💭
Cloud Spannerで条件を絞った上でソートするクエリのパフォーマンスチューニング Part2


はじめに
この記事はPart1の続きです。
今回は、前回の改良版のクエリについて書きます。
実験について
スキーマやデータは一緒なので、前回の実験についてを参照してください。
実験パターン
- UserTypeを5つ指定してCreatedAtで降順にソートし20件取得する
- 存在しないUserTypeを1つ含んで、UserTypeを2つ指定してCreatedAtで降順にソートし20件取得する
使用するクエリ
-
User10mByUserTypeCreatedAtを使ってUserTypeごとに取得し、UNIONするクエリ (UserByUserTypeCreatedAtでUserTypeごと & UNION DISTINCT)
SELECT u.* FROM ( (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByUserTypeCreatedAt} WHERE UserType = 0 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByUserTypeCreatedAt} WHERE UserType = 2 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByUserTypeCreatedAt} WHERE UserType = 4 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByUserTypeCreatedAt} WHERE UserType = 6 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByUserTypeCreatedAt} WHERE UserType = 8 ORDER BY CreatedAt DESC LIMIT 20) ORDER BY CreatedAt DESC LIMIT 20 ) t INNER JOIN User10m u ON u.ID = t.ID ORDER BY u.CreatedAt LIMIT 20 -
User10mByCreatedAtUserTypeを使ってUserTypeごとに取得し、UNIONするクエリ (UserByCreatedAtUserTypeでUserTypeごと & UNION DISTINCT)
SELECT u.* FROM( (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByCreatedAtUserType} WHERE UserType = 0 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByCreatedAtUserType} WHERE UserType = 2 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByCreatedAtUserType} WHERE UserType = 4 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByCreatedAtUserType} WHERE UserType = 6 ORDER BY CreatedAt DESC LIMIT 20) UNION DISTINCT (SELECT ID, CreatedAt FROM User10m@{FORCE_INDEX=User10mByCreatedAtUserType} WHERE UserType = 8 ORDER BY CreatedAt DESC LIMIT 20) ORDER BY CreatedAt DESC LIMIT 20 ) t INNER JOIN User10m u ON u.ID = t.ID ORDER BY u.CreatedAt LIMIT 20 -
(こちらはshinmetalさんに教えてもらいました) User10mByUserTypeCreatedAtを使ってUserTypeごとに取得するクエリ (UserByUserTypeCreatedAtでUserTypeごと)
SELECT c.* FROM UNNEST([0,2,4,6,8]) AS OneUserType, UNNEST(ARRAY( SELECT AS STRUCT * FROM User10m@{FORCE_INDEX=User10mByUserTypeCreatedAt} WHERE UserType = OneUserType ORDER BY CreatedAt DESC LIMIT 20 )) AS c ORDER BY c.CreatedAt DESC LIMIT 20
実験結果
UserTypeを5つ指定してCreatedAtで降順にソートし20件取得する
| クエリ種別 | 3回の平均CPU時間[ms] |
|---|---|
| UserByUserTypeCreatedAtでUserTypeごと & UNION DISTINCT | 27.51 |
| UserByCreatedAtUserTypeでUserTypeごと & UNION DISTINCT | 30.45 |
| UserByUserTypeCreatedAtでUserTypeごと | 50.20 |
存在しないUserTypeを1つ含んで、UserTypeを2つ指定してCreatedAtで降順にソートし20件取得する
| クエリ種別 | 3回の平均CPU時間[ms] |
|---|---|
| UserByUserTypeCreatedAtでUserTypeごと & UNION DISTINCT | 16.22 |
| UserByCreatedAtUserTypeでUserTypeごと & UNION DISTINCT | 4433.33 |
| UserByUserTypeCreatedAtでUserTypeごと | 17.39 |
結果と考察
考察1: 複数の値でフィルタリングするなら各々から取得した方がパフォーマンスが良い
結果: UserByUserTypeCreatedAtを使う方は、Part1の結果と比べても明らかにパフォーマンスが向上している。
考察2: 最終的に取得する数だけTable scanする方がパフォーマンスが良い
結果: 「UserByUserTypeCreatedAtでUserType毎 & UNION DISTINCT」と「UserByUserTypeCreatedAtでUserType毎」を比較すると、「UserByUserTypeCreatedAtでUserType毎 & UNION DISTINCT」の方がパフォーマンスが良い。
- 最終的に取得する20件分だけTable scanしているクエリの方がパフォーマンスが良い
-
UserByUserTypeCreatedAtでUserType毎 & UNION DISTINCTの実行計画の一部
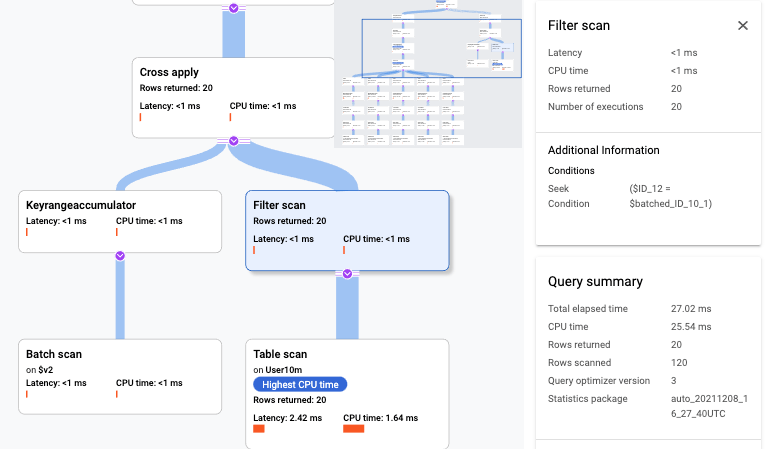
-
UserByUserTypeCreatedAtでUserType毎の実行計画の一部

-
おわりに
Part1とPart2の結果をまとめると
- 複数の値でフィルタリングする場合は、各々の値で取得してからソートし直した方がパフォーマンスが良い
- 最終的に取得する数だけTable scanする方がパフォーマンスが良い
Discussion