tsuzumiを使おうとした話② ~アダプタチューニングを試す~
前回のおさらい
前回、tsuzumiを使ってみるべくAzureの準備で右往左往してしまいましたが、
無事Azure AI Foundryでデプロイするところまでは進められました。
今回はその続きとして、上の記事でも紹介している公式のパワポ(tsuzumi on Azure MaaS ユーザーガイドv1.0) に沿ってチュートリアルを進めてみようと思います。
スムーズにいけばよいのですが。
※実はこれを書き始めた時点では実際の作業をしていません。
↓公式資料はこちら
どこからはじめるか
この公式のユーザーガイドに従うと、前回は「2.tsuzumiを使おう」のチューニング前の回答確認(P.22)までは終わっている状態です。
この続きから始めていきましょう。
アダプタチューニングとは
現在LLMを使って何かアプリを作ってみるとき、特に企業内ではRAGを作ってみたいというニーズが高いのではないかと推察します。
RAGはLLMにも読み取れるような形式で個々の保有するドキュメントのデータをデータベースに格納し、そのデータを参照することでLLMがデータベース内の文書情報に基づいた回答をしてくれるシステムで、
これがよく使われるのが会社のノウハウを回答してくれるチャットボット作りです。
tsuzumiでも似たようなユースケースは考えているようで、RAGを作ることについてもユーザーズガイドで言及されていますが、
「RAGを利用してtsuzumiを利用する場合は、精度向上のためにRAGの内容に合わせてアダプタチューニングを行うことを推奨します」
と記載されている通り、tsuzumiはアダプタチューニングが推奨されているよう。

図: tsuzumi on Azure MaaS ユーザーガイドv1.0 P42より
アダプタチューニングは元のモデルのパラメータは変更させず、モデルに層を追加しそこに学習を行う手法です。
モデルのパラメータの一部だけを変更するという点ではLoRAやQLoRAという名前を聞いたことがある!という人もいるかもしれませんが、
これらもアダプタチューニングの1種です。
転移学習
└─ パラメータ効率型チューニング(PEFT)
├─ アダプタチューニング(一般的な方法)
│ ├─ 通常のアダプタ(小MLPなど)
│ ├─ LoRA(低ランク行列で差分を表現)
│ └─ QLoRA(LoRA+量子化)
└─ Prefix Tuning / Prompt Tuning など
通常のアダプタチューニング、LoRA、QLoRAの違いをまとめるとこのようになるようです。
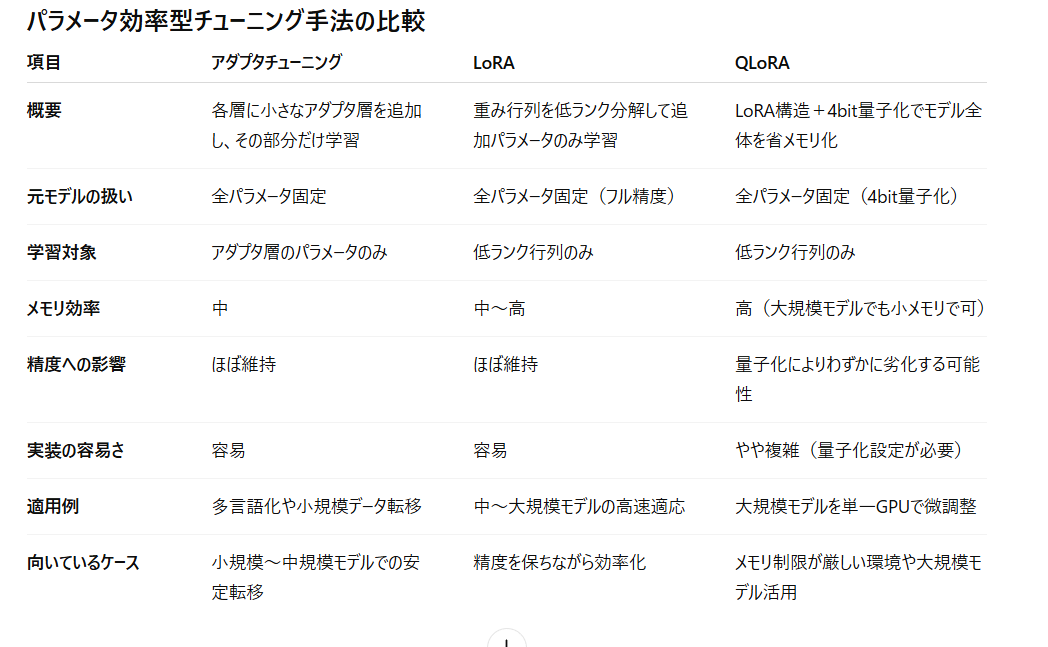
なるほど。(私も勉強をしながら書いているので、もし誤りがあったらご指摘ください。)
だいたいわかったような気がするので、実際に操作してみよう。
Azure上でtsuzumiのアダプタチューニングをする
公式ドキュメントのケースでは、アダプタチューニングにより回答の語尾が「~ござる」になるように学習を進めます。
AI Foundryの「微調整」を選び、tsuzumiを選びます。

Serverless APIを選んで、次へなどを押して進行していく。
トレーニングデータを選択するよう指示が出てくるので、↓からダウンロードしたデータをアップロードします。
チューニングの実行に少し時間がかかります。
さあ、うまくいくのか?

昼ごはんとか食べたり食器の片づけをしたりコーヒーを淹れたりして待つ。
1時間ほどかかった。

アダプタチューニング結果の確認
「このモデルを利用する」ボタンを押してデプロイを進める。
25/08/14現在、デプロイによりトークンの使用料のほか、時間当たり0.8ドルかかるらしい。
テスト用のモデルは使い終わったら消しておくのがよさそうだ。

このボタンを押して5分ほど経つとプロビショニング成功と表示された。
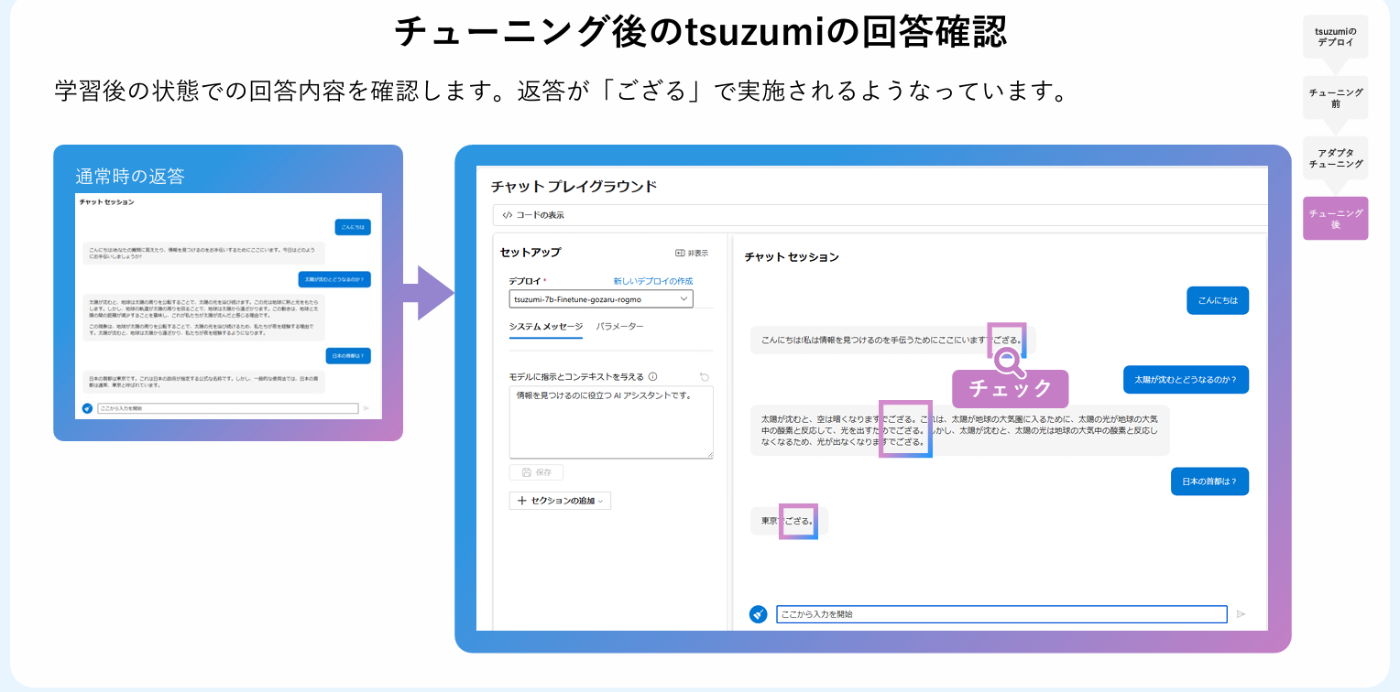
さあ、試しに回答がどう変わるかチャットプレイグラウンドで試してみよう。
チャットプレイグラウンドで先ほどのファインチューニングモデルを選択しチャットを投げかけてみる。

おや???普通の回答しかしない。
データがおかしいのか?と思い学習したデータを確認する。
{"messages":[{"role":"user","content":" 魚の種類はどっち?イコクエイラクブカとロープ"},{"role":"assistant","content":"イコクエイラクブカでござる。"}]}
{"messages":[{"role":"user","content":" ラクダはなぜ水なしで長く生きられるのか?"},{"role":"assistant","content":"ラクダは、長時間にわたってエネルギーと水分で満たされた状態を保つために、腰の脂肪を利用していますでござる。"}]}
これを見る限り学習データが間違っていたということもなさそうだ。
学習パラメータの違いだろうか?ガイド通りに進めたのだが…
公式ガイドを見るとパラメータはデフォルトのまま進める、と書いてあったものの
NTTが資料作成時に使ったらしい学習率パラメータと今回のデフォルトとなっている学習率パラメータが違うことが原因だろうか。

学習率パラメータをNTTの資料に合わせ、5e-6にしリトライしようとしたものの、
現在の私が使うAzureでは設定できないパラメータになっているようだ。

再現できず残念。
が、うまくいくと、返答に「ござる」がつくようになるのだとか。
感想
最近はモデルにプロンプトによる事前指示で「返事にはござるをつけてください」としておけば「ござる」とつけてくれると思う。
ただAzureのリソース上でのチューニングの仕方をこんなわかりやすくまとめてくれている資料もなかなかないと思うので、そこにちょっとした感動をした。
別のチューニングを行いたい場合や、企業の方が自社に合わせてモデルをチューニングする際に大いに参考にできると思う。
また次回に続く予定。
Discussion