ベイズ線形回帰モデル
はじめに
線形回帰モデルをベイズ的に取り扱うベイズ線形回帰についての記事です。"ベイズ的に取り扱う" ということや、実際どのような計算を行うことで予測できるのかなどをまとめています。
問題設定
まずはじめに、線形回帰モデルとベイズ線形回帰モデルについてまとめます。
線形回帰モデル
線形回帰モデル[1]では
の形式を用いて、入力変数
ベイズ線形回帰モデル
ベイズ線形回帰モデルにとは、上述の線形回帰モデルをベイズ的に取り扱うモデルです。「ベイズ的な取り扱い」[3]についての定義は書籍によってまちまちな印象ですが、
- 事前分布
- 尤度関数
- 周辺分布
- 条件づき分布
など、パラメータやデータに関して確率的取り扱いを行うことを指すことが一般的だと思います。決定論的な予測ではなく、確率的な予測を行うのがベイズ的な取り扱いだとして以下では説明を進めてみます。
事前分布
線形回帰モデルのパラメータ
を考えます。事後分布の性質も簡単に把握するために、ガウス分布などの共役な事前分布を選ぶことが多いです。また、事前にパラメータについての知見があればそれを踏まえた分布にすることも可能です。
事後分布
線形回帰モデルの目的は得られているデータセットからモデルパラメータを推定し、未知のデータへの予測を行うことです。そのため次に、対応するパラメータの事後分布を計算します。あるデータセット
です。
パラメータの推定について
パラメータの事後分布を計算することができましたので、
の形も決まるので、未知のデータへの予測も可能になります。ただし
しかし一般的に、事後分布は解析的に評価することが困難です(数式としては表現できるが計算機での実行が難しいなど)。そこで使用されるテクニックがマルコフ連鎖モンテカルロ法(MCM法)と呼ばれる計算法であり、この計算法では任意の確率分布を定義することができます。そのため実際のベイズ的取り扱いでは必ずと言っていいほど、MCMC法がセットで登場します[4]。
補足
ベイズ線形回帰モデルでは解析的に事後分布を計算することができます。そのためMCMC法は不要ではあるのですが、例として簡単であったためベイズ線形回帰モデルの事後分布を題材に以下のMCMC法について見ていきます。
マルコフ連鎖モンテカルロ法
ベイズ推論を用いた統計解析では事後分布
を計算し、そこから値をサンプリングすることで予測などを行います。ただしニューラルネットワークなどを用いたモデルではこの事後分布
ベイズ線形回帰モデルでは解析的に事後分布の形を求めることができたのですが、一般的にはベイズ推論の枠組みでの学習時には確率計算を何らかの形で近似的に求める方法が必要となります。大きく分けて、(1)サンプリングに基づく手法、と(2)最適化に基づく手法の2パターンがあります。サンプリング手法ではマルコフ連鎖モンテカルロ法などが有名で、最適化手法では変分推論が有名です。
問題設定
ベイズ線形回帰モデルを題材として、MCMC法を用いてパラメータ推定を行ってみます。まず観測データ
を考えます。
このデータを表現するためのモデルとして、基底関数にガウス基底関数を9個用いた[5]
の形の線形モデルを考えます。ここでの目標はデータの情報
各種手法
マルコフ連鎖モンテカルロ法と一口に言っても実際の計算方法・実装方法は様々な手法があり、ここでは代表的な(簡単に実装できた)メトロポリスヘイスティングス法を紹介します。
メトロポリス・ヘイスティングス法
サンプリングを行いたい確率分布を目標分布
- 初期値
z_0 - 提案分布
q(z) z_\star - 採択確率を計算する
- 確率
\min(1, r) z_{t+1} \leftarrow z_\star z_{t+1} \leftarrow z_t
手順(2)~(4) を繰り返して得られたサンプリング結果
メトロポリスヘイスティングス法では採択確率の計算時に目標分布の比
実装
提案分布にガウス分布を用いて[7]、メトロポリスヘイスティングス法を用いてベイズ線形回帰モデルのパラメータ推定を行ってみます。まず目標分布を以下のように実装します:
def gauss(idx, x, D=9):
"""
ガウス基底関数
"""
mu = idx * (1 / (D - 1)) # 基底関数の中心を等間隔に配置
sigma = 0.1 # 全基底関数で一定
return np.exp(-0.5 * ((x - mu) ** 2) / sigma ** 2)
def target(w):
"""
目標分布
"""
D = 9
def prior(w):
"""
パラメータの事前分布
"""
mu = np.zeros(D)
sigma = np.eye(D)
coeff = 1 / (2 * np.pi * np.sqrt(np.linalg.det(sigma)))
exponent = np.exp(-0.5 * (w - mu).T @ np.linalg.inv(sigma) @ (w - mu))
return coeff * exponent
def likelihood(x_data, y_data, w):
"""
尤度関数, p(D|w)
"""
def p(x_i, y_i, w):
mu = sum(w[j] * gauss(j, x_i) for j in range(D))
sigma = 1.0 # 観測ノイズの標準偏差
coeff = 1 / (np.sqrt(2 * np.pi) * sigma)
exponent = np.exp(-0.5 * ((y_i - mu) / sigma) ** 2)
return coeff * exponent
return np.prod([p(x_i, y_i, w) for x_i, y_i in zip(x_data, y_data)])
return likelihood(x_data, y_data, w) * prior(w)
実際のメトロポリスヘイスティングス法に従ったサンプリング部分を以下のように実装します:
def metropolis_hastings(target, initial_sample, iterations):
samples = [initial_sample]
accept_count = 0
for i in range(iterations):
current_sample = samples[-1]
proposal_sample = np.random.randn(D)
accept_prob = min(1, target(proposal_sample) / target(current_sample))
if np.random.rand() < accept_prob:
samples.append(proposal_sample)
accept_count += 1
else:
samples.append(current_sample)
# print(f"Acceptance rate: {accept_count / iterations}")
return np.array(samples)
以下のように 10,000回のサンプリングを行ってみます。
D = 9
initial_sample = np.zeros(D)
iterations = 10000
samples = metropolis_hastings(target, initial_sample, iterations)
サンプリングした結果の samples は、(10001, 9) 次元のベクトルで、10001 個の線形モデルの作成・予測値の計算を行います。それらを用いることで推論結果の平均・分散を計算することができます。以下に、サンプリング結果の平均値で作成した線形モデルを実線、分散をハッチで表現してみます:
# 新しい x 値の範囲を定義
x_new = np.linspace(0, 1, 100)
# サンプリングされたパラメータを使用して y の予測値を計算
y_pred_samples = np.array([sum(w[j] * gauss(j, x_new) for j in range(D)) for w in samples])
# 予測値の平均と標準偏差を計算
y_pred_mean = np.mean(y_pred_samples, axis=0)
y_pred_std = np.std(y_pred_samples, axis=0)
# 予測分布のプロット
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(x_data, y_data, marker="o", label='Original data', facecolor="None", edgecolor="black")
ax.plot(x_new, y_pred_mean, 'r-', label='Predicted mean')
ax.fill_between(x_new, y_pred_mean - 2*y_pred_std, y_pred_mean + 2*y_pred_std, color='red', alpha=0.2, label='Predicted std deviation')
ax.legend()
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_xlim(0, 1)
ax.set_title('Bayesian Linear Model Predictions')
plt.show()
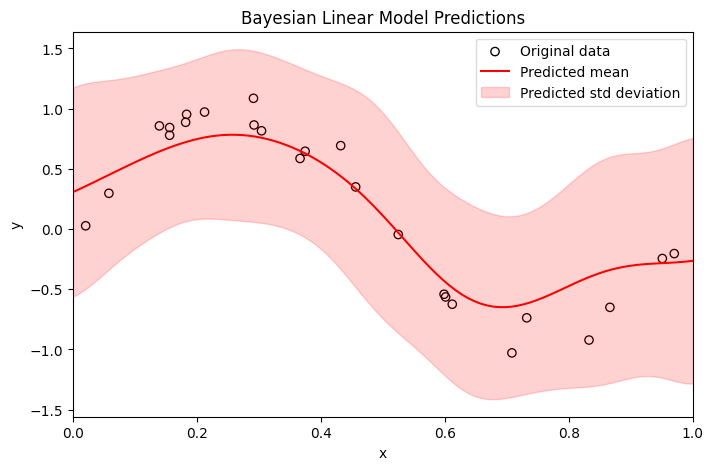
適当に実装してみたのですが、それっぽくはなっているので満足しました。雰囲気は掴めたかと思います。
その他
その他にサンプリング手法はたくさん実装されており、
- ハミルトニアンモンテカルロ法
- ギブスサンプリング
などがありました[8] 。これらの手法の違いなども、これから時間を見つけて勉強していければと思っています。
最後に
マルコフ連鎖モンテカルロ法では無限に計算を続けることができれば真の分布から得られたものと同一視できるという利点があるのですが、必要なサンプルサイズの増大によって計算コストが増大してしまうという欠点があります。そこで最近では最適化に基づく事後分布の近似手法があり、その中で変分推論法などが出てきます。変分推論なども勉強できればと思っています。
-
入力変数
x w y=w_0 + w_1x_1+... -
\rm{w} -
Bishopでは「事前分布を導入するところから、線形回帰モデルのベイズ的な取り扱いについて説明する.」との導入がありますが、確率分布を導入する部分がベイズ的な取り扱いの肝です。 ↩︎
-
ベイズ的な取り扱い = MCMC法ではなく、事後分布から直接サンプリングできないのでMCMC法を使用する、というような流れは頭に入れておきましょう。 ↩︎
-
Bishop p.155 の設定をそのまま拝借しているだけで、「ガウス基底関数を9個」用いることに特別な意味はないです。ただ個数が具体的な方がイメージが付きやすいかと思います。 ↩︎
-
ここでの例はパラメータの事後確率分布
p(\rm{w}| \rm{Y}, \rm{X}) -
よく例としてガウス分布が使われますが、問題によって一様分布を用いる場合やその他の分布を用いる場合などがあります。 ↩︎
-
「ベイズ深層学習」p.86 ↩︎
Discussion