Cloudflare AI Gateway を試してみた
先日開催されたBirthday Weekで発表されたCloudflare AI Gatewayを試してみた記事です。(現在オープンベータ中で、ログ表示などには少しまだ課題を残しているようです。)
Cloudflare AI Gatewayとは
ChatGPTなどのAIサービスを用いる際に企業のGatewayとなるよう、それらサービスのProxyとして稼働するように作られています。対応しているサービスは以下の通りです。
・OpenAI
・Azure
・Hugging Face
・Workers AI
また、ユニバーサルエンドポイントという機能を持ち、一つのエンドポイントが複数LLMサービスのゲートウェイとして機能させることが可能です。例えばOpenAIへのリクエストに失敗した際、自動でHugging Faceへ通信させる、などが主な使い方です。
リクエストが失敗する理由はいろいろありますが、疎通の問題、OpenAIの問題、リクエスト元のネットワークの問題に加えてトークンの枯渇があります。企業でLLMの利用を行う場合、まとめてGateway経由でトークンおよびAPI Keyを管理しているケースがあります。このトークンが枯渇した場合、副のLLMに依頼を投げることが出来るようになります。
AI Gatewayを用いることで、外部LLMサービスへのリクエスト状態を可視化させることが可能となり、適正な利用がされているか?の分析を行うことが可能です。
またログ機能により、質問されている内容を把握することが可能となるため、機密情報が質問に用いられていないかを識別しDLPを組み合わせたり等の判断に役立てることができます。
早速やってみる
利用方法はとても簡単です。対応しているLLMサービスであればリクエスト用エンドポイントを変更するのみです。例えばOpenAiであれば通常用いられているAPIエンドポイントを以下のように書き換えるのみです。
https://api.openai.com/v1
https://gateway.ai.cloudflare.com/v1/<accountID>/<gateway name>/openai
ではWorkersでサンプルアプリケーションを作成していきます。
いつも通りnpm create cloudflare@latestを実行し、jsでHello Worldをまずは作ります。
作成されたフォルダへ移動し以下を実行します。
npm install openai
次にOpenAIの環境変数をセットします。
npx wrangler secret put OPENAI_API_KEY
上記をそのまま実行するとプロンプトが出てきますので、そこにAPI Keyを張り付けてください。
次にAPI Gatewayを作成していきます。マネージメントコンソール左ペインからAI→AI Gatewayをクリックします。

適当な名前を入れて作成を押します。
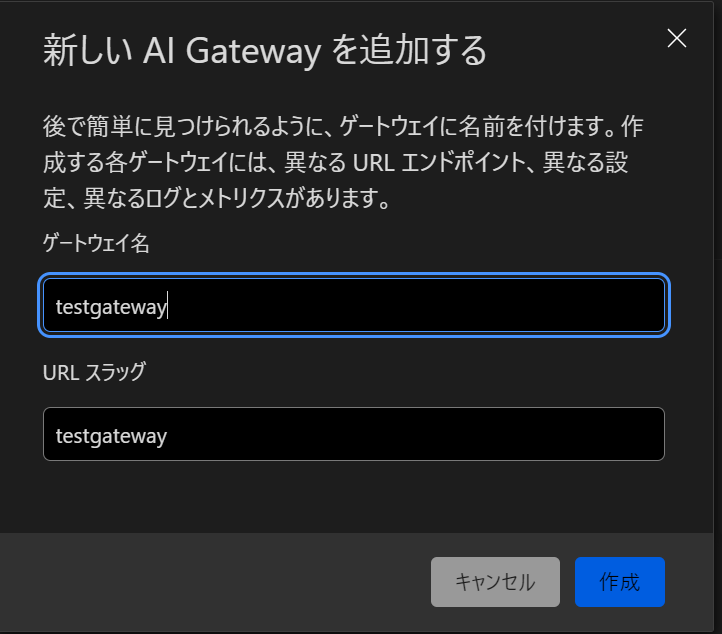
test gateway API Endpointsをクリックします。
ドロップダウンからOpen AIを選択しAI Gateway のエンドポイントをcopyしておきます。

Workersに戻りsrc/index.jsを以下に書き換えます。
import OpenAI from "openai";
export default {
async fetch(request, env, ctx) {
const openai = new OpenAI({
apiKey: env.OPENAI_API_KEY,
baseURL: "https://gateway.ai.cloudflare.com/v1/<account ID>/<gateway name>/openai"
});
try {
const chatCompletion = await openai.chat.completions.create({
model: "gpt-3.5-turbo-0613",
messages: [{role: "user", content: "こんにちは"}],
max_tokens: 100,
});
const response = chatCompletion.choices[0].message;
return new Response(JSON.stringify(response));
} catch (e) {
return new Response(e);
}
},
};
baseURL: "https://gateway.ai.cloudflare.com/v1/<account ID>/<gateway name>/openai"
の部分が重要です。OpenAIのエンドポイントではなくAI Gatewayのエンドポイントになっています。
wrangler deploy
を実行し関数をデプロイしてブラウザからアクセスします。

これでAI Gateway経由でOpenAIへのアクセスが完了しました。
マネージメントコンソールでログを見てみます。

分析
以下のようにOpenAIへのアクセス統計が出力されます。

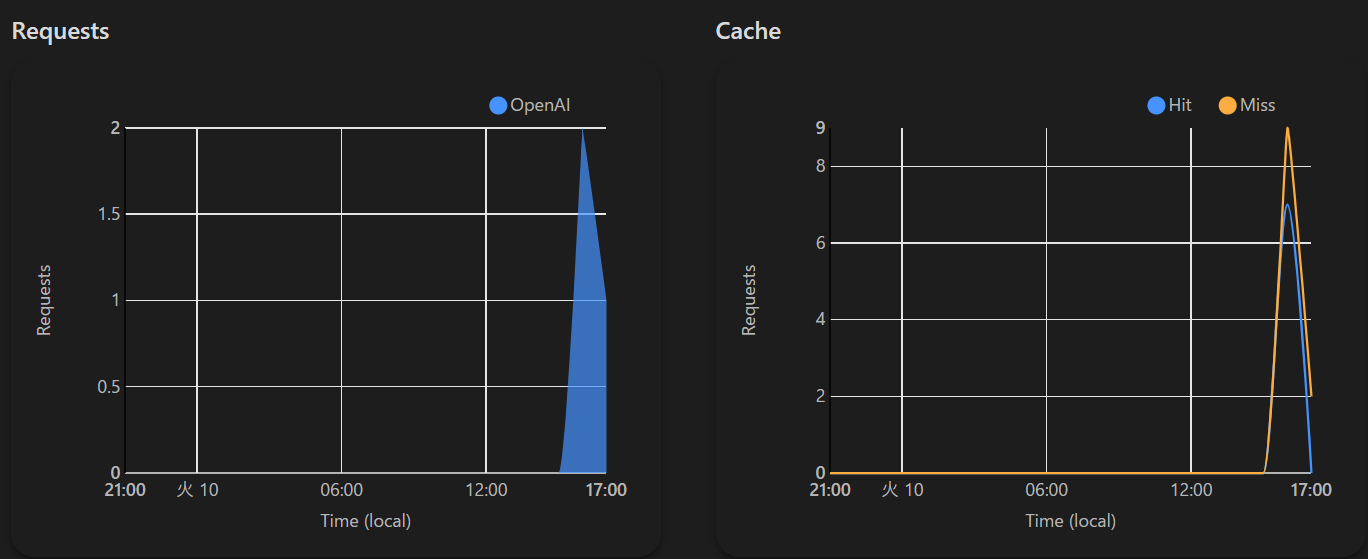
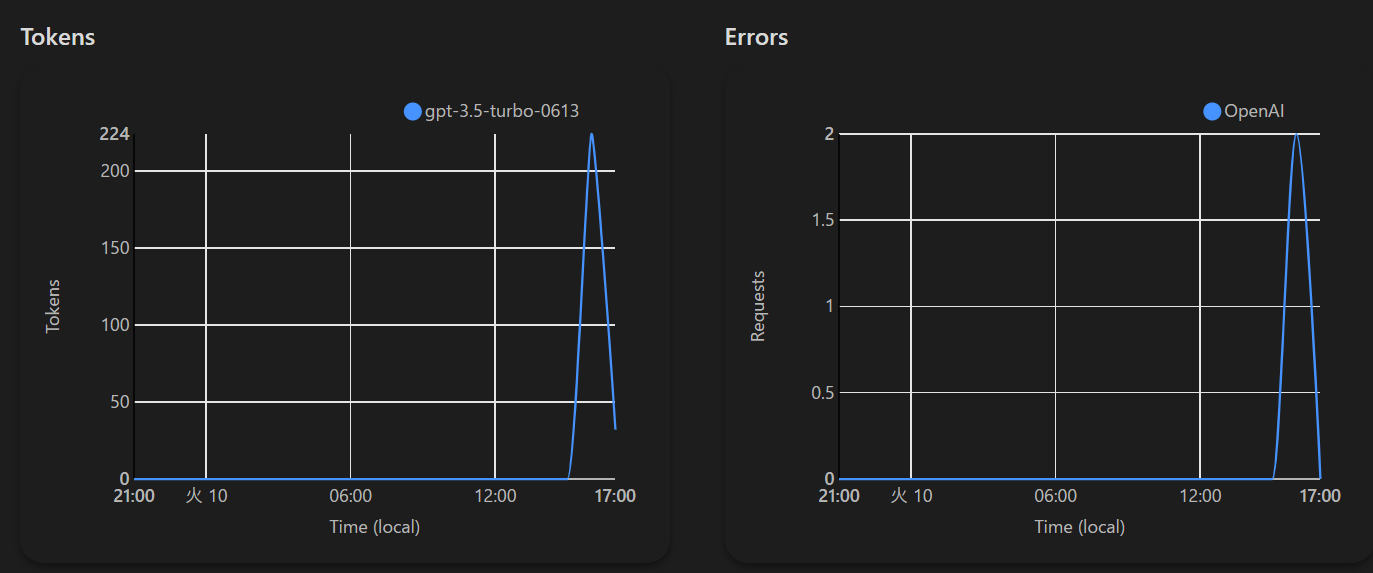
ここで表示されるcostですが現在OpenAIのみに対応しており、Cloudflareのコストではないです。また、あくまで目安ですので信じすぎず定期的にOpenAIの画面をチェックいただくことをお勧めします。
ログ
LLMのAPIはJSONでやり取りがされますがそのリクエストとレスポンスを記録するのがログ機能です。

一度のAPIコールごとに1件ログが出力されます。
ドリルダウンをすると以下のようにRequestとReponseが確認できます。

{
"model": "gpt-3.5-turbo-0613",
"messages": [
{
"role": "user",
"content": "こんにちは!"
}
],
"max_tokens": 100
}
{
"id": "chatcmpl-892atOsCWJhq5Porc0AE0by8mpXLF",
"object": "chat.completion",
"created": 1697165615,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "こんにちは! いらっしゃいませ。何かお困りですか?"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 22,
"total_tokens": 31
}
}
設定
このトグルをオンにすることでログが出力されます。


この機能をオンにすると、質問に対する回答がキャッシュされ、指定された時間の間トークンを消費せずにキャッシュされた回答が戻ります。試したところこんにちはとこんにちは!では異なる質問と認識されるため、ベクトル化されたデータを用いた質問の類似性の判断などは行っていないようです。
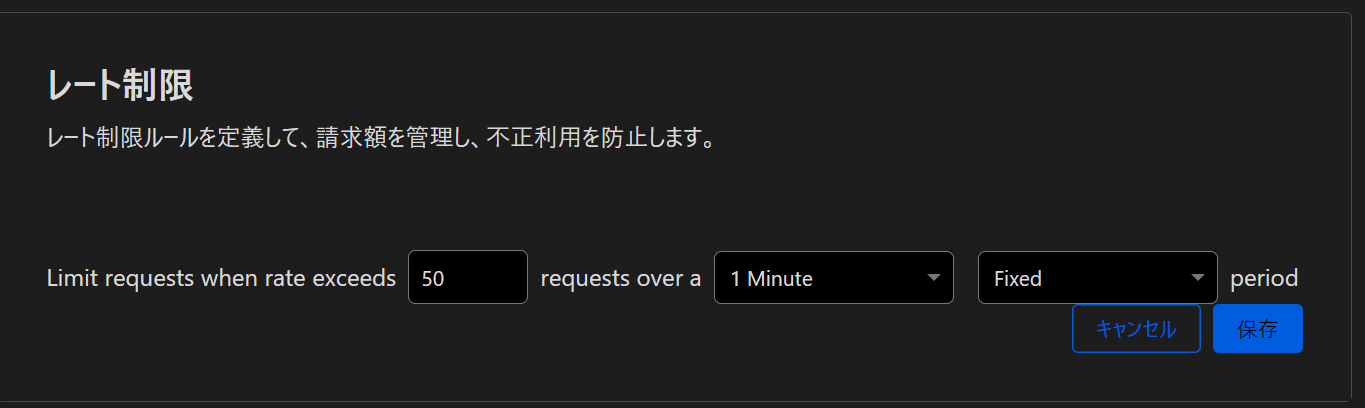
定められた時間の中で一定数以上のリクエストに制限を設ける機能がRate Limitingです。
企業全体でトークンの消費量を一定に保ちたい場合などに役立ちます。
Discussion