PythonとAWSで並列処理最適化: パフォーマンス向上の鍵
はじめに
本記事では、AWS と Python を用いたバックエンドエンジニアにとっての関心事である、並列処理の最適な設定を検証します。具体的には、Python での並列実行において最もネットワークパフォーマンスが高まる並列数を調査します。
実験手法
AWS S3 バケット内の全ファイルを取得し、サイズを返すプログラムの実行時間を計測しました。実験環境は AWS Fargate を使用し、Thread と Process による並列処理を検証しました。詳細なプログラムは下記のコードを参照してください。
import base64
import csv
import hashlib
import logging
import threading
import time
from typing import TYPE_CHECKING, List
import boto3
import os
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
if TYPE_CHECKING:
from mypy_boto3_s3.client import S3Client
BUCKET_NAME = os.environ["BUCKET_NAME"]
RESULT_BUCKET_NAME = os.environ["RESULT_BUCKET_NAME"]
CONCURRENCY = int(os.environ["CONCURRENCY"])
ENDPOINT_URL = os.environ.get("AWS_ENDPOINT_URL")
MODE = os.environ["MODE"]
TAG = os.environ["TAG"]
thread_local = threading.local()
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
# (worker)
# 指定のキーのファイルを取得してSizeを返す
def worker(key: str):
cli: S3Client = thread_local.client
obj = cli.get_object(Bucket=BUCKET_NAME, Key=key)
length = 0
for chunk in obj["Body"].iter_chunks():
length += len(chunk)
return (key, obj["ContentLength"], length)
def _worker_init():
sess = boto3.session.Session()
thread_local.client = sess.client("s3", endpoint_url=ENDPOINT_URL)
client = boto3.client("s3", endpoint_url=ENDPOINT_URL)
is_truncated = True
param = {"Bucket": BUCKET_NAME}
keys: List[str] = []
logger.info("*** list start ***")
# バケット内の全てのKeyをリストにする
while is_truncated:
response = client.list_objects_v2(**param)
is_truncated = response["IsTruncated"]
keys += [content["Key"] for content in response["Contents"]]
param["ContinuationToken"] = response.get("NextContinuationToken", "")
logger.info("*** task start ***")
if MODE == "thread":
# マルチスレッド
RESULT_KEY = f"result_{TAG}_thread_{CONCURRENCY}.csv"
with ThreadPoolExecutor(max_workers=CONCURRENCY, initializer=_worker_init) as pool:
time_start = time.perf_counter()
result = list(pool.map(worker, keys))
time_end = time.perf_counter()
with open(RESULT_KEY, "w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow((f"Key (time = {time_end - time_start}) sec", "Size", "CalcSize"))
writer.writerows(result)
client.upload_file(RESULT_KEY, RESULT_BUCKET_NAME, RESULT_KEY)
else:
RESULT_KEY = f"result_{TAG}_process_{CONCURRENCY}.csv"
with ProcessPoolExecutor(max_workers=CONCURRENCY, initializer=_worker_init) as pool:
time_start = time.perf_counter()
result = list(pool.map(worker, keys))
time_end = time.perf_counter()
with open(RESULT_KEY, "w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow((f"Key (time = {time_end - time_start}) sec", "Size", "CalcSize"))
writer.writerows(result)
client.upload_file(RESULT_KEY, RESULT_BUCKET_NAME, RESULT_KEY)
logger.info("*** task end ***")
実験条件
以下の条件で実験を行いました。
- Fargate vCPU: 1, 2, 4
- 並列化手段: Thread, Process
- 並列数: 1, 2, 4, 8, 16
- S3 バケット: サイズ 118GB、ファイル数 46000
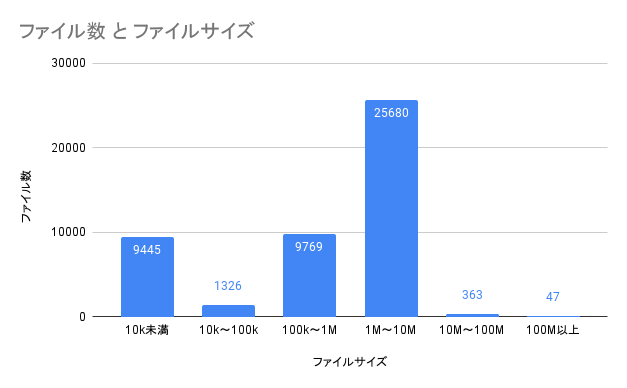
バケット内のファイル数とファイルサイズは下図のもので実験しました。
結果
検証結果を以下にまとめます。
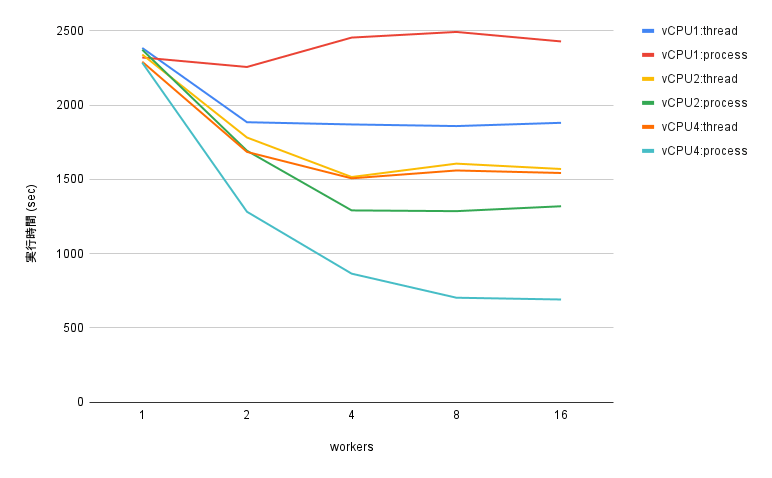
- Thread を用いた並列化
vCPU に関わらず、並列数 2 でパフォーマンス上限に達し、それ以上は横ばい - Process を用いた並列化
vCPU の 2 倍の並列数でパフォーマンス上限に到達
考察
多くの vCPU 数を使用する場合は、Process を用いた並列化が有利です。一方、少ない vCPU(1 以下)を使用する場合は、Thread を用いた並列化が有利です。Python の GIL の影響で、Thread を用いた並列化では vCPU 数の増加による恩恵を受けられないため、vCPU 数を増やす場合には Process を用いた並列化を実施するべきです。
まとめ
本記事では、Python での並列実行における最適な並列数を検証しました。実験結果から、多くの vCPU 数を使用する場合は Process を用いた並列化が優位であり、少ない vCPU(1 以下)を使用する場合は Thread を用いた並列化が優位であることが分かりました。この結果は、バックエンドエンジニアが AWS と Python を使用してパフォーマンスを最大限に引き出すための知見として役立ちます。
最後に、アダコテックはエンジニアを含め、製造業の革新に取り組んでくださる仲間を募集しています。気になるポジションがありましたら気軽にエントリーください。
Discussion