Remix という 考え方
こんにちは、@kaa_a_zu です。今日(11/23)の日本時間早朝に React Router の制作者である @Ryan氏 と @Michael が着想した Remix V1.0 が正式リリースされました🎉
RemixがWebの世界に及ぼす影響は大きいと思っており、実際のコードやドキュメントを見ながら既存のフレームワークと何が異なっているのかを中心に書いた紹介記事です。(正直、魂が震えています)
より具体的な使い方はドキュメントを見て、手を動かしていただくのが良いかと思います。また、既に国内でも使ってみた系の記事がいくつかあるようです。
Remixの機能には様々なものがありますが、当記事では筆者がより注目しているものについて書いていきます。Remixに興味があるけど、あまり追えていないという方に読んでいただけると嬉しいです。
※この記事はGatsbyやNext.jsよりもRemixの方が良いということを伝えたいものではありません
目次
- はじめに、Remixの思想
- SSGの機能を備えていない
- ファイルシステムルーティング
- Remixにおけるステート管理
- その他
0. はじめに、Remixの思想
特徴の紹介に移る前にRemixの思想について触れておくことで、なぜそのようになっているかが分かるかと思います。詳しくはRemix Philosophyをご覧ください。
- サーバー/クライアントモデルを採用している(データを提供するサーバと、利用するクライアントとを分離するモデルのこと)
- 基盤となる技術を抽象化しないこと
- ウェブの基礎となるブラウザ、HTTP、そしてHTMLなどと共に取り組んでいく
- JavaScriptを使ってブラウザの動作をエミュレートし、UXを向上させる
この4つの思想全てが大切だとは思うのですが、中でも「サーバー/クライアントモデルの採用」が戦略的にSSGに対応していないRemixのメイン思想かなと個人的に思っています。
1. SSGの機能を備えていない
冒頭でも少しだけ触れましたが Remix は SSG(ビルドをして静的サイトとして提供する方法)の機能を備えていません。これは一見すると、昨今のフレームワークに遅れをとっているように見えてしまいます。しかしながら、それは違います。そもそもSSGがここまで一般的になった理由に立ち返ってみると、その1つはキャッシュをすることができて、CDNを通して世界中に配信できるようになったことです。しかしながら、現在世の中にあるほとんどのサービス(TwitterやInstagramなどのSNS, ECサイトなど)は、秒ごとにコンテンツデータが変わります。この動的なデータを含むサイトを静的サイトとして提供する手段として生まれたのが、ISR(必要になったタイミングでSSGをする)です。しかしながら、SSG,ISRには問題があります。例えば、(静的サイトを作るための)ビルド時間、ビルドの複雑さ、サイトの変更をするまでにラグが生じる、認証が必要なサービスには使用できないなどその他にも様々な問題があります。その背景からRemixはSSGの機能を持っていません。
ここで当然のように出てくる疑問として「毎回SSRをするってことは、パフォーマンスが悪くなるのでは?」があると思います。しかしながら、そんなことはなくRemixは別の方法でこの問題を解消しています。これには、大きく2つの方法があります。
1つ目が、分散サーバー,分散データベースをエッジで実行することです。エッジコンピューティングの代表格とも言えるCloudflareは、ユーザーの近くでコードを実行することに加えてデータベースも備えています。ユーザーの近くで全てを完結させることによって静的サイトの配信に劣らないパフォーマンスを提供することが出来ます。(※現在では、Cloudflareのみに対応しているとのことですが順次同様のエッジサービスへの対応もしていくとのことです 参照)
そもそもCloudflare並びにエッジコンピューティングについて知りたい人は、mizchiさんの記事を見るのが良いと思います。
2つ目が、ネットワーク上に送信するもの(JavaScript、JSON、CSSなどのリソース)の量を減らすことです。これについては「2. ファイルシステムルーティング」でより詳しく説明をします。
2. ファイルシステムルーティング
Webの領域を経験している方なら当たり前のように聞くようになったNext.jsですが、このNext.jsのルーティングとRemixのルーティングはディレクトリ構造に沿ってルーティングを行う(Next.jsはpagesディレクトリ、Remixはroutesディレクトリ)という点において非常に似ています。しかしながら、2つの点で大きく異なってます。
NestedRoutingのサポート
1つ目がNestedRoutingをサポートしていることです。(※これはRemixがというよりもReact Router V6の機能という方が正確かもしれません)
以下はRemixでルーティングをするためのコードです。
<Route path="/" element={<App />}>
<Route path="todos" element={<TodoList />}>
<Route path=":index" element={<TodoDetail />} />
</Route>
</Route>
Next.jsでは、各pageは完全に独立しているため、別のpageに移ると今までのコンポーネントはすべてアンマウントされ、その後で次のページのコンポーネントがマウントされます。例えば、/todos にヘッダーをレンダリングしたとします。しかし、/todos/item-1に移動すると、そのヘッダーは存在しません。この問題を回避するために、レイアウトコンポーネントなどを利用し、全てのpagesに適応するようにしていたと思います。しかし、コンポーネントは移行中にアンマウントされるので、内部の状態は失われてしまいます。例えば、ヘッダーに検索フィールドがあった場合、ユーザーがそこに入力したテキストは、ページ遷移の際に失われてしまいます。Remixの提供するNestedRouteingではこの問題が起こりません。全体に適応するレイアウトコンポーネントを作ることなく、todosのヘッダーを /todos/item-1 と共通化することが簡単に出来ます。また、NestedRouteingにはもう1つの利点があります。それは、Remixがファイル構造を知っているため、ユーザーが/todosから/todos/item-1に移動した場合に再度/todosのデータをFetchする必要がないということです。更にファイル構造を知っているということはレンダリングされうるものも知っているということです。必要なリソースを並列してダウンロードをすることができるのはこのためです。
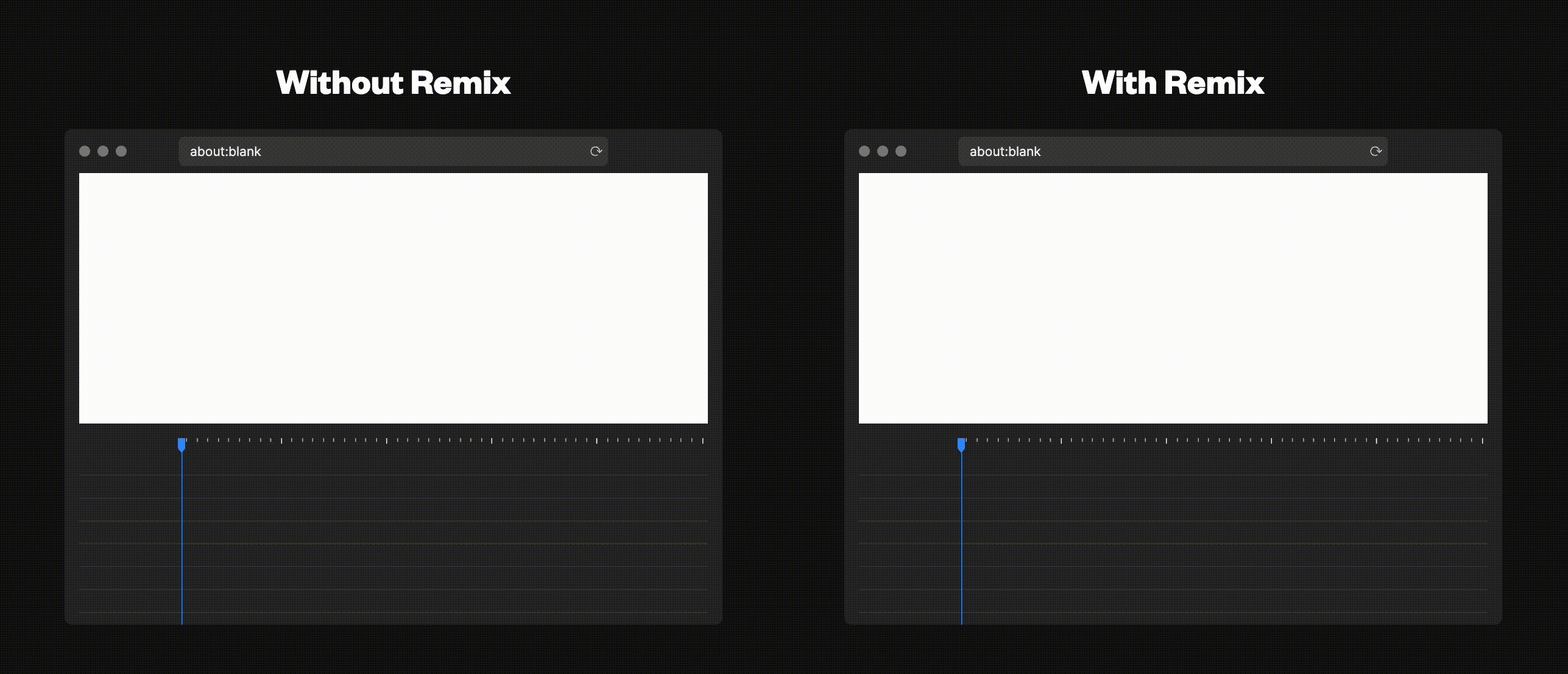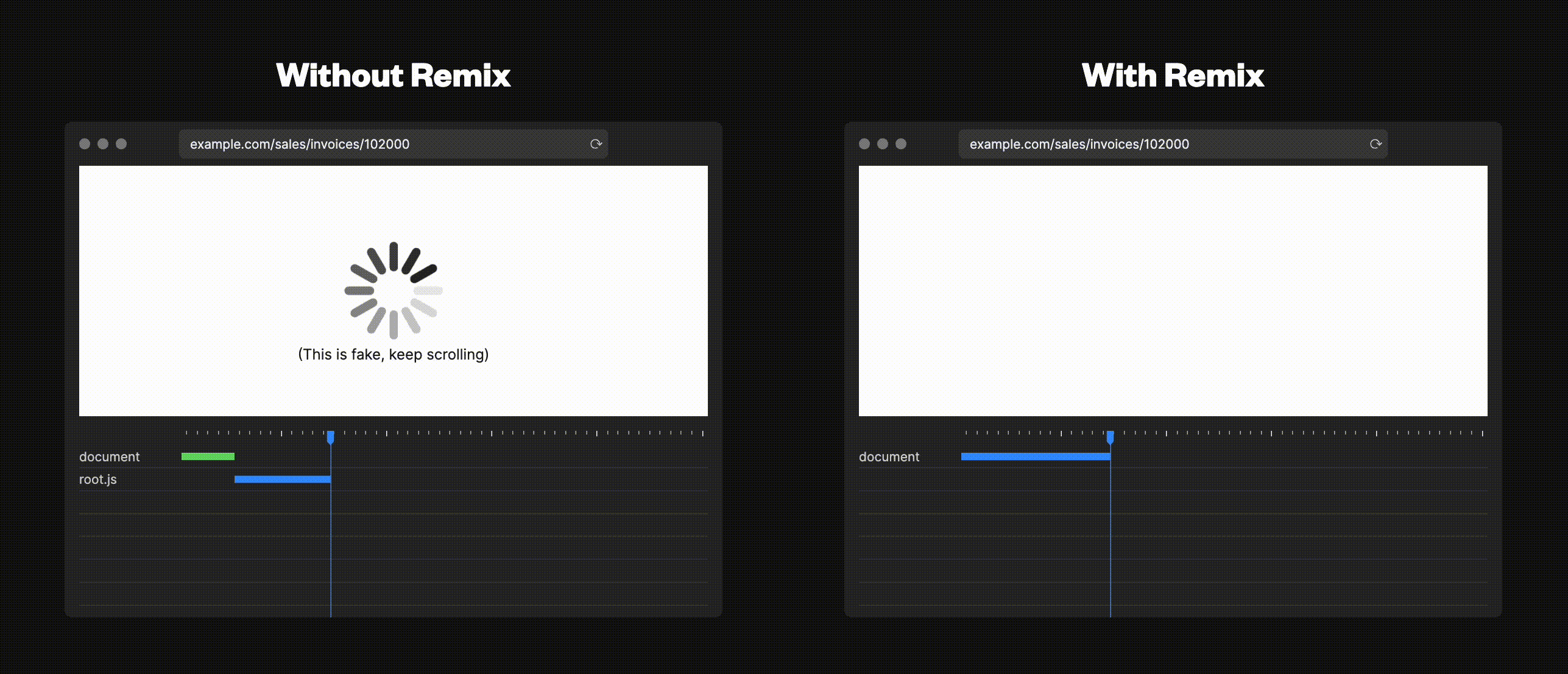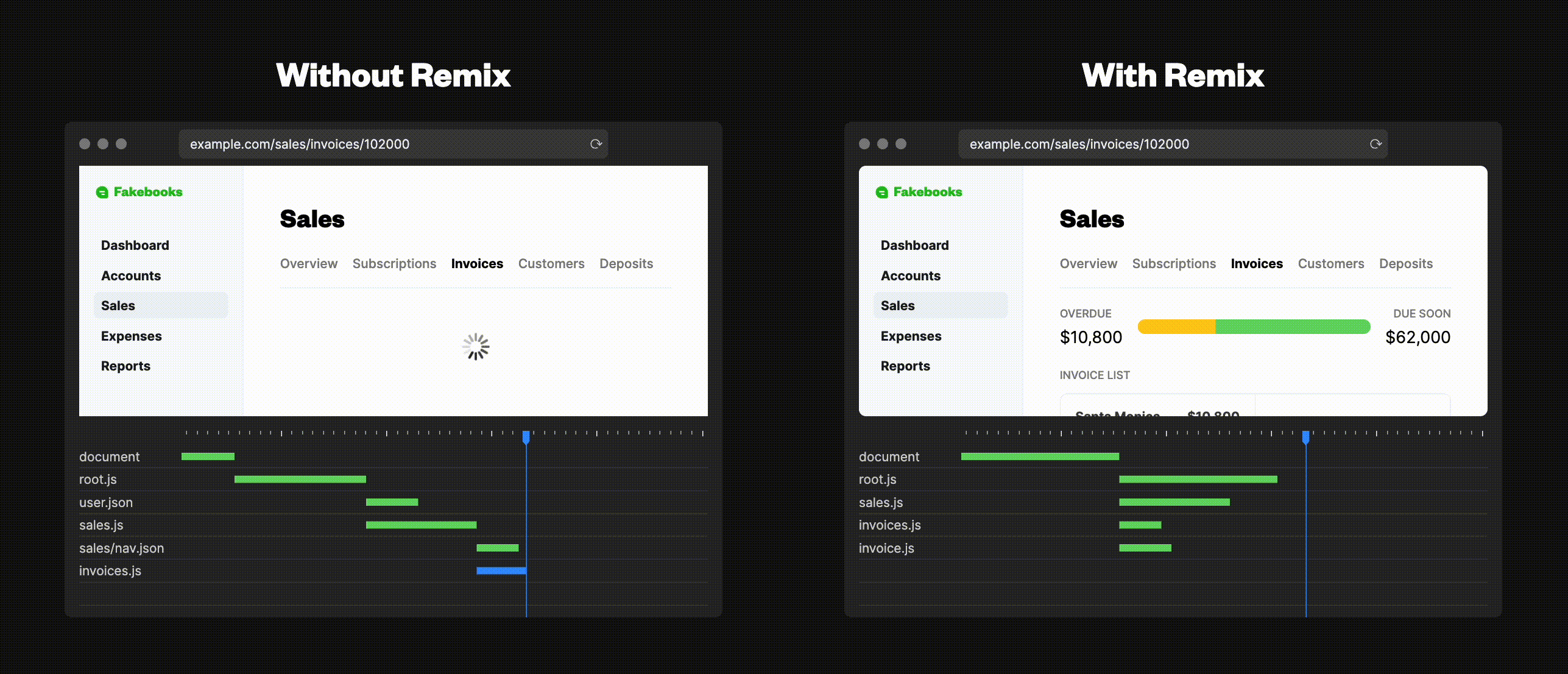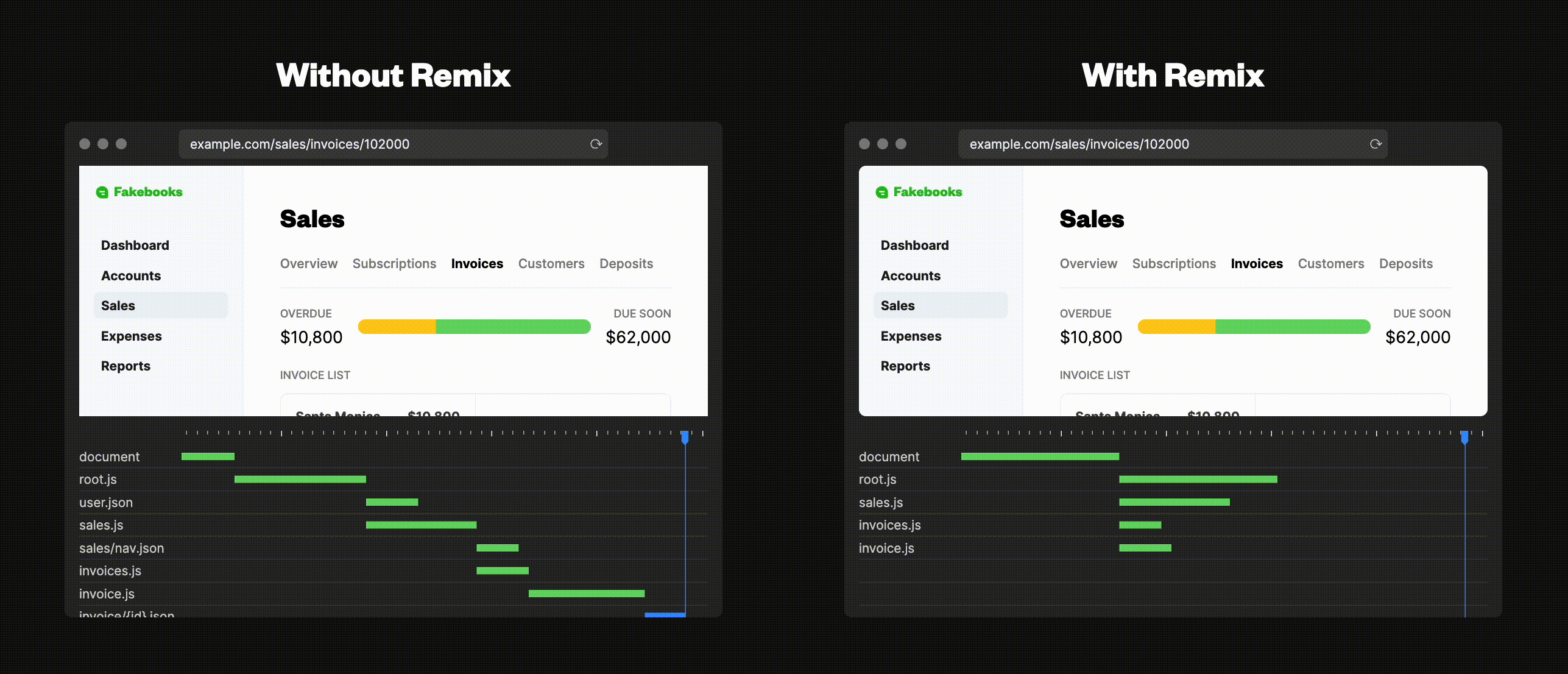 (引用元: https://remix.run/)
(引用元: https://remix.run/)
HTTPヘッダーの詳細設定
2つ目が、詳細にHTTPヘッダーを操作することができることです。Remixではルートコンポーネント毎にcache-headerを詳細に設定することができます。繰り返しになりますが、RemixはWebサイトをbuildして静的サイトとしてCDNにアップロードする機能を持っていません。代わりに、キャッシュヘッダーに依存しています。つまりCDNからしたら静的ファイルとして扱われることとほぼ同義です。これを実現させるコードは以下の通りで、headers function を定義するだけでいいのです。(キャッシュヘッダーの扱いは依然として難しいですが😅)
export function headers() {
return {
"Cache-Control": "public, max-age=300, s-maxage=3600"
};
}
export default function Component() {
/* ... */
}
より詳細についてはこちらのdocsを見てください。因みにNext.jsの getInitialProps や next.config.js でも同様にヘッダーの操作をすることが出来ます。参照
3. Remixにおけるステート管理
(11/24 01:51AM に追記)
Next.js をはじめとする、多くのReact Webフレームワークで論点となっていたことの1つにステート管理というものがありました。このステート管理には2つの文脈がありました。1つ目は状態を維持し他の場所で使うこと、2つ目はパフォーマンスをより良くすることです。そして多くのWebエンジニア達がこの問題に悩まされていたと思います。
当然、Remix における、当問題解決のためのベストプラクティを知りたくなります。こちらについてはコミュニティからも回答をいただいており、結論、従来のステート管理方法をとる必要はないとのことでした。
まず、1つ目の文脈における状態維持についてですが、/route/*内においてloader によって取得されたデータには、そのroute以下(routeのスコープ)内に限り useLoaderData()によってアクセスすることができます。この実態はuseContextになっているようです。該当コード
そのため、適切なルート設定をしてあげれば状態の維持を行うことはできそうです。
次に2つ目の文脈におけるパフォーマンスについてですが、RemixはエッジとHttp Cacheをフルに活用します。そのため、そもそも apolloが提供するような InMemoryCacheを使わなくてもパフォーマンスがでます。ただ、これは現時点での情報で、実際にプロダクトを作っていく上においてReduxやApolloなど、従来のステート管理が必要になる可能性はあります。まだ浅い技術ですので、ベストプラクティスを探していきたいです。(※現時点でもReduxやApolloなどを利用することはできます。単純にSSR対応をさせるだけなので各々のlibs doc にある対応方法を見てください。)
余談になりますが、RemixはSuspense と SuspenseCacheの機構に依存しています。SuspenseCacheはReact18から登場するキャッシュのためのステート管理機構と言うのがイメージとして正しいかと思います。この機構によりCacheにはアプリケーションのどこからでもアクセスをすることが可能になります。詳細についてはこちらのGithubをご確認してください。この機構を利用した様々なパフォーマンス向上もRemix内部で行っているようですが、当記事の本題からはそれるため、こちらは別の記事で紹介をしようと思います。
4. その他
紹介しきることはできなかったのですが、面白い機能が他にもあるので頭出しだけしておきます。
- Resource Routes: コンポーネント以外のものをルートとして設定することができる
- auto mutation: Remixが自動的にデータを再検証してくれる(≒ Postした後にFetchを明示的にしなくても良い)
- metronome: Remix用のモニタリングツール、現在はBetaとして提供されている
最後に
当記事ではRemixという新しいWebフレームワークについて紹介をしました。率直な感想として、プロダクトに使ってみたいという気持ちとWebフロントエンドの領域が再度慌ただしくなってきてヤバいという気持ちがあります(笑) Remixの思想はSSGが普遍化したからこそ生まれたものだと感じていて、依然としてSSG/ISRの有用性は高いと思っています。各々の作りたいプロダクトにあう技術の選定がより大事だとひしひしと感じた勤労感謝の日でした。
ここまで読んでくださり、ありがとうございました。試しながら記事を書いたのですが、誤った記述がいくつかあるかもしれません。ご指摘をいただけると助かります🙌
Discussion
やってみて2つの疑問が生じました。ご存知の方がいましたら教えていただけると助かります。
①Router-Based Caching と B/F Cache の棲み分け
RemixはReactのSuspenseCache に依存しています。そのキャッシュキーとなるのは 「ルート+ロケーション」です。これにより、テキスト入力中に誤って別のページに遷移してしまってもブラウザバックをすることで編集中のテキストを保持できるようになっています。つまり HTTP/1.1 Section 13.13 に準拠していると言えます。
疑問なのは B/FCacheとRouter-Based Cacheの棲み分けについてです。Chrome97で主要ブラウザのB/FCache対応が全て完了したように思えますが、RemixのいうこれはB/FCacheと違う、もしくはより上位の何かを提供してくれるものなのでしょうか?ご存知の方がいたら教えてください。
②Remix における Redux, ApolloなどによるState管理
@adwd118氏 とディスカッションをしましたが、Remixにおけるステート管理について、良い方法があまりわかっていません。キャッシュを駆使するためパフォーマンス文脈でのState管理をしないのがRemix Way なのでしょうか?
②について、11/24 01:51AM にコミュニティから回答をいただき、記事への追記をしました。
Next.jsの公式の通りにレイアウトコンポーネントを組めば、共通のヘッダー要素をもたせることができ、且つ状態も維持できます。Devツールで確認する限りは、再レンダリングもされていないようです。
「はじめに」で挙げている思想の二番目について、「基盤となる技術を抽象化しないこと」と訳されていますが、これだと意味が通らなくなってしまうと思います(抽象化こそ、Remix などのフレームワークが担う役割であるため)。原文では
と書かれていますので、直訳的にするなら「基盤となる技術を抽象化しすぎない」のように、またやや意訳するなら「適切なレベルの抽象化をおこなう」のようになるはずです。このように理解しないと、その他の思想との関係も見えなくなってしまいます(Server/Client Model も抽象化の選択の一つでありますし、HTTP 通信に関わる API をどの程度露出させるべきかなどの話も同じことです)。また、これは原文に書かれていないことであるため想像に過ぎませんが、「他のフレームワークが抽象化を過剰におこなっており、Remix はそれらとは一線を画す」という宣言であるとも読め、その意味でも重要であると感じます。
ちょっと突っ込みのような体になってしまい申し訳ありませんが、原文をチェックしない読者に誤った情報を提供することになるのでは、と危惧したため、コメントさせていただきました。誤訳の訂正と、タイトルだけでなく各思想がどのように関連しているかを補足すると、より素敵な記事になると思います!