OpenAI Agents SDKのエージェントの実装の種類(agent_patterns)について解説する
エージェントの実装パターン
以下のgithubのサンプルについて解説する。
決定論的フロー(Deterministic flows)
タスクを複数の小さなステップに分割して事前にコード上で定義しておき、それぞれをエージェントに処理させる方法。前のエージェントの出力が次のエージェントの入力となる。
上位エージェントが動的に振り分けをしているわけではなく、事前に定義したフローチャートに従って実行される。分岐の部分は実質的にif文。
例:物語作成 → ①概要生成 → ②本文生成 → ③エンディング生成
サンプルファイル:deterministic.py
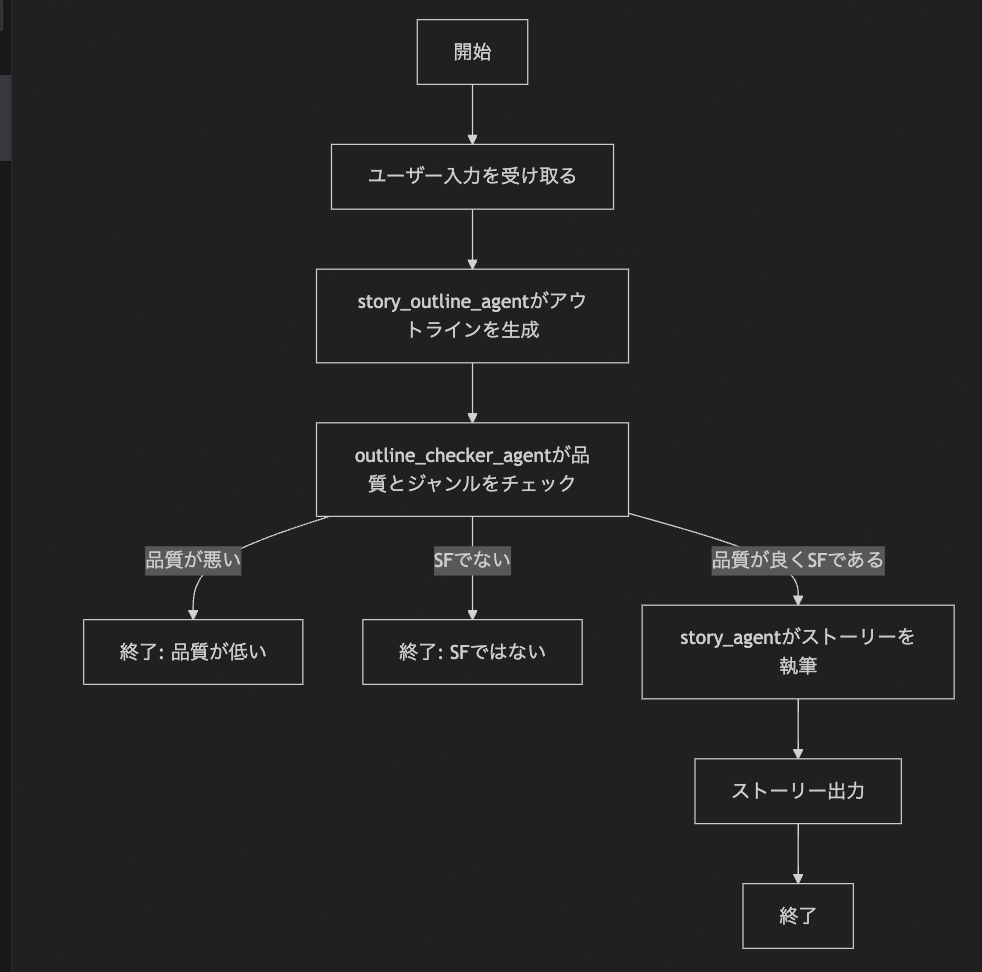
「food」について作らせて、品質チェックが通らずに終了した場合

ハンドオフとルーティング(Handoffs and routing)
特定のタスクを処理する専門エージェントが複数存在する場合、最初に受付を行うエージェントが、タスクを適切な専門エージェントへ渡す(ハンドオフ)方法。
Agents as toolsと違って、主導権は完全に専門エージェントに渡るため、上位エージェントに結果が戻らない。
例:最初の受付エージェントが、依頼内容の言語に基づいて専門のエージェントへ引き渡す
サンプルファイル:routing.py

ツールとしてのエージェント(Agents as tools)
エージェント同士の会話の主導権を完全に渡すのではなく、一時的に別のエージェントをtoolとしてのように使い、その結果を元のエージェントに返す方法。
Handoffs and routingと違って、主導権は上位エージェントのままなので、toolとして専門エージェントを呼び出した後は上位エージェントに結果が戻り、その結果を踏まえて次の処理が決定される。
例:翻訳タスクを、専門エージェントに完全に任せるのではなく、複数の言語を同時に翻訳処理させ、その結果を上位エージェントが利用する
サンプルファイル:agents_as_tools.py
オーケストレーターエージェントは複数の翻訳タスクがあることを理解して、それぞれのタスクをtoolを使って処理して結果を受け取る。その後に結果を別で定義した統合エージェント(結果をまとめるエージェントお)が最終結果を作る。
注意点としては、このコードでは最終結果をまとめるエージェントはオーケストレーターエージェントから呼び出されているのではなく、コード上で呼び出しされている。
(Handoffs and routingではなく、Deterministic flowsの処理)
Hi! What would you like translated, and to which languages? おはようをスペイン語、こんにちはをフランス語、おやすみをイタリア語にして
Final response:
正しい翻訳です:
- 「おはよう」をスペイン語で: **Buenos días**
- 「こんにちは」をフランス語で: **Bonjour**
- 「おやすみ」をイタリア語で: **Buona notte**


作成中
図はありませんが、一旦日本語の解説の部分だけ公開しておきます。
ジャッジとしてのLLM(LLM-as-a-judge)
LLMは、別のLLMからフィードバックをもらうことで、生成物の品質を向上できることがある。例えば、小さいLLMで生成したアウトラインに対し、別の大きなLLMが評価・フィードバックを行い、それを元に改善を繰り返すという手法。
評価LLMの審査に合格するまで、何度も繰り返しタスクを実行させる。
例:物語のアウトライン作成 → 評価 → 改善の繰り返し
サンプルファイル:llm_as_a_judge.py
並列化(Parallelization)
複数のエージェントを並列で動かすことで、速度向上や品質改善(最適な回答の選定など)を行う方法。
例:複数の翻訳エージェントを同時に実行し、最もよい翻訳を採用する
サンプルファイル:parallelization.py
ガードレール(Guardrails)
エージェントへの入力が適切かどうかを検証し、不適切な場合に即座に処理を停止する仕組み。
入力以外にも、出力が適切かどうかのチェックもできる。自身でガードレールエージェントのプロンプトを設定できるため、倫理基準の違反など以外にも、表現が適切かどうかの判定などにも使える。
例:顧客サポートエージェントに数学問題の質問が来た場合にすぐ拒否する仕組み。
高速モデルを使った入力検証(ガードレール)と、低速モデルを使った本来の処理を並列化し、高速な検証が不適切な入力を即座に止めることで処理時間を短縮することが可能。
サンプルファイル:input_guardrails.py, output_guardrails.py
Discussion