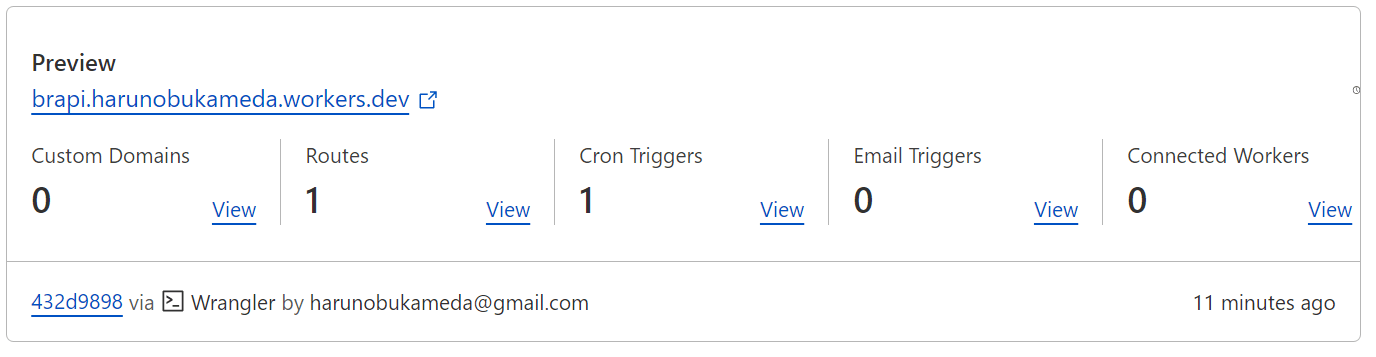

スクリプトからはfetchが削除されていますのでブラウザからのアクセスはエラーが戻るようになります。
Discussion