🔥
ローカルLLMの推論速度を高速化する5つの手法と比較評価
目的
ローカルLLMの推論速度を改善する手法がいくつか報告されています。
今回は実際に報告されている5つの手法を実装して推論速度がどの程度改善するか確認します。
推論処理の高速化手法
1. torch.compile
- 計算グラフを構築
- 各演算をCPUやGPUのデバイスに特化した細かい命令に分解
- 与えられた入力に対して上記の命令を呼び出して演算を効率化
実装
モデルを読み込んだ直後にtorch.compileを追加
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="cuda",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
load_in_4bit=False,
use_cache=False,
).eval()
model = torch.compile(model)
2. flash_attention_v1
-
Scaled Dot-Product Attention(SDPA)において、queryとkeyの内積演算を複数のブロックに分割し、SRAM(Static RAM)に転送し計算を行う手法 - SDPAの適用箇所のみに限り速度2~3x, メモリ効率10~20xの改善が見込める
実装
モデル読み込み後にto_bettertransformer()に変換し、torch.backends.cuda.sdp_kernelで括った上で推論します。
def infer_flash_attn_v1(model, tokenizer):
model.to_bettertransformer()
token_ids = tokenizer.encode(
self.prompt,
add_special_tokens=False,
return_tensors="pt"
)
with torch.backends.cuda.sdp_kernel(
enable_flash=True,
enable_math=False,
enable_mem_efficient=False
):
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
temperature=0.8,
top_p=0.95,
top_k=50,
repetition_penalty=1.10,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
return tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True,
)
3. flash_attention_v1 + torch.compile
-
flash_attention_v1とtorch.compileを併用した手法
実装
def infer_flash_compile(model, tokenizer):
model.to_bettertransformer()
model = torch.compile(model)
token_ids = tokenizer.encode(
self.prompt,
add_special_tokens=False,
return_tensors="pt"
)
with torch.backends.cuda.sdp_kernel(
enable_flash=True,
enable_math=False,
enable_mem_efficient=False
):
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
temperature=0.8,
top_p=0.95,
top_k=50,
repetition_penalty=1.10,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
return tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True,
)
4. flash_attention_v2
-
flash_attention_v1の並列化とパーティショニングを行う手法 -
flash_attention_v1の適用箇所のみに限り2~3xの速度改善が見込める
実装
torch_2.2にアップグレードすることで、デフォルトのSPDAがflash_attention_v2に変更されるため、こちらで実装を代用します。新しくコードを追加することはありません。
速度を比較する場合はこちらの実装だけ仮想環境を作成し、他の手法とは別で推論速度を計測しました。
pip install --upgrade transformers
5. vLLM
-
paged_attentionを用いた手法 - OSの仮想メモリとページングの仕組みを参考
-
SDPAのkeyとvalueの値を分割してテーブルに保存しておくことで、同じトークンが再度呼び出されたときに、都度計算することなく呼び出しだけで計算を完了させる手法
実装
vllmをインストール後、推論部を以下のように書き換えます。
pip install vllm
from vllm import LLM, SamplingParams
from vllm.model_executor.parallel_utils.parallel_state import destroy_model_parallel
model = LLM(
model=model_name,
tokenizer=tokenizer_name,
dtype='float16'
)
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95,
top_k=50
)
outputs = model.generate(
self.prompt,
sampling_params
)
実験設定
- 入力文は次の文章で固定:
今日は良い天気ですね。このあとの予定は - モデル毎、高速化の手法毎に100回応答文を生成
- 応答文毎に生成時間と生成トークン数を測定し、
トークン数/生成時間で1秒あたりのトークン生成速度を算出し、100回分のトークン生成速度の平均で比較 - 全ての手法でトークン生成速度を計算し集計
- 検証モデルと高速化手法は以下
| No. | CPU | GPU | VRAM | VRAM使用量 |
|---|---|---|---|---|
| 1 | インテル® Core™ i9-10980HK (2.4GHz・Turbo 5.3GHz・8コア16スレッド) | NVIDIA GeForce RTX 3080 Laptop GPU | 16GB | 2.97GB |
| No. | モデル | パラメータ数 |
|---|---|---|
| 1 | llm-jp/llm-jp-1.3b-v1.0 | 1.3B |
| No. | 高速化手法 |
|---|---|
| 1 | なし |
| 2 | torch.compile |
| 3 | flash_attention_v1 |
| 4 | flash_attention_v1 + torch.compile |
| 5 | flash_attention_v2 |
| 6 | vLLM |
実験結果
- 計測時間: 7984.71 秒(約1.3時間)
| No. | 高速化手法 | token/second |
|---|---|---|
| 1 | なし | 44.36 |
| 2 | torch.compile | 43.60 |
| 3 | flash_attention_v1 | 48.97 |
| 4 | flash_attention_v1 + torch.compile | 65.59 |
| 5 | flash_attention_v2 | 74.76 |
| 6 | vLLM | 102.69 |
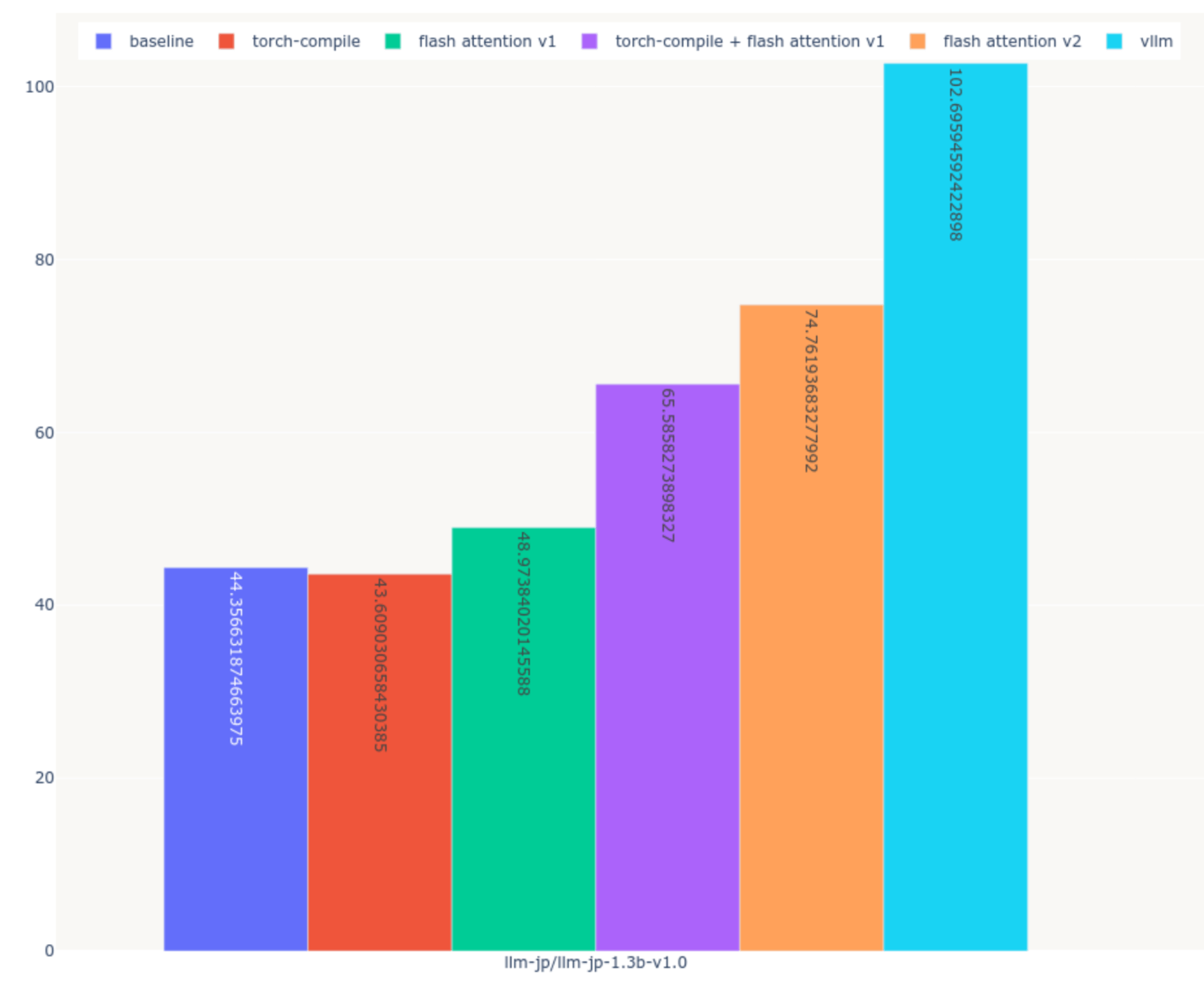
実験に対する所感
-
torch.compileを除く4つの手法で推論速度の改善が認められた。 - 5つの高速化手法のうち、特に推論速度の改善が認められたのは
flash_attention_v2とvllmの2つ - 5つの高速化手法のうち、
vllmが推論を最も高速化させる -
flash_attention_v2の74token/sもvllmの102token/sも十分に速いと判断 - 人間が1分間に話す目安と言われる文字数が約300文字
- 例えば以下の例文は319文字
コミュニケーション能力があり、傾聴力を活かして信頼を勝ち取れるのが私の強みです。
大学時代は靴屋でアルバイトをしていました。接客ではお客様とコミュニケーションを取ることも
大切な仕事なので、日頃からお客様の話を聞くことを心がけていました。
理想の商品を探しているお客様の話に耳を傾けるだけではなく、時には質問をすることで
「何を求めているのか」をお客様自身が整理しやすいようにしていました。こうした接客を
心がけていた結果、お客様に「伊藤さんに担当してもらってよかった」と言っていただくことが
できました。御社でもまずはお客様、クライアント様の話を聞き、相手が何を望んでいるかを
感じ取り、先回りして提案することで、信頼を得て活躍したいと考えています。(319文字)
- 上記の文章を
llm-jp/llm-jp-1.3b-v1.0のトークナイザーでトークン化すると187トークンとなる - 人間が
60秒で喋る文字数をllm-jp/llm-jp-1.3b-v1.0_vllmは1.83秒で生成することになる - 音声合成にかかる処理は今回は検証外のため無視すると、人より
32.78倍速い生成結果となる - 高速化しない場合は
2.87秒での生成のため、高速化により1.56倍の推論速度改善を達成
まとめ
ローカルLLMの推論速度を改善する5つの手法を紹介、実装し比較しました。今回は1.3Bパラメータと小さいモデルでの評価となりましたが、計算資源に余裕のある方はぜひより大きなモデルで高速化を検証してみてください。
高速化の手法にTensorRT_llmなるものがNVIDIAさんから公開されているようですが、Docker配布である点と、エラーが度々出て再現できなかったため比較の対象外としました。もし比較された方がいらしたらご紹介いただけると幸いです。
Discussion