🎉
TiDB Cloud Starter の自動埋め込み (2) 外部埋め込みLLMモデルの持ち込み
前回の記事では、TiDB Cloud Starter が新たに提供している機能である自動埋め込み機能を触ってみました。これにより、TiDB Vector Search に対するベクトル検索が、データ挿入時、検索時ともに事前の埋め込み(ベクトル化)が不要で行えるようになりました。
以下の様にテーブル作成時に対象カラムに用いられるモデルを指定することで、自動で埋め込み処理が行われるようになります。
CREATE TABLE documents (
id INT PRIMARY KEY AUTO_INCREMENT,
content TEXT,
content_vector VECTOR(1024) GENERATED ALWAYS AS (
EMBED_TEXT("tidbcloud_free/amazon/titan-embed-text-v2", content)
) STORED
);
テーブルスキーマで指定しておけば、Insert,Select双方において自動でリテラルがカラム定義で指定されたモデルが利用されます。
insert
INSERT INTO documents (content) VALUES
("Electric vehicles reduce air pollution in cities."),
("Solar panels convert sunlight into renewable energy."),
("Plant-based diets lower carbon footprints significantly."),
("Deep learning algorithms improve medical diagnosis accuracy."),
("Blockchain technology enhances data security systems.");
select
SELECT id, content FROM documents
ORDER BY VEC_EMBED_COSINE_DISTANCE(
content_vector,
"Renewable energy solutions for environmental protection"
)
LIMIT 3;
SHOW CREATE TABLE documents;を実行するとGenerated Columnとして対応されていることがわかります。
CREATE TABLE `sample` (
`id` int(11) DEFAULT NULL,
`content` text DEFAULT NULL,
`embedding` vector(1536) GENERATED ALWAYS AS (embed_text(_utf8mb4'openai/text-embedding-3-small', `content`)) STORED
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
Generated Columnについては別の記事でまとめていますので、併せてご確認ください。
外部モデルの持ち込み
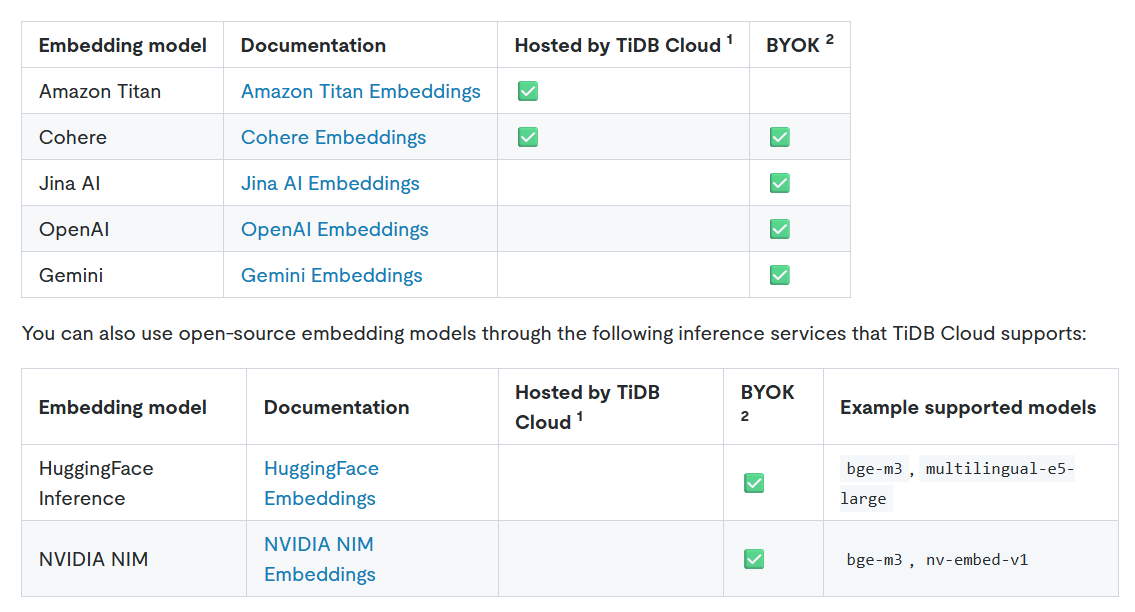
公式サンプルではTiDB Cloudが提供するAmazon Titanモデルを利用していましたが、別途外部モデルの持ち込みが可能となっています。
さっそくやってみる
1. OpenAI API キーの発行
まずはここからAPI Keyを発行します。
2. 環境変数の組み込み
SQL Editorで環境変数をセットします。
SET @@GLOBAL.TIDB_EXP_EMBED_OPENAI_API_KEY = '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';
3. テーブル作成
CREATE TABLE sample (
`id` INT,
`content` TEXT,
`embedding` VECTOR(1536) GENERATED ALWAYS AS (EMBED_TEXT(
"openai/text-embedding-3-small",
`content`
)) STORED
);
openai/text-embedding-3-smallとして外部埋め込みモデルが指定されています。
4. データ挿入と検索
INSERT INTO sample
(`id`, `content`)
VALUES
(1, "Java: Object-oriented language for cross-platform development."),
(2, "Java coffee: Bold Indonesian beans with low acidity."),
(3, "Java island: Densely populated, home to Jakarta."),
(4, "Java's syntax is used in Android apps."),
(5, "Dark roast Java beans enhance espresso blends.");
SELECT `id`, `content` FROM sample
ORDER BY
VEC_EMBED_COSINE_DISTANCE(
embedding,
"How to start learning Java programming?"
)
LIMIT 2;
このように文字列ではなくベクトルを用いた検索が行われていることがわかります。

SQL 実行計画の確認
自動埋め込みによるベクトル検索機能はIndexが効かずフルスキャンとなっていることが確認できます。
id task estRows operator info actRows execution info memory disk
Projection_15 root 2 test.sample.id, test.sample.content 2 time:1.19ms, loops:2, Concurrency:OFF 1016 Bytes N/A
└─TopN_8 root 2 Column#7, offset:?, count:? 2 time:1.18ms, loops:2 12.9 KB N/A
└─Projection_16 root 2 test.sample.id, test.sample.content, test.sample.embedding, vec_cosine_distance(test.sample.embedding, ?)->Column#7 2 time:1.16ms, loops:2, Concurrency:OFF 12.5 KB N/A
└─TableReader_14 root 2 data:TopN_13 2 time:1.12ms, loops:2, cop_task: {num: 1, max: 1.03ms, proc_keys: 5, copr_cache_hit_ratio: 0.00, build_task_duration: 8.17µs, max_distsql_concurrency: 1}, rpc_info:{Cop:{num_rpc:1, total_time:991.1µs}} 12.4 KB N/A
└─TopN_13 cop[tikv] 2 vec_cosine_distance(test.sample.embedding, ?), offset:?, count:? 2 tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 5, total_process_keys_size: 31181, total_keys: 6, get_snapshot_time: 2.08µs, rocksdb: {block: {}}} N/A N/A
└─TableFullScan_12 cop[tikv] 5 table:sample, keep order:false, stats:pseudo 5 tikv_task:{time:0s, loops:1} N/A N/A
このため多用される場合は以下の通り従来型のVector Indexを用いたベクトル検索と組み合わせて利用することを検討する必要があります。
CREATE TABLE documents (
id INT PRIMARY KEY AUTO_INCREMENT,
content TEXT,
content_vector VECTOR(1024) GENERATED ALWAYS AS (
EMBED_TEXT("tidbcloud_free/amazon/titan-embed-text-v2", content)
) STORED,
VECTOR INDEX ((VEC_COSINE_DISTANCE(content_vector)))
);
Discussion