データ指向アプリケーションデザインを読んで
本を読んだきっかけ
原則24時間365日動かすアプリ開発、運用で痛い目を見たところから、本を読み始めた。
適当に書いておきたことを整理しつつ、思考を整理する。
下記覚えている限りの障害と対応。
・Lambdaを冪等に設計していないことにより重複処理が実行され、データが不整合な状態に
→直すのにアプリのコードを見て問題を別環境で再現させて検証して、直した結果をまたその環境で試してみたいな無駄な工程が発生。データ補正も大変だった。コードバグでLambdaを非同期でキックするべきところが同期でキックしていて、aws sdkの仕様によりレスポンスが戻ってこないと2分(確か)でリトライをかける処理で重複となった。
・MySQLをRDBMSとして使用していたが、トランザクション分離モデルにリピータブルリードを使用していてギャップロックで1つのバッチが他バッチに影響することがあった
→ロックをかけてるSQLの特定に時間がかかった。バッチが動いている時間から特定し下記を参考にSQLを特定した。Lambdaのメモリ使用量がギリギリになっていたり、Lambda処理が終了時にトランザクションのリリースをしてなかったのでそれら両方を直したら解決した。多分他に見直すべきは起動時間だったり、transactionの単位を小さくすることだったり、適切にインデックス(uniqueな)を貼るとか、トランザクション分離レベルの変更(その分スキューを妥協できるかを業務要件と付き合わせる必要はある)とかがあるのかなと思った。
・色んな対抗システムとデータの送受信を行うシステムだったが、送信元の注文の商品価格データが壊れていて、決済関連の集計処理で正しい値が出力されなくなった
→結局集計対象になっている期間のすべての注文データを調べて、購入された日時と価格表から正しい価格を算出してそのあたいに補正するSQLを組んで、補正するというような大規模な補正が行われた。送受信側どちらかでバリデーション、細かい単位でデータ監査の為の冗長なバッチ(日次とかで動かす)をするのが良いかと思った。
・パッケージ(すでにある既存のコード)をカスタマイズして開発をしていくPJであるが、夜間バッチで対象データに対してまとめて処理している部分を、「ファイル(CSV等の行単位のフォーマットに対象レコード格納)アップロードにより部分的に処理していく新規機能」の開発を行なっていたが、システムのデータ構造への理解が不足していて(更新時にイミュータブルにレコードを追加して履歴として持つのか、それともレコードを更新するのか)、データに不整合が起きた
→影響範囲(特にエンドユーザ)を調べたが影響について拾いきれず、後続の処理で想定外にエンドユーザに影響するインシデントが発生した。後続の処理のソースコードに改修を加え、不整合な状態でのデータも後続処理を止めないように対応。その後、データ補正の対応を行った。
・集計で使用する移行データの日時が十分に要件定義されておらず、軒並み決済関連の集計結果が壊れていた
→移行元DBのテーブルを稼働中DBにコピーして、誤っている日持と合っている日時を照合して(何かしら採番されていて参照できるキーがあるので)正しい日時に直すデータ補正の対応を行った。
・元々RDSのデータをParquetでS3に出力してAthenaで月次集計をしているバッチがあり、それをRDBMS Onlyで集計するようにリプレイスしたが、パフォーマンスが出ず、CREATE TABLE AS SELECT ~ という構文を使っていることもあり、他バッチが操作するテーブルをロックしたまま半日以上プロセスが残っていた。
→プロセスをkillしてロックについては暫定対応したが、集計結果についてはパフォーマンスの見直しをしたのち(バッチウィンドウは精々2h程度だったので)、再度集計する必要があった。中途半端に日時データを作成していたこともあって、データの導出結果についても分かりづらくメンテナンスし辛い状況であったので、最低限入力と出力について詳細に設計書に残すべきだったと反省している。※そもそも数百万レコードに対してUNIONをしたり、一時テーブルを何個も作成して無理くりクエリを書いていたのでデータシステムの選定から誤っていたと反省している(そもそもRDBMSでやるべきじゃない?)
他にも色々あったと思うが、個人的に大きなデータを扱う際の知識が乏しく上記の問題に対して開発・テスト段階で気づくことができなかったのが大きな反省点なので本書を読むことにした。
読んだ感想(ざっくり)
難しいと感じた。
聞いたことあるけどよくわからない言葉も含め、知らない言葉が多く出てきたし、今までチラ見してきたAWSのサービスについても内部構造を深掘りしてみたいと感じることができた。
タイトル通りだが、データを扱うということについて様々な角度から関連技術とその組み合わせ、トレードオフについて説明している。
信頼性、拡張性、保守性の3つを満たすようなシステムにするにはどうした良いかというのが目標(と思ってます)。
ワークロードごとにどのサービスを使うと良いかを時間をかけずに答えることはまだできない気がするので、そこはドキュメントや各社の使用実績(記事書いてくださってるところ)を追いながら見ていこうと思う。
括弧の中は本を読みながら本書の言葉と紐つくんじゃないかとイメージしてたもの。
※合意とか全順序ブロードキャストらへんの話は結構抽象的で複雑てよく分かってないのでもう一度どっかで読み直します
- DynamoDB(NoSQL、パーティション、Merkle Tree(ハッシュキー & Bツリーを合わせたもの))
- データ格納はMerkle Treeを使っていて、ハッシュキーとBツリーを合わせたような構造でデータを保持しているのではないか?と言われてる。公式がデータ格納形式についてドキュメント化してないのでなんともだが。
- https://medium.com/swlh/building-dynamodb-brick-by-brick-237e0008b698
- https://marcy.hatenablog.com/entry/2018/07/31/213705
- 公式ならこれ見ればわかる??
- Aurora(レプリケーション、合意、ACIDトランザクション(直列化、弱い分離性))
- Kinesis Date Streams(ストリーム処理、エンドツーエンドで書き込みの線形化、読み込みは結果整合性)
- Athena(分散データのバッチ処理イメージしてるけど合ってる?Apache Parquetを使えば列試行データウェアハウスみたいになるイメージ)
- EMR(分散データのバッチ処理でイメージしてる。Hadoop。)
- EKS(etcd、ノード間の合意、クオラム)
- S3(SSTable)
個人的なレベルは達人に学ぶDB〜〜を読んで、ユーザがほとんどいないような小さなアプリケーションの開発で下記のことを意識して開発するようなレベルであり、そんなにSQL、DBMSに対して自信がなかった。 一応業務でMySQLとPostgreを両方使っていたが、違いもよくわかっていなかった(今もよく分かってない)。
- DBMSのデータの持ち方は木構造である
- 下記についてインデックスはつけておいたほうがいい
- 外部キー
- レコードの参照で使用するカーディナリティが高いカラム
- ※条件に使うことで対象レコード数をグッと減らせるカラム
- レコードを一意に決定するカラム(複合)
- 使えるSQLクエリ
- 基本的なCRUD処理, INNER JOIN, LEFT JOIN, GROUP BY, ORDER BYしか知らない
- 恥ずかしながら、UNION は知らなかった(聞いたことはあったかも)
- 正規化、非正規化のメリット・デメリットはちょっと分かる
- 非正規化するとREAD、INSERTするときはパフォーマンスが良いけど、UPDATEする時に更新箇所が複数になる可能性があるイメージ
- ※非正規化するならDBとして持つのではなく、何らかの導出関数を使ってマテリアライズドビューを作るイメージ
- all or nothingにしたいならトランザクションで囲む(nodejsだと下記の様な雰囲気)
- releaseが必要だったのはpoolからconnectionをとってきてる時だけだったかな?忘れた
const conn = Aurora.connect()
conn.beginTransaction()
try {
~~ 何らかのビジネスロジック
conn.commit()
} catch {
~~ エラーログを出力
conn.rollback()
} finally {
conn.release()
}
NoSQLについてはDynamoDBを使ったことがあるが、テーブル設計が難しく(変更が後から効かない)、書き込みスループットがオンデマンドでいじれる、パーティションで分けて負荷分散するんだなあくらいしかわからなかった。
耐障害性の仕組みとか、トランザクションの仕組み、トランザクション分離モデルとトレードオフについては分かってなかった。
exactly-onceとか決定的かとか冪等性(冪等じゃない処理を冪等にするにはエンドツーエンドでリクエストIDを使う)とか、
リトライをすべきエラーとそうでないエラーで分けるとかは自分の頭の中で考慮できてなかった。
データが破損していると気づくための監査の考え方、データをイベント(履歴)で持ちながら決定的な導出関数があればリトライや監査が容易であることも勉強になった。
2,3ヶ月くらいかけて1周読み切ったのでもう一周しながらちょこちょこ気になったところをメモしていく。
1章:信頼性、スケーラビリティ、メンテナンス性に優れたアプリケーション
上記の語句は下記の様な意味。
- 信頼性:
- ハードウェアやソフトウェアの障害、ヒューマンエラーへの耐性
- →システムは上記の問題が発生しても正しく動き続けるべき
- ハードウェアやソフトウェアの障害、ヒューマンエラーへの耐性
- スケーラビリティ:
- 負荷とパフォーマンスの計測、レイテンシのパーセンタイル、スループット
- →システムの成長に対して無理のない方法でスケールすべき
- 負荷とパフォーマンスの計測、レイテンシのパーセンタイル、スループット
- メンテナンス性:
- 運用性、単純性、進化への対応
- →運用、保守者が生産的に活動できるべき
- 運用性、単純性、進化への対応
信頼性
何か問題を起こしても正しく動き続ける。
問題を起こすもの = フォールト
そういったものに対して耐障害性を持つ = フォールトトレラント
フォールト ≠ 障害
障害 = システムが全体として必要なサービスのユーザへの提供を止めてしまった
フォールトが障害にならない様にする。
意識的にフォールトを発生させるテスト手法はChaos Monkey。
netflixで使われてた。
↓こっちはイベントだけどaws gamedayでも似た様なことやっていた。
ハードウェア障害
データセンタでハードウェア障害は付き物。
ハードウェアを冗長化させることで対応していた。
最近、データの量や求められるアプリの処理量が増えていくに連れて、ハードウェアのフォールトも増えた。
awsの様なサービスは単一のマシンが信頼性を持つよりは、柔軟性やエラスティックさを持つように設計されている。
※エラスティック:需要の大小などに応じ、ITリソースなどがその必要なサイズや範囲で提供・利用できる性質のこと
そのため、ハードウェアの冗長化だけではなく、ソフトウェアによる耐障害性の手法を使う。
単一マシンでは再起動する場合はダウンタイムが発生するが、
複数マシンでマシンの障害に耐えられるシステムは、ローリングアップデートが可能。
※ローリングアップデート:1回に1つのノードずつパッチを当ててアップデートをしていくので、ダウンタイムが生じない
ソフトウェア障害
ハードウェア障害はノード間に相関性がそこまでないことが多い。
ソフトウェア障害はシステマチックで、サービス間に関連性があることが多い。
- ソフトウェアのバグ。問題のある特定の入力が与えられるとサーバのインスタンスがクラッシュする(閏秒の件など)。
- プロセスの暴走
- カスケード障害。1つのシステムコンポーネントの障害が原因で他のシステムコンポーネントに影響を与えて連鎖していく障害。
- 下記のリンクが参考になる。
- マイクロサービス間だとリトライやタイムアウトの制御をすることや、そもそもリクエストをしないようにネットワーク間にサーキットブレーカーを入れることが考えられます(上の記事のまま)
手っ取り早い解決策はなく、下記の様な対応が必要。
- システムの前提や、動作の入念なチェック
- 徹底したテスト
- プロセスの分離
- プロセスクラッシュと再起動の許容
- 計測やモニタリング
- システムの挙動分析
ヒューマンエラー
人間は信頼できない。
サービス障害が発生するフォールトの中で最もオペレータによる設定ミスが多い。
- エラーの可能性を最小限に。インターフェースを適度に厳しく。
- 本番環境と同等のサンドボックス環境で実体験
- (感想) これやりたいけど、個人情報のマスクをしないとだよなと思ったりした。
- UT、ITa、ITb、システムテスト、ユーザ受け入れテストまでちゃんとやる。。。
- リカバリ(ロールバック)を正しいタイミングで実施できる様にする
- 即座に実施するのか、段階的に実施するのか(ソースコードだと段階的が良い?)
- パフォーマンスメトリクスやエラーの発生率などをモニタリングする仕組み
- 障害発生時のトレーニング?
スケーラビリティ
ある側面から負荷が増大しても、システムが対応できる能力のことを指して使われることが多い。
負荷の表現
負荷は負荷のパラメータと呼ばれる。
システムのアーキテクチャに依存する。
サーバならリクエスト数/秒、DBなら読み書きの比率、チャットルームならアクティブユーザ数、キャッシュならヒット率。
Twitterの例
ツイートのポスト:平均4600リクエスト/秒、最大12000リクエスト/秒
ホームタイムライン:300000リクエスト/秒
で、
- ユーザ→ツイート→フォロワー(=クライアントのユーザID)のように結合してクライアントごとにツイートをDBから投稿取得する(ツイートは時間順にソート)
- ユーザがツイートするたびに、フォロワーのタイムライン上(クライアントのメールボックスの様なもの)に投稿をPushする(ツイートは時間順にソート)
負荷のパラメータを見る限り、書き込み(ポスト)よりも読み込み(タイムライン)の方が負荷が高いので2のパターンを採用した。
ユーザによっては大量のフォロワーを持っているため、後述の章で説明されるが、2で対応しきれないため1で取得したデータをタイムラインにマージするハイブリッドな手法を取る。
パフォーマンスの表現
負荷が表現できたら、システムのパフォーマンスの表現を知ってスケーラビリティの評価ができる様にしたい。
バッチなら、通常スループットに注目。
スループットは1秒あたりに処理できるレコード数、ある量のデータセットに対して要する時間などを意味する。
オンラインシステムの場合は、通常レスポンスタイムに注目。
クライアントがリクエストしてからレスポンスを受け取るまでの時間を意味。
※レイテンシ ≠ レスポンスタイム
レイテンシは、リクエストが処理を待っている期間であり、リクエストはこの期間待ち状態にありサービスを待っています。
よくわからなかったので、下記を参考にすると
レイテンシは、client(request) -> server(process) -> client(response) の内、server(process)は除いたネットワークの部分のみということでしょうか?
レスポンスタイムでいうと、外れ値(極端に大きな遅延)がところどころに見られる。
ガベージコレクションによる一時停止とかTCPの再送とか様々な状況で見られるらしい。
レスポンスタイムは平均値ではなくて、パーセンタイルで見るのが良く95, 99, 99.5あたりがよく使われるらしい。中央値に近い概念で50パーセンタイル = 中央値。
↓非機能要件の「性能目標値:オンラインレスポンス」でも順守率というところで恐らく満たすべきパーセンタイルを聞かれている。
大きなパーセンタイルのレスポンスタイムはテイルレイテンシと呼ばれる。
テイルレイテンシは例えば複数のサービスコンポーネントにリクエストを行うバックエンドサービスにおいて、障害を起こす要因となる。
パーセンタイルはSLOやSLAに使われる。
↓SLOとSLAの違いについては下記が参考になる?
SLAは契約で、SLOは目標だからSLAの方が条件自体は緩いが、責任が重たいイメージ。
レスポンスタイムにおいて、95パーセンタイルは200ms以下で、99パーセンタイルは1s以下みたいな使われ方をする。
サーバの同時処理数が少ないことにより、低速なリクエストがあると移行の処理が待たされる
ヘッドオブラインブロッキングという現象がある。
そのためレスポンスタイムはクライアント側で計測すべき。
負荷への対処
主に2つの方法が考えられる。
- スケールアップ(単一マシンを強力に
- スケールアウト(汎用的なマシンに分散させる
複数マシンに分散させるアーキテクチャはシェアードナッシングとも呼ばれる。
スケールアップかスケールアウトかどちらが良いとかはなく、ワークロードによりけりで、複合的に使用することでコストを下げてスケーラビリティが高められることもある。
ステートレスなシステムは分散した複数マシンで管理するのが楽だが、ステートフルなシステムは難しい。
→これは本の中で多くの紙面を使って書かれることになる。
システムの中にはエラスティックなものもあり(EC2 Auto Scalingとか)、負荷に応じて自動でリソース追加を行うことも可能。
負荷の予測が難しい時は役に立つが、手動の方がわかりやすく運用時に想定外のことが起こりづらい。
※エラスティック:需要の大小などに応じ、ITリソースなどがその必要なサイズや範囲で提供・利用できる性質のこと(https://www.hulft.com/column/glossary-20#:~:text=エラスティック(Elastic)とは,訳すことができます。)
結局アプリの負荷のパラメータによりけりで、どういった処理が頻繁に行われるか?によってスケールさせる方法は変わる。
スループットは同じでも、少量のデータを多くのリクエスト数実行するのか、1回のリクエストで多量のデータを処理するのかによってもまた変わってくる。
メンテナンス性
---- ここ感想 ----
自分が作ってきたものでも、実際に目にしたものでも下記の様なものはあったので、PJの予算とスケジュールはあるけれど、やっぱりここは大事にしたい。
- スパゲッティコードで内部の処理の見通しが悪い
- ライブラリのバージョンが低くなっていて環境をバージョンアップして後方互換性が担保されるか心配
- (私が関わった案件だとnodejsをバージョンアップした結果動かなくなったライブラリがあったことがありました)
- 各サービスの挙動が謎
- 有識者が社内にほとんど居ない
- 設計書は残っているが設計案(どうしてその設計にしたのか)が残ってないので、他サービスとの関連もそうだが、非機能的な考慮がわからない
- データ更新系の処理はどこから実行されるかわからず怖い
- どのエンティティがイミュータブルで、何がミュータブルかはわかった方が良いなと思った
- サービス間が密結合で、副作用が怖い(リトライ時とか
- 自分だけで手元で好き勝手に動作を確認できる環境がなく、追加機能が開発しずらい
---- ここ感想 ----
本書で訴えている3原則は下記。
- 運用性
- 運用チームが扱いやすい
- 単純性
- システムが理解しやすい
- 進化性
- システムの変更しやすさ
- 拡張性、修正の容易性、プラスティシティとも言われる
運用性
本書では、運用チームが負う責任について他にも紹介しているが、気になる部分を抜粋。
- システムのモニタリング(パフォーマンスや障害について)して検知する
- →障害の種類について事前に想定できるなら、種類ごとに誰に通知するのか(専門分野的な)を決めてチャネルを変えるなりしたいと思った
- システムのモニタリング(パフォーマンスや障害について)して原因分析、復旧させる
- →複数サービスがある場合は各サービスで占有しているリソースやサービス間の通信をモニタリングしたいと思った(誰が誰を呼んでいて、その結果はどうであったか)
- →イミュータブルな形でイベントログを残していたら復旧が容易であったかもしれない
- →復旧手順については事前に認識を合わせておく、なんなら復旧トレーニングもやりたい
- →ダウンタイムがあるなら事前にclientと合意をとっておく
- ソフトウェアやプラットフォームを最新に保つ
- →プラットフォームは、クラウドを使うならできるだけフルマネージドなサービスにしておく(それでもダウンタイムがあったり物によっては手動で適用したりしないといけないものはあるので事前に確認しておく)
- →ブランチ戦略によるが、ソースコードはGithub等のレポジトリ管理ツールの特定のブランチ(テスト済みであり最新であると関係者で何らかのプロトコルで合意が取れている)からデプロイできる様にしておく
- →言語やその環境のバージョンアップは定期的に行い、同等のバージョンを持つ環境でテストできる様にしておく
- 将来の問題に予想して事前に解決する(キャパシティプランニング)
- →データの破損を事前にチェックするような機能を入れるとか
- →そのためにはイミュータブルなデータの持ち方をしないといけない
- →せめて怪しそうな場所にはバリデーション処理を入れる
- →データの破損を事前にチェックするような機能を入れるとか
- 運用で予想外のことが起こらない様にプロセスを定義して、プロダクション環境の安定を保つ
- →リトライ時のパラメータ(例えば時間のオフセット)だけでなく、他サービスへの影響を考えて、いつリトライするか?も大事
- →本番同等のデータを持つ環境で検証できるとありがたいなと思った(個人情報のマスクは必要だけど)
- 優れたドキュメンテーションと理解しやすい運用モデル(Xを実行するとYが生じる)
- →入力と出力が明確で、exactly onceである処理
- →イミュータブルであるのが望ましい
- →誰にリトライさせるかも考える(クライアントからAPI叩くならユーザにリトライさせる)
単純性
システムを単純にすると、実装から乗じる偶発的な複雑さを除去できる。
偶発的な複雑さを取り除くための優れた手段は、抽象化。
内部実装の複雑さを隠蔽して、再利用できる様にすること。
例)SQL、高レベルなプログラミング言語
進化性
ビジネスの優先度やユースケースは変わり、システムへの要求は変わっていく。
アジャイルな仕事は変化に対応する上で有用なフレームワークだが、扱うシステムの部分は限定的なもの(全体の中の一部のソースコード)。
データシステムは巨大で、そのシステムに対してアジリティを高めるのが目標。
本書では、進化性はデータシステムのレベルでのアジリティを指す。
進化性は単純性や優れた抽象化に依存する。
データモデルとクエリ言語
アプリケーションをデータモデルのレイヤーを積みかねることで構築される。
レイヤーの主題はその下位層のレイヤーでどのように表現されているか?である。
・アプリ開発者は現実のビジネスに関連するモデル(デバイス、人、etc)をオブジェクトやデータ構造として定義してAPI等で取り出せる様にする
・データ構造をJSONやXML、リレーショナルモデルのテーブル等で保存する
・我々が使ってるデータベースを作ったエンジニアは上記のデータ構造をディスク上に保存するバイト列に変換する表現を作っている。こうして我々がデータ操作を行える
・もっと低いレベルではハードウェアレベルでバイト列をどう変換、表現するかがある
データモデルを提供することで下位の複雑さを隠蔽してる。
アプリケーションに適したデータモデルを選択しよう。
リレーショナルモデル
最も有名なデータモデル。
データはリレーションと呼ばれ(SQLではテーブル)、リレーションはタプル(行)の集合である。
リレーショナルモデルについては、筑波大学に公開していただいている講義動画があるのでそれも参考になる。
※アカデミックな内容なので集合論が若干出てくるので、そこは結構眠くなるが頑張る。
下記のような構造でデータを持つ。
起源は、ビジネスデータの処理にある。
・トランザクション処理(ネットショッピングや銀行取引など)
・バッチ処理(請求処理、レポーティング)
などは昔からある。
リレーショナルモデルが目標としていたのは、クリーンなインターフェースで内部実装の複雑さを隠蔽すること。アプリケーション実装者がデータを扱うことについて考えることを減らす。
ネットワークモデルや階層モデルも出てきたが、長く続かずリレーショナルモデルがメインを占めていた。
クエリオプティマイザという仕組みが最も効率的なデータへのパスを見つけて実行してくれるため、ユーザはそのパスに対して気にする必要がない。
インデックスさえ張っておけば勝手に使って探索してくれる。
反対にネットワークモデル(CODASYLモデル)はレコード間のリンクをプログラミング言語におけるポインタの様なもので参照していたので、欲しいレコードまで辿り着くためにリンクリストの様に頭から辿っていく必要があった。
NoSQL
2010年台から出てきたバズワードらしい。
今ではNot Only SQLと解釈される。
NoSQLでもDynamodbのようにマルチオブジェクトトランザクションをサポートしたりするものも出てきてる。勿論RDBMSとトランザクションの実装方法は全然違うが。
違いは下記の様なもの。ドキュメントモデルでは水平方向にスケールしてリクエストが増大してもパーティションごとに振り分けられるので、負荷分散できるイメージ。
SQL データベースはリレーショナルであり、NoSQL データベースは非リレーショナルである。
SQL データベースは SQL(構造化問い合わせ言語)を使用し、あらかじめ定められたスキーマがあるが、NoSQLデータベースには非構造化データ用の動的スキーマがある。
SQL データベースは垂直方向に拡張可能だが、NoSQL データベースは水平方向に拡張可能である。
SQL データベースはテーブルベースだが、NoSQL データベースはドキュメント、キーバリュー、グラフ、ワイドカラムストア型である。
SQL データベースは複数行のトランザクションに適しているが、NoSQL はドキュメントや JSON のような非構造化データに適している。
https://www.integrate.io/jp/blog/the-sql-vs-nosql-difference-ja/
採用される様になった理由は、例えば下記がある。
・巨大なデータセットや優れた書き込みスループット
・商用DBよりもOSSの方が良い(内部実装わかるし、ベンダーロックイン防げる)
・RDBMSの制約がきつい
本書ではNoSQLの中にドキュメントモデルだけでなく、グラフモデルも入っていた。
ドキュメントモデル
ドキュメントモデルはNoSQLの一種。
データはコレクションと呼ばれ、コレクションはドキュメントの集合である。
※少なくともMongoDBはそうでした。それ以外は別の呼び方かも。。
MongoDB stores data records as documents (specifically BSON documents) which are gathered together in collections. A database stores one or more collections of documents.
ドキュメントという形で、必要な情報は1箇所にまとまっているので一度のクエリで取り出せる。
RDBMSだと複数テーブルJOINしたりとめんどくさい。
必要な情報は1箇所にまとまっている = ローカリティ
と言う。
インピーダンスミスマッチ
リレーショナルモデルだと、アプリケーションが欲しいデータ構造(オブジェクト)とDBが返せるデータ構造(テーブル、行、列)が異なるのでそこの変換レイヤーが必要になる。
インピーダンスミスマッチと言われる。
RailsのActiveRecordとかはORMを使って変換レイヤーを担ったが、アプリ層からSQLを実行しなくてもアプリが欲しい状態でデータを取得できたが、完全にはその差異を隠蔽できない。
フレームワークごとに方言があり、中々覚えるのが大変。
多対一、多対多について
IDにはユーザが変更しうる文字列ではなく、ユーザの操作とは関係のない何らかの採番値を使う。
更新が起きる際に1箇所だけ変更したいから。
こうした複製を排除する考えは正規化の礎になってる。
ドキュメントモデルにおいて、1対多はサポートされていることが多くの場合結合を必要としないが、
多対一、多対多については結合を必要とする。
リレーショナルモデルでは外部キーを持つことで結合するが、ドキュメントモデルでもドキュメント参照を持って結合する必要がある。
リレーショナルモデルとドキュメントモデルの違いとか使いどき
リレーショナルモデルの使いどき
リレーショナルモデルはデータを細分化(ユーザ、組織、職...etc)するアプローチなので、アプリのコードが複雑になりがち。
スキーマオンライトで書き込み時にスキーマがチェックされるため、書き込まれたデータはスキーマに沿っていることが保証される。
スキーマ変更時はALTER TABLE ~~のようなクエリを実行する。通常早く終わるがMySQLは時間がかかるって書いてあるが、公式見るとアルゴリズム変えれば(INSTANT?)早くなりそう。
ただロック取らないから安全なのかは不明。
ALTER TABLE 操作は、次のいずれかのアルゴリズムを使用して処理されます:
COPY: 操作は元のテーブルのコピーに対して実行され、テーブルデータは元のテーブルから新しいテーブルの行ごとにコピーされます。 同時 DML は許可されません。
INPLACE: 操作ではテーブルデータのコピーは回避されますが、テーブルが適切に再構築される可能性があります。 操作の準備フェーズおよび実行フェーズでは、テーブルに対する排他的メタデータロックが短時間で取得される場合があります。 通常、同時 DML はサポートされています。
INSTANT: 操作では、データディクショナリ内のメタデータのみが変更されます。 準備および実行中にテーブルに対する排他的メタデータロックは行われず、テーブルデータは影響を受けず、操作が即時に行われます。 同時 DML が許可されます。 (MySQL 8.0.12 で導入)
UPDATE文にについては大規模なテーブルに対して実行すると時間がかかるから、アプリのソースコードを変えて読み取り時に値を更新する様に書き換える処理を追加したりするのも1つの手(最初のALTER時はNULLで登録しておく)。
ドキュメントモデルの使いどき
対して、ドキュメントモデルは単一のクエリで欲しいデータを取得できるものの、多対多のリレーションを持つエンティティがあると有用でなくなる。
またドキュメント参照をしている箇所は、別途指定して取得する必要がある。
ネストが深すぎたりしてこういった処理が頻繁に実行されるのであれば、使用を控えた方が良いかも。
スキーマオンリードで、アプリケーションが読み取る際にスキーマは解釈される。
スキーマ(というよりレコードの値)を変更するには、アプリのソースコードを変えて読み取り時に値を更新する様に書き換える処理を追加したりする。
あとは下記の様な場合に使用するのが良いかも。
・スキーマが外部システムによって決定されて制御不可能
→ただRDBMSでもJSON型はサポートされてたりするので上記の条件だけなのであれば別にそれを使うでも良い
・一度に取得したい関連エンティティが多すぎる
・ローカリティを活用して高速なデータの書き込み、読み込みをしたい ※大量データがあってとか
比較
どっちを使うかみたいな話になりそうだが、両方組み合わせるという選択肢もユースケースによってはできるはず。
どっちかを読み書きで使って、OLAPは何らかの手段でレプリケーションした先で行うとか。
この複数モデルの永続化をポリグロットパーシステンスというらしい。
ちなみにレコード間の関連性が強い場合は、グラフモデルが有用らしい。
グラフモデルについては後で整理する。
・データが多対多であるか?
→yesならリレーショナルモデルに一票
・データの読み込み、書き込みが局所的か?
→yesならドキュメントモデルに一票。とはいえリレーショナルモデルにも関連データをグループ化する考えはある(SpannerとかOracleとか)
・一度に取り出したいデータのエンティティが多いか?
→yesならドキュメントモデルに一票
→エンティティが多くても結合回数が多いならリレーショナルモデルの方が良い?
・レコード中の値が外部システムから指定され、制御不可能である
→yesならドキュメントモデルに一票?(JSON型で良いならRDBMSでもサポートあり)
・OLTPしか使わない?
→yesならドキュメントモデルに一票。OLAPも使うならリレーショナルモデルの方が良い?
・複数行のトランザクション(データ整合性のためのロック)を使用する?
→yesならリレーショナルモデルの方が良い?ただ最近だとNoSQLでもマルチオブジェクトのトランザクションをサポートしてるものもがあるので、トレードオフを理解した上で使うのもありかなと思った。
| データモデル | 多対多/多対一のサポート | スキーマの柔軟性 | 結合の柔軟性 |
|---|---|---|---|
| リレーショナルモデル | O | X | △ |
| ドキュメントモデル | △ | O | O |
グラフモデル
グラフは頂点と辺を用いてレコードを表現する。
ソーシャルグラフやWebグラフで使う。
ソーシャルグラフなら、頂点が人で辺が関係性を表す。
一部のエンティティだけでなく、多くのエンティティやメインのエンティティに対して多対多の考え方が強い場合はグラフモデルを使うのが自然になる。
線がクロスしてわかりづらいが、下記の様になる。
※mermaidでグラフモデルを書く良い方法が見つからなかったのでclass図でかいた。
グラフモデルについては、下記の2種類がある。
- プロパティグラフモデル
- Neo4j, Titan, InfiteGraph
- トリプルストアモデル
- Datomic, AllgeroGraph
これらのモデルを操作する宣言的なクエリ言語についても見ていく。
宣言的なクエリ言語について
プログラミング言語やネットワークモデル(CODASYL)のクエリ言語は命令的。
SQLクエリは宣言的。
SELECT name FROM users WHERE user_id = 102;
命令的はデータ操作をする順序も指定するが、宣言的はデータの操作を指定せずにどういった結果が欲しいかを記述する(勿論そこに必要な条件などは記載する)。
宣言的な言語は命令型のAPIに比べて扱いやすい。
DBでは複雑な内部実装を隠蔽することができる。
他のWEB技術だと、CCSやReact, Vue.jsなども宣言的な表現をする。
・CCSで特定のクラスを持つelementのスタイルを変える
・elementに囲まれたテキストの内容を変更する
をPureなJavascriptで同じ処理をやろうとすると処理は長くなるし、条件を満たす全てのイベントで発火するように組まないといけない。保守は面倒で挙動もわかりづらい。
また、宣言的な言語は並列処理にも向いている。処理の順序を決めないから呼び出し側ではなく、呼び出された側で制御して並列処理をすることができる。
プロパティグラフモデルとCypher
特徴
プロパティグラフモデルの頂点、辺はそれぞれ下記から構成される。
- 頂点
- ユニークな識別子
- 外向きの辺の集合
- 内向きの辺の集合
- プロパティの集合(key,value)
- 辺
- ユニークな識別子
- 始点(頂点)
- 終点(頂点)
- 頂点間のラベル
- プロパティの集合(key,value)
Cypher
Cypherはプロパティグラフ用のクエリ言語の1つ。
テーブルスキーマは下記の様に定義できる。
charlieとかがユニークな識別子で、{name: 'Charlie Sheen'}はプロパティの集合、
[:ACTED_IN {role: 'Bud Fox'}]が関連性で、
-[:関連性]->で始点→終点の向きを示してる。
CREATE
(charlie:Person {name: 'Charlie Sheen'}),
(martin:Person {name: 'Martin Sheen'}),
(michael:Person {name: 'Michael Douglas'}),
(oliver:Person {name: 'Oliver Stone'}),
(rob:Person {name: 'Rob Reiner'}),
(wallStreet:Movie {title: 'Wall Street'}),
(charlie)-[:ACTED_IN {role: 'Bud Fox'}]->(wallStreet),
(martin)-[:ACTED_IN {role: 'Carl Fox'}]->(wallStreet),
(michael)-[:ACTED_IN {role: 'Gordon Gekko'}]->(wallStreet),
(oliver)-[:DIRECTED]->(wallStreet),
(thePresident:Movie {title: 'The American President'}),
(martin)-[:ACTED_IN {role: 'A.J. MacInerney'}]->(thePresident),
(michael)-[:ACTED_IN {role: 'President Andrew Shepherd'}]->(thePresident),
(rob)-[:DIRECTED]->(thePresident),
(martin)-[:FATHER_OF]->(charlie)
下記のように指定してレコードを取得できる。
wallstreet に ACTED_IN している actor の role を探すクエリ。
MATCH (wallstreet {title: 'Wall Street'})<-[r:ACTED_IN]-(actor)
RETURN r.role
他にも-[:関連性]->()を使うと関連性を満たす任意の頂点を()で表現できるし、
[:関連性*0..]って書くと関連性を0回以上繰り返すことができる。
指定回数も可能。
宣言的にかけるので、効率的なパスはクエリオプティマイザが勝手にやってくれる。便利。
ちなみにリレーショナルモデルのクエリで書こうとすると結合(グラフモデル)が何回行われるかわからないので、RECURSIVEを使って再起的に書いて取得する。
↓MySQL8時点でRECURSIVEを使って再起的な処理を階層構造を持つデータに対して検索する実装方法を書いていただいた資料もあるので併せて読む。
トリプルストアモデルとSPARQL
特徴
トリプルストアはプロパティグラフモデルと同じ概念を異なる言葉を使用して表現している。
↓言葉の対応表(英語のSVOC的な)
| データモデル | S | V(C) | O |
|---|---|---|---|
| プロパティグラフ | 頂点(始点) | 辺 | 頂点(終点) |
| トリプルストア | 主語 | 述語 | 目的語 |
レコードはこの(主語, 述語, 目的語)の形で保存され、トリプルと呼ばれる。
本書の言うとおり調べるとセマンティックWEBに関するRDFの記事ばかり出てきて、よくわからなかったが
Notation3(N3)とのサブセットであるTurtleというフォーマットを使ってトリプルで書くと下記の様になる。
@prefix : <url:example> .
_:alice a :Person .
_:alice :name "Lucy" .
_:alice :knows _:bob .
_:bob a :Person .
_:bob :name "Bob" .
_:bob :knows _:alice .
セミコロンを使えば同じ主語に対して複数の述語を使うことができる。
@prefix : <url:example> .
_:alice a :Person; :name "Lucy"; :knows _:bob .
_:bob a :Person; :name "Bob"; :knows _:alice .
本書によるとturtle言語はRDFデータのフォーマットにもなっていて、主語、述語、目的語はURIになる。
セマンティックWEBの考えから、識別子だけでは一意にならないことからURIと組み合わせたとのこと。
RDFをXMLを使って表現することもできるが、Turtle/N3(上記リンク参考)の方が人が見たときにわかりやすい。
SPARQL
SPARQLはトリプルストアのRDFデータモデルを扱うためのクエリ言語。
本書によると、下記の様にかける。
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "Saitama".
?person :livesIn / :within* / :name "Tokyo".
}
グラフモデルの礎となったDatalog
SPARQLやCypherより前に出たもので、トリプルストアに似ている。
トリプルストアのモデルがsubject predicate objectであるのに対して、
Datalogのデータモデルはpredicate(subject, object)の様に記述される。
DatalogはSPARQLやCypherの様にいきなりSELECTをするのではなく、データの取り出し方についてルールを決めて取り出す。
SPARQLの下記のような再起的にwithinで指定する場所にアクセスする箇所については、再起的に場所に対してpredicate(subject, object)を定義して、すべての場所に対して定義できたのちに結果を取得する。
?person :bornIn / :within* / :name "Saitama".
?person :livesIn / :within* / :name "Tokyo".
3章:ストレージと抽出
ストレージはデータの保存と取り出すことを考える必要がある。
リレーショナルデータベースで使われるBツリーのようなページ志向のストレージエンジンやNoSQLでよく使われるlog-structured ストレージエンジンを見ていく。
※ちなみにMongoDBやDynamoDBのような所謂NoSQL(ドキュメントモデル)でもBツリーを使っているので、Key-Value, NoSQLだからと言ってlog-structuredストレージ、LSMツリーを使っているわけではない。読み込みをするならLSMツリーは微妙ってことなのだろうか?
簡単なデータベース
最も簡単なデータベースの形はログのようなデータ構造で、key, valueの構造でデータを蓄える。
書き込みはログの末尾に追加する形で、
読み込みはログファイルを読み込み、頭の行から該当のレコードがあるかどうかを1つずつルックアップして探していく。
書き込みは高速であるが、読み込みはO(n)の計算量で、最悪すべてのレコードをルックアップする必要があるのでコストがかかる。n: レコード数が倍になるたびに計算量は倍になっていく。
読み込みを高速化するために通常インデックスを追加のデータ構造としてもつ。
インデックスを導入することで書き込みのパフォーマンスは下がる。インデックスの内容も更新する必要があるため。
ハッシュインデックス
key-value型のためのインデックス。
keyごとにバイトオフセット(ファイル中のレコードの開始位置を指し示した値)を表したハッシュマップをメモリで管理してディスクから該当keyのレコードを取り出す。
データストレージではファイルに追記するのみ。
読み書きで高いパフォーマンスだが、ハッシュマップがメモリ中に収まらないといけない。
レコード自体はメモリに収まらなくも良い。ファイルシステムのキャッシュ中にあるならディスクI/Oなしで読み出しできる。
Bitcask(Riakのストレージエンジン)はこの方法を採用してる。

今の状態だとファイル中に書き込みしかしてないので、いずれディスクの容量がいっぱいになってしまう。
データファイル中のレコードをいくつかのセグメントに分けて、コンパクションとマージを行うことで同じkeyに対して最新の値のみ残しつつ、tombstone(削除フラグ、墓石ともいう)をセグメントに書き込むことで削除も可能(tombstone以降の値は読まない)。
また、コンパクション・マージ中は古いセグメントは残しつつ行うので読み書きも継続できる。
コンパクション・マージが完了すれば古いセグメントは消す。
読んでてよく分からなくなってたが、このセグメントはディスク上に合ってコンパクション・マージはメモリ上に読み込んでから行う。

読みはいいけど、書きはコンパクション・マージ行いながらは無理なんじゃないかと思ったが、コンパクション・マージは凍結した(もう書き込みがない)セグメントであればできるので問題ないかと思った。※合ってるかは分からない
実装で重要な点は下記。
- ファイルフォーマットは、文字列の長さをバイトにエンコードした値を頭に付与した「生の文字列」を続けるようなバイナリフォーマットの方が高速
- レコードの削除はtombstone
- クラッシュのリカバリはセグメントを読み直して、ハッシュマップをメモリ上に再生成するが、セグメントの数が多いと時間がかかるので、Bitcaskではセグメントごとのハッシュマップのスナップショットを逐次ディスクに保存することでリカバリを高速化してる
- 部分的に書き込まれた破損レコードはチェックサムを入れることで壊れた部分を無視できる
- 並行性の制御はライターを1つにして書き込みをシングルスレッドで処理することで実現。読み込みは平行でも可
追記のみのログは下記の理由で優れてる
- 追記&コンパクション&マージはシーケンシャルな書き込みで高速、磁気ディスクのHDDでは尚のこと、SSDでも望ましい
- 並行処理とクラッシュリカバリがログへのイミュータブルな書き込みであることからシンプルな実装になる
- 古いセグメントをマージした後に廃棄することでフラグメンテーションを起こす問題を避けられる
とはいえ、下記の様な問題も。
- ハッシュマップが巨大になってくると、メモリに置けなくなるがかといってディスクに置いたらパフォーマンスが出ないし、ハッシュの衝突も気にする必要がある
- 範囲検索ができない(ハッシュごとにルックアップしないといけない)
SSTableとLSMツリー
上記のような問題を解消するために、ハッシュインデックスに少し改良を加えて、
- データファイル中の(key, value)レコードの並びがkeyでソートされる様にする
- セグメント中に同じkeyのレコードは複数存在しない(重複しない)
- →先ほどのハッシュインデックスのコンパクションで重複排除していたのでそれで満たされる
変更を加える。
このフォーマットをソート済み文字列テーブル(SSTable)と呼ぶ。
書き込みがシーケンシャルにできなくなる様な気もするが、それは後で述べる。
- →先ほどのハッシュインデックスのコンパクションで重複排除していたのでそれで満たされる
以下の利点。
-
セグメントのソートとマージについて、マージソートを用いることで計算量を抑えてメモリ上でソートをしつつ、先ほどのコンパクション&マージと同等の処理を行うことが可能。書き込みがシーケンシャルでも問題なくこのソート処理については順次バックグラウンドで行っていく。処理詳細については後述。
- マージソートは大きい値の並びをソートする時に最初に小さい単位に分割して、ソートした単位同士をマージを再起的に繰り返すこと
https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/sorting/merge-sort
- マージソートは大きい値の並びをソートする時に最初に小さい単位に分割して、ソートした単位同士をマージを再起的に繰り返すこと
-
セグメント内の(key, value)レコードがkeyでソートされているので、メモリ上のハッシュマップで全てのキーを管理する必要がない。数KB程度ならスキャンに時間がかからないらしいので、それくらいの単位でハッシュマップのkeyを管理すれば良い。
-
読み込み時には一定範囲の(key, value)のレコード群を読み込むことになるので、まとめて圧縮してお蹴るためディスク容量の節約やI/Oの帯域削減になる
書き込みをシーケンシャルにしつつ、ソート&コンパクション&マージをする処理の流れは下記。
memtableはインメモリのバランスドツリーデータ構造(ex: red-black tree)である。
そのため、レコード挿入&削除をしても高さを保ちつつ(データアクセスの計算量をO(logn)に)、ソートするというデータ保持の仕方になっている。
memtableがクラッシュしてデータを失った場合のために書き込み後は即座にログに書き込む。memtableのリストアを目的としてるのでソートしなくても問題ない。
ネットワーク層とかは前段のサーバとかそういうものはすっ飛ばしてますし、所々想像入ってます。
パフォーマンス最適化
読み込み時にkeyに対して古いセグメントを読みにいく必要があり、仮にkeyが存在しなかったときにルックアップに時間がかかる可能性がある。
そのため、ブルームフィルタ(集合の内容についての概要を保持するメモリ効率の良いデータ構造)を使って、存在しないことをチェックする。
コンパクション&マージのタイミングについては下記の2つがある。
- サイズごと
- →新しく小さいセグメントを古く大きなセグメントに連続的にコンパクション&マージ
- 階層ごと
- →キーの範囲ごとに小さなSSTableに分割して、コンパクション&マージをインクリメンタルに行う
- ※必要なディスク領域が少なくて済む
Bツリー
最も広く使われているインデックス。
SSTableと同様にkey, valueの組み合わせをkeyでソートして保持している。
バランスツリーなのでinsert, deleteをしてもツリーの高さが保持可能。
B+ツリーの場合は、
・Bツリーと比べて索引部とデータ部に分かれている
・keyの長さを短縮して保持している
・データ部のレコードがリンクリストのように隣のポインタを持つため、連続したスキャンも効率的に可能
B+ツリーの最適化は一般的なのでB+ツリーのことをBツリーと呼ぶことも多い。
ページ、ブロックという単位で読み書きを行い、下記図だとrefに対応するレコード群(レコードの塊)がそれである。
ページあたりのrefの数ことを分岐係数という。

書き込み処理時は一度にツリーの複数ページに書き込むことがあるため、途中でデータベースがクラッシュした際にデータが破損する可能性がある。それを防ぐため、ツリー反映前にwrite-aheadログ(WAL、redoログ)に書き込みを行う。追記のみ行うファイルである。
並行処理制御はツリー自体に軽いロック(ラッチ)を施すことで実現。
パフォーマンス最適化
B+ツリーの最適化も含めてさまざまな最適化がある
- WALの代わりにコピーオンライトを用いて、ツリー内の親ページの新しいバージョンを作成して参照先(ref)を更新する。並行制御にも有効でスナップショット分離でも使われる
- ページに保持するキーを短縮
- →B+ツリーの利点
- リーフページ(ツリーの一番下。画像で言うとデータ部のところ)は左右隣に参照を持っていて、連続的にスキャンする際に親ページを参照する手間が省ける
- →B+ツリーの利点
- できる限りリーフページの並び順にディスク上でシーケンシャルに並ぶように配置する。とはいえ、データ量が多くなると難しくなる。その点、LSMツリーはストレージ上の大きなセグメントを一度に置き換えるためディスク上のシーケンシャルな並びを実現しやすい。
BツリーとLSMツリーの比較
ちなみに多くのファームウェアではSSDの内部でlog-structuredなアルゴリズムを使っているらしく、SSD
の書き込みはシーケンシャルになるらしい。
とはいえ、書き込みの増幅を抑えてフラグメンテーションを減らすことはSSDにメリットがある。
ちなみに、書き込みの増幅とは一度の書き込みで複数の書き込みが生じること。
Bツリーの場合は複数ページにわたって書き込みが発生する場合がある。
| 種別 | 書き込みスループット | ディスク容量 | スループットの安定性 | 強いトランザクション | カバーするワークロードの広さ |
|---|---|---|---|---|---|
| Bツリー | 書き込み増幅のため△ | フラグメンテーションが起こったりと△ | 予測しやすくO | keyに対するインデックスを1箇所で管理していてツリーをラッチ可能なためO | OLTPで使用実績O |
| LSMツリー | シーケンシャルな書き込みで基本的にはO | 圧縮かつコンパクション&マージ処理でO | コンパクション&マージ処理は重たく高いパーセンタイルでは△ | keyが複数箇所に点在しているためX(△?) | ディスク容量を逼迫したり高いトランザクションを求められると厳しい??TTLは決めとく必要がある?? |
インデックス
ここまではkey-valueのインデックスなので、リレーショナルモデルにおけるプライマリキーの様なもの。
プライマリキーとはタプル、行、ドキュメントといった単位を一意に決めるキーのこと。
セカンダリインデックスもまた使われていて、RDBで使われるCREATE INDEX コマンドを使った際に作成されるインデックスである。
セカンダリインデックスは、キーがユニークでないため行の識別子と組み合わせたり、キーに対する値をリストで持つだったりにすればkey-valueインデックスから容易に実装可能。
インデックスの値の保存
インデックスが指し示す値は下記のいずれか。
- ヒープファイル中にある場所
- 行、タプル、ドキュメントへの参照
ヒープファイルはセカンダリインデックスを複数作る際に、データの複製を避けることができるため有用。
keyの更新を伴わない場合は容易であるが、「更新元の値の長さ」< 「更新後の値の長さ」となる場合は、下記の必要があるため、状況によっては読み取りのパフォーマンスが落ちる可能性がある。
・ヒープファイル中の新しい場所を参照するようにすべてのインデックスを更新
・ヒープファイル中のレコードの位置を新しい参照先のポインタを保持する
インデックスされた行を直接インデックス内に保存する方が最もパフォーマンスが良く、この方式を取るものをクラスタ化インデックスという。
MySQLのストレージエンジンのinndbではプライマリキーのみサポートしている。
セカンダリインデックスはレコードの参照(プライマリキー)を指している。
また、クラスタ化インデックスと非クラスタ化インデックスの間をとるものをカバリングインデックスといい、テーブルの一部列のみを持つインデックスである。
MySQLのストレージエンジンのinndbでは必要ならカラムに対して連結されたインデックスを使うのも1つの手だと言ってる。
※キーに対するインデックスなのだからインデックスでキーを保持するのは当たり前の話か。
各クエリーで使用できるインデックスは 1 つだけであるため、カラムごとに個別のセカンダリインデックスを作成しないでください。 ほんの少数の異なる値を持ち、めったにテストされないカラムへのインデックスは、どのクエリーにも役立たない可能性があります。 同じテーブルに対して多くのクエリーがあり、カラムのさまざまな組み合わせをテストする場合、多数の単一カラムインデックスよりも、少数の連結されたインデックスを作成してみてください。 インデックスに結果セットに必要なすべてのカラムが含まれている (カバリングインデックスと呼ばれます) 場合、クエリーはテーブルデータをまったく読み取らなくても済む可能性があります。
https://dev.mysql.com/doc/refman/8.0/ja/optimizing-innodb-queries.html
複合インデックス
複数カラムのインデックスを 連結インデックス という言い方をする。
例えば、(姓、名)から電話番号を取得するインデックスを考えると、「姓」「名」を組み合わせたものをキーとして保持&探索を行う。
順番が大事。
上の順番なら特定の(姓、名)、(姓)のレコードを探索する分にはインデックスが利用できるが、特定の(名)のレコードの探索にはインデックスが利用できない。
※確か連携した部分に対して範囲検索をしているため、カラム順序順の値については一致検索が効く。
MySQLの場合↓
下記のように複数カラム(ex: 緯度、経度)に対して範囲検索をする場合は上記のような 連結インデックス ではインデックスの利用ができない。
※これ知らなかった。。。
↓ここにも書いてあるがBツリーの構造をイメージすると確かにそうか。
下記の場合は空間充填曲線というものを使い、2次元の位置を単一の値に変換してBツリーを使うことで各カラムで可能。PostGISではPostgreSQLのGISTインデックスの機能を用いたRツリーを用いて地理空間インデックスを実装している。
select * from spots
where
latitude >= 32.1111 and latitude <= 50.1111
and
longitude >= 50.1111 and longitude <= 70.1111
これは緯度、経度だけではなく、(青、赤、緑)のような複数の値についてもサポート可能。
(日付, 気温)とかでもおけ。
全文検索と曖昧インデックス
今までソート順序を持つキーに対するインデックスを考えてきたが、
スペルミスの様な類似の単語に対する検索は考慮されてこなかった。
全文検索エンジンではある語を検索すると、スペルミスをした語や類似語に関して検索が可能になっている。Lucene(ElasticSearchの内部で使われてるやつ)ではある編集範囲(編集範囲=1 ならば 1つの文字が追加・削除・置換されている)にある語に対して検索が可能になっている。
Luceneは語の辞書にSSTableに似た構造を使っている。
trie に似たキー内の文字に対する有限オートマトン。
trieは、下記を見た限り文字列の並びに対して検索が書けられるぽい。
「TE」をキーとするとなら「TEA」「TED」「TEN」が取れる。
有限オートマトンというのは、
有限個の状態と遷移と動作の組み合わせからなる数学的に抽象化された「ふるまいのモデル」である。
https://ja.wikipedia.org/wiki/有限オートマトン
だそう。複数の状態を持つが、そのうち1つの状態を持つらしい。
このオートマトンはある編集距離内にある語の効率的な検索をサポートするレーベンシュタインオートマトンに変換可能。
わかりません。。。前に見た自然言語周りを少しだけ勉強した時に見たことあるかも。
全データのメモリ保持
データセットをすべてメモリに乗せられるならそれに越したことはないが、
今までの話ではディスク上にデータセットが載っていた前提で話が進んでた。
ディスクやメモリと比べて
・永続性がある
・GB単位のコストが低い
というメリットがある。
RAMが安価になるたびにディスクのメリットは薄れ、複数のマシンに分散することでメモリ上にデータセットを保持することが可能になる。
このことがインメモリデータベースの発展につながった。
Memcachedのようにインメモリkey-valueストアの中にはキャッシュだけの用途として、マシンが落ちてデータが失われても良いとするものもある。
他の大体のインメモリデータベースは耐久性を目指していて、バッテリ駆動のRAM、ディスクに変更ログを書く、メモリの状態を他マシンにレプリケーション等を行っている。
ディスクに書かれたログは分析、バックアップ、検索が可能なので運用面でメリットもある。
RedisやCouchbaseだとディスクへの非同期書き込みで弱い耐久性を持っている。
サービスによって永続性に対する考え方が全然違うのでそこはドキュメントを見て調べないとと思った。
インメモリデータベースのメリットは、
- パフォーマンス
- ディスクから読み取りをしなくて済むことではなく、メモリ内のデータ構造をディスクに書き込める形にエンコードするオーバヘッドを削減できること
- ディスクから読み取りは十分なメモリがあれば、OSがディスク上のブロックをメモリ上にキャッシュしてくれるらしい。
- ディスクから読み取りをしなくて済むことではなく、メモリ内のデータ構造をディスクに書き込める形にエンコードするオーバヘッドを削減できること
- 保持するデータ構造の柔軟性
- プライオリティキューや集合のようなデータ構造をメモリ上に持つことが容易にできる
アンチキャッシングアプローチでは、
長い間使われていないデータをメモリからディスクに退避させ、将来アクセスされた時にまたメモリにロードし直す。
不揮発性メモリに期待。
今までスレッドに書かずにすでに書いていた内容に対して更新をかけていたのだが、そういえばスレッド形式でものが書けるのだから、新しく書きたい項目があったらこうやって書けばいいやと思い出した。
下までスクロールするの大変だし、そうしよう(最初からそうしとけ)。
トランザクション処理か分析処理か?
トランザクション処理とは?
単にクライアントが低レイテンシで読み書きを行うということだけ
分析処理とは?
ユーザに対してデータそのものを返すのではなく、ようやく統計(レコード数、合計、平均など)を計算します
ビジネス上で求められることは2つ
- オンライントランザクション処理(OLTP)
- ECサイトの商品購入etc
- オンライン分析処理(OLAP)
- ある月のある店舗の売り上げ合計を調べる
OLTPがオンラインなのはわかるが、なんでOLAPはオンラインなのかの説明に下記がある。
アナリストが探索的なクエリのためにOLAPシステムをインタラクティブに使うことを指しているのでしょう
OLTPとOLAPの比較
| 特性 | OLTP | OLAP |
|---|---|---|
| 読み取りパターン | 少数のレコードをキーで取得 | 大量のレコードを集計 |
| 書き込みパターン | ユーザ入力によるランダムアクセスと低レイテンシ | バルクインポート(ETL) or イベントストリーム |
| 利用者 | エンドユーザ | アナリスト |
| データセットのサイズ | ギガバイト〜テラバイト | テラバイト〜ペタバイト |
1990年代からOLTP、OLAPで使うデータベースを分ける様になった。
OLAPで使うデータベースを データウェアハウス とよぶ。
データウェアハウス
大きな企業では顧客が利用するOTLPシステムは複数あり、それぞれ複雑で管理はそれぞれ別チームで行うことが多い。
OLTPシステムは高い可用性と低レイテンシを押さえておいて欲しいので、アナリストにOLAP目的であまりいじりまわして欲しくない。
OLAP目的のクエリは負荷が大きく、OLTPシステムのトランザクションに影響を及ぼす可能性があるためである。
別管理なので、OLTPシステムから OLAPシステムのためのデータウェアハウス にETLする必要がある。
下記のような流れになる。
扱うデータ量が少なかったり、OLTPシステムに可用性や低いレイテンシを求めないならデータウェアハウスを別で持つ必要はないが、データ量が多い上にそれらを満たそうと思うと分析処理が厳しくなってくる。特にOLTPシステムを止めちゃいけない系だと。
前述したインデックスだと分析のような大量データを処理するのに向かない。
インデックスは少量のデータを取得するのに向いているので。
OLTPデータベースとの相違点
データウェアハウスのデータモデルは総じて、リレーショナル。
SQLが分析的なクエリに適しているため。
OLTPリレーショナルデータベースもデータウェアハウスもインターフェースは同じSQLであることから似ている様に思えるが、ストレージエンジンの作りは異なるもの。
データベースベンダはOLTP, OLAP双方をサポートしているサービスを提供しているが、実際は内部実装が異なり、双方独立したエンジン&ストレージを使用する様になっている。
Microsoft, SQL Server, SAP HANAなど。
OSSではSQL on Hadoopプロジェクトが立ち上がっている。
Hadoopなので本書で後述するバッチ処理の様な動きになるかと思われる。データをパーティションごとに分けて複数の小さなマシンで処理を分割して結合を繰り返す決定的な処理である。
Apache Hive, Spark SQL, Cloudera Impala, Facebook Presto(->今はtrinoという名前になっている), Apache Tajo, Apache Drillなどがある。
スターとスノーフレーク
多くのデータウェアハウスはスタースキーマ(ディメンションモデル)と呼ばれる。
ファクトテーブルとディメンションテーブルからなる。
ファクトテーブルはある時点で生じたイベントを指し、ディメンションはイベントに紐つくマスタデータを指す。
下記の様な構造になっていて、ファクトテーブルをディメンションテーブルが取り囲むスターの様な形になっているため、スタースキーマと呼ばれる。
他の項目についてもディメンションを増やしたり、分割したりすることができる。
例えば日付や時刻といったカラムもディメンションとして定義できるし、商品をさらにカテゴリ分けてしておくことも可能(dim_products が dim_product_categories に属するように設計可能)。
このディメンションをさらにサブディメンションに分割する考えは、スノーフレークスキーマと呼ばれる。下記なのでスタースキーマよりもさらに細かくっていうことでしょう。たぶん。
「snowflake」は「雪片・雪の結晶」という意味
上の図ではカラム数がせいぜい5個程度だったが、典型的なデータウェアハウスではテーブルは大量の列を持つ。列数が100以上になることは珍しくないらしい。
列志向ストレージ
ファクトテーブルが膨大な行数を持ち、ペタバイトに及ぶならそれらの行を効率的に保存して探索するのは難題。
ディメンションテーブルは通常小さい。とはいえ、数100万レコード程度はあるらしい。
例えば上記の様な図であれば下記の様なクエリが考えられる。
※dateの型については適当。実際にはcastが行われると遅いとかあるので、そこは気をつける様にする。
select
cs.customer_sk,
pd.product_category,
sum(sl.net_price),
sum(sl.gross_price)
from fact_sales sl
inner join dim_customers cs
on cs.customer_sk = sl.customer_sk
inner join dim_products pd
on pd.product_sk = sl.product_sk
where
date = "2013-01-10"
pd.product_category in ("Meet", "Fluit")
group by
cs.customer_sk, pd.product_category
このクエリのパフォーマンスを上げて実行しようとすると、
ファクトテーブルでcustomer_sk、product_skのような結合やgroup byの条件となるキーにインデックスを貼ってパフォーマンスを上げられるが、
行指向ストレージの場合は、オプティマイザにしたがって取得した外部表の行に対してディスクからメモリにロードしてフィルタリングするため、処理に時間がかかる。
結合アルゴリズムについては下記にまとめていただいているものを参照する。
MySQLの場合だとHash JoinかNested Loop Joinの2択で、等価結合でインデックスなしならHash Join、インデックスありならNested Loop Joinとなる。
whereが効いていれば実際にスキャンする外部表は減るのが、全体のスキャン量が多いとやっぱり行指向だと厳しいという印象。
ちなみにこれがオプティマイザの計算によっては内部表が小さければHash Joinになるんじゃないかという話も公式ではないが出ている。
等価結合でインデックスなしならHash
結構うろ覚えでかいてるので後でちゃんと調べる。
列指向ストレージはシンプルで、列に含まれる値をまとめて保存する。
下記の様なレコードがあったときに、
| customer_sk | product_sk | date | net_price | gross_price |
|---|---|---|---|---|
| 1 | 1 | 2020-04-11 | 1000 | 1100 |
| 1 | 2 | 2020-04-12 | 1500 | 1650 |
| 2 | 3 | 2020-02-12 | 1600 | 1760 |
| 2 | 4 | 2020-01-12 | 1800 | 1980 |
| 3 | 4 | 2020-01-16 | 1800 | 1980 |
列ごとに下記のように値を保持する。列ごとにファイルが分かれているイメージ。
それぞれの列ファイルが同じ順序で値を保持する必要がある。任意の行(例えばn番目とする)を構成するためには各列ファイルのn番目の値を並べて再構成する。
customer_sk: 1, 1, 2, 2, 3
product_sk: 1, 2, 3, 4, 4
date: 2020-04-11, 2020-04-12, 2020-02-12, 2020-01-12, 2020-01-16
net_price: 1000, 1500, 1600, 1800, 1800
gross_price: 1100, 1650, 1760, 1980, 1980
※今思ったが列指向だとyyyy-mm-ddのように冗長な値の持ち方はまずいのかなと思った。なるべく正規化をして冗長な表現を減らすことが重要なのだろうか?
行指向ストレージの行ごとに全ての列の値を保持するのとは対照的。
列ストレージは非リレーショナルモデルにも同じ様に適用できる。
例えば、Parquetはドキュメントデータモデルをサポートする列ストレージフォーマットである。
列の圧縮
クエリに必要な列だけ読み込むだけでなく、列を圧縮すればディスクに対する負担も減る。
上の例におけるproduct_skを圧縮すると、下記の様になる。
列の値に対して繰り返しが起きているため、画像のようなビットマップエンコーディングをすることができ、さらにproduct_skの取りうる値が増えてくると0が並ぶことになり(こういった状態を疎と呼ぶ)無駄なスペースを取るので、(0 zeros, 1 one, rest zeros)の様なランレングスエンコーディングをすることで圧縮効率をさらに高めることができる。

product_sk = 1: 0, 1 (0 zeros, 1 one, rest zeros)
product_sk = 2: 1, 1 (1 zeros, 1 one, rest zeros)
product_sk = 3: 2, 1 (2 zeros, 1 one, rest zeros)
product_sk = 4: 3, 2 (3 zeros, 2 one)
ビットマップエンコーディングは和演算(A or B)や積演算(A and B)を行うことにも適しているので、
下記の様な演算に対しても処理を行うことが可能。下記の様な演算が可能であるのは各列の値の並びが実際の行の並び(他の列の並び)に対応しているからである。
-- 和演算
where product_sk IN (1, 2, 3, 4)
-- 積演算
where product_sk = 4 and date = "2020-01-16"
Cassandra、HBaseはBigTableから受けついだ列ファミリという概念があるが、全ての列が行キーと一緒に格納されているため上で表現した列指向(列の値だけを他の列と順番を保って保持する)とは異なり、行指向に近いもの。
数百万行をスキャンしなければならないデータウェアハウスのクエリでは、ディスクからメモリにデータを移すための帯域が大きなボトルネックとなります。
とはいえ、これが唯一のボトルネックというわけではありません。
メインメモリからCPUキャッシュへの帯域への効率的な利用、分岐の予測ミスとCPUの命令処理パイプライン中のバブル、現代的なCPUのシングルインストラクションマルチデータ(SIMD)命令の利用も考慮する。
ここら辺は詳細についてわからなかったが、ハードウェアレベルで処理速度について考慮して、場合によっては並列処理も行うことを考えると理解。
圧縮した列はL1キャッシュに乗り切るので、CPUサイクルの効率的な利用に繋がる。
圧縮した列に対して、ANDやORといった処理は直接処理可能なので、ベクトル化処理(vectorized processing)と言われる。
ソート
ソートキーを順番に定義して、その順に列をソートすることが可能。
例えば、
ソートキー1: 日時
ソートキー2: 商品ID
であれば、ある月の商品IDの売り上げ合計金額を高速に出力することが可能。
列の値は同じ値が並んでいる方が圧縮効率が高いので、ソートをすることはクエリを高速化する上で重要。
圧縮の効果は最初に定義したソートキーのほうが高い。
値がバラバラの順序になるため、後に定義したソートキーの効果は薄れていく。
書き込み
列指向の圧縮された列では、Bツリーが扱うようなインプレースでの更新は不可能。
ソートされたテーブルの列の途中に値を加えたい場合、全ての列ファイルを書き換える必要がある。
LSMツリーであれば、ディスクに書き込む前にソートが可能なのでverticaというサービスはそれを利用している。
メモリ内の直近の書き込みとディスクの書き込みを両方を調べて、結果を組み合わせる。
集計:データキューブとマテリアライズドビュー
MINやMAX、AVGの様な集計関数があるが、クエリのたびに計算するのはコストがかかるため実体化された集計としてどこかにキャッシュしておくのが、計算コスト上良い。
こういったキャッシュを生成する方法がマテリアライズドビュー。
ビューは問い合わせの定義を事前に書いておくだけで、実際に結果レコードをディスク上に持たないが、マテリアライズドビューはディスクにもつ。
データの更新に伴い、マテリアライズドビューも更新する必要があるが、書き込み負荷がかかるためOLTPデータベースではあまり使われない。
マテリアライズドビューの特化したケースでよく使われるものに、データキューブ(OLAPキューブ)というものがある。
何らかの次元の組み合わせで集計した値を持つテーブルである。
例えば、日時-製品-顧客の組み合わせの売上などである。
2次元であればエクセルやスプレッドシートの表の様な形で表現できる。
ただ当然生のデータではないので、クエリの柔軟性には欠ける。
基本的には生のデータのまま扱い、必要に応じて(重たい集計処理など)データキューブのような集計結果を使用すると良い。
4章: エンコーディングと進化
進化性について。
進化性
ビジネスの優先度やユースケースは変わり、システムへの要求は変わっていく。
アジャイルな仕事は変化に対応する上で有用なフレームワークだが、扱うシステムの部分は限定的なもの(全体の中の一部のソースコード)。
データシステムは巨大で、そのシステムに対してアジリティを高めるのが目標。
本書では、進化性はデータシステムのレベルでのアジリティを指す。
進化性は単純性や優れた抽象化に依存する。
https://zenn.dev/link/comments/404e5316ae2365
リレーショナルデータベースはスキーマオンライトであるため、ある時点で決定されるスキーマは厳密に1つである。※ALTER TABLEにてスキーマが変更されることはあるが
ドキュメントデータベースを始めとするNoSQLの中にはスキーマオンリードのものが多く、データベースには異なる時点で書き込まれた新旧のデータフォーマットが混在することもある。
そのデータを読み書きするアプリもそのデータフォーマットの変更に対して対応する必要がある。
- サーバサイドアプリケーションの場合は、ローリングアップデートをして複数ノード中の幾つかのノードにデプロイをして、テストを行いながら複数ノードに反映することができる。ダウンタイム無しでできるのが魅力。
- クライアントアプリケーションの場合は、ユーザ自身でアップデートする必要があるため、新旧のデータフォーマットは共存し得る
互換性には2つある。
- 後方互換性
- 新しいコードが古いコードで書かれたデータフォーマットを読めること
- 前方互換性
- 古いコードが新しいコードで書かれたデータフォーマットを読めること
後方互換性はアプリ開発者が内部実装を知っていれば満たされるように改修を加えることできるが、前方互換性は難しいことがある。
データエンコードのフォーマット
プログラムはデータを異なる表現で使う。
- メモリ上
- オブジェクト、構造体、リスト、配列、ハッシュテーブル、ツリーなどで保持
- ファイル書き込みや、ネットワーク経由でデータ送信時
- データを何らかのバイトの並び(JSONやCSVなど)にエンコードする必要がある
上記のように、メモリ上と、ネットワークやストレージで扱うデータフォーマットは異なるので、データフォーマットを変換する エンコーディング(シリアライゼーション、マーシャリング) が必要。
反対にエンコーディングされたデータを元に戻すことを デコーディング(パース、アンマーシャリング)と呼ぶ。
※シリアライゼーションはRDBでも使う言葉だが、その場合は直列かという意味もあるので文脈によって変わることに注意。
言語固有のフォーマット
プログラミング言語には、インメモリオブジェクトをバイトの並びにエンコードするライブラリがある。
RubyだとMarshal。
Ruby オブジェクトをファイル(または文字列)に書き出したり、読み戻したりする機能を提供するモジュール。
下記の様な問題があり、ほとんど使われてない。
- 言語特有のデータフォーマットなので、他の言語との互換性が失われている可能性があるため、他の組織のシステムとの結合が難しくなる
- デコードする際は、任意のクラスをインスタンス化する必要があるため、セキュリティ上のリスクになることがある
- とはいえ、言語によって制約もあり、RubyのMarshalだと下記の様なオブジェクトはそもそもエンコードできない制約。
名前のついてない Class/Module オブジェクト。(この場 合は、例外 ArgumentError が発生します。無名クラスについて は、Module.new を参照。)
システムがオブジェクトの状態を保持するもの。具体的には以下のイン スタンス。Dir, File::Stat, IO とそのサブクラス File, Socket など。
MatchData, Data, Method, UnboundMethod, Proc, Thread, ThreadGroup, Continuation のインスタンス。
特異メソッドを定義したオブジェクト
- バージョニングについては後付けになっていることも多く、前方、後方互換性については十分にサポートできていない可能性がある
- 一応RubyだとRubyのMarshalだと下記の様にバージョニングはサポートしているが、loadするときにメジャーバージョンが異なるとエラーを返す仕組みになっていて確かに互換性について考慮してない様に見える。
MAJOR_VERSION -> Integer[permalink][rdoc][edit]
MINOR_VERSION -> Integer
Marshal.#dump が出力するデータフォーマットのバージョン番号です。
Marshal.#load は、メジャーバージョンが異なるか、バージョンの大きなマーシャルデータを読み込んだとき例外 TypeError を発生させます。
- エンコードのパフォーマンスが悪い
JSON、XML、バイナリフォーマット
XMLは冗長で複雑(確かにタグの構造を追ってくのはしんどい。エディタでXMLを見やすくするプラグインを入れたりしないと。)、
JSONはJavascriptのサブセットで扱いやすいため人気。XMLよりは冗長でない。
CSVは言語から独立しているが、区切り文字や値の囲み(ダブルクォーテーション)など考えることが多いし、フォーマットとしてそこまで強力ではない。
人が読めて直感的にはわかりやすいが、表面的には出てきてない問題もある。
- XML, CSVでは数値と文字列のエンコーディングを区別できない。JSONはできるが、浮動小数点数値と整数値を区別できず、制度も指定不可。
- →大きな数値を扱うときに問題になる
- JSON、XMLはユニコード文字列(人が認識できる文字列)はサポートしているが、バイナリ文字列はサポートしていない。base64でエンコードして持つことはできるがデータサイズが増える
- XMLスキーマは広く使われているが、JSONベースのツールの多くがスキーマを扱わない
- CSVにはスキーマがないのでアプリに任されている。区切り文字、値の囲み(ダブルクォーテーション)を考える必要がある。OSS等のライブラリでパーサの仕様がどうなっているのかは要チェック。
複数のシステムでデータフォーマットに合意することが大事で、難しいこと。
バイナリエンコーディング
組織内で扱われるなら、使用するエンコーディングについて制約が少なくなる。
コンパクトでパースが高速なフォーマットを使うことができる。
JSONはXMLほどではないが、バイナリフォーマットに比べると多くのデータ領域を消費する。
JSONのバイナリフォーマットには、MessagePack, BSON, BJSON, BISON, Smile 等がある。
これらにはデータ型や種類を拡張したりするものもがあるが、基本的なデータ型はJSONと同じである。
JSONやXMLはスキーマを持たないので、データフォーマット中にフィールド名を持つ必要がある。
下記の様なJSONのレコードをエンコーディングすることを考える。
76バイトである。ここで計測。
{
"name": "takuya",
"age": 24,
"favorite": ["banana", "apple"]
}
Message Packでバイナリエンコードすると下記の様になる。
実際には下記のエンコードした結果が全て結合されて16進数の並びとして表現される。
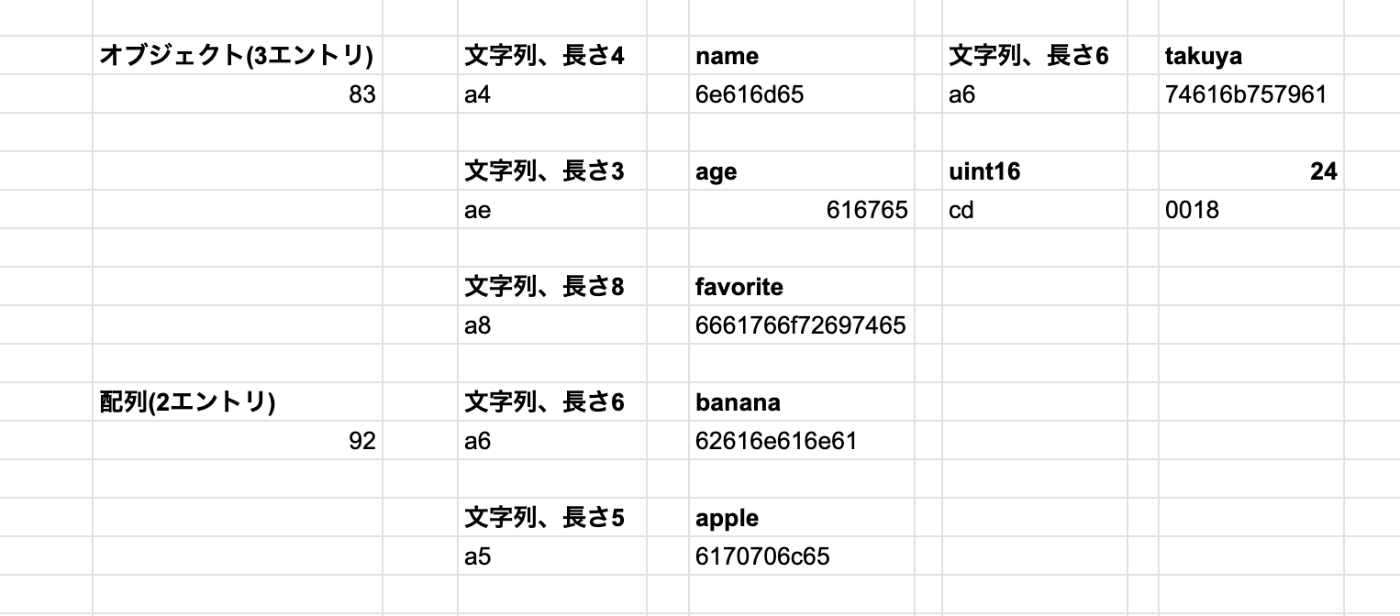
カウントしてみたところ43バイト。76→43なので微妙?
フィールド名が長いと圧縮率が微妙になる。
Thrift と Protocol Buffers
こちらは先ほどのMessage Packよりも効率良く圧縮できる。
Thrift と Protocol Buffers は同じ原理に基づくバイナリエンコーディングライブラリ。
Protocol Buffers は Google で Thrift は Facebookで開発された。
双方OSSとなっている。
双方ともに、エンコードするデータに対するスキーマを必要とする。
先ほどのJSONをエンコードするとそれぞれ下記の様になる。
Thrift
struct Person {
1: required string name,
2: optional i64 age,
3: optional list<string> favorite
}
Protocol Buffers
message Person {
required string name = 1;
optional i64 age = 2;
repeated string favorite = 3;
}
Thriftには2つの異なるバイナリフォーマット、BinaryProtocol、CompactProtocolがある。
Thrift BinaryProtocol を使って上記のJSONをバイナリエンコーディングすると下記の様になる。
異なるのはフィールド名や型の情報を含めず、フィールドタグ(1,2,3)を使用している。
45バイトでMessage Packよりも圧縮率が悪い。そもそもフィールド名が長くないのと、フィールド名の長さを表現するバイト列が固定長なので0が並んでいた場合に圧縮率が悪いよう。

Thrift CompactProtocolを使って上記のJSONをバイナリエンコーディングすると下記の様になる。
下記によってバイト数を削減して、20バイトになる。
- フィールドの型(長さ)とタグ番号を1バイトに格納
- 可変長整数を用いる
https://ja.wikipedia.org/wiki/可変長数値表現
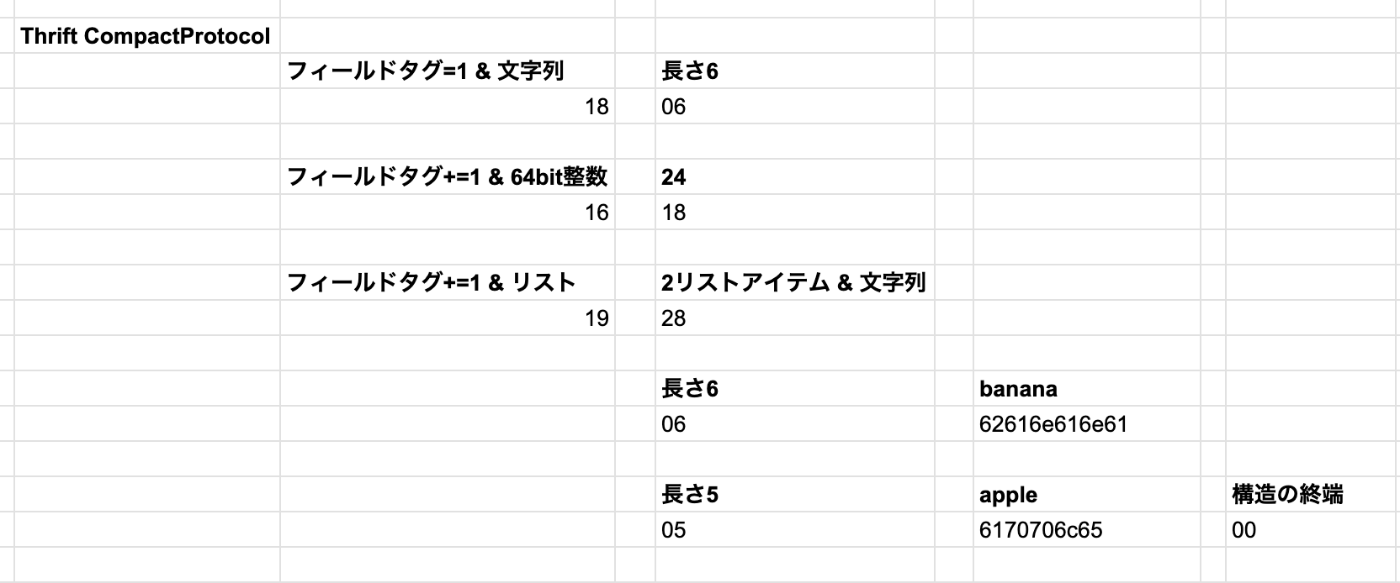
注意点としてはrequiredやoptionalは値のエンコードには影響しないこと。単にenabledを指定すると実行時にチェックが行われるだけ。Protocol Buffers に関しても Thrift CompactProtocol と類似したエンコード方法をとる。
フィールドタグとスキーマの進化
フィールドタグを変更すると、既存のデータが不正なものになり、互換性が失われる。
そのため、フィールドタグは不変であるべき。
新しいフィールドを追加する場合は、新しいフィールドタグを使用する。
前方置換性については、古いコードが認識できないフィールドタグについては無視することが可能なので満たされる。
後方置換性については、新しく追加したフィールドタグが「必須でない」or「必須 && デフォルト値が設定」であれば満たされる。
フィールドの削除の場合は、置換性の扱いが逆になる。
削除可能であるのは必須でないフィールドのみで、同じタグを使い回すことはできない。
データ型とスキーマの進化
詳しくはそれぞれのライブラリの公式ページを見る。
32bit整数のフィールドを64bit整数に変換することを考えると、後方置換性は保たれるが、前方置換性は保たれない可能性がある。
64bit整数が、32bit長に収まらない可能性があるから。
Protocol Buffers ではリストや配列といった方を持たずに、
optional, requiredと同列に repeated という表現を持つ。
すでにoptionalであるフィールドに対して、repeatedとなる変更をかけると、古いコードはrepeatedの最後の要素を指す。
Thrift では専用のリストデータ型を持ち、ネストしたリスト型をサポートする。
Avro
Apache Avroもバイナリエンコーディングのフォーマット。
ThriftがHadoopにうまく適合しなかったため、新しく生み出されたフォーマット。
Avroにはユーザが編集することを想定としたスキーマ(IDL)と、プログラムから見て理解しやすいスキーマ(JSON形式)の2つがある。
IDLで書くと下記の様な表記になる。
record Person {
string name;
union {null, long} age;
array<string> favorite;
}
スキーマ(JSON形式)は下記の様な表記となる。
{
"type": "record",
"name": "Person",
"fields": [
{"name": "name", "type": "string"},
{"name": "age", "type": ["null", "long"], "default": null}
{"name": "favorite", "type": { "type": "array", "items": "string" }}
]
}
Thrift や Protocol Buffers と比べてフィールドタグがないことが特徴。
エンコードした結果にもフィールドタグ分がないので、Thrift や Protocol Buffers と比べて圧縮率も高い。
フィールドタグがないので、エンコード・デコードの互換性は、ルールを守った上(後述)でリーダとライターでスキーマを突き合わせて担保する。
※Thrift や Protocol Buffers にはエンコードした結果にもフィールドタグが含まれるので、前述の項目の追加にはデフォルト値を、項目の削除はoptionalな項目を、とすることで前方・後方置換性が保たれる
下記のようなイメージ。
ライターのスキーマ:アプリがデータをエンコードしてデータベース/ファイルやネットワーク通信で対抗先システムに送信
リーダーのスキーマ:アプリがネットワークやデータベース/ファイルから受信したデータをデコード
リーダとライターのスキーマを突き合わせて、リーダがデコードする方法は下記の様なイメージ。
ライターが持ってるnameはリーダが持つスキーマには無いのでデコード時に無視される。

互換性を保つためには、追加・削除するフィールドはデフォルト値を持ったものである必要がある。
デフォルト値を持たないフィールドを削除
→古リーダースキーマで新ライタースキーマで書かれたバイナリを読めないので、前方互換性が失われる
デフォルト値を持たないフィールドを追加
→新リーダスキーマで古ライタースキーマで書かれたバイナリを読めないので、後方互換性が失われる
ライタースキーマとリーダースキーマの関連
ライタースキーマで書かれていることを、リーダースキーマがどう知るか問題は、各パターンによって変わる。
大量レコードを持つファイルの場合
・ライターがファイルの先頭にライタースキーマを含めて、ファイルを書き込む(Avroの仕様でそれが可能なファイルフォーマット。オブジェクトコンテナファイルという)
個別にレコードが書かれるデータベースの場合
・スキーマをバージョンとともにデータベースに保持しておく
・レコードの頭にスキーマのバージョンを含めて、レコード書き込み
→読み込み時に使用するスキーマをバージョンをキーにデータベースから取ってこれる
※レコード単位という意味だと違うが、DBのテーブル単位という意味だと Railsのmigration という機能はそれに近いのかなと思ったり
ネットワーク越しでレコード送信を行う場合
・2つのプロセスが双方向のネットワーク通信を行なっている場合は、接続確立時にスキーマのバージョンのネゴシエーションを行う
・Avro RPCはこれに従うらしい
※gRPCはprotcol bufferを使って同じ様なことしているのだろうか?
「1. 破壊的変更を回避できる」というのは、client を変更せずに server が変更できることを指しています。典型的なケースの1つは、server が自身の response に新しく field を追加したい時、client に影響を与えずにそれができることです。「複数の microservice を同時に更新する(デプロイする)」ことは極めて困難である為、これは重要な特徴となります。
「1. 破壊的変更を回避できる」について
gRPC は後方互換性のある schema 変更を support している
https://www.wantedly.com/companies/wantedly/post_articles/219429
動的に生成されたスキーマ
Avroは動的に生成されたスキーマと相性が良い。
例えばリレーショナルDBとか。スキーマ変更はデータを読み込むときに理解することができる。
前述の通り。スキーマ変更をした際にavroのフォーマットを変更することもできる。
個別にレコードが書かれるデータベースの場合
・スキーマをバージョンとともにデータベースに保持しておく
・レコードの頭にスキーマのバージョンを含めて、レコード書き込み
→読み込み時に使用するスキーマをバージョンをキーにデータベースから取ってこれる
※レコード単位という意味だと違うが、DBのテーブル単位という意味だと Railsのmigration という機能はそれに近いのかなと思ったり
同じことをThriftやProtocol Bufferでやろうとすると、スキーマ変更を追ってフィールドタグを手動で追加する必要あり。データベースの列名とフィールドタグの対応が自動で追えないから。
スキーマのメリット
下記の様なメリット
- バイナリJSONよりコンパクトになりうる
- ドキュメント(IFファイル定義とか)よりも正確で最新である
- デプロイに先立って互換性を確認できる
- 静的言語ユーザにとってはコンパイル時の型チェックがサポートされる(Thrift, Protocol Bufferなど)
スキーマの進化はスキーマレス/スキーマオンリードのJSONデータベースが提供するのと同様に、柔軟性をもたらしつつ、データに関する保証を強めてくれる。
データフローの形態
メモリを共有していないプロセスにデータ送信したり、ネットワーク経由でデータ送信する場合はバイナリエンコーディングする必要があった。
その際に前方、後方互換性は進化性を保証する上で重要であることが書かれていた。
データフローの形態としては下記を考える。
- データベース経由
- サービス呼び出し経由(RESTとRPC)
- 非同期メッセージパッシング経由
データベース経由でのデータフロー
データベースには単一のプロセスではなく、複数のプロセスによってアクセスされることが多い。
複数プロセスは異なるサービスの場合もあるし、異なるインスタンスの場合もある。
ローリングアップデートの場合は片方のインスタンスが古い場合があるので、前方置換性(新しいコードでwriteされたデータを古いコードでreadできる)が求められる。
アプリ側でその際に気にしておかないといけないのは、古いコードでreadした値をそのままwriteする際に追加されたフィールドが無視されて書き込む可能性があること。
※スキーマのバージョンをDB側にある値と比較して古ければ書き込まないとかの対策が必要なんだろか?
異なる値が異なる時刻に書き込まれる
データはコードよりも長生き。
スキーマの進化により様々なバージョンのスキーマによりエンコードされたデータが存在する。
※地層みたい。
データを新しいスキーマに合わせて一新することもできるが(マイグレーション)、大規模データの場合はコストがかかるので、大体のDBでは新しいフィールド追加(デフォルト値null)の際には古いデータを書き換えない。
LinkedInで使用されるドキュメントDBのespressoはAvroを使ってるのでデフォルトnullをデータを書き換えずに処理可能。
データベースは単一のバージョンのスキーマでエンコードされているかのようにデータを扱うことができる。
アーカイブストレージ
バックアップのような形でスナップショットを取得してデータを保管することがある。
一度書き出したら変更しないので、Avroのオブジェクトコンテナファイルのようなフォーマットが適してる。
大量レコードを持つファイルの場合
・ライターがファイルの先頭にライタースキーマを含めて、ファイルを書き込む(Avroの仕様でそれが可能なファイルフォーマット。オブジェクトコンテナファイルという)
Parquetの様な列試行フォーマットもエンコードに適してるらしい。
※あんまよくわからないけど、みた感じフィールドタグもないしフィールド名でスキーマ進化追ってそうなので多分Avroと同じで動的なスキーマ進化にも対応できる感じかな?
まあawsのrdsからスナップショットを取るとデフォルトだとParquetらしいから多分そうだろ(適当)
サービス経由(RESTとRPC)
ネットワーク経由でデータのやり取りをするプロセス群がある場合は、クライアントとサーバという2つの役割を持たせて処理するのが一般的な手法。
サーバはネットワークに対してAPIを公開して、クライアントはAPIにリクエストを発行する。
このAPIはサービスと呼ばれる。
GETリクエストでHTMLやCCSや画像等のデータを取得、POSTリクエストでサーバにデータを投入する。
APIは標準的なプロトコルとデータフォーマット(HTML、URL、SSL/TLS、JSONとか)を使用していて、概ねブラウザやJavascriptを使ったアプリケーション(XMLHttpRequest)は合意しているので通信をすることが可能。
サーバ自身がクライアントになることもある。
例えばAPIサーバがデータベースにアクセスしてデータを取得してクライアントに返すことなどを考えると、APIサーバ自身がクライアントになっていると言える。
大規模なアプリケーションを複数の異なる機能を持つサービスに分割することを、サービス指向アーキテクチャ(SOA)と呼ばれていたが、最近はマイクロサービスアーキテクチャと呼ばれる。
マイクロサービスの目標はそれぞれのサービスを独立してデプロイできること。
それぞれのサービスが異なるチームの管理下にあって、それぞれが合意を得ずに自由にサービスを更新できること。
新旧のサービスが入り乱れるので、クライアントサーバ間でAPIのバージョンの互換性は保つ必要がある。
Webサービス
HTTPが使われている場合、Webサービスと呼ばれる。
下記の様なパターンがある。
- WebブラウザやJavascriptアプリケーションからHTTP経由でリクエストされる。公開されたインターネットを使用して通信する。
- 同一組織内にあるサービス間で通信する。データセンター内でのリクエストが想定される。マイクロアーキテクチャの中で設計・実装されること多い。
- 他の組織にあるサービスに対して通信する。決済APIとか認証API(OAuth)とか。
RESTとSOAPがある。
RESTはプロトコルではなくHTTPの上に設計された設計哲学。
リソースの識別にURLを使い、キャッシュや認証、コンテンツタイプのネゴシエーションにHTTPを使う。
SOAPはHTTPに依存せずに、WSDLというXMLベースの言語に依存。
WSDLは人間が読める様に設計されてなく、手作業で書くのは困難なので専用のIDEやベンダのツールを使ってコード生成する。
クライアント・サーバ間の結合は運用上、上記の理由から難しく、SOAPよりもRESTの方がよく使われる。
RESTはOpenAPIの様なAPI定義のフォーマット(Swagger)で簡単に記述できるため、コード生成の必要性がほとんどない。
RPCの問題
RPCは、リモートにあるネットワークサービスへの発行を同じプロセス内でメソッドを呼び出すのと同じように実行できる様なプロトコルとして設計されていた。
(この特徴を場所の透過性というらしい)
ただ、ネットワークの通信とは下記の点で大きく違う。
- ローカルの関数呼び出しは予測可能だが、ネットワークの通信は予測不可能。サーバが応答不可になる可能性はあるし、パケットの消失の可能性もある。こうした現象は一般的でリトライの機構が必要。
- ローカルの関数呼び出しの挙動は、結果返却、例外投げる、制御を返さないの3つ。ネットワークの通信はタイムアウトという終わり方がある。この場合は処理が成功したのか失敗したのかリクエストした側にはわからない。
- 上記の様な現象に至る際にリクエストは届いたが、レスポンスが到達しなかったパターンがあり、その場合はサーバ側の処理は成功しているから、リトライ時した際に予想していない挙動になることがある。なので、サーバ側の処理は冪等に設計すべき。ローカルの関数呼び出しはこの点考慮不要。
- ローカル関数呼び出しの場合はメモリ中のオブジェクトへの参照を渡すことが可能だが、ネットワーク通信では不可能なので適切なデータフォーマットにエンコーディングする必要がある。数値とか文字列の様なプリミティブな値なら良いが、大きなオブジェクトなら問題になる
- クライアントサーバ間の言語が異なる場合は、RPC上でのデータ型の変換が難しい
- Javascpirtで2^53より大の値をパースできない問題とか
現在のRPCの方向性
RPCは現在も使われている。
下記フォーマットとRPCフレームワークの関係は下記の様になってる。
Thrift -> Figagle
Avro -> Avro RPC
Protocol Buffers -> gRPC
JSON → Rest.li
現在のRPCはリモートリクエストがローカル関数呼び出しと異なることを明らかにしてるものが多い。FinagleやRest.liは future(promise)を使って失敗する可能性のある非同期処理をカプセル化する。
gRPCはストリームをサポートしていて、複数のリクエスト、レスポンスの列を1回の呼び出しで行える。
Streams in HTTP/2 enable multiple concurrent conversations on a single connection;
https://grpc.io/blog/grpc-on-http2/
RPCフレームワークの中にはサービスディスカバリという機能を持っているものもあり、特定のサービスのIPアドレスとポートを知ることができるもの。サービスが複数ノードに分散してコンテナとして動いてる場合とかに必要なやつ。ECSとかEKSだとIPが増えたりコンテナ数が増えたりするので(あまりよくわかってないけど多分そう)
RPCのエンコーディングと進化
進化性という意味だと、クライアントとサーバに変更を加えることができ、独立してデプロイが可能なことが望ましい。
クライアントはものによるが更新にはユーザのインストール操作が必要だったりするので、一般的にサーバ側に変更を加えて、クライアントをアップデートするという流れが考えられる。
互換性としては、リクエストの後方互換性とレスポンスの前方互換性が必要とされる。
- 前述のバイナリフォーマット(Thrift, Protocol Buffers, Avro)はフォーマットでサポートしている互換性がサポートされる
- SOAPの場合はリクエストとレスポンスはXMLスキーマと合わせて指定される。スキーマは進化可能だが落とし穴もあるらしい。
- RESTful APIではレスポンスにJSONを、リクエストにはJSONあるいはURIエンコード/formエンコードされたりリクエストパラメータを使うことが一般的。
- 通常は必須でないリクエストパラメータの追加やレスポンスオブジェクトの新しいフィールドの追加が互換性を保つ
組織の境界を跨ぐ通信にRPCを使う(例えばiOSアプリケーションとサーバ間とかの場合。ブラウザとサーバ間だと間にproxyサーバを置くことを推奨されてるらしい。)のは、クライアントにアップデートを強要することができないので、サーバは複数バージョンのサービスAPIを用意しておく必要がある。
RESTful APIの場合はacceptヘッダー内か、URL内にバージョン番号を使うのが一般的。
メッセージパッシングによるデータフロー
非同期のメッセージパッシングシステム。
RPCとデータベースの中間に位置する様なもので、クライアントのリクエストが低いレイテンシで送信されるという意味ではRPCに似ているし、一時的にメッセージを保存するメッセージブローカー的な動きはデータベースに似ている。
メッセージブローカーの使用には下記の様な利点がある。
- 受信側が動作してない場合に、一時的にデータをバッファしてくれるのでシステムの信頼性が増す
- 受信側のプロセスがクラッシュした場合に、メッセージブローカー側でメッセージを保存するのでメッセージが失われることを避けることが可能
- メッセージブローカーを使うことで受信側のサーバのIPアドレスやポートを知る必要がない
- ※とはいえメッセージブローカーをAZ冗長化させてエンドポイントが複数になることはあると思う。わからないけど。
- メッセージブローカーを使うことで1つのメッセージを複数の受信側に送れる
- メッセージブローカーを使うことで送信側と受信側を論理的に分離可能
- 送信側は受信側が受信したことまでは気にするけど、処理したかどうかまでは気にしない。疎結合にできる
コミュニケーションパターンは非同期。
送信側は受信側が受信したことまでは気にするけど、処理したかどうかまでは気にしない。疎結合にできる
メッセージブローカー
最近ではRabbitMQ, HornetQ, NATS, Apache Kafkaの様なOSSサービスが人気。
あるプロセスはキュー、トピックに対してメッセージ送信する。
メッセージブローカーは送信側に受信側がメッセージ受信したことを保証する。
送信側をパブリッシャ、プロデューサ、受信側をサブスクライバ、コンシューマと言ったりする。
1つのトピックに対して多くのプロデューサ、コンシューマが関わることがある。
aws sqsでも同じような言葉が使われてる。
通常メッセージブローカーは利用するデータモデルを制限しない。
メッセージは所詮バイト列なので、メッセージは任意のエンコーディングフォーマットが使用できる。
互換性はエンコーディングフォーマットが互換性を持つなら、進化性を保ったままパブリッシャとコンシューマを任意の順序で独立にデプロイ可能。
コンシューマがそのメッセージをなんやかんやして他のトピックに送信するなら、未知のフィールドの保全(古いコードが新しいコードで書かれたDBの値を読めるが、そのままDB書き込みしちゃうと追加されたフィールドが失われる件と同様)に努める必要がある。