Bert-VITS2(v2.2) ウォームアップ戦略と学習率による精度変化
概要
初投稿です。何卒よろしくお願いいたします。
Bert-VITS2は中国人の方が開発されているTTS(音声合成)のソフトです。
本家リポジトリは最近まで活発に開発が進み、モデルの構造なども変わっていきました。
本稿ではv2.2について実験を行った記録をまとめていきます。
知る人にとっては今更かつ中途半端なバージョンではありますが
まあまあなレベルまでまとめることができたので、記事に残させていただこうと思います。
ちなみにサブ目標としてCLIPの制御が可能になるか調査もありましたが
CLIPを活かすにはモデル構造がまだ発展途上である可能性や、
スタイルによる感情制御という代替手段の確立から立ち消えとなりました。
仮説
とある方により、Bert-VITS2 v2.1における学習率のウォームアップの有効性が示唆されました。
訓練にかかる時間が短縮されたv2.2ではこの戦略がより試しやすいと考えました。
(モデル構造に依存しないのでv2.1でも短縮される)
v2.2バージョンアップに伴いモデル構造が変化したため、訓練の設定で何を重視するかも変わったと予想されました。
(ユーザーが訓練したモデルでは、デモで示されたようなCLAPによる感情制御が効かないことからも
適切な訓練設定の発見が期待された)
方法
Bert-VITS2でTTSモデルを訓練し各ステップのモデルで生成した音声に対し、疑似的なMOSを測定します。
ウォームアップエポックと学習率を色々変えて測定しました。
疑似的なMOS測定
SpeechMOSによってMOSを測定します。本来のMOSの定義からすると、スコアは人間による主観に基づきます。
対して、SpeechMOSはAIによる客観的な評価になります。
そのためここでは疑似的という表現を使わせていただきます。
また、実際のMOSと相関があることがわかっています。(参考文献を参照)
SpeechMOS モデル : UTMOS strong
MOS測定の文章
100コのテキストで生成した音声の SpeechMOS 平均をとるようにしました。
以下のコーパスを使用しました。
jsut_ver1.1
voiceactress 100
生成時のCLAP Text promptは Neutral としました。
Bert-VITS2
バージョン : 2.2 (Tags/v2.2)
使用したコーパス : JVNV F1(女性話者)
訓練のスクリプト train_ms.pyは学習率に関する挙動を一部、修正しました。
- 事前学習モデルの保存した学習率ではなく
config.json train learning_rate の値を使用するように修正 - ウォームアップ新規追加
config.json train warmup_epochsで指定された期間内は
学習率が線形に増加するようにし
ウォームアップ後はExponentialLRと同様に減衰していくようにした - スケジューラのstepをステップごとに呼び出すように変更(エポックでない)
Tensorboardで確認できる学習率は以下のようになります。

以下はconfig.jsonから抜粋した設定です。
{
"train": {
"log_interval": 50,
"eval_interval": 250,
"seed": 42,
"epochs": (可変),
"learning_rate": (可変),
"batch_size": 4,
"warmup_epochs": (可変),
"c_mel": (可変),
"c_kl": 1.0,
},
結果・考察
実験1
3段階の学習率でウォームアップ期間の長さを変えて行いました。
訓練はMOSの最大値更新が見られなくなるエポック数で適宜、打ち切りました。
| 学習率 | エポック |
|---|---|
| 2e-4 | 100 |
| 2e-5 | 200 |
| 2e-6 | 300 |
ここではc_melは一律、30としました。
学習率2e-4
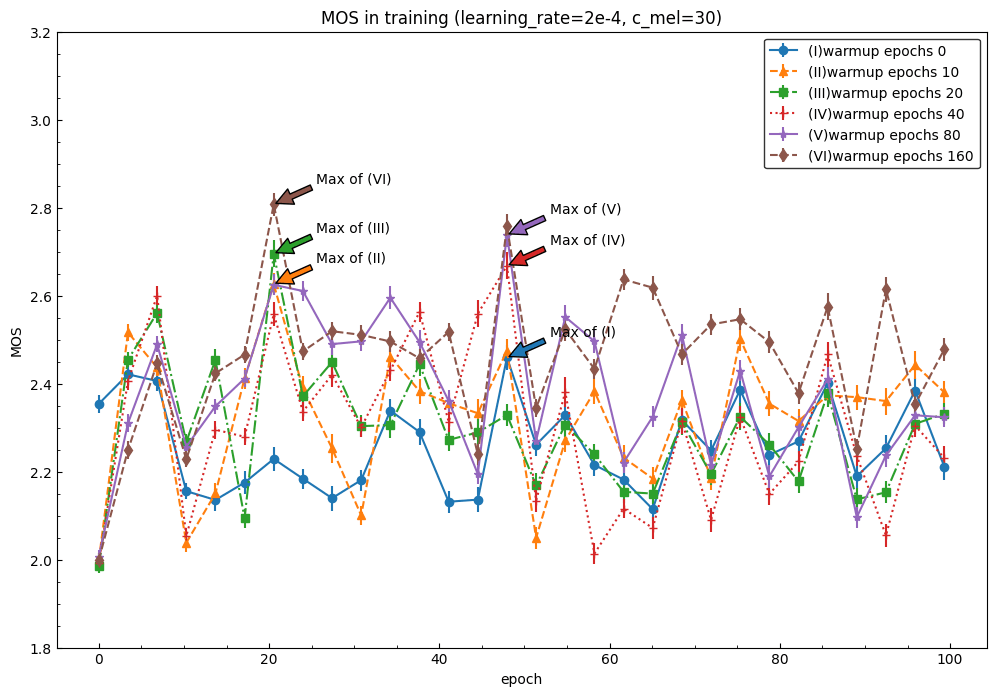

40, 80ではウォームアップ期間に最高値に達しています。
この学習率ではウォームアップが長すぎることになります。
デフォルトよりも学習率を下げることに一定の効果があると考えられます。
学習率2e-5

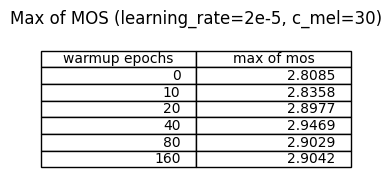
ウォームアップ戦略がない場合(warmup epoch 0)、
MOSが最大に達するエポックが遅く、その値もウォームアップありと比べて低いものとなりました。
これは訓練初期の不安定さに起因すると考えられます。
ウォームアップ戦略ありの中の比較では、40エポックが最も高いMOSを記録しました。
80, 160ではウォームアップ期間に最高値に達していますが、40エポックより低い値であることから期間が長すぎることになります。
この学習率ではウォームアップ戦略を導入することで品質を向上できる可能性が示唆されました。
2e-4 ~ 2e-5 の周辺に最適な学習率があるかもしれません。
学習率2e-6
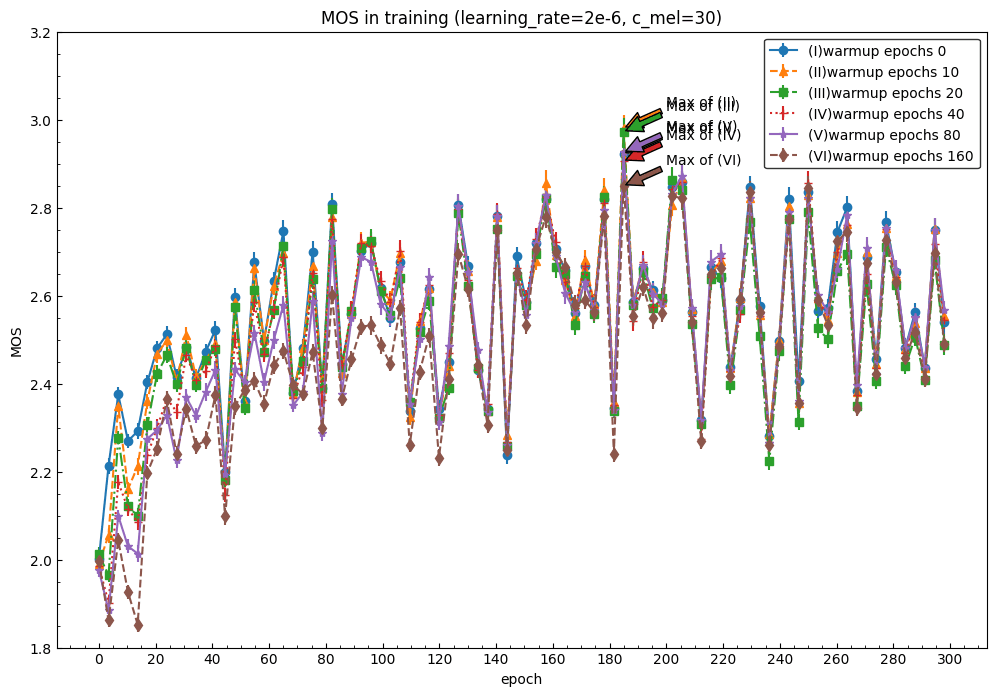

- ほとんど同じように推移していくこと
- MOSが最大値を記録するエポックが同じところに位置していること
- ウォームアップ期間とMOSの最大値には相関がないこと
などから、ここではウォームアップ戦略というよりも、低い学習率が訓練の流れを支配していると言えます。
実験2
実験1でウォームアップの効果がある学習率がわかってきました。
次にc_melを変化させて、MOSがどう変わるか確認しました。
学習率は、2e-4と2e-5の幾何的な平均にあたる6e-5で行いました。
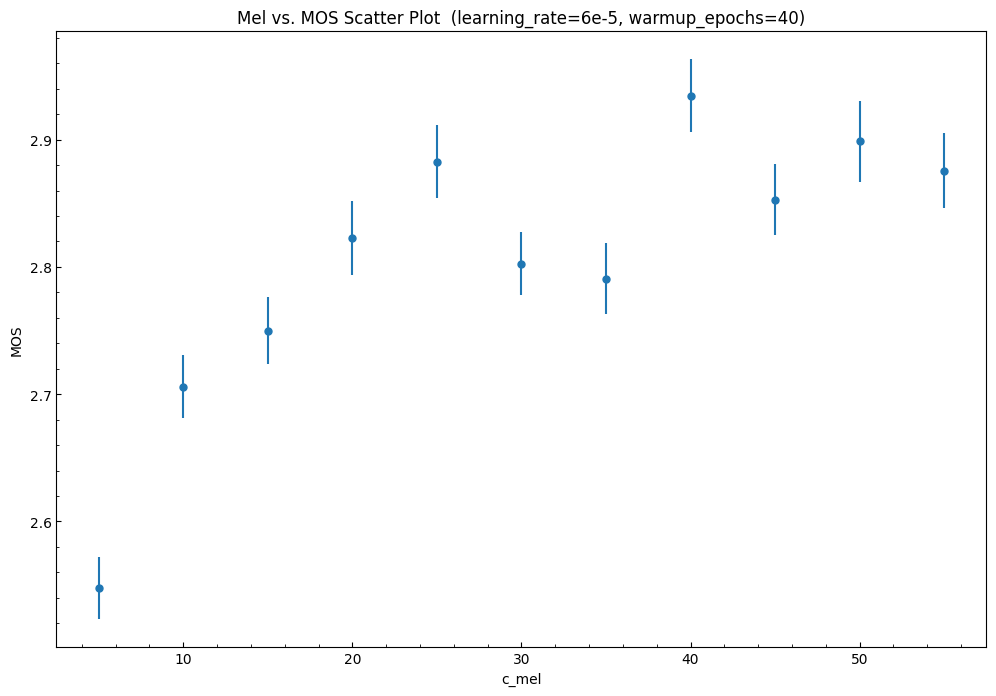
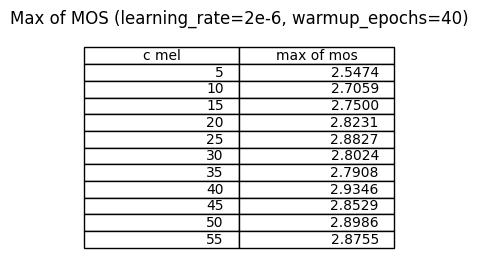
c_melは下げれば良いというものではなく、細かな調整が必要なようです。
結論
全体として、学習率を下げることは精度向上につながるものの、より多くのエポックが必要となることがわかります。
ウォームアップ戦略を活用することによって、ただ学習率を下げた場合にせまる品質のモデルを、より早期に得ることが期待できるのではないでしょうか。
今後の目標
- Style-Bert-VITS2ではどうか
- 複数話者を含む学習は、単一話者と比べてどうか
- 他のパラメータはどれだけ精度に影響するか
- 感情表現やイントネーションの自然さの定量評価は可能か
- 線形以外のルールでのウォームアップはどうか
参考文献
K. Seki, S. Takamichi, T. Saeki, and H. Saruwatari, “Text-to-speech synthesis from dark data with evaluation-in-the-loop data selection,” in Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Jun. 2023.
Discussion