ComfyUIで音声データセットを作る
モチベーション
音声合成や声質音声のモデル訓練には良質な音声データセットが必要です。文字起こしやノイズ除去、ボーカル分離などを駆使して準備することが多いです。こういった場合、基本的には書き捨てのコードを書くことになります。問題は処理をかける順番やパラメータを変えて実験してみると途端にコードがごちゃごちゃし始めることです。いい感じにコードの再利用性を高めつつ、気軽に色々試せるようにするにはどうしたらいいかと考えました。そこでComfyUIに白羽の矢が立ちました。
先行事例の調査
ComfyUIは画像生成のイメージが強いですが、音声を扱うカスタムノードも一定数存在することがわかりました。
カスタムノード作成
サンプルケースとして、以下の前処理フロー実現を目指しました。
- 音声の読み込み
- Demucsでボーカル抽出
- Silero VADで無音除去
- faster-whisperで文字起こし
- 文字起こしテキストとボーカル音声を保存
ここでは詳しくは触れませんが、およそ以下の流れでカスタムノードを作ることができます。
- Gitリポジトリを作り、ComfyUIの
custom_nodesディレクトリに配置する - カスタムノードクラスを定義する
-
__init__.pyでエクスポートする
ワークフロー全体像
以下のようになりました。以降、個別のノードについて述べていきます。
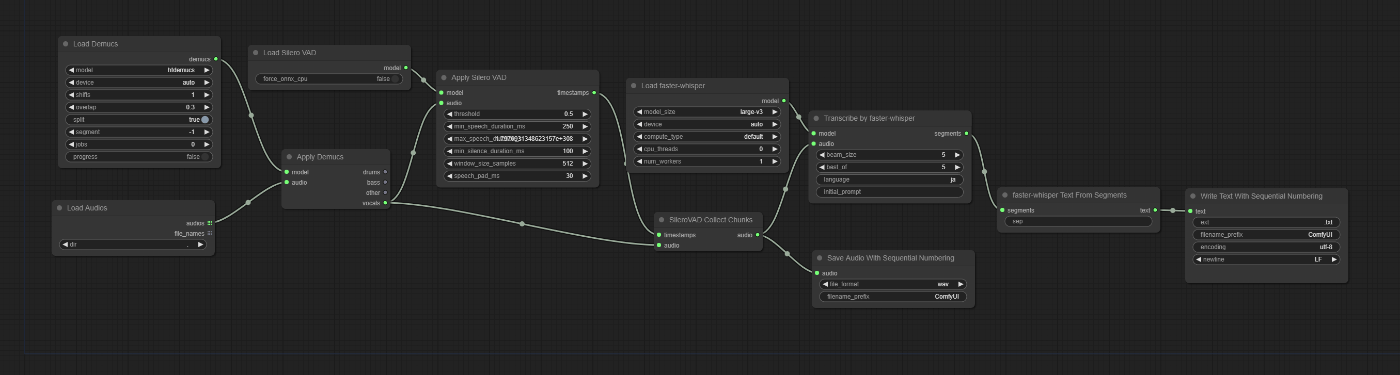
音声の読み込み
種々のAIツールを活用するため、PyTorch torchaudioを軸にした設計が良さそうです。フローを流れるデータはwaveformとsample_rateを属性にもつデータクラスにしてみました。密接に関係するデータはセットで扱うメリットが大きそうです。
torchaudio.loadで音声ファイルを読み込むノードを作りました。

audio_inputディレクトリを事前に作っておき、この中のファイルorディレクトリを参照するようにします。UIではコンボボックスで選択することができます。
AIツール(Demucs, Silero VAD, faster-whisper)
画像生成で使われるControl Netは
- モデルを読み込むことに特化したLoaderノード
- モデルと画像を受け取って、処理を適用するApplyノード
という2段構成になっています。このように分離しておくことにより、1度読み込んだモデルを使い回すことができます。これと同様にノードを準備しました。
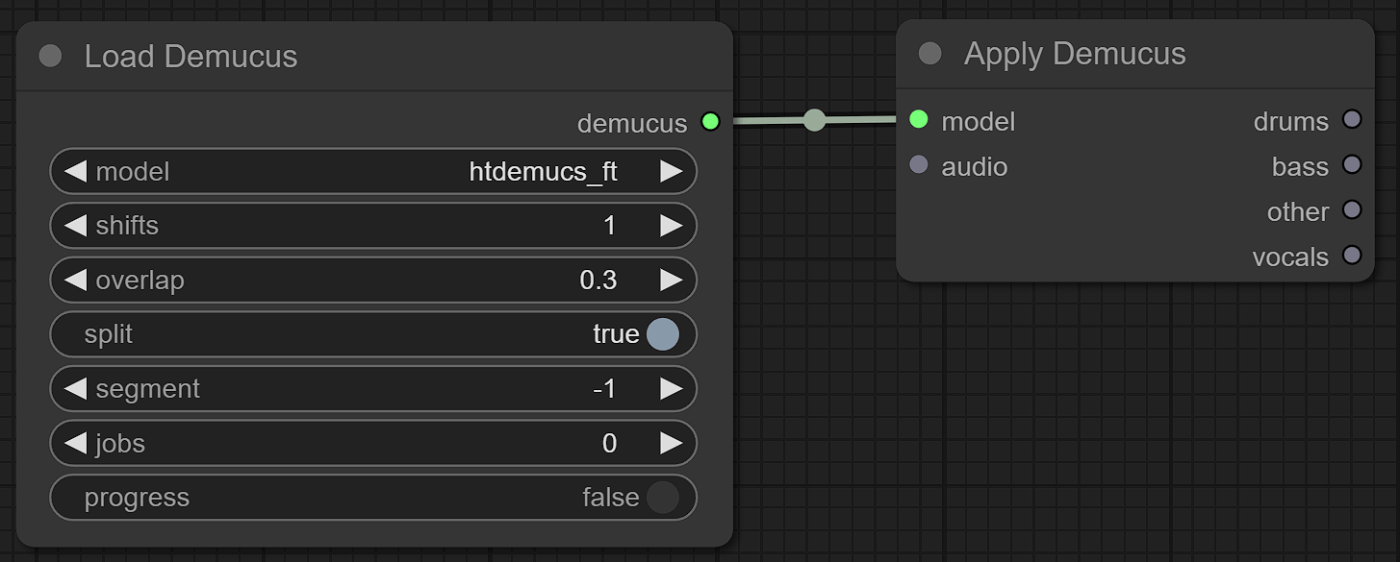
Demucsの例
音声の保存
音声保存用ノードもいくつか作りました。
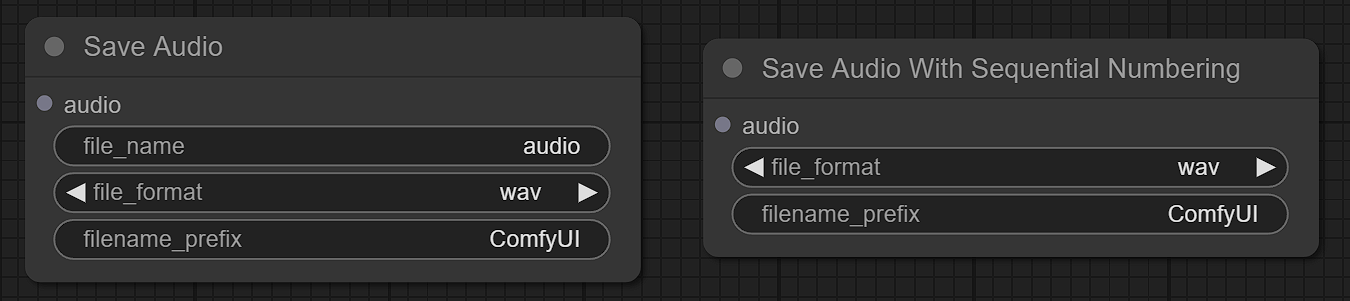
ComfyUI標準のノード「Save Image」は複数の画像保存が想定されています。これになぞらえて「Save Audio With Sequential Numbering」ノードを作成しました。名前の通り、ファイル名に連番がつきます。
とは別にここでは単一のファイル保存用ノードを「Save Audio」とし、ファイル名を指定できるようにしました。
audio_outputディレクトリを事前に作っておき、これに保存するようにします。また、torchaudioのサポートするフォーマットを指定できます。
文字起こしテキスト保存
シンプルなテキスト保存用ノードを作成しました。

苦戦ポイント:リスト or not
音声の読み込みでは2つのノードを作成しました。「Load Audios」ノードはデータを"リストで出力"します。ここでリスト出力とは、ノードクラスの属性OUTPUT_IS_LISTにおいてTrueの出力であることを意味します。ノードの出力ピンの見た目が格子状になっていることに気づかれたでしょうか。
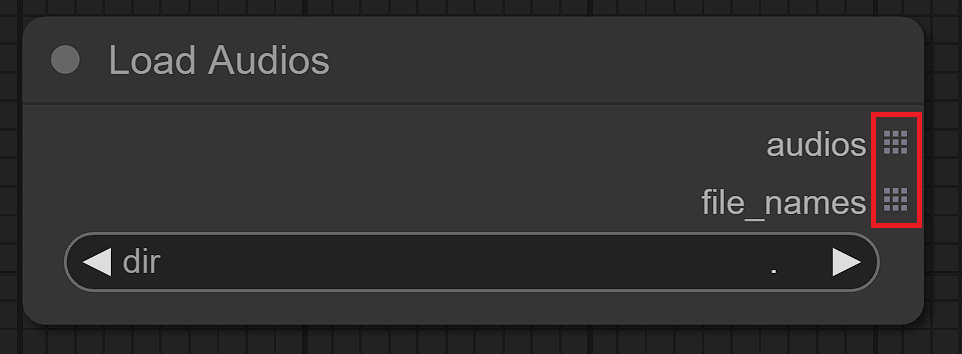
Load Audiosノードの出力ピンaudiosとfile_names
これによって実行時の挙動に変化が起こります。例えばfaster-whisperなどでは発話区間を示すセグメントが複数のデータとしてかえってきます。最終的には次のような設計になりました。
非リスト出力
まず、文字起こしテキスト全てを取得したい場合です。「Transcribe by faster-whisper」ノードはsegmentsを出力します。これはリスト出力ではありません。listオブジェクトという1つの集合体として扱われるイメージでしょうか。
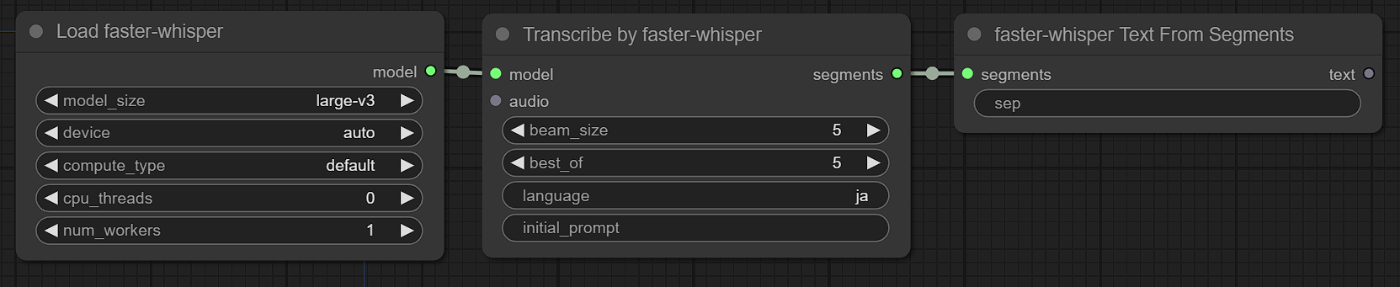
リスト出力
segmentsについてループ処理を行いたい場合、「faster-whisper List Segments」ノードを使います。後続のノードでループ処理によるトリミングを行うワークフローは以下です。
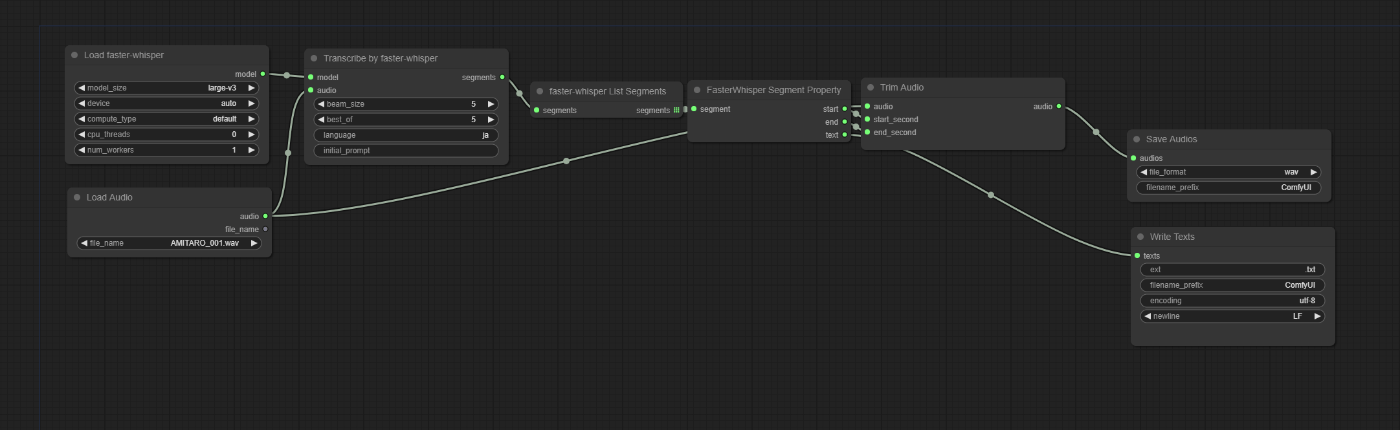
これがリスト出力です。ComfyUI Executorは以下の場所をセグメントの数分、ループ処理してくれます。

このように単一のデータとして出力し、後から必要に応じてデータをリストととして取り出せるようにしました。ループ処理が行われるブロックを可能な限り避け、意図しない動作を避けるねらいがあります。
はじめはlistのデータは即座にリストとして出力するように設計していました。しかし、リスト出力を多く含む複雑なワークフローになればなるほど、期待通りの結果を得るのは困難であることがわかりました。リスト出力は便利な側面がある一方、この複雑さを助長しかねません。
したがって、リストの入出力になるノードは限られた範囲での使用にととめるべきと言えそうです。また、リストの取り扱いを避けつつループ処理を実現するには、ワークフローを繰り返し実行するのも1つの方法です。例えば、「Primitive」ノードを使うことで実行するたびに、設定値をインクリメントすることができます。
終わりに
カスタムノードを作成し、それらを組み合わせることによって、音声データセット作成のワークフローができました。ノード次第で作業の幅が広がる点も魅力的です。同時にComfyUIのパワーも改めて感じました。実はノードベースのアプリケーション候補は他にもありました。しかし現時点ではどれも使い勝手は一長一短であり、ComfyUIに軍配が上がる印象でした。
以下がリポジトリへのリンクです。
テキストファイルの読み書き、文字列処理やパス操作のノードはそれぞれの機能に特化したリポジトリにまとめる方針にしました。
参考
ComfyUIのプラグインを作る!
Guide To Making Custom Nodes in ComfyUI
Comfy-Custom-Node-How-To
Discussion