Tableau Prepを触ってみた(dbtの処理をPrepに移行してみる)
業務でTableau Prepのフローを読む機会があったので、個人学習がてら、少しだけTableauPrepに触れてみました。
やること
dbt-labsのjaffle_shopの処理を、そのままTableau Prepで再現してみます。
これが

こうなります。

実施環境
- Tableau Cloud
- Snowflake
Tableau Prepとは
Tableau Prepは、GUIでデータパイプラインを作成できるツールです。さまざまなデータ操作を、画面ポチポチするだけで簡単に実現できるようになっています。
サンプルデータ付きの公式のチュートリアルがあるので、初めて触れるなら、まずはこちらをやってみるのが良いと思います。
(1時間もあれば終わります!)
データの取り込み
RAWテーブルの取り込みをします。jaffle_shopのRAWテーブルは、seedとしてcsvファイルから取り込まれています。今回はあらかじめSnowflake上にraw_*の名前でテーブルを作っておき、これをPrepに食わせることにしました。
Tableau Prepでは、多種多様なデータソースとのコネクターが標準で用意されています。
ここではSnowflakeを選択します。

選択すると、接続先情報の入力画面が出てくるので、言われた通りに入力。
(認証方法はパスワード認証やOktaの認証も選べました。)

その後も画面に出てくる通りにデータベース、スキーマ、テーブルを選択すると、フローにテーブルが追加されます。
クリーニング
STGテーブルを作成します。
jaffle_shopのSTGモデルでは、列名の名寄せや、単位の変更(セント→ドル)などが行われていました。
select
id as payment_id,
order_id,
payment_method,
-- `amount` is currently stored in cents, so we convert it to dollars
amount / 100 as amount
from source
このような列の加工は、「クリーニング」機能を用いて実現できます。
追加したRAWテーブルのステップから、➕ボタンを押下して、「クリーニング」を選びます。
クリーニングステップが追加され、画面下のパネルではデータがプレビューされるのがわかります。
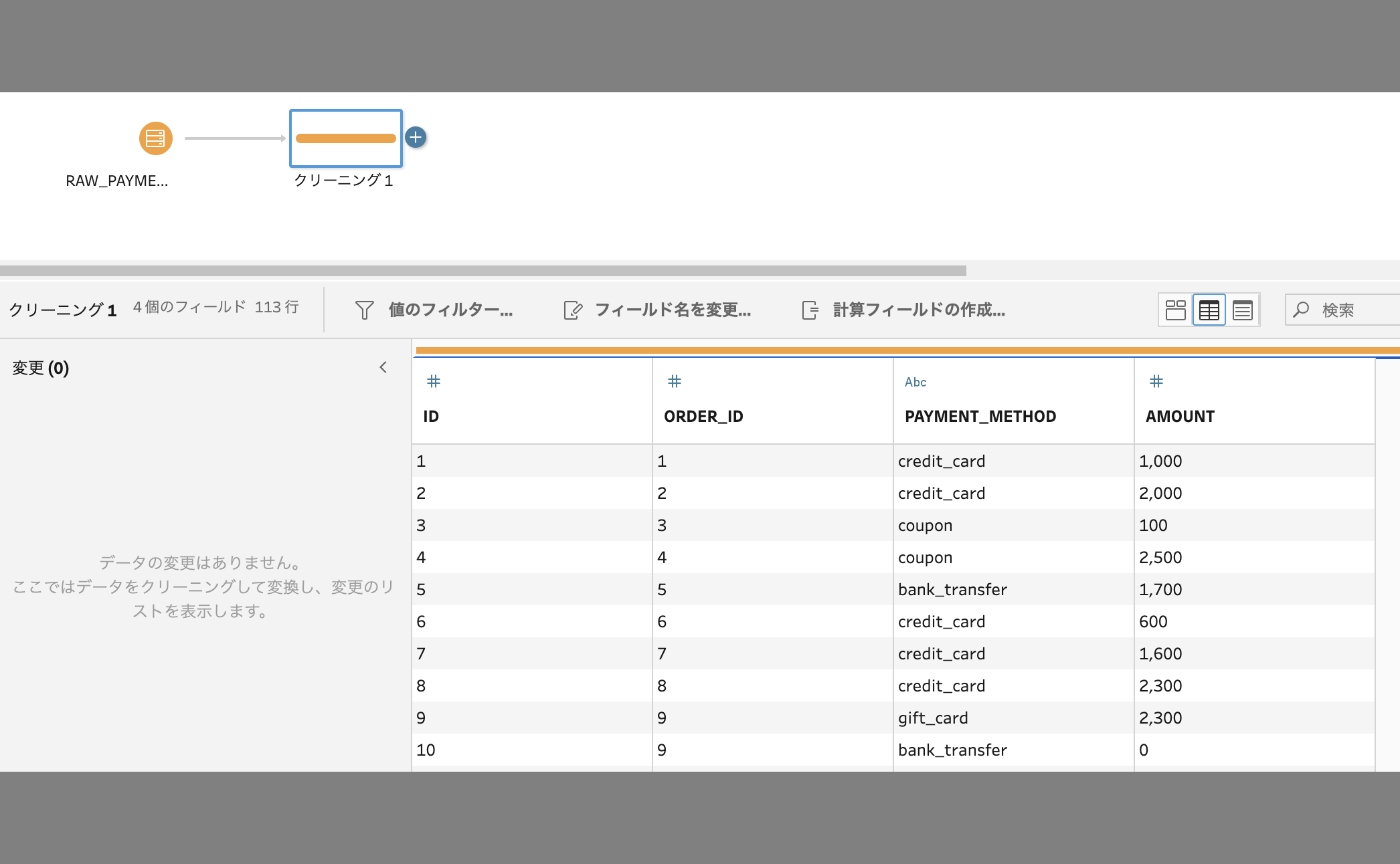
列名の変更は、プレビューの列名を編集するだけです。これで、列名の変更が定義されます。

新しい列の追加や、既存の列の編集は、「計算フィールドの作成」から行えます。
関数も色々用意されていそうなので、カラム単位の計算であれば、この中である程度実現できそうです。
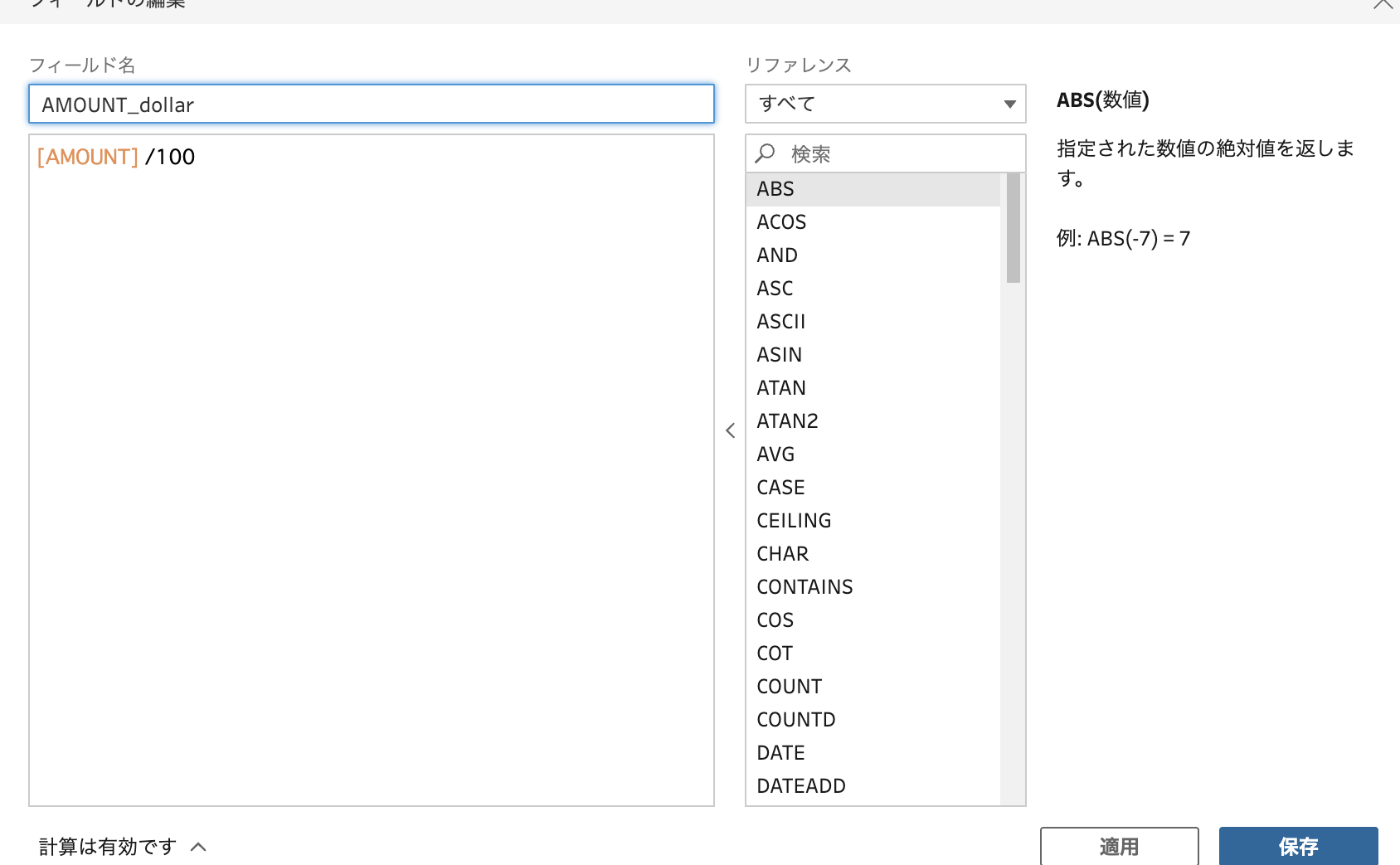
ただ、計算フィールドの追加では、既存のフィールド名を指定して上書きすることができないので、上のSQLを再現するためには、
一度別名でフィールドを追加既存フィールドを削除-
追加したフィールドをリネームする
といった手間が必要でした。

(追記)計算フィールドで既存のフィールド指定ができると情報をいただきました。後日調べて追記しますm(__)m
集計・結合
マート層を作成します。
集計
customersモデルの以下のcteを考えます。customer_idごとにorder_dateの最大値と最小値の取り出しと、order_idのカウントを行います。
customer_orders as (
select
customer_id,
min(order_date) as first_order,
max(order_date) as most_recent_order,
count(order_id) as number_of_orders
from orders
group by customer_id
),
集計ステップを使用して、データの集計を行うことができます。
集計ステップを追加すると、画面下パネルに編集画面が表示されます。
プレビューされるフィールドを、ドラッグ&ドロップでグループ化したいフィールドや集計フィールドに追加するだけです。

ただし、残念ながら、一つのフィールドに対して複数の集計関数を指定することができません。
今回でいえば、order_dateの最大値と最小値を一つの集計ステップで求めることができないということです。

よって、同じフィールドへ複数の集計関数を使いたい場合には、以下のように別々の集計ステップを使って計算した後、ひとつのテーブルに結合するしかありません。

(追記)こちらは、フィールドを複製すれば、わざわざ別の集計ステップを作らずとも計算可能だそうです。思いつかなかった!
結合
次は、以下のcteを考えます。3つのcte句で求めた結果をすべてJoinしています。
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order,
customer_orders.most_recent_order,
customer_orders.number_of_orders,
customer_payments.total_amount as customer_lifetime_value
from customers
left join customer_orders
on customers.customer_id = customer_orders.customer_id
left join customer_payments
on customers.customer_id = customer_payments.customer_id
)
結合は、結合ステップを用いて実現できます。
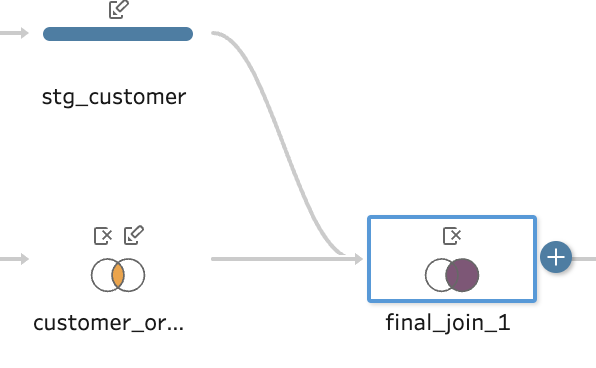
結合ステップを選択後、画面下のパネルからは、
- 結合条件に用いるカラムや演算子
- 結合方法
が選べます。

左結合、右結合、完全一致、など、ベン図をポチポチしながら、実際のデータプレビューを確認しながら選んでいけるので、SQLに不慣れなユーザーでも、簡単に処理を組んでいくことができそうです。
ただ、上のSQLを再現しようとすると、複数のテーブルのJoinになるので、ステップがネストしていきます。依存するデータが増えると、管理が難しくなりそうです。

Snowflake側で起きること
ここまで、GUIでフローをポチポチ組んでみました。
簡単に作成ができる一方で、dbt(SQL)を用いてモデリングした際に比べて、ステップ数はどうしても増えそうな印象です。
実行されるクエリの本数も増えてしまうのでしょうか?
このフローを実際に動かして、Snowflakeのクエリヒストリーを確認してみました。
1本目のクエリ
(DB・WHの指定とか、セッションの切り替えとかを除いて、)一本目のクエリが以下です。
SELECT "t0"."AMOUNT" AS "amount",
"t0"."credit_card_amount" AS "credit_card_amount",
"t0"."coupon_amount" AS "coupon_amount",
"t0"."bank_transfer_amount" AS "bank_transfer_amount",
"t0"."gift_card_amount" AS "gift_card_amount",
"db27cd2f-1f1e-4d6d-bada-c0c971"."ID" AS "ORDER_ID",
"db27cd2f-1f1e-4d6d-bada-c0c971"."USER_ID" AS "CUSTOMER_ID",
"db27cd2f-1f1e-4d6d-bada-c0c971"."ORDER_DATE" AS "ORDER_DATE",
(CASE WHEN 8192 >= 0 THEN LEFT("db27cd2f-1f1e-4d6d-bada-c0c971"."STATUS",8192) END) AS "STATUS"
FROM "DB"."PUBLIC"."RAW_ORDERS" "db27cd2f-1f1e-4d6d-bada-c0c971"
LEFT JOIN (
SELECT "87818c7b-aea2-47c0-90ec-586383"."ORDER_ID" AS "ORDER_ID",
SUM((CASE WHEN ("87818c7b-aea2-47c0-90ec-586383"."PAYMENT_METHOD" = 'bank_transfer') THEN (CASE WHEN 100 <> 0 THEN "87818c7b-aea2-47c0-90ec-586383"."AMOUNT" / 100 END) ELSE 0 END)) AS "bank_transfer_amount",
SUM((CASE WHEN ("87818c7b-aea2-47c0-90ec-586383"."PAYMENT_METHOD" = 'coupon') THEN (CASE WHEN 100 <> 0 THEN "87818c7b-aea2-47c0-90ec-586383"."AMOUNT" / 100 END) ELSE 0 END)) AS "coupon_amount",
SUM((CASE WHEN ("87818c7b-aea2-47c0-90ec-586383"."PAYMENT_METHOD" = 'credit_card') THEN (CASE WHEN 100 <> 0 THEN "87818c7b-aea2-47c0-90ec-586383"."AMOUNT" / 100 END) ELSE 0 END)) AS "credit_card_amount",
SUM((CASE WHEN ("87818c7b-aea2-47c0-90ec-586383"."PAYMENT_METHOD" = 'gift_card') THEN (CASE WHEN 100 <> 0 THEN "87818c7b-aea2-47c0-90ec-586383"."AMOUNT" / 100 END) ELSE 0 END)) AS "gift_card_amount",
SUM((CASE WHEN 100 <> 0 THEN "87818c7b-aea2-47c0-90ec-586383"."AMOUNT" / 100 END)) AS "AMOUNT"
FROM "DB"."PUBLIC"."RAW_PAYMENTS" "87818c7b-aea2-47c0-90ec-586383"
GROUP BY 1
) "t0" ON ("db27cd2f-1f1e-4d6d-bada-c0c971"."ID" = "t0"."ORDER_ID")
テーブルの別名がUUIDになっていたりして読みにくいですが、ordersモデルの処理のようです。
2本目のクエリ
put 'file:///var/opt/tableau/tableau_server/data/tabsvc/temp/flowprocessor_0.20233.23.1108.1145/tableau-temp/TPB9C3F65992F34E9D9A0B6D151A18C276_1jf8l6v03v9m5f1e6lsk60l3fow5.csv' @~
出力をcsv化してSnowflakeに配置している様子。
3本目のクエリ
COPY INTO "DB"."PUBLIC"."orders_tableau_prep" (
"amount",
"credit_card_amount",
"coupon_amount",
"bank_transfer_amount",
"gift_card_amount",
"ORDER_ID",
"CUSTOMER_ID",
"ORDER_DATE",
"STATUS"
)
FROM
@ ~ / file_format = (
type = csv field_delimiter = ',' skip_header = 1 TIMESTAMP_FORMAT = 'YYYY-MM-DD HH24:MI:SS.FF' DATE_FORMAT = 'YYYY-MM-DD' FIELD_OPTIONALLY_ENCLOSED_BY = '"' ESCAPE = NONE ESCAPE_UNENCLOSED_FIELD = NONE
) pattern = '.*TPB9C3F65992F34E9D9A0B6D151A18C276.*' PURGE = TRUE
CSVからテーブルに出力している様子。
4本目から、customersモデルの処理も流れていましたが、同じことをやっているだけなので割愛します。
わかったこと
データ変換はSnowflake側でまとめて処理されている
注目したいのは、RAWテーブルから取り出したデータを加工し、最終出力の形にするまでが一つのクエリになっている点です。
Tableau側にデータを取り出して、サーバでデータ加工して、結果をWHに戻すわけではなさそうです。
すべてのデータ変換をSQLに書き換えられるとも思えないので、できる限りではあると思いますが、WHのコンピューティングリソースを使って変換をしようとしてくれるのは嬉しいですね。
CSVを一旦経由して、WHに取り込まれる
WH側で加工してくれるといっても、最終出力は一度Tableau server側に送られ、CSVファイルとしてSnowflakeに帰ってきています。
ただし、今回はテーブルをDrop&Createで、完全に洗い替える設定で動かしています。
Tableauでは増分更新をサポートしており、設定によってはこのあたりの動作は変わるのかもしれません。
そのうち機会あれば検証してみたいです。
まとめ
Tableau prepでdbtの処理を再現してみました。
実装は楽ですし、変換されるクエリも、自動変換特有の重たい処理ができないような工夫がされています。
複雑な処理になればなるほど見通しが悪くなりそうではありますが、これはローコード製品すべてに言えることだと思います。
使い所を選べば、とてもいい感じの製品だと思いました。
Discussion