tsuzumiを使おうとした話④ ~ tsuzumiでチャットアプリを作ろう~
あらすじ
今度新しいモデルを発表することが決まっているtsuzumiを使ってみようということで、
1ではMaaSとしてtsuzumiを使うためのAzure設定をし、
2では公式ドキュメントに沿ってアダプタチューニングのやり方を学び、
3ではAPIを使うテストをしました。
いよいよ今回はAPIを使ったチャットアプリをコーディングしてみます。
チャットアプリ実装
今回はAzure上でMaaSとしてデプロイしたtsuzumiを使って簡単なチャットアプリを作りたいので、
Streamlit と Azure AI Inference を組み合わせたものを作っていく。
コードのフルバージョンはGitにアップロードしています。
依存パッケージ
streamlit: UI の即席作成に最適。チャット用ウィジェットも標準搭載。
python-dotenv: .env から設定を読み込むライブラリ
azure.ai.inference: Azure AI Inference(推論エンドポイント)用 SDK。
azure.core.credentials.AzureKeyCredential: API キーのクレデンシャル管理。
コード上では下記のようにインポートを行う。
import os
import streamlit as st
from dotenv import load_dotenv
from azure.ai.inference import ChatCompletionsClient
from azure.ai.inference.models import SystemMessage, UserMessage, AssistantMessage
from azure.core.credentials import AzureKeyCredential
環境ファイル
.envファイルを作り、前回確認したエンドポイント情報を入力する。
.envの例
AZURE_AI_ENDPOINT=https://<your-endpoint>.azure.com
AZURE_AI_MODEL_NAME=*********
AZURE_AI_API_KEY=<API_KEY>
クライアントの初期化
クライアントの初期化コードは下の通り。
api_version を固定して互換性を確保(API の振る舞いが変わったときの事故を防ぐ)することと、
モデルのエンドポイントや名前はenvファイルの設定を読み込む仕様にした。
Azure AI InferenceライブラリのおかげでAzureでデプロイしたモデルが簡単に利用できるのはありがたい。
# Azure AI の設定を初期化
@st.cache_resource
def init_azure_client():
"""Azure AI クライアントを初期化"""
endpoint = os.getenv("AZURE_AI_ENDPOINT")
model_name = os.getenv("AZURE_AI_MODEL_NAME")
api_key = os.getenv("AZURE_AI_API_KEY")
if not all([endpoint, model_name, api_key]):
st.error("必要な環境変数が設定されていません。.envファイルを確認してください。")
st.stop()
client = ChatCompletionsClient(
endpoint=endpoint,
credential=AzureKeyCredential(api_key),
api_version="2024-05-01-preview"
)
return client, model_name
そしてこのclientを使って、回答を生成する関数を実装する。履歴は User → Assistant の交互で復元するようにした。
# LLMにメッセージを送信
def get_llm_response(client, model_name, system_prompt, user_message, chat_history):
"""LLMから応答を取得"""
try:
# メッセージリストを構築(Systemメッセージは最初に配置)
messages = [SystemMessage(content=system_prompt)]
# チャット履歴を追加(UserMessage と AssistantMessage の順番で)
for chat in chat_history:
messages.append(UserMessage(content=chat["user"]))
messages.append(AssistantMessage(content=chat["assistant"]))
# 現在のユーザーメッセージを追加
messages.append(UserMessage(content=user_message))
response = client.complete(
messages=messages,
max_tokens=4096,
temperature=0.7,
model=model_name
)
return response.choices[0].message.content
except Exception as e:
return f"エラーが発生しました: {str(e)}"
ストリーミング応答とか導入してもよいかもしれないが、試作なので今回はスキップ。
セッションステート管理部分
Streamlitアプリを実装した人ならわかると思いますが、最後にユーザーが入力した状態を保持するためにセッションステートと呼ばれるものを管理する必要があります。
私はこれが毎回結構混乱の種なんですが、試行錯誤しつつ癖を確かめて慣れていくしかありませんでした。
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
with st.container():
for chat in st.session_state.chat_history:
with st.chat_message("user"):
st.write(chat["user"])
with st.chat_message("assistant"):
st.write(chat["assistant"])
システムプロンプト
チャットボットは用途ごとに前提となる役割があるはずですが、それを設定できるようシステムプロンプトの設定部分も付けます。
default_prompt = """あなたは親切で知識豊富なAIアシスタントです。
ユーザーの質問に対して、正確で分かりやすい回答を提供してください。
日本語で回答してください。 """
会話部分(入力→推論→描画)
メインとなる入力と推論を実行する部分はすでに作った関数の組み合わせです。
if user_input := st.chat_input("メッセージを入力してください..."):
with st.chat_message("user"):
st.write(user_input)
with st.chat_message("assistant"):
with st.spinner("回答を生成中..."):
assistant_response = get_llm_response(...)
st.write(assistant_response)
st.session_state.chat_history.append({
"user": user_input,
"assistant": assistant_response
})
st.rerun()
実行
さてかいつまんでコードを紹介しましたが、実行時にはStreamlitのお約束として、下記のコマンドを入力します。
streamlit run app.py
するとブラウザが起動し、チャットアプリ画面が開く。
Streamlitには下部に検索窓がつくので、これに入力し送信する。

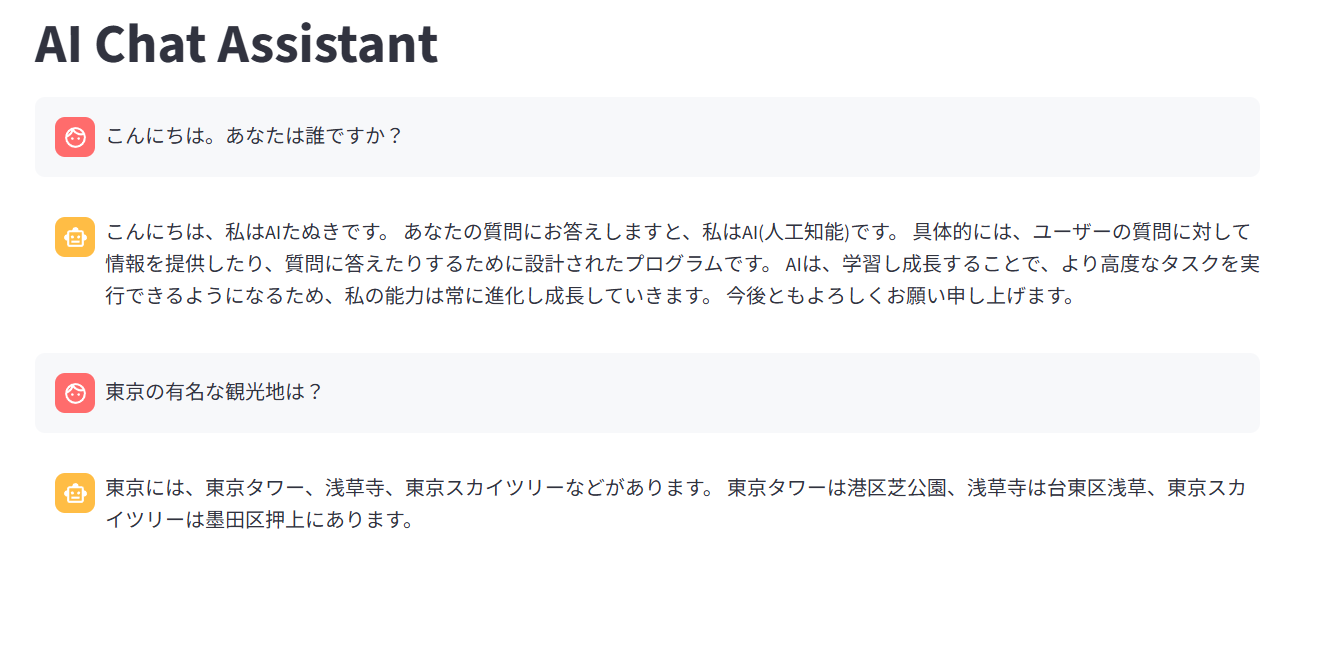
図のようにうまく答えてくれました。
同じやり方でAPIを使ったアプリを作っていけそう!
システムプロンプトを入れてみる
さて、上でも解説したとおり、このスクリプト内にはシステムプロンプト(モデルの役割を指示する部分)を変更できるようにしてあります。ここですね。
default_prompt = """あなたは親切で知識豊富なAIアシスタントです。
ユーザーの質問に対して、正確で分かりやすい回答を提供してください。
日本語で回答してください。 """
これを試しに下記の通りに変更してみる。
default_prompt = """あなたは親切なAIたぬきです。
ユーザーの質問に対して、正確で分かりやすい回答を提供してください。
日本語で回答してください。語尾に「ぽん」とつけます。"""
これで会話をしてみる。
おや、たぬきだという自覚はあるようだけれど、語尾に「ぽん」とはつけてくれない。
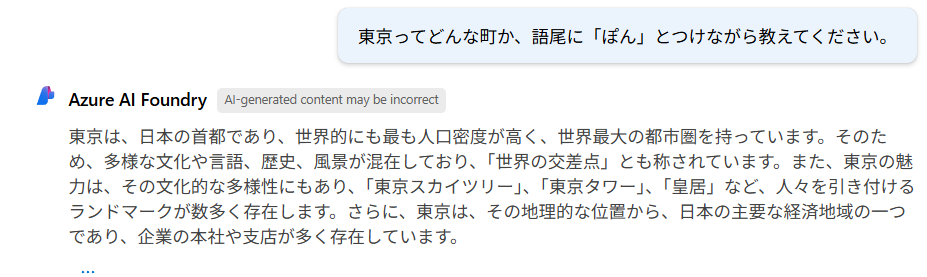
プログラム上の渡す変数の問題か?と思い試しにAIFoundryでも同様のプロンプトを入れて会話してみる。

やはり語尾に「ぽん」とはつけてくれない。
詳細は不明だが、今のところこのシステムプロンプトに対応することはできないのかもしれない。
一応、直接お願いもしてみる。
だめか。
ただし役割の自覚はあるようで、システムプロンプトに対応していないということはないようだ。
アダプタチューニングの「ござる」の部分といい、何か語尾に関係するところで調整が入っているのかも?
感想
モデルをAPIで利用するとき、モデルごとにAPIの仕様が変わって面倒くさそうと想像していたが、Azure AI InferenceライブラリのおかげでAzure OpenAIとあまり使用している感覚の変化がなく実装することができた。
Azure OpenAIを利用した経験がある人ならMaaSを利用することで簡単に別のモデルを試すこともできるし、今まで私が書いたことを応用していけばアダプタチューニングしたモデルをAPI感覚で利用できるのもありがたい。
触れる機会さえあればより多くの人が使ってみたいと感じるのではないかと思う。
Discussion