[個人開発]料理のレシピを管理できるサイト
Recipe Manager

概要
ポートフォリオとして、料理のレシピを管理できるWebアプリケーションを開発しました。
楽天APIを使ってレシピサイトを検索したり、オリジナルのレシピを登録したりできます。
技術スタック
Frontend
JSライブラリ: React、
UIライブラリ: Shadcn/ui、
ビルドツール: Vite
Git: https://github.com/atiek-hub/recipe-mgr
Viteについては、高速なビルドツールで、開発サーバーの立ち上げや、ホットリロードなど快適な開発環境を提供してくれる。
shadcn/uiは機能が充実しており、綺麗なUIを簡単に実装できる。V0と組み合わせると、かなり良い画面を生成してくれるのもメリット
Backend:
JSランタイム: Bun、
フレームワーク: Hono、
ORM: Prisma、
DB: Supabase
Git: https://github.com/atiek-hub/recipe_mgr_app_backend
Bun、Honoのメリットや、環境構築方法については、以下のスクラップにまとめました。
構成図

テーブル設計

RecipeSites は、楽天APIを使用して取得したレシピ情報を登録するテーブルです。
ただし、楽天APIの利用規約により、取得した情報を長期間保存し、DBから再表示する形式の利用は原則として認められていません。
そのため本アプリは一般公開を行わず、APIの活用例としての技術的なプロトタイプとして制作したものであり、あくまで個人学習およびポートフォリオ用として紹介しています。
MyRecipesについては、正規化を行い、子テーブルとして、Ingredients(食材)テーブルとInstructions(調理手順)テーブルを関連づけています。
各ページの概要
サインイン画面

Supabaseと接続し、メールアドレスとパスワードでログインします。
サインアップ画面

Supabaseと接続し、メールアドレスとパスワードでサインアップした後、ユーザーテーブルに、ID、名前、メールアドレスを登録します。
レシピサイト検索/お気に入り登録画面

楽天APIを用いて、カテゴリー別料理レシピを検索したり、取得したレシピをお気に入り登録することができます。
オリジナルレシピの登録画面

レシピ名、完成画像、必要な食材、調理手順を入力し、登録することができます。
レシピサイト、オリジナルレシピの一覧画面


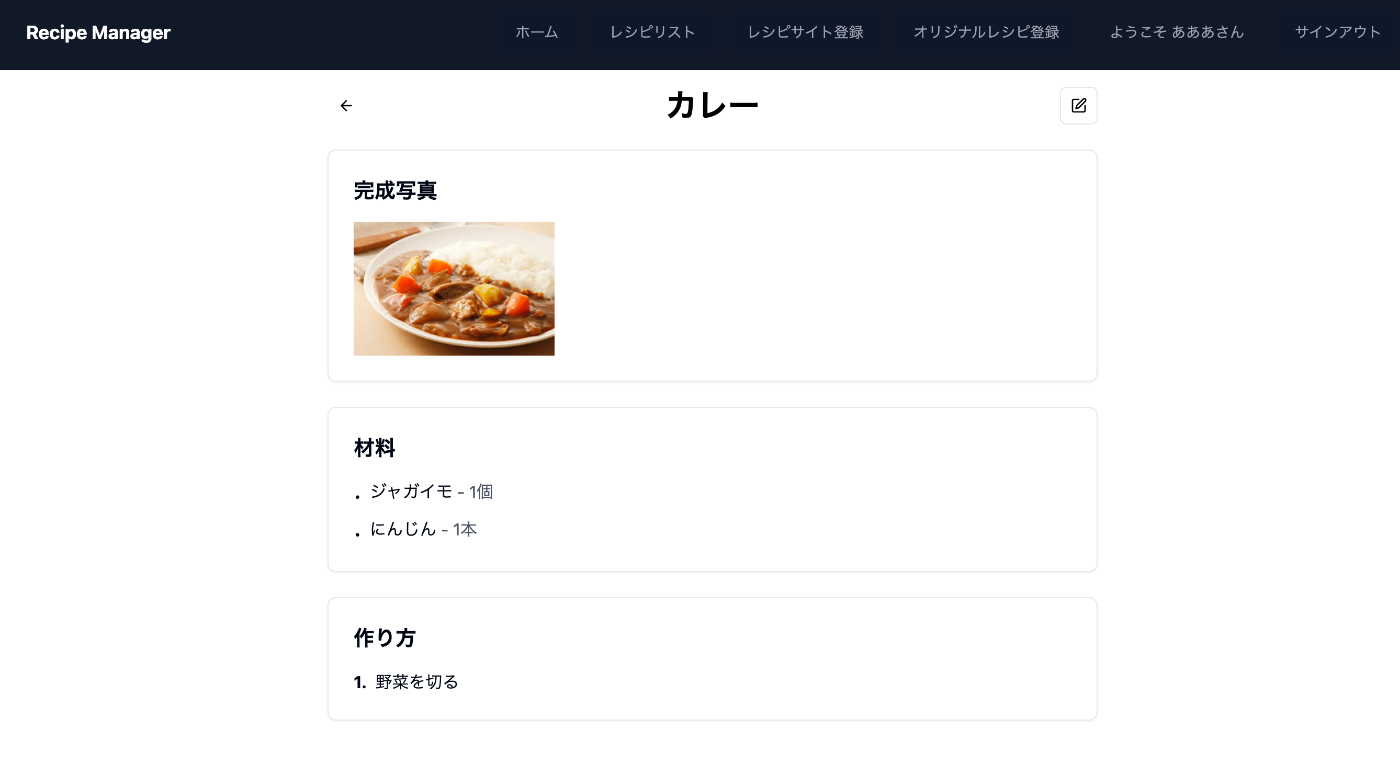

登録したレシピサイトやオリジナルレシピを一覧で見ることができ、一覧から削除することができます。
また、オリジナルレシピについては、編集をすることができます。
ホーム画面
各画面に遷移するためのリンク等が表示されています。
所感
このアプリを作成しようと思ったきっかけとしては、最近一人暮らしを始めて自炊をする機会が増えてきたことでした。
レシピサイトの検索や自分で考えたレシピを登録を手軽にできれば、もっと自炊がしやすくなるのではないかと思い、実際に作ってみることにしました。
今回は楽天の「レシピカテゴリAPI」と「カテゴリ別レシピランキングAPI」を使って、様々なレシピサイトを取得できるようにしました。
しかし、APIの導入に際して利用規約を十分に確認せず進めてしまったため、最終的にアプリの内容が公開基準を満たさないことが判明し、公開を見送る結果となりました。
この経験を通じて、APIやOSSなど、扱うサービスごとに利用規約やライセンスがあるという点は事前にしっかりと確認して、開発を進めていくこと重要性を再確認しました。安易に導入するのではなく、規約に基づいた適切な利用を心がける必要があると感じました。
開発についての所感としては、バックエンドを意識して開発を進めました。
今回、開発スピードが高速ということと、パフォーマンスの高さという点で、HonoとBunをバックエンドに採用しており、DBはSupabase、ORMとしてPrismaを採用しました。
以下の記事では、Node.js、Deno、Bunそれぞれのランタイム環境での、Honoのパフォーマンスを測定しており、Bunでの処理速度が最も高いです。
また、Bunランタイムのホットリロード機能によって、コードの修正を行うと即時反映されるため、ストレスなく開発を行うことができました。
DBについては、設計からきちんと学びたいと考え、「達人に学ぶDB設計 徹底指南書 ~初級者で終わりたくないあなたへ」を読み、テーブルの正規化を意識しながら設計を行いました。自身でテーブルを設計したことで、データの動きが分かりやすくなり、データに不整合が発生してしまうようなCRUD処理を行わないように意識しながら開発を進めることができました。
ER図の見方が分かり、データの流れが理解できると、フロントエンドの開発も効率的に行うことができると分かりました。
また、パフォーマンスの向上を目的として、データの加工処理は可能な限りフロントエンドではなくバックエンドで実施し、フロントエンドでは加工済みのデータを取得して表示する構成としました。特に、親子関係にあるテーブルデータについては、バックエンドで親子データを統合して一括で取得できるようにし、フロントエンドからは単一のリクエストで両方のデータを取得可能とすることで、不要なAPIコールを削減し、通信コストとレンダリング負荷の軽減を実現しました。
全体を通して、フルスタックな開発への理解が深まりました。
まだまだ理解しきれていない部分や向上できる部分がたくさんあるため、引き続き実践的な開発を通じて学んでいきたいと思います。
Discussion