Amazon S3 Tables (Apache Iceberg) をやってみる
沖縄の皆さん元気ですかー!?
Amazon S3 Tables とは
AWSのドキュメントによるとS3 Tables とは以下の定義の様です。
Amazon S3 Tables は、Apache Iceberg サポートが組み込まれた初めてのクラウドオブジェクトストアを提供し、表形式データの大規模な保存を効率的に行えるようにします。継続的なテーブル最適化は、バックグラウンドでテーブルデータを自動的にスキャンして書き換えるため、管理されていない Iceberg テーブルと比較して最大 3 倍高速なクエリパフォーマンスを実現します。これらのパフォーマンス最適化は、今後も引き続き改善されます。さらに、S3 Tables には Iceberg ワークロード固有の最適化が含まれており、汎用 S3 バケットに保存されている Iceberg テーブルと比較して、1 秒あたり最大 10 倍のトランザクションを配信できます。S3 Tables のクエリパフォーマンスの改善について詳しくは、ブログをご覧ください。
従来S3に保存されているデータに対してクエリを実行できるAWSのサービスとしてはAmazon AthenaやAmazon Redshift Spectrumなどがありました。これらのサービスはS3がオブジェクトストレージであるという技術特性から、データロックが行えず、またデータの更新なども行えない(S3にはデータ更新という機能が存在せず、上書きのみが可能)ため参照系クエリのみが実行可能でした。
2022年にAmazon AthenaがApache Icebergに対応しました。
そのハンズオンシナリオはこちらです。
(今回のブログ用に少しアップデートしてあります)
Apache Iceberg とは
ChatGPT先生によるとApache Icebergの特徴は以下の通りです。
Apache Iceberg の特徴
1.スキーマの進化 (Schema Evolution)
列の追加・削除・リネームが可能で、データの再書き込みが不要。
2.隠れたパーティショニング (Hidden Partitioning)
ユーザーが明示的にパーティションを管理する必要がなく、クエリパフォーマンスが向上。
3.タイムトラベル & スナップショット (Time Travel & Snapshots)
過去のテーブルの状態をクエリでき、データの復元や監査に役立つ。
4.ACID トランザクション対応
データの一貫性を確保しながら更新や削除が可能。
5.効率的なメタデータ管理
Hive Metastore に依存せず、大規模データでもスケールしやすい設計。
6.マルチエンジン対応
Spark、Trino、Flink、Presto、Hive など、さまざまなデータ処理エンジンで利用可能。
一番特徴的なのはやはりメタデータによりオリジナルのデータが管理されることでしょう。これにより本来更新か行えなかったオリジナルデータに対応するメタデータにステータスを管理させることによって疑似的なデータのUpdate/InsertやDeleteが行えるようになります。またそれぞれの更新系オペレーションにはタイムスタンプが記録され、過去に遡ったデータスナップショットへのタイムトラベルクエリが簡単に行えることです。
例えば以下のようなSQLで実行可能です。
SELECT * FROM iceberg_table20220415 FOR TIMESTAMP AS OF TIMESTAMP '2025-01-26 08:40:00 UTC'
Amazon AthenaでApache Icebergに対応したのですが、今回のAmazon S3 Tablesが管理されていない Iceberg テーブルと比較して最大 3 倍高速なクエリパフォーマンスを実現します。と謳っているため大幅なパフォーマンス向上が期待できます。
さっそくやってみる
この作業ではルートユーザーでは行えません。Lake Formationがrootに対する権限の付与をサポートしてないためです。AdministratorAccess等の権限が付与されたユーザーを使います。
S3, S3 Tabeles, Athena, LakeFormation, Glueの権限が付与されていればAdministrator以外でも大丈夫です。
1. S3 Tablesの作成
の手順をやっていきます。
マネージメントコンソールのS3画面、左ペインからテーブルバケットをクリックします。
まず統合を有効化しますをクリックします。


テーブルバケットの作成をクリックします。

適当な名前を付けて、全てデフォルトのままバケットを作成してください。
作成されたARNをコピーしておきます。

2. 名前空間とスキーマの作成 (Old)
2015年3月にアップデートがありAthena側から直接S3 Tablesにテーブルを作成できるようになりました。とはいえCLI経由での操作も乙なもんですのでこれはこれでやります。
次に以下のコマンドで名前空間を作成します。
aws s3tables create-namespace --table-bucket-arn <s3 tables バケットarn> --namespace <名前空間の名前>
viエディタでtable.jsonというファイルを作成します。<S3 tables バケットarn>は自分の環境に合わせて置換してください。
{
"tableBucketARN": "<S3 tables バケットarn>",
"namespace": "<先ほど作成した名前空間>",
"name": "my_table",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{"name": "id", "type": "int","required": true},
{"name": "name", "type": "string"},
{"name": "value", "type": "int"}
]
}
}
}
}
作成出来たら以下のコマンドを実行します。
aws s3tables create-table --cli-input-json file://table.json
これでスキーマが作成されます。
(当初の手順では書き漏れていました。@raiha_tecさん指摘ありがとうございます!)
沖縄の皆さん元気ですかー!?
2. 名前空間とスキーマの作成 (Athenaから)
では新しい機能のAthenaからの作成も行います。

CLIで作成されたものが必と表示されています。これに追加でもう一つAthenaから作成します。Athenaでテーブルを作成をクリックします。

先ほどの名前空間を指定してAthenaでテーブルを作成をクリックします。
そうすると以下の様にSQL実行画面が出てきます。ただし今実行するとエラーとなります。


AWS Lake Formationの設定を行っていないためです。AthenaからS3 Tablesを操作するためにはLake Formationで権限を付けてあげる必要があります。(ちなみに皆さんの過去の作業状態次第ではLakeFormationの作業をしなくてもそのままAthenでクエリが実行できる場合もあります。)
尚これはAhena側の制限でありS3 TablesはIcebergアプリケーションからのアクセスを受け付けるREST APIが現在は提供されています。
3. AWS Lake Formation の設定
以下の作業はrootユーザーでは行えないので、マネージメントコンソールへログイン可能な別のIAMユーザーを作成して作業を行って下さい
ちなみにrootユーザーでAWSの操作を行えばこのステップは全て飛ばすことが行えますが、rootユーザーでのAWS操作はおすすめされていないのは言うまでもない(民明書b(ry)
次にAthenaからS3 Tables のバケットにクエリを発行できるよう権限設定を行います。
この手順ではLake Formationを使っています。通常汎用S3バケットに対してAthenaからクエリを発行する場合、Lake Formationの設定は不要です。ワークグループというAthenaの設定から読み取りと操作ログを保存するS3バケットを指定するだけですが、やってみたところS3 Tablesのバケットは指定が行えませんでした。Lake Formationが必須の様ですので、ここは大人しく手順に従って作業を進めます。
https://console.aws.amazon.com/lakeformation/
にアクセスを行います。普段Lake Formationを利用していない初回の場合は以下のように権限を付与する旨のダイアログが出ますので、権限を付与してあげます。

左ペインのData permissionsをクリックします。

Grantボタンをクリックします。

権限を付与したいIAMユーザーを作成します。

LF-Tags...の部分でNamed Data Catalog Resourcesを選択してください。

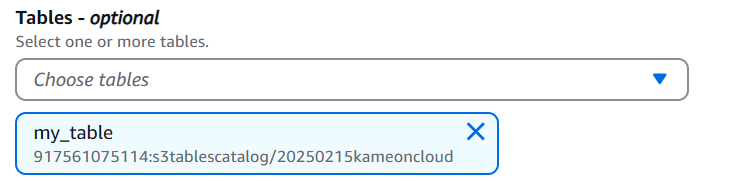
Catalogsで先ほど作成したS3 Tablesの名前が含まれたものをカタログを選択します。

少し解説 Glue Data Catalog
この部分ですが、手順書には適切なGlue Data Catalogを選択、と記載があります。S3バケットの中身をAthenaやRedshift Spectrumからテーブルとして参照させるには、だれかがバケットの中身を読み取ってテーブルフォーマットとして定義してあげる必要があります。それを行うサービスがAWS Glueというもので、そのサービスが管理しているテーブルフォーマット(実際はS3の中身をテーブルとして 定義しているもの)がGlue Data Catalogです。この手順だと、自動でS3 Tablesの作成を行った後table.jsonをスキーマとして設定した段階で自動で作成されているのでGlueを意識する必要はりません。
話をもとに戻します。次にDatabasesで先ほど作成したスキーマを指定します。

Tablesも同様です。
Tables PermissionsでSuperを選択してGrantを押します。
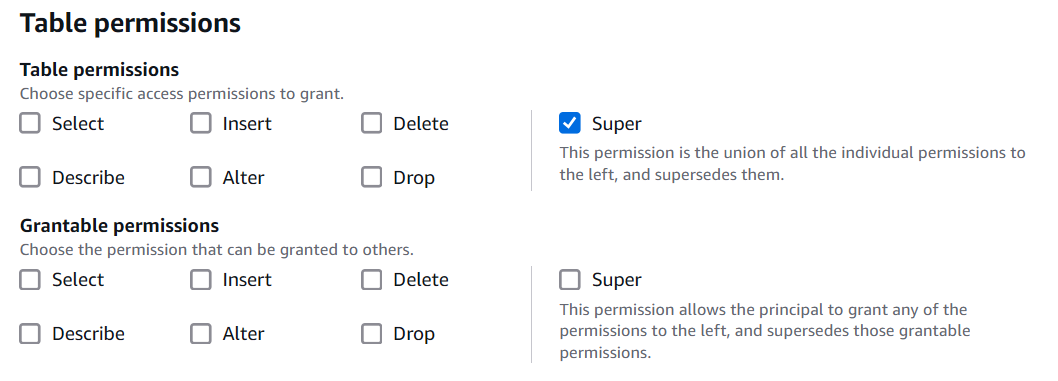
以下のようにアクセス権が設定されます。

4. Amazon Athena からクエリの発行
Athenaのマネージメントコンソールからクエリエディタを起動すると先ほど設定したテーブルなどが見えるはずです。
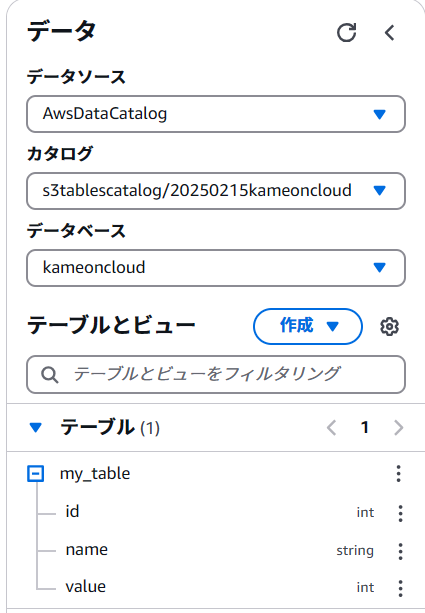
以下2つのクエリを実行してみます。<>の値は適宜置換してください。
INSERT INTO <namespace>.my_table
VALUES
(111, 'ABC', 100),
(222, 'XYZ', 200);
SELECT * FROM <namespace>.my_table;
成功したら以下のように時間を1分ずつ遡ってタイムトラベルクエリを実行して見みます。
select * from <namespace>.my_table FOR TIMESTAMP AS OF TIMESTAMP '2025-02-15 5:52:00 UTC'
沖縄の皆さん元気ですかー!?
5. お掃除!
S3 Tablesはマネージメントコンソールからは削除できないためCLIで削除します。
aws s3tables delete-table --table-bucket-arn <bucket arn> --namespace my_namespace --name my_table
aws s3tables delete-namespace --table-bucket-arn <bucket arn> --namespace my_namespace
aws s3tables delete-table-bucket --region ap-northeast-1 --table-bucket-arn <bucket arn>
テーブルを削除すると、マネージメントコンソールから名前空間の確認が途中でできなくなるので、3番目のコマンドが動作しなくなる人がいたら以下を実行して名前空間を確認してください。
aws s3tables list-namespaces --table-bucket-arn <bucket arn>
Discussion