海外スタートアップの資金調達情報をスクレイピングで収集・ChatGPTで要約する





はじめに
業務として海外のスタートアップの資金調達についての情報をまとめることになりました。
- 100件〜200件程度
- 結果はnotionに記載
- 特にpreseed,seedについての情報がほしい
- 公開日時やスタートアップの公式サイトなどの基本情報を取得する
- そのスタートアップのサービスが解決している課題を簡単にまとめる
- 期限は1週間
一つ一つ検索し、英語を読み込みこみ、自力でまとめていくと時間的に間に合いません。
退屈なことはPythonにやらせたい、、、
そこで、日本でいうPR timesのような海外のサイトを見つけて、プレスリリースを収集させて、ChatGPTに要約させることにしました。
その手順についてチームへの共有を兼ねて簡単にまとめています。
エラー等で作業が中断しても復帰しやすいように、各ステップで毎回中間ファイルとしてデータを出力させています。
step0 サイトの選定
GlobeNewswireというサイトが最も適していました。
複数の条件で絞り込んだ検索ができるからです。
今回は、国を絞らない、English、seed、2023年1月1日〜2024年4月30日、Financial Agreementsで検索しました。
私の探した範囲ではスクレイピングについて禁止事項等の記載はありませんでしたが、見落としている可能性もありますので、以下は各自の責任の上実施してください。

なお実際に取得した結果を確認したところ、「seed」で検索したとしても、プレスリリースの文章内に「seed」の文字が含まれていると、サービス自体がシリーズAだとしても検索結果に引っかかってしまいます。
後々投資ラウンドごとに分ける必要があります。
わかりやすい例として、以下の記事では記事タイトルからして明らかにシリーズAのサービスですが、本文にseedの文字列が含まれているために、検索結果に表示されています。

step1 一覧ページのスクレイピング
まずは一覧ページから、記事タイトルとそのURLを取得しましょう。
Chromeの開発者モードで確認すると、data-section属性の値が"article-url"であるすべての'a'タグを抽出すれば良いとわかります。
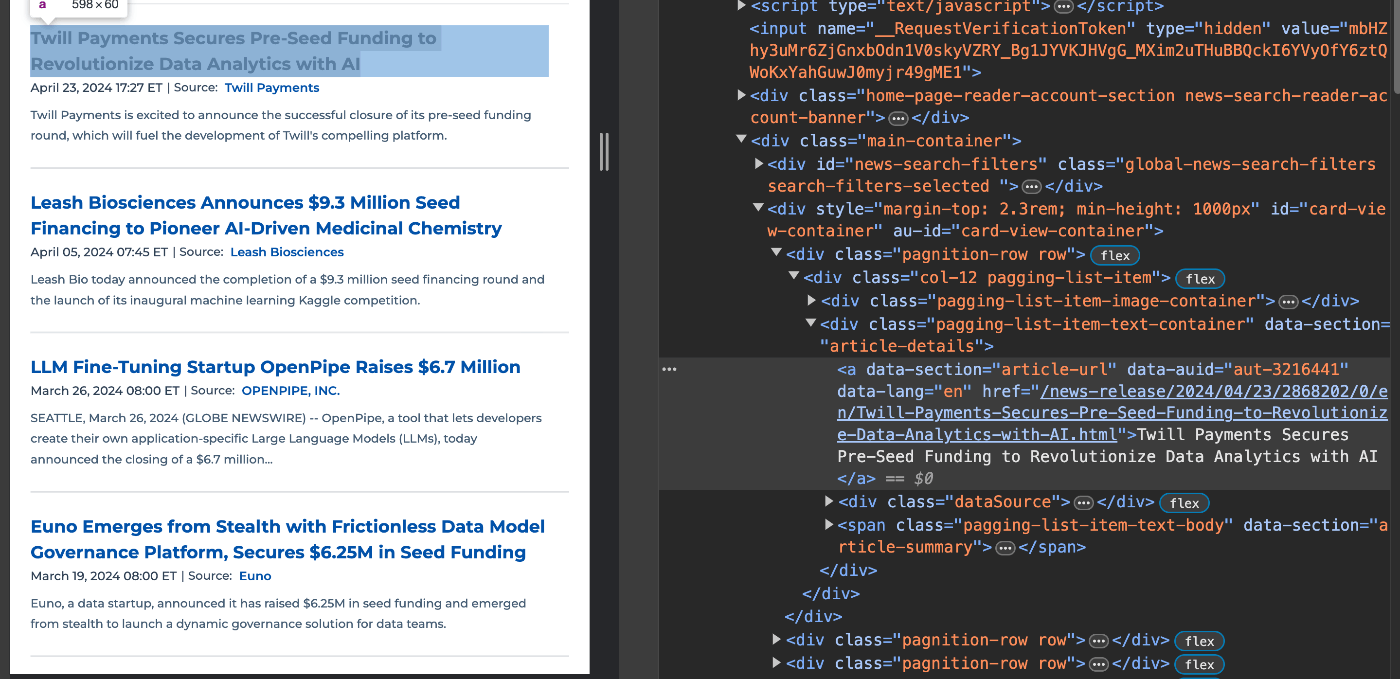
必要なライブラリをインストールしてください。
pip install beautifulsoup4
pip install requests
page_numberで一覧ページのページ数を変更できます。
今回はpage_numberを変更して2回実行し、1ページ目と2ページ目のcsvを取得しました。
1ページ50件の表示なので、合計100件です。
(本来はforループでこの辺りも自動化すべきですが、横着しました。)
import requests
from bs4 import BeautifulSoup
import csv
from datetime import datetime
def scrape_page(url, page_number):
# URLにページ番号を追加
url_with_page = f"{url}&page={page_number}"
response = requests.get(url_with_page)
soup = BeautifulSoup(response.text, 'html.parser')
# 記事のタイトルとURLを抽出
articles = soup.find_all('a', attrs={"data-section": "article-url"})
data = []
for index, article in enumerate(articles, start=1): # 通し番号を追加するためのカウンター
title = article.get_text(strip=True)
link = "https://www.globenewswire.com" + article['href']
data.append([index, link, title]) # 順番をNo, URL, Titleに変更
return data
def save_to_csv(data, filename):
# CSVに保存
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['No.', 'URL', 'Title']) # ヘッダーの順番も変更
writer.writerows(data) # データの書き込み
if __name__ == '__main__':
# 実行日を取得
today = datetime.now().strftime("%Y%m%d")
# ベースURLを設定
base_url = 'https://www.globenewswire.com/search/lang/en/keyword/seed/date/[2023-01-01%2520TO%25202024-04-30]/subject/fin?pageSize=50'
# ページ数を指定
page_number = 1
# スクレイピング実行
data = scrape_page(base_url, page_number)
# ファイル名に実行日とページ数を追加して保存
filename = f'{today}_page{page_number}_scraped_data.csv'
save_to_csv(data, filename)
print("スクレイピング完了")
実行結果はこのようになります。
| No. | URL | Title |
|---|---|---|
| 1 | https://www.globenewswire.com/news-release/202... | Twill Payments Secures Pre-Seed Funding to Rev... |
| 2 | https://www.globenewswire.com/news-release/202... | Leash Biosciences Announces $9.3 Million Seed ... |
| 3 | https://www.globenewswire.com/news-release/202... | LLM Fine-Tuning Startup OpenPipe Raises $6.7 M... |
step2 個別記事の本文を取得
次にそれぞれの記事のURLにアクセスして、本文をすべて取得します。
今回はたまたま印刷用の簡素なページがあったので、そちらから情報を取得しました。
元々のURLにprint=1をつけるとひらけます。
属性がitemprop="articledetail"の要素を取得します。

一般的なマナーとして、アクセス間隔を開けるようにしましょう。今回は5秒あけました。
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import pandas as pd
import time
def scrape_page(url):
# URLにページ番号を追加
url = f"{url}?print=1"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# タイトルと本文を抽出
title = soup.find(itemprop="headline").text
content = soup.find(itemprop="articledetail").text.strip()
# print(title)
# print(content)
time.sleep(5)
return title, content
if __name__ == '__main__':
# CSVファイルを読み込む
df_1 = pd.read_csv('20240501_page1_scraped_data.csv')
df_2 = pd.read_csv('20240501_page2_scraped_data.csv')
df = pd.concat([df_1, df_2])
df.reset_index(drop=True, inplace=True)
print("データの読み込み完了")
df["Title"] = ""
df["Content"] = ""
for i in range(0, len(df)):
url = df.loc[i, "URL"]
title, content = scrape_page(url)
# タイトルと本文をデータフレームに追加
df.loc[i, "Title"] = title
df.loc[i, "Content"] = content
print(df.loc[i, "Title"])
print(df.loc[i, "Content"])
df.to_csv("output_step2.csv")
print(f"{i+1}回目のループを保存しました")
print("スクレイピング完了")
| No. | URL | Title | Content |
|---|---|---|---|
| 1 | https://www.globenewswire.com/news-release/202... | Twill Payments Secures Pre-Seed Funding to Rev... | CAMDEN, Del., April 23, 2024 (GLOBE NEWSWIRE)... |
| 2 | https://www.globenewswire.com/news-release/202... | Leash Biosciences Announces $9.3 Million Seed ... | – Financing will support development of a foun... |
| 3 | https://www.globenewswire.com/news-release/202... | LLM Fine-Tuning Startup OpenPipe Raises $6.7 M... | SEATTLE, March 26, 2024 (GLOBE NEWSWIRE) -- ... |
step3 ChatGPTで要約
本文を読み込ませて、内容を要約させましょう。
数ヶ月前のアップデートでAPIの呼び出し方が変わったため、最新のライブラリのバージョンだと既存のZenn等の解説記事のコードでは動かない場合があります。注意しましょう。
先に.envファイルに管理画面から発行したAPIキーを記載しておきます。
OPENAI_API_KEY=sk-proj-abcdefghijk...
また必要なライブラリをインストールしてください。
pip install python-dotenv
pip install openai
from openai import OpenAI
from dotenv import load_dotenv
import os
import pandas as pd
import time
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
def GPT(input_text, max_tokens=2048, temperature=0):
messages=[
{
"role": "system",
"content": "【指示】入力した文章から、以下の質問に答えてください。また、簡潔な文にするため、質問の答えの主語としてサービス名を含める必要はありません。【質問】・サービス名・公開日・投資ラウンド・資金調達額・サービスサイトのURL・誰のどんな課題を解決するのか?・課題の根本原因は何か?・課題の解決策は?・顧客はなぜそのサービスにお金を払いたいのか?・課題のどの作業が短縮されるのか?・解決策は競合と比較してどのような新規性があるか?【出力形式の例】・サービス名:Fiteo公開日:2023年1月9日・投資ラウンド:プレシード資金調達額:情報なし・サービスサイトのURL:https://fiteo.co・誰のどんな課題を解決するのか?:小規模ブランドがオンライン市場での販売で直面するリーチ、ブランド認知度、予算の問題を解決する。・課題の根本原因は何か?:小規模ブランドは大手ブランドと比べてリーチ、ブランド認知度、マーケティング予算が不足している。・課題の解決策は?:スポンサード製品掲載を通じてオンライン市場での製品発見を促進する。・顧客はなぜそのサービスにお金を払いたいのか?:スポンサード製品が商品を購買者の目の前に配置することで、売上を増やす効果的な手段となるため。・課題のどの作業が短縮されるのか?:小規模ブランドが消費者にリーチする時間が短縮される。・解決策は競合と比較してどのような新規性があるか?:ソーシャルプラットフォームに触発された製品発見体験にスポンサードコンテンツを組み込むことで、他のオンラインマーケティング戦略と差別化を図る。"},
{
"role": "user",
"content": input_text
},]
print("extract API request")
start = time.time() # 現在時刻(処理開始前)を取得
response = client.chat.completions.create(
model="gpt-4",
messages=messages,
max_tokens=max_tokens,
n=1,
stop=None,
temperature=temperature,
)
print("extract API response received!")
end = time.time() # 現在時刻(処理完了後)を取得
time_diff = int(end - start) # 処理完了後の時刻から処理開始前の時刻を減算する
print("実行時間:" + str(time_diff) + "秒") # 処理にかかった時間データを使用
outputs = response.choices[0].message.content
print(outputs)
return outputs
def save_as_markdown():
import pandas as pd
# CSVファイルを読み込む
df_csv = pd.read_csv('output_step3_int.csv').astype(str)
# マークダウンファイルの内容を構築
markdown_content = ""
for index, row in df_csv.iterrows():
markdown_content += f"## {row['サービス名'].strip()}\n\n"
markdown_content += f"- **公開日:** {row['公開日'].strip()}\n"
markdown_content += f"- **投資ラウンド:** {row['投資ラウンド'].strip()}\n"
markdown_content += f"- **資金調達額**: {row['資金調達額'].strip()}\n"
markdown_content += f"- **サービスサイトのURL**: {row['サービスサイトのURL'].strip()}\n"
markdown_content += f"- **プレスリリースのURL**: {row['URL'].strip()}\n"
markdown_content += f"- **課題**: {row['誰のどんな課題を解決するのか?'].strip()}\n"
markdown_content += f"- **根本原因**: {row['課題の根本原因は何か?'].strip()}\n"
markdown_content += f"- **解決策**: {row['課題の解決策は?'].strip()}\n"
markdown_content += f"- **お金を支払う理由**: {row['顧客はなぜそのサービスにお金を払いたいのか?'].strip()}\n"
markdown_content += f"- **短縮される作業**: {row['課題のどの作業が短縮されるのか?'].strip()}\n"
markdown_content += f"- **新規性**: {row['解決策は競合と比較してどのような新規性があるか?'].strip()}\n"
markdown_content += "\n"
# マークダウンファイルとして保存
with open('output_step3_final.md', 'w', encoding='utf-8') as file:
file.write(markdown_content)
def process_output(output, i):
# 新たな列のデータを抽出
temp_data = {}
if "・サービス名:" in output:
temp_data["サービス名"] = output.split("・サービス名:")[1].split("・")[0].strip()
if "・公開日:" in output:
temp_data["公開日"] = output.split("・公開日:")[1].split("・")[0].strip()
if "・投資ラウンド:" in output:
temp_data["投資ラウンド"] = output.split("・投資ラウンド:")[1].split("・")[0].strip()
if "・資金調達額:" in output:
temp_data["資金調達額"] = output.split("・資金調達額:")[1].split("・")[0].strip()
if "・サービスサイトのURL:" in output:
temp_data["サービスサイトのURL"] = output.split("・サービスサイトのURL:")[1].split("・")[0].strip()
if "・誰のどんな課題を解決するのか?:" in output:
temp_data["誰のどんな課題を解決するのか?"] = output.split("・誰のどんな課題を解決するのか?:")[1].split("・")[0].strip()
if "・課題の根本原因は何か?:" in output:
temp_data["課題の根本原因は何か?"] = output.split("・課題の根本原因は何か?:")[1].split("・")[0].strip()
if "・課題の解決策は?:" in output:
temp_data["課題の解決策は?"] = output.split("・課題の解決策は?:")[1].split("・")[0].strip()
if "・顧客はなぜそのサービスにお金を払いたいのか?:" in output:
temp_data["顧客はなぜそのサービスにお金を払いたいのか?"] = output.split("・顧客はなぜそのサービスにお金を払いたいのか?:")[1].split("・")[0].strip()
if "・課題のどの作業が短縮されるのか?:" in output:
temp_data["課題のどの作業が短縮されるのか?"] = output.split("・課題のどの作業が短縮されるのか?:")[1].split("・")[0].strip()
if "・解決策は競合と比較してどのような新規性があるか?:" in output:
temp_data["解決策は競合と比較してどのような新規性があるか?"] = output.split("・解決策は競合と比較してどのような新規性があるか?:")[1].split("・")[0].strip()
# 新たな列をdfに追加
for key, value in temp_data.items():
df.loc[i, key] = value
# データフレームを中間ファイルに保存
df.to_csv("output_step3_int.csv")
# マークダウンの中間ファイルを保存
with open('output_step3_int.md', 'a') as f:
f.write(output + '\n\n')
# 最終ファイルとして保存(途中で止まった時のためにループ内で保存している)
save_as_markdown()
if __name__ == '__main__':
# CSVファイルを読み込む
df = pd.read_csv('output_step2.csv')
print("データの読み込み完了")
for i in range(0, len(df)):
# 記事内容を取得
title = df.loc[i, "Title"]
content = df.loc[i, "Content"]
input_text = output = f"{title}\n{content}"
try:
output = GPT(input_text)
process_output(output, i)
print(str(i+1) + "回目のループを保存しました")
except Exception as e:
print(f"何らかのエラーが出ました: {e}")
continue
print("実行終了")
プロンプトはブラウザのChatGPTで様々な文章を試して、その中で調子の良かったものを用意しました。出力形式の例を入力して回答の形式を固定しています。
【指示】
入力した文章から、以下の質問に答えてください。また、簡潔な文にするため、質問の答えの主語としてサービス名を含める必要はありません。
【質問】
・サービス名
・公開日
・投資ラウンド
・資金調達額
・サービスサイトのURL
・誰のどんな課題を解決するのか?
・課題の根本原因は何か?
・課題の解決策は?
・顧客はなぜそのサービスにお金を払いたいのか?
・課題のどの作業が短縮されるのか?
・解決策は競合と比較してどのような新規性があるか?
【出力形式の例】
・サービス名:Fiteo
・公開日:2023年1月9日
・投資ラウンド:プレシード資金調達額:情報なし
・サービスサイトのURL:https://fiteo.co
・誰のどんな課題を解決するのか?:小規模ブランドがオンライン市場での販売で直面するリーチ、ブランド認知度、予算の問題を解決する。
・課題の根本原因は何か?:小規模ブランドは大手ブランドと比べてリーチ、ブランド認知度、マーケティング予算が不足している。
・課題の解決策は?:スポンサード製品掲載を通じてオンライン市場での製品発見を促進する。
・顧客はなぜそのサービスにお金を払いたいのか?:スポンサード製品が商品を購買者の目の前に配置することで、売上を増やす効果的な手段となるため。
・課題のどの作業が短縮されるのか?:小規模ブランドが消費者にリーチする時間が短縮される。
・解決策は競合と比較してどのような新規性があるか?:ソーシャルプラットフォームに触発された製品発見体験にスポンサードコンテンツを組み込むことで、他のオンラインマーケティング戦略と差別化を図る
取得した結果はnotionにそのままコピペできるようにmdファイルで出力されます。
## Twill AI
- **公開日:** 2024年4月23日
- **投資ラウンド:** プレシード
- **資金調達額**: 情報なし
- **サービスサイトのURL**: https://twillpayments.com/ai
- **プレスリリースのURL**: https://www.globenewswire.com/news-release/2024/04/23/2868202/0/en/Twill-Payments-Secures-Pre-Seed-Funding-to-Revolutionize-Data-Analytics-with-AI.html
- **課題**: 中小企業がデータ分析をフルに活用できないという課題を解決する。
- **根本原因**: 中小企業は支払い処理に高額なコストを払いつつ、データを活用するためのリソースが不足している。
- **解決策**: ビジネスデータを集約し解釈するプラットフォームを開発し、データ分析を簡素化し、すべてのビジネスオーナーにアクセス可能にする。
- **お金を支払う理由**: データの深い理解を促進し、隠れた機会を発見し、トレンドを予測し、意思決定プロセスを効率化するため。
- **短縮される作業**: データ分析と意思決定プロセスが短縮される。
- **新規性**: ビジネスアプリケーションを安全に一元化されたデータベースに接続する広範なAPIライブラリを提供し、ユーザーがデータと多次元的に関わることを可能にする。
## Leash Biosciences
- **公開日:** 2024年4月5日
- **投資ラウンド:** シードラウンド
- **資金調達額**: $9.3 million
- **サービスサイトのURL**: https://www.leash.bio
- **プレスリリースのURL**: https://www.globenewswire.com/news-release/2024/04/05/2858467/0/en/Leash-Biosciences-Announces-9-3-Million-Seed-Financing-to-Pioneer-AI-Driven-Medicinal-Chemistry.html
- **課題**: 薬物発見における効率性と精度の問題を解決する。
- **根本原因**: 薬物発見は時間とコストがかかり、予測モデルの精度が不十分であるため。
- **解決策**: AIと機械学習を活用した医薬化学の予測モデルを開発し、大規模な生物学的データ収集を行う。
- **お金を支払う理由**: 薬物発見の効率性と精度を向上させ、時間とコストを節約するため。
- **短縮される作業**: 小分子薬物候補の予測と選択の作業が短縮される。
- **新規性**: Leash Biosciencesは、自社で生成した170億以上の高品質なタンパク質-化学物質相互作用測定を用いて、医薬化学の一般化可能な機械学習モデルを開発することで、競合と差別化を図っている。
step4 投資ラウンドごとにデータを分割する
step3の時点で今回取得した100件分のデータがすべてmdファイルになっています。
しかし、実は「seed」での検索結果であっても、異なる投資ラウンドのサービスが含まれていることがわかりました。
そこで、step3の中間出力であるoutput_step3_int.csvから、投資ラウンドごとにデータを分割して、mdファイルに保存します。
## Twill AI
- **公開日:** 2024年4月23日
- **投資ラウンド:** プレシード
## Leash Biosciences
- **公開日:** 2024年4月5日
- **投資ラウンド:** シードラウンド
import pandas as pd
def save_as_markdown(filename):
import pandas as pd
# CSVファイルを読み込む
df_csv = pd.read_csv(filename).astype(str)
# マークダウンファイルの内容を構築
markdown_content = ""
for index, row in df_csv.iterrows():
markdown_content += f"## {row['サービス名'].strip()}\n\n"
markdown_content += f"- **公開日:** {row['公開日'].strip()}\n"
markdown_content += f"- **投資ラウンド:** {row['投資ラウンド'].strip()}\n"
markdown_content += f"- **資金調達額**: {row['資金調達額'].strip()}\n"
markdown_content += f"- **サービスサイトのURL**: {row['サービスサイトのURL'].strip()}\n"
markdown_content += f"- **プレスリリースのURL**: {row['URL'].strip()}\n"
markdown_content += f"- **課題**: {row['誰のどんな課題を解決するのか?'].strip()}\n"
markdown_content += f"- **根本原因**: {row['課題の根本原因は何か?'].strip()}\n"
markdown_content += f"- **解決策**: {row['課題の解決策は?'].strip()}\n"
markdown_content += f"- **お金を支払う理由**: {row['顧客はなぜそのサービスにお金を払いたいのか?'].strip()}\n"
markdown_content += f"- **短縮される作業**: {row['課題のどの作業が短縮されるのか?'].strip()}\n"
markdown_content += f"- **新規性**: {row['解決策は競合と比較してどのような新規性があるか?'].strip()}\n"
markdown_content += "\n"
# マークダウンファイルとして保存
with open(f'{filename.replace(".csv", "")}_final.md', 'w', encoding='utf-8') as file:
file.write(markdown_content)
def categorize_and_save(csv_file, column_name, categories):
import pandas as pd
# CSVファイルを読み込む
data = pd.read_csv(csv_file)
# カテゴリによってデータを分割しCSVに出力
for i, (category, matches) in enumerate(categories.items()):
# データをフィルタリング
filtered_data = data[data[column_name].isin(matches)]
# CSVファイルに保存
filtered_data.to_csv(f"output_step-4_{category}.csv", index=False)
# マークダウンファイルに保存
save_as_markdown(f"output_step-4_{category}.csv")
# 'その他' カテゴリの処理
other_data = data[~data[column_name].isin(sum(categories.values(), []))]
other_data.to_csv("output_step-4_99_その他.csv", index=False)
save_as_markdown(f"output_step-4_99_その他.csv")
# 実行
if __name__ == '__main__':
# カテゴリを定義
categories = {
"01_プレシード": ["プレシード"],
"02_シード": ["シードラウンド"],
"03_シリーズA": ["シリーズA"],
"04_シリーズB": ["シリーズB"],
"05_シリーズC": ["シリーズC"]
}
# カテゴリごとにデータを分割しCSVで保存
categorize_and_save("output_step3_int.csv", '投資ラウンド', categories)
# CSVからマークダウンファイルを保存
for category in categories:
save_as_markdown(f"step-4_{category}.csv")
最終的な出力はこのようになります。

mdファイルの中身をnotionにコピペすると、このように表示できます。

まとめ
この記事では以下の内容を実施しました。
- step0:絞り込み検索ができるプレスリリースサイトの選定
- step1:スクレイピングで一覧ページを取得
- step2:各記事の本文を取得
- step3:ChatGPTで要約させる
- step4:投資ラウンドごとに分割して保存
大量の記事を要約する必要がある方は、ぜひご活用ください。
Discussion