【解説つき】OpenAI Agents SDK, Responses APIでAIエージェント作成
OpenAIが新たにAIエージェント作成のためのツールである、Agents SDKを発表しました。
今までAIエージェントを作成する際は、LangGraphなどの学習コストの高いライブラリ使っての構築が必要でしたが、OpenAI自ら作成したツールという点でより簡単に作成できるようになりました。
↓公式発表
この記事でやること
日本語でのコメント付きで、Agents SDKのクイックスタートを丁寧に実施します。
この記事を実施してもらうことで、以下の機能について確認できます。
- AgentのHandoff(タスク割り振り)
- Input Guardrails(不適切な入力の検知)
- build-in-toolsのWeb searchの機能(Agentでweb検索を元に回答させる)
- traceで実行結果の確認
Responses APIとは
新たに発表されたOpenAIのチャットを呼び出すAPIです。
以前はChat Completions APIを使っていましたが、現在はResponses APIが推奨になりました。
client.responses.createと書きます。
新機能として、build-in-toolsがあります。
最も使いそうなものを例とすると、web検索機能をAPIから使えるようにWeb searchがあります。これまでは別途検索用のTavilyなどのAPIを経由するのが標準的でしたが、標準ツールとして提供されました。
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4o",
tools=[{"type": "web_search_preview"}],
input="What was a positive news story from today?"
)
print(response.output_text)
また、この記事内では言及しませんが、会話履歴がサーバー側で保存されるようになった点も大きな変更です。
OpenAI Agents SDKとは
OpenAIが提供したAIエージェントを構築するためのSDKです。これを使うとLLMへの単純なリクエストに比べて、より高度なLLMアプリケーションを構築できるようになります。
具体的には、ユーザーの依頼内容に応じた子エージェントLLMの使い分け、出力結果によるフロー分岐、複数のツールの使い分け、条件を満たすまでのループ動作などを実装できます。
(類似のAIエージェント構築のツールとしては、LangGraphというフレームワークが有名です。)
以前はSwarmという名称でリリースされており、それの進化版です。
Responses APIを利用することを想定しています。非推奨ではありますが、Chat Completions APIでも利用可能です。
コード全文
この公式Quickstartをベースに、一部分かりやすく改変しています。
ディレクトリを作り、仮想環境を作ります。
mkdir my_project
cd my_project
python -m venv .venv
仮想環境をアクティベートします。
source .venv/bin/activate
Agents SDKをインストールします。
pip install openai-agent
.envを作成してAPIキーを書き込みます。
OPENAI_API_KEY=sk-...
homework_agents.pyを作成します。
コードは長いのでアコーディオンに格納しています。
homework_agents.pyのコード
# 必要なモジュールのインポート
from agents import Agent, InputGuardrail,GuardrailFunctionOutput, Runner, WebSearchTool, set_default_openai_key
from pydantic import BaseModel # データバリデーション用のベースクラス
import asyncio # 非同期処理のためのモジュール
import os
# .envファイルの読み込み
from dotenv import load_dotenv
load_dotenv()
# OpenAI APIキーの取得と設定
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEYが設定されていません")
# デフォルトのAPIキーを設定(LLMリクエストとトレース機能の両方に使用)
set_default_openai_key(api_key, use_for_tracing=True)
# 宿題の出力を定義するPydanticモデル
# このモデルは、ガードレールエージェントの出力形式を定義します
class HomeworkOutput(BaseModel):
is_homework: bool # True: 宿題関連の質問, False: 宿題以外の質問
reasoning: str # エージェントが判断した理由を格納する文字列
# ガードレールエージェントの定義
# このエージェントは入力された質問が宿題に関連するものかどうかを判断します
guardrail_agent = Agent(
name="ガードレールチェック",
instructions="ユーザーが宿題について質問しているかどうかを確認する。",
output_type=HomeworkOutput, # 出力はHomeworkOutputモデルに従う必要がある
)
# ガードレール機能の実装
# この関数は入力された質問が適切かどうかをチェックします
async def homework_guardrail(ctx, agent, input_data):
# ガードレールエージェントを実行して入力を評価
result = await Runner.run(guardrail_agent, input_data, context=ctx.context)
final_output = result.final_output_as(HomeworkOutput) # 出力をHomeworkOutput型にする
# ガードレールの判定結果を返す
return GuardrailFunctionOutput(
output_info=final_output, # 判定の詳細情報
tripwire_triggered=not final_output.is_homework, # 宿題でない場合はトリガーを発動してブロック
)
# 数学専門のチューターエージェント
math_tutor_agent = Agent(
name="数学専門エージェント",
handoff_description="数学の質問を専門とするエージェント", # トリアージエージェントが振り分けを判断する際に使用
instructions="数学の問題のサポートを提供します。各ステップでの理由を説明し、例を含めます", # エージェントの行動指針
)
# 歴史専門のチューターエージェント
history_tutor_agent = Agent(
name="歴史専門エージェント",
handoff_description="歴史に関する質問を専門とするエージェント", # トリアージエージェントが振り分けを判断する際に使用
instructions="歴史に関する質問のサポートを提供します。重要な出来事と背景を明確に説明します。なお、回答の際は必要であればウェブ検索をして根拠となる情報を添付して。", # エージェントの行動指針
tools=[WebSearchTool()] # ウェブ検索ツールを使用可能にする
)
# メインの振り分け(トリアージ)エージェント
# 質問の内容に応じて適切な専門エージェントに振り分けを行います
triage_agent = Agent(
name="トリアージエージェント",
instructions="ユーザーの宿題の質問に基づいて、どのエージェントを使用するかを判断します。",
handoffs=[history_tutor_agent, math_tutor_agent], # このエージェントが振り分け可能な専門エージェントのリスト
input_guardrails=[
InputGuardrail(guardrail_function=homework_guardrail), # 入力チェックのガードレールを設定
],
)
# メインの実行関数
# 実際のエージェントの動作をテストします
async def main():
# テストケース1: 歴史の質問
# これは歴史チューターエージェントに振り分けられるはずです
try:
result = await Runner.run(triage_agent, "アメリカ合衆国の初代大統領は誰ですか?")
print(result.final_output)
except Exception as e:
print(f"エラー: {e}")
# テストケース2: 宿題ではない一般的な質問
# これはガードレールによってブロックされるはずです
try:
result = await Runner.run(triage_agent, "人生とは何ですか")
print(result.final_output)
except Exception as e:
print(f"エラー: {e}")
# テストケース3: 歴史かつweb検索が必要な質問
# これは歴史チューターエージェントに振り分けられるはずです
try:
result = await Runner.run(triage_agent, "現代日本の歴史についての質問です。東京タワーの建設経緯について根拠のURL付きで教えて")
print(result.final_output)
except Exception as e:
print(f"エラー: {e}")
# メイン関数を実行
if __name__ == "__main__":
asyncio.run(main())
コードの解説
大まかな流れ
- 質問が宿題に関係があるかを判定
- 関係がある場合は、質問が数学 or 歴史の話でエージェントに割り振り
- 歴史の話の場合web検索が要るかどうかを判定
- web検索が要る場合はWebSearchTool()を使って検索内容に基づいて回答を作成

- web検索が要る場合はWebSearchTool()を使って検索内容に基づいて回答を作成
モジュールのインポート
WebSearchTool, set_default_openai_keyなどの元々のクイックスタートにはないツールのimportもしています。
# 必要なモジュールのインポート
from agents import Agent, InputGuardrail,GuardrailFunctionOutput, Runner, WebSearchTool, set_default_openai_key
from pydantic import BaseModel # データバリデーション用のベースクラス
import asyncio # 非同期処理のためのモジュール
import os
APIキーを設定(LLM, トレース機能)
set_default_openai_key(api_key, use_for_tracing=True)を設定しておかないと、トレース機能が動作せず、Dashborad上で処理結果の確認ができません。
↓トレース機能の結果

# .envファイルの読み込み
from dotenv import load_dotenv
load_dotenv()
# OpenAI APIキーの取得と設定
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEYが設定されていません")
# デフォルトのAPIキーを設定(LLMリクエストとトレース機能の両方に使用)
set_default_openai_key(api_key, use_for_tracing=True)
なお、Azure OpenAI Serviceのキーでも動作することを確認しました。
ガードレールエージェントの定義
Guardrails(ガードレール)とは、AIエージェントがユーザーからの入力を処理する際に、不適切な内容を事前または事後に検出して処理を中断するための仕組みです。
これを挟んでおくことで、後段に複雑なエージェントを組んだ際に、関係のないリクエストを大量に送られてAPI利用料金が跳ね上がることを防げます。
後ほど説明するトリアージエージェントの中でinput_guardrails=[]にhomework_guardrail関数を設定することで、最初に入力内容が適切かのチェックを行えます。
今回は使っていませんが、同様にoutput_guardrails=[]を定義することで、出力内容が適切かどうかのチェックも行えます。
出力形式の型と、判定基準を書きます。
例えば、宿題に全く関係のない質問をガードレールエージェントに送るとこのような結果が返ってきます。
{
"is_homework": false,
"reasoning": "The question is philosophical and open-ended, often explored for personal reflection or discussion, rather than related to homework or academic tasks."
}
# 宿題の出力を定義するPydanticモデル
# このモデルは、ガードレールエージェントの出力形式を定義します
class HomeworkOutput(BaseModel):
is_homework: bool # True: 宿題関連の質問, False: 宿題以外の質問
reasoning: str # エージェントが判断した理由を格納する文字列
# ガードレールエージェントの定義
# このエージェントは入力された質問が宿題に関連するものかどうかを判断します
guardrail_agent = Agent(
name="ガードレールチェック",
instructions="ユーザーが宿題について質問しているかどうかを確認する。",
output_type=HomeworkOutput, # 出力はHomeworkOutputモデルに従う必要がある
)
# ガードレール機能の実装
# この関数は入力された質問が適切かどうかをチェックします
async def homework_guardrail(ctx, agent, input_data):
# ガードレールエージェントを実行して入力を評価
result = await Runner.run(guardrail_agent, input_data, context=ctx.context)
final_output = result.final_output_as(HomeworkOutput) # 出力をHomeworkOutput型にする
# ガードレールの判定結果を返す
return GuardrailFunctionOutput(
output_info=final_output, # 判定の詳細情報
tripwire_triggered=not final_output.is_homework, # 宿題でない場合はトリガーを発動してブロック
)
質問回答用の専門エージェントを作成
今回は2つの専門エージェントを用意します。これらは上位エージェントからのhandoff、つまりタスク振り分けによってタスクを処理します。
なお、歴史専門のエージェントには、tools=[WebSearchTool()]としてResponses APIのbuild-in-toolsの一つであるweb検索のツールを設定しています。
# 数学専門のチューターエージェント
math_tutor_agent = Agent(
name="Math Tutor",
handoff_description="数学の質問を専門とするエージェント", # トリアージエージェントが振り分けを判断する際に使用
instructions="数学の問題のサポートを提供します。各ステップでの理由を説明し、例を含めます", # エージェントの行動指針
)
# 歴史専門のチューターエージェント
history_tutor_agent = Agent(
name="History Tutor",
handoff_description="歴史に関する質問を専門とするエージェント", # トリアージエージェントが振り分けを判断する際に使用
instructions="歴史に関する質問のサポートを提供します。重要な出来事と背景を明確に説明します。なお、回答の際は必要であればウェブ検索をして根拠となる情報を添付して。", # エージェントの行動指針
tools=[WebSearchTool()] # ウェブ検索ツールを使用可能にする
)
上位エージェント(トリアージエージェント)を設定
このエージェントは質問内容を解釈して、専門エージェントにタスクを振り分けます。
利用可能なエージェントはhandoffs=[]に記載します。
また、input_guardrails=[]に先に定義しておいたhomework_guardrail関数を設定することで、トリアージエージェントが呼び出される前にガードレールエージェントが実行されます。
# メインの振り分け(トリアージ)エージェント
# 質問の内容に応じて適切な専門エージェントに振り分けを行います
triage_agent = Agent(
name="トリアージエージェント",
instructions="ユーザーの宿題の質問に基づいて、どのエージェントを使用するかを判断します。",
handoffs=[history_tutor_agent, math_tutor_agent], # このエージェントが振り分け可能な専門エージェントのリスト
input_guardrails=[
InputGuardrail(guardrail_function=homework_guardrail), # 入力チェックのガードレールを設定
],
)
呼び出し
result = await Runner.run(triage_agent, "アメリカ合衆国の初代大統領は誰ですか?")
の形で呼び出せます。
# メインの実行関数
# 実際のエージェントの動作をテストします
async def main():
# テストケース1: 歴史の質問
# これは歴史チューターエージェントに振り分けられるはずです
try:
result = await Runner.run(triage_agent, "アメリカ合衆国の初代大統領は誰ですか?")
print(result.final_output)
except Exception as e:
print(f"エラー: {e}")
# テストケース2: 宿題ではない一般的な質問
# これはガードレールによってブロックされるはずです
try:
result = await Runner.run(triage_agent, "人生とは何ですか")
print(result.final_output)
except Exception as e:
print(f"エラー: {e}")
# テストケース3: 歴史かつweb検索が必要な質問
# これは歴史チューターエージェントに振り分けられるはずです
try:
result = await Runner.run(triage_agent, "現代日本の歴史についての質問です。東京タワーの建設経緯について根拠のURL付きで教えて")
print(result.final_output)
except Exception as e:
print(f"エラー: {e}")
# メイン関数を実行
if __name__ == "__main__":
asyncio.run(main())
実行&結果の確認
今回は3つのテストケースを実行しています。
Traceについて
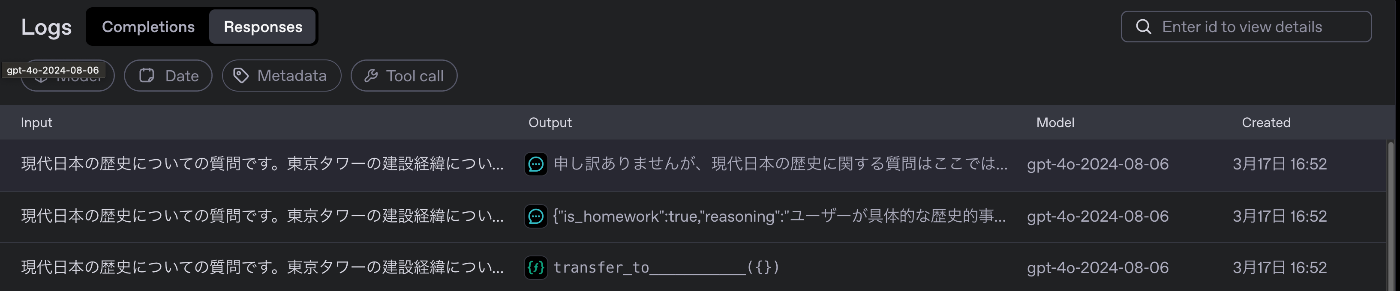
OpenAI PlatformのDashboard上から実行結果を確認できます。
一覧で確認できます。

詳細な実行結果の流れを確認できます。

テストケース① アメリカ合衆国の初代大統領について聞く
質問:アメリカ合衆国の初代大統領は誰ですか?
想定通り、歴史の宿題だと認識してHistory_agentsに割り振りされて、回答が得られています。
アメリカ合衆国の初代大統領はジョージ・ワシントンです。彼は1789年から1797年まで大統領を務めました。ワシントンはアメリカ独立革命の指導者の一人であり、合衆国憲法の成立にも重要な役割を果たしました。

テストケース② 宿題と全く関係ない質問をする
質問:人生とは何ですか
ガードレールチェックで、宿題と関係ない内容であるとしてストップがかかりました。
エラー: Guardrail InputGuardrail triggered tripwire
テストケース③ 宿題かつweb検索が必要な質問をする
質問:現代日本の歴史についての質問です。東京タワーの建設経緯について根拠のURL付きで教えて
History_agentsへの割り振りが行われ、その中でResponses APIの新機能である、WebSearchToolが実行されて、URL付きで回答できています。
東京タワーは、1958年(昭和33年)に完成した高さ333メートルの自立式鉄塔で、日本の戦後復興と高度経済成長の象徴として知られています。
**建設の背景と経緯**
1950年代、日本ではテレビ放送が急速に普及し、各放送局が独自の電波塔を建設していました。しかし、電波の混信や受信環境の悪化が問題となり、これを解決するために共同の電波塔として東京タワーの建設が計画されました。 ([mugenzatugaku.kodomonogimon-otonamogimon.com](https://mugenzatugaku.kodomonogimon-otonamogimon.com/seikatu-8/?utm_source=openai))
設計は「耐震構造の父」と称される内藤多仲氏が担当し、エッフェル塔をモデルにしつつも、日本の耐震技術を取り入れた独自の構造となっています。 ([waseda.jp](https://www.waseda.jp/top/news/65272?utm_source=openai))
〜〜〜省略〜〜〜

注意点
いくつか引っかかったポイントがあるのでまとめます。
エージェントのnameを日本語にするとうまく割り振りされなかった
私がコードを日本語化した際に、nameを数学チューター, 歴史チューターのように日本語で設定すると、なぜかどんな質問をしても必ず数学エージェントに割り振りされてしまいました。
元々の"Math Tutor", "History Tutor"に戻るとうまく動作しました。
もしかすると日本語でもうまく動作するパターンもあるのかもしれませんが、英語で指定する方が無難だと思います。
# 数学専門のチューターエージェント
math_tutor_agent = Agent(
name="Math Tutor",
handoff_description="数学の質問を専門とするエージェント", # トリアージエージェントが振り分けを判断する際に使用
instructions="数学の問題のサポートを提供します。各ステップでの理由を説明し、例を含めます", # エージェントの行動指針
)
# 歴史専門のチューターエージェント
history_tutor_agent = Agent(
name="History Tutor",
handoff_description="歴史に関する質問を専門とするエージェント", # トリアージエージェントが振り分けを判断する際に使用
instructions="歴史に関する質問のサポートを提供します。重要な出来事と背景を明確に説明します。なお、回答の際は必要であればウェブ検索をして根拠となる情報を添付して。", # エージェントの行動指針
tools=[WebSearchTool()] # ウェブ検索ツールを使用可能にする
)
model_settings.DEFAULT_MODELは特に設定場所がない
↓この記事にはmodel_settings.DEFAULT_MODELにデフォルトのモデルの設定があるとされているのですが、設定箇所を見つけられませんでした。
なお、デフォルトモデルはgpt-4o-2024-08-06が使われているようです。
私と同じ話をしている人を見つけました。
参考
Discussion