LangChainJS と OpenAI を Cloudflare Workersから試してみる
先日Serverless Days 2023 に参加してきました。
Cloudflare も Workers を中心としたセッションをさせてもらいました。
そこで改めて肌で感じたのが Serveless コミュニティも LLM に強い興味を持っており、LangChainJSは今後必須のツールになるであろうということです。
LangChainJSとはなにか
Bing 先生によると
LangChainJSとは、LLM(Large Language Model)とLLMにはない他のソースやLLMにはできない計算方法を組み合わせることを目的としたJavaScriptのライブラリです。LangChainJSを使うと、WebページやGoogle検索などの外部ソースにアクセスしたり、独自のツールを定義したりすることができます。LangChainJSは、Cloudflare WorkersやZapierなどのプラットフォームとも連携できます。LangChainJSは、自然言語処理の可能性を広げるための便利なツールキットです。
単純にはJavaScript経由でLLMを呼び出す際に色々な処理を挟み込むことができるライブラリ、と解釈してよさそうです。
Cloudflare は公式ブログで「Using LangChainJS and Cloudflare Workers together」としてWorkersでの実装手順をアナウンスしていますので、今回はそれをやってみることとします。
さっそくやってみる
必要なもの:
・OpenAIアカウントとAPI Key
OpenAIではアカウント開設直後にはクレジットが付与されるらしいのですが、私の環境では付与されていませんでした。開設後3か月経過したからか、ポリシーが変わったか、私の環境ではクレジットが付与されていませんでしたので、5ドルだけ課金しました。
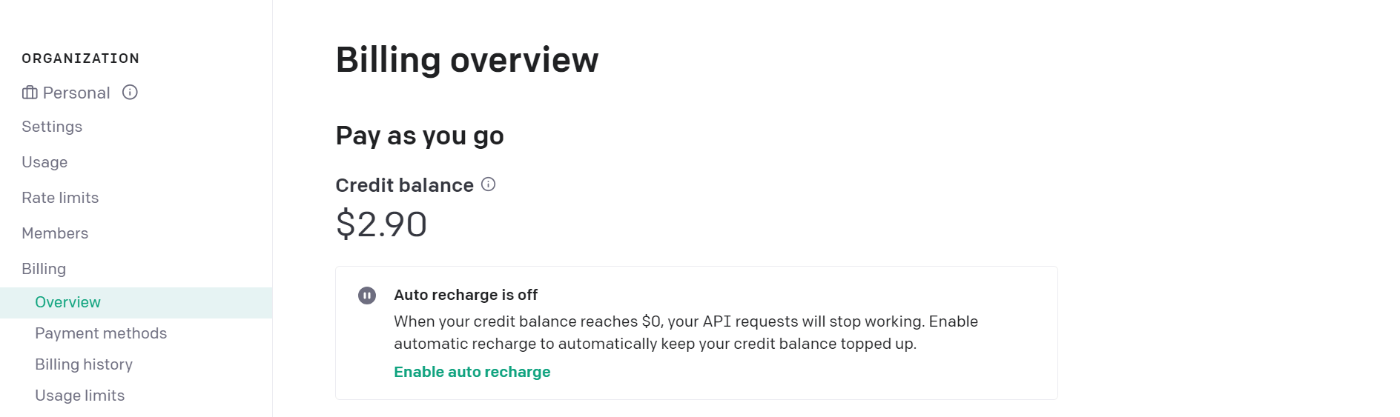
自分への投資と思えば安いものなので興味がある方は払ってしまいましょう。OpenAIの手順自体はこの記事からは割愛します。
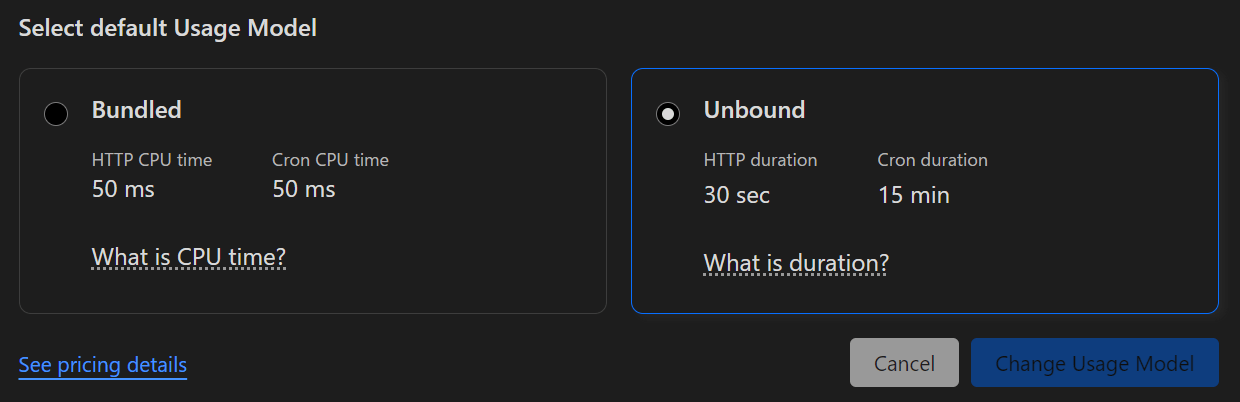
・Workers Unboundモード
月五ドルです。上記同様自分への投資と思えば安いものなので興味がある方は払ってしまいましょう。Workersは無償プランでは10msまでのCPU時間を使えますが、OpenAI等、外部APIを呼び出す場合これはタイムアウトしてしまいます。このためUnboundモードに切り替え利用可能なCPU時間を30秒に延長させます。
まずはいつも通り、この記事に基づきHello Worldまでやっておきます。
以下のコマンドを実行し、新しいプロジェクトを立ち上げます。
mkdir langchain-workers
npm create cloudflare@latest
プロジェクト名(そのまま公開したアプリケーションのアブドメインになります)に任意の文字列を設定し、Hello World Scriptを選びます。TypeScriptはnoにします。
Do you want to deploy your application?はNoで作業を進めましょう。
次に以下を実行します。
cd <出来ているサブディレクトリ>
npx wrangler secret put OPENAI_API_KEY
OpenAIのKeyをコピペで貼り付けます。
これによりAPI Keyをソースコードに貼り付けることなくWorkersの環境変数にセットすることが出来ます。(ただし、Windowsのローカル環境では、この環境変数は動作しませんのであとで少しソースコードを変更することで対応します。覚えておいてください。)
npm install langchain
npm install cheerio
でLangChainJSとCheerioをインストールします。この時点で一旦wrangler devを実行し画面にHello Worldが出ることを確認しておきます。
/src/index.jsを以下に書き換えます。
import { CheerioWebBaseLoader } from "langchain/document_loaders/web/cheerio";
export default {
async fetch(request, env, ctx) {
const loader = new CheerioWebBaseLoader(
"https://en.wikipedia.org/wiki/Brooklyn"
);
const docs = await loader.loadAndSplit();
console.log(docs);
return new Response("Hello World!");
},
};
CheerioWebBaseLoaderは、LangChainJSに含まれるクラスの一つで、Webスクレイピング用ツールとして機能します。Cheerioというライブラリを使って、HTMLドキュメントをパースしてテキストやメタデータを抽出し、LangChainJSのDocumentインスタンスを作成します。
再度wrangler devを実行してみます。以下のような情報が出てくればHTMLは無事パースされています。
[mf:inf] GET / 200 OK (999ms)
Array(242) [ Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document, Document,
試しに以下をコードに挿入しておくとHTMLがパスされて各Arrayオブジェクトに格納されていることがわかります。
console.log(docs[1]);
console.log(docs[2]);
console.log(docs[3]);
console.log(docs[4]);
この辺りの動作の詳細は以下にまとまっていますので興味がある方は見てください。
次に/src/index.jsを以下に変更します。
import { CheerioWebBaseLoader } from "langchain/document_loaders/web/cheerio";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAI } from "langchain/llms/openai";
import { RetrievalQAChain } from "langchain/chains";
export default {
async fetch(request, env, ctx) {
const loader = new CheerioWebBaseLoader(
"https://en.wikipedia.org/wiki/Brooklyn"
);
const docs = await loader.loadAndSplit();
const store = await MemoryVectorStore.fromDocuments(docs, new OpenAIEmbeddings({ openAIApiKey: env.OPENAI_API_KEY}));
const model = new OpenAI({ openAIApiKey: env.OPENAI_API_KEY});
const chain = RetrievalQAChain.fromLLM(model, store.asRetriever());
const question = "What is this article about? Can you give me 3 facts about it?";
const res = await chain.call({
query: question,
});
return new Response(res.text);
},
};
読み込んでいるライブラリがいろいろと増えています。この辺りはブログを読んでいただくとて作業を先に進めるためにwrangaler devを実行します。おそらく環境次第では以下のエラーが出るはずです。

これは、先ほどOpenAIのAPI KeyをWorkersの環境変数に書き込みましたがローカル環境からアクセスできないためです。
2か所ありますので固定文字列で置き換えるなど回避しておきましょう。
以下のようにBrooklynに対する回答が出てきます。
This article is about Brooklyn, a borough of New York City, New York, United States. Three facts about Brooklyn are: 1) It was published in 1941 and is still in existence today; 2) It is home to over 2.6 million people; 3) It is the most populous borough of New York City.
これはソースコード上の
const question = "What is this article about? Can you give me 3 facts about it?";
に対する回答です。最後に外部インプットで質問を受け取ることが出来るように以下に書き換えます。
(前)
const question = "What is this article about? Can you give me 3 facts about it?";
(後)
const { searchParams } = new URL(request.url);
const question = searchParams.get('question') ?? "What is this article about? Can you give me 3 facts about it?";
URLでWorkersを呼び出す際に/?question=xxxxxがあればその質問をOpenAIに投げて、空欄だった場合What is this article about? Can you give me 3 facts about it?を投げます。
例えば以下の様に呼び出すと返事が戻ってきます。
http://127.0.0.1:8787/?question=where is boorklyn?
名言ボットを作る
では最後に少し日本語でカスタマイズをしてみます。
検索のもとになるサイトを以下に変更します。
const loader = new CheerioWebBaseLoader(
"https://www.cosmopolitan.com/jp/trends/lifestyle/g32046697/comforting-quotes-to-encourage-you-during-life-s-greatest-challenges34/"
);
wrangler publishでDeployした後
https://<domain>/?question=名言を一つランダムでください
でサイトを呼び出します。毎回異なる名言が出てきます。
よくよく考えたら偉人Botの必要性はない気が。。。
だって、名言は変えずにそのまま出してほしいわけなので。
データソースを以下に変更してCloudflareについていろいろ質問してみる、等ができます。
https://en.wikipedia.org/wiki/Cloudflare
Discussion