「しかのこのこのここしたんたん」を読み上げさせたい!!
最近、「しかのこのこのここしたんたん」というリズミカルなフレーズが巷で話題です。このフレーズがマルコフモデルにより生成されると考えた時、非常に低い確率であることを体験できるデモサイトを構築してみました。ぜひ、実際に体験してください。
マルコフモデルとは
マルコフ連鎖(マルコフモデル)とは、状態の遷移が確率的に決定されるモデルのことです。言い換えれば、過去の状態にのみ基づいて未来の状態が決まるという概念です。この特性を利用して、自然言語処理の分野では文章やテキストの生成に活用されています。
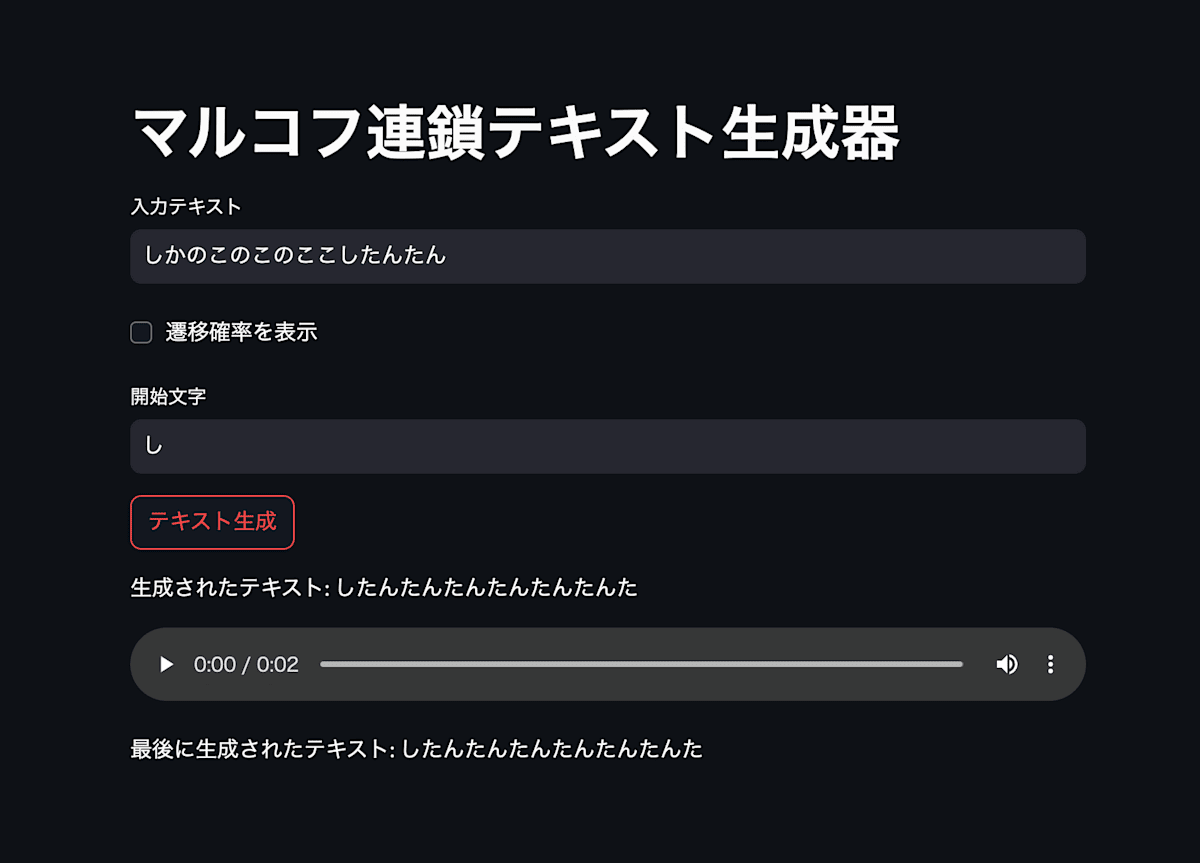
「しかのこのこのここしたんたん」での具体例
このフレーズを選んだ理由
このフレーズは短く、同じ文字や音が繰り返されているため、遷移確率を計算するのに適しています。初学者にも直感的に理解しやすい例と言えます。
状態遷移
例えば、「しかのこのこのここしたんたん」というテキストを入力として、マルコフモデルを構築すると次のような遷移確率が得られます。
マルコフモデルに基づく遷移確率:
-
遷移元: 'し'
- → 'か': 0.50
- → 'た': 0.50
-
遷移元: 'か'
- → 'の': 1.00
-
遷移元: 'の'
- → 'こ': 1.00
-
遷移元: 'こ'
- → 'の': 0.50
- → 'こ': 0.25
- → 'し': 0.25
-
遷移元: 'た'
- → 'ん': 1.00
-
遷移元: 'ん'
- → 'た': 1.00
このモデルに基づいてテキストを生成すると、「したんたんたんたんたんたんた」や「しかのここしかのこのこのこし」のような、テキストが確率的に多く生成されます。
今回、「しかのこのこのここしたんたん」のフレーズは非常に低い確率であることが分かります。
デモの作成方法
実際にこのモデルを用いてリアルタイムにテキストを生成し、さらに音声合成エンジンを使って音声に変換するインタラクティブなデモアプリケーションをStreamlitで作成します。デモはこちらで公開していますので、ぜひ試してみてください。
コード
以下がデモアプリケーションのソースコードです。
import streamlit as st
from collections import defaultdict
import random
from gtts import gTTS
import io
from gtts.tts import gTTSError
def create_markov_model(text):
model = defaultdict(lambda: defaultdict(int))
for i in range(len(text) - 1):
current_char = text[i]
next_char = text[i + 1]
model[current_char][next_char] += 1
return model
def calculate_transition_probabilities(model):
probabilities = {}
for char, transitions in model.items():
total = sum(transitions.values())
probabilities[char] = {next_char: count / total for next_char, count in transitions.items()}
return probabilities
def generate_text(probabilities, start_char, length):
result = start_char
current_char = start_char
for _ in range(length - 1):
if current_char in probabilities:
next_char = random.choices(list(probabilities[current_char].keys()),
weights=list(probabilities[current_char].values()))[0]
result += next_char
current_char = next_char
else:
break
return result
def text_to_speech(text, lang='ja'):
if not text:
return None
try:
tts = gTTS(text=text, lang=lang)
fp = io.BytesIO()
tts.write_to_fp(fp)
fp.seek(0)
return fp
except gTTSError as e:
st.error(f"音声の生成中にエラーが発生しました: {str(e)}")
return None
st.title("マルコフ連鎖テキスト生成器")
# 入力テキスト
text = st.text_input("入力テキスト", value="しかのこのこのここしたんたん")
# マルコフモデルの作成
model = create_markov_model(text)
# 遷移確率の計算
probabilities = calculate_transition_probabilities(model)
if st.checkbox("遷移確率を表示"):
st.subheader("マルコフモデルに基づく遷移確率:")
for char, transitions in probabilities.items():
st.write(f"遷移元: '{char}'")
for next_char, prob in transitions.items():
st.write(f" → '{next_char}': {prob:.2f}")
st.write()
start_char = st.text_input("開始文字", value="し")
# セッション状態の初期化
if 'generated_text' not in st.session_state:
st.session_state.generated_text = ""
if 'audio' not in st.session_state:
st.session_state.audio = None
# テキスト生成ボタン
if st.button("テキスト生成"):
st.session_state.generated_text = generate_text(probabilities, start_char, length=len(text))
st.write(f"生成されたテキスト: {st.session_state.generated_text}")
audio_fp = text_to_speech(st.session_state.generated_text)
if audio_fp:
st.session_state.audio = audio_fp
st.audio(st.session_state.audio, format='audio/mp3')
else:
st.warning("音声を生成できませんでした。テキストのみ表示します。")
# 最後に生成されたテキストを表示
if st.session_state.generated_text:
st.write(f"最後に生成されたテキスト: {st.session_state.generated_text}")
解説
以下は、簡潔にまとめたStreamlitアプリケーションのコード解説です。
-
ライブラリのインポート
- 必要なライブラリをインポートします。
-
マルコフモデル関連関数
-
create_markov_model: 入力テキストからマルコフモデルを作成します。 -
calculate_transition_probabilities: マルコフモデルに基づいて遷移確率を計算します。 -
generate_text: 遷移確率を基にランダムなテキストを生成します。
-
-
音声合成関連関数
-
text_to_speech: 生成されたテキストを音声に変換します。 -
autoplay_audio: 音声データを自動再生します。
-
-
Streamlit アプリケーション
-
テキスト入力:
st.text_inputでユーザーがテキストを入力します。 -
遷移確率の表示:
st.checkboxで遷移確率の表示を選択し、st.writeで表示します。 -
開始文字の入力:
st.text_inputでテキスト生成の開始文字を入力します。 -
開始/停止ボタン:
st.buttonでテキスト生成と音声再生の開始/停止を制御します。 -
生成間隔:
st.sliderでテキスト生成と音声再生の間隔を設定します。 -
テキストと音声の出力:
st.emptyとst.writeで生成されたテキストを表示し、autoplay_audioで音声を再生します。
-
テキスト入力:
まとめ
この記事では、「しかのこのこのここしたんたん」というフレーズをマルコフ連鎖モデルを用いて生成するデモを作成しました。マルコフモデルに基づいたテキスト生成と音声再生を体感することで、確率的なテキスト生成の面白さを実感できます。ぜひ、デモサイトで実際にお試しください。
Discussion