Google Cloud Managed Service for Prometheusを使ってメトリクスとトレースを紐付け O11y 強化!
はじめに
こんにちは、逆井(さかさい)と申します。
この記事は Google Cloud Advent Calendar 2023 の 23 日目の記事になります 🎄
前日は @takashabe さんの Cloud Runでログとトレースを紐づけてObservabilityを高める でした。こちらの記事では「ログとトレース」を紐付け可観測性を高める方法が述べられています!
本記事では「メトリクスとトレース」を紐付けることでシステム状態の解析性を向上させる方法について書いていきます。オブザーバビリティにおいて、テレメトリーデータ(ログやトレース、メトリクスなど)が相互に紐付いて収集されていることはとても重要な要素です。
22、23日目の記事でテレメトリーを紐付ける方法を一気見していきましょう!(並びは偶然)
前提
メトリクスとトレースの紐付けのために、Google Cloud Managed Service for Prometheus(以下、GMP)や Cloud Monitoring, Cloud Trace を使用します。本記事では紐付ける方法についてフォーカスするため、これらプロダクトや使用方法についての説明は省略します。
メトリクスとトレースの紐付け(座学)
エグザンプラー(Exemplar)について
最初に、メトリクスとトレースを紐付けるために用いるエグザンプラーを簡単に紹介します。Exampler ではなく、Exemplar です!以下、エグザンプラーと表記します。
Prometheus が収集するような OpenMetrics 形式のメトリクスは以下のようなフォーマットで生成されます。
# TYPE foo histogram
foo_bucket{le="0.01"} 0
foo_bucket{le="1"} 11
foo_bucket{le="10"} 17
foo_bucket{le="+Inf"} 17
foo_count 17
foo_sum 324789.3
これは一般的な Histgram 型メトリクスのサンプルです。見馴染みの深い方も多いでしょう。このメトリクスに対して OpenMetrics エグザンプラーを用いて付与情報を追加することができます。
エグザンプラーとしてトレース ID を付与したメトリクスは以下のような形です。# の後にラベルとして情報を追加することができます。
# TYPE foo histogram
foo_bucket{le="0.01"} 0
foo_bucket{le="1"} 11 # {trace_id="KOO5S4vxi0o"} 0.67
foo_bucket{le="10"} 17 # {trace_id="oHg5SJYRHA0"} 9.8 1520879607.789
foo_bucket{le="+Inf"} 17
foo_count 17
foo_sum 324789.3
foo_created 1520430000.123
Google Cloud のサービスを使う
GMP を使うとエグザンプラーを取り込むことができます!!
また取り込んだメトリクスを Cloud Monitoring の Metrics Explorer で可視化すると、エグザンプラーから関連するトレース情報をダッシュボード上にプロットし Cloud Trace への遷移が可能です。
以降のパートでは、サンプルアプリケーションを用いることでアプリケーションメトリクスを取得し、レイテンシが大きくなった際のエグザンプラーからトレース情報に遷移しアプリケーション内部のパフォーマンスを詳細に見ていきます。これによりトラブルシューティングを簡便化でき、エグザンプラーーを使ったメトリクスとトレース情報の紐付けのメリットをデモ的に紹介します。
エグザンプラーがサポートされている GMP コレクションのバージョンや、メトリクスの型(例えば、GMP の場合は、ヒストグラム型に適用されたエグザンプラーのみ取り込むことが可能)、エグザンプラーの保持期間についてはドキュメントを参照してください。
メトリクスとトレースの紐付け(やっていき)
まずは監視対象であるアプリケーションのデプロイと、監視に必要な準備をします。
構築する全体像は以下です。今回は Google Kubernetes Engine(GKE)上にアプリケーションをデプロイし検証を進めていきます。

アプリケーションのデプロイ
アプリケーションは Go で簡単なサーバーを書きました。特筆すべき点は以下です。
- OpenTelemetry を使って分散トレース計装
- prometheus/client_golang パッケージを使ってメトリクス計装
-
/エンドポイントに対するリクエストの Duration を Histgram 型 メトリクスとして収集 - メトリクスにエグザンプラーとして
trace_id/span_id/project_idを付与
※ これらのパラメーターは Cloud Trace と統合 するために必要になります - そのメトリクスを
/metricsエンドポイントで配信
-
このアプリケーションを Kubernetes にデプロイして、/metrics エンドポイントからメトリクスをスクレイピングしてみると以下のようなメトリクスを取得でき、エグザンプラーとしてメトリクスにトレース情報(と Google Cloud の Project 情報)が付与されていることもわかります。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
gcp-advent-calendar-58d46cb84d-pbtgl 1/1 Running 0 8s
$ curl -H 'Accept: application/openmetrics-text' localhost:8080/metrics
# HELP http_request_duration_seconds A histogram of the HTTP request durations in seconds.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.01"} 0
http_request_duration_seconds_bucket{le="0.02"} 0
http_request_duration_seconds_bucket{le="0.04"} 0
http_request_duration_seconds_bucket{le="0.08"} 0
http_request_duration_seconds_bucket{le="0.16"} 0
http_request_duration_seconds_bucket{le="0.32"} 1 # {project_id="***",trace_id="656858120dc09acecf8baa331d736577",span_id="0a9cf4dc142a9fa6"} 0.240129272 1.7034402922686768e+09
http_request_duration_seconds_bucket{le="0.64"} 1
http_request_duration_seconds_bucket{le="1.28"} 1
http_request_duration_seconds_bucket{le="2.56"} 1
http_request_duration_seconds_bucket{le="5.12"} 1
http_request_duration_seconds_bucket{le="10.24"} 1
http_request_duration_seconds_bucket{le="+Inf"} 1
http_request_duration_seconds_sum 0.240129272
http_request_duration_seconds_count 1
アプリケーションのコード全文
package main
import (
"context"
"fmt"
"log"
"math/rand"
"net/http"
"time"
texporter "github.com/GoogleCloudPlatform/opentelemetry-operations-go/exporter/trace"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"go.opentelemetry.io/contrib/detectors/gcp"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/sdk/resource"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.21.0"
)
var tracer = otel.Tracer("EXEMPLAR-APP")
func main() {
// OpenTelemetry Traces
tp, err := setupTracerProvider()
if err != nil {
log.Fatalf("Error setting up trace provider: %v", err)
}
defer func() { _ = tp.Shutdown(context.Background()) }()
// Define Metrics
requestDurations := prometheus.NewHistogram(prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "A histogram of the HTTP request durations in seconds.",
Buckets: prometheus.ExponentialBuckets(0.01, 2, 11),
})
registry := prometheus.NewRegistry()
registry.MustRegister(
requestDurations,
)
// Metrics Endpoint
http.Handle(
"/metrics", promhttp.HandlerFor(
registry,
promhttp.HandlerOpts{EnableOpenMetrics: true}),
)
// Main Handler
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
ctx := context.Background()
ctx, span := tracer.Start(ctx, "Root Span")
defer span.End()
start := time.Now()
func1(ctx)
func2(ctx)
// Dummy Logic
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// Record Metrics
duration := time.Since(start).Seconds()
traceID := span.SpanContext().TraceID().String()
spanID := span.SpanContext().SpanID().String()
requestDurations.(prometheus.ExemplarObserver).ObserveWithExemplar(
duration, prometheus.Labels{
"project_id": "***",
"trace_id": traceID,
"span_id": spanID,
},
)
fmt.Fprintf(w, "Request took %v seconds\n", duration)
})
log.Fatalln(http.ListenAndServe(":8080", nil))
}
func func1(ctx context.Context) {
_, span := tracer.Start(ctx, "Func1")
defer span.End()
time.Sleep(time.Millisecond * time.Duration(rand.Intn(100)))
}
func func2(ctx context.Context) {
_, span := tracer.Start(ctx, "Func2")
defer span.End()
rand.NewSource(time.Now().UnixNano())
if rand.Float64() < 1.0/100.0 {
time.Sleep(3 * time.Second)
} else {
time.Sleep(10 * time.Millisecond)
}
}
func setupTracerProvider() (*sdktrace.TracerProvider, error) {
ctx := context.Background()
projectID := "***"
exporter, err := texporter.New(texporter.WithProjectID(projectID))
if err != nil {
return nil, err
}
res, err := resource.New(ctx,
resource.WithDetectors(gcp.NewDetector()),
resource.WithTelemetrySDK(),
resource.WithAttributes(
semconv.ServiceNameKey.String("EXEMPLAR-APP"),
),
)
if err != nil {
log.Fatalf("resource.New: %v", err)
}
tp := sdktrace.NewTracerProvider(
sdktrace.WithBatcher(exporter),
sdktrace.WithResource(res),
)
otel.SetTracerProvider(tp)
return tp, nil
}
アプリケーションの K8s マニフェスト全文
apiVersion: apps/v1
kind: Deployment
metadata:
name: gcp-advent-calendar
labels:
app.kubernetes.io/name: gcp-advent-calendar
spec:
selector:
matchLabels:
app.kubernetes.io/name: gcp-advent-calendar
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/name: gcp-advent-calendar
spec:
containers:
- image: ghcr.io/keisukesakasai/gcp-exemplar-app:latest
name: gcp-advent-calendar
ports:
- name: metrics
containerPort: 8080
メトリクス監視の構成 with GMP
GKE の場合、Autopilot の場合は 1.25 以降、Standard の場合は 1.27 以降で GMP コンポーネントであるマネージドコレクション(Prometheus ベースのコレクタ)が有効化されています。
$ kubectl get po -ngmp-system
NAME READY STATUS RESTARTS AGE
alertmanager-0 2/2 Running 0 38h
collector-b5sbg 2/2 Running 0 38h
collector-b8l4g 2/2 Running 0 38h
gmp-operator-8547d84898-pcjn9 1/1 Running 0 38h
rule-evaluator-74bc75b4f7-2h6pq 2/2 Running 2 (38h ago) 38h
先ほどデプロイしたアプリケーションのメトリクスを取り込むために PodMonitoring カスタムリソースを作成します。PodMonitoring で適切な監視対象の設定を行うことで、アプリケーションのメトリクスを自動でスクレイピングし収集してくれます。
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: gcp-advent-calendar
labels:
app.kubernetes.io/name: gcp-advent-calendar
spec:
selector:
matchLabels:
# 監視対象をラベルで選択
app.kubernetes.io/name: gcp-advent-calendar
# 3 秒間隔で /metrics エンドポイントのメトリクスを収集
endpoints:
- port: metrics
interval: 3s
$ kubectl get podmonitoring
NAME AGE
gcp-advent-calendar 4s
さて、収集したメトリクスを見ていきましょう
アプリケーションから収集したメトリクスである http_request_duration_seconds を Metrics Explorer のヒートマップで見てみましょう。
見慣れない方もいるかもしれませんが、見方は簡単で、X 軸方向は時間、Y 軸方向は Histgram の箱(Duration の秒数)があり、色がその箱に含まれているデータ数(分布)になります。結果を見ると、基本的に 1 秒弱でレイテンシーが分布しているようです。白線で見えている 95 パーセンタイルの線もその辺をうようよしていることが確認できます。
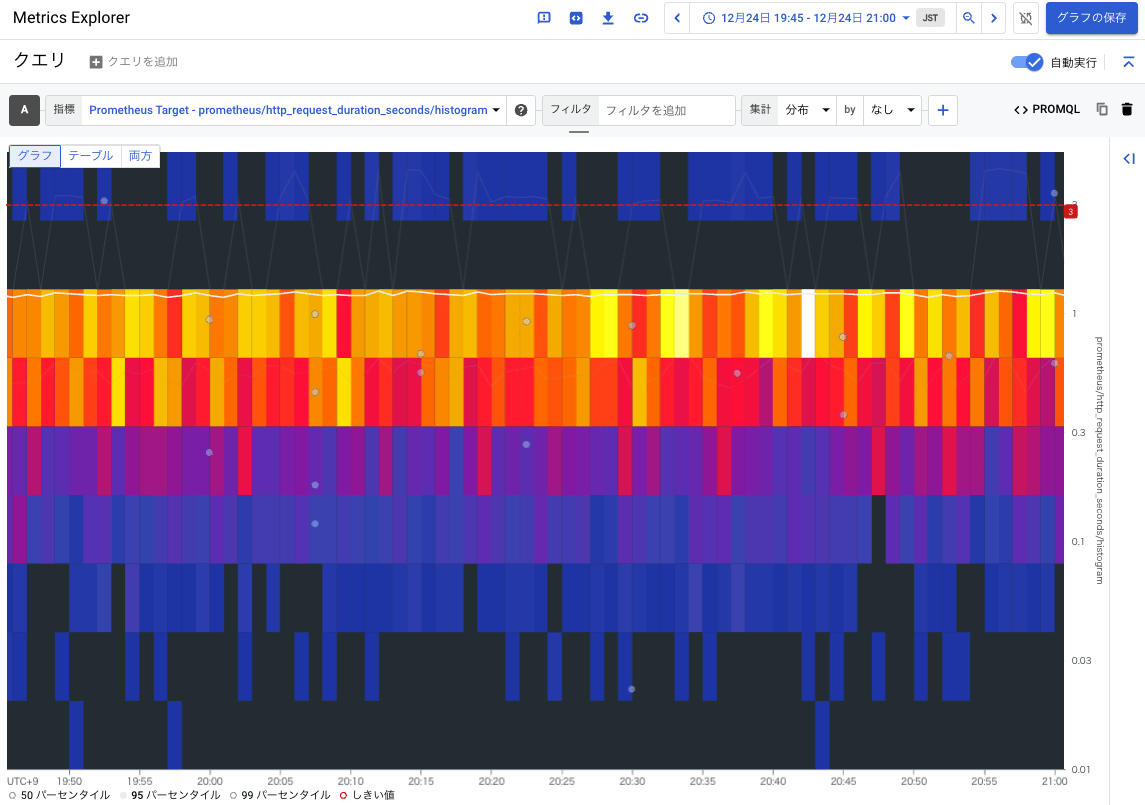
グラフの中にいくつかポイントがあることが分かりますが、これがエグザンプラーでトレース情報が付与されたメトリクスです。ポイントを押下すると、トレース情報に基づいて、Cloud Trace の画面を表示してくれます。アプリケーションの各処理でどのくらいの処理時間がかかっているかが分かります。(下図は典型的なリクエストの分散トレース)

ヒートマップ上部を見ると、稀に 3 秒くらい応答に時間を要しているリクエストがありそうなこともわかります。※ アプリケーションに 1 % くらいの割合で Sleep を仕込んでいるため
ここにも、エグザンプラーによるサンプルトレースがあるのでクリックしてみます。その結果が以下です。上で確認した典型的なリクエストのトレースに比べると、Func2 での処理時間が大きくなっていることが分散トレースから簡単に取得することができます 🎉🎉

このように、メトリクスと分散トレースを紐付けることで、メトリクスの異常値を俯瞰し、さらにそこからアプリケーション内部の処理を細かく見ることができる分散トレースへドリルダウン的に探索しにいけます。エグザンプラーを使ったテレメトリーの紐付けはトラブルシューティングにおいて便利です。ぜひ検討してみてください!
まとめ
GMP や Clout Monitoring, Cloud Trace を使ってメトリクスとトレースを紐づけてみました。オブザーバビリティにおいて各テレメトリーが紐付いていることは大事ですので紹介しました。また、聞き馴染みのないエグザンプラーについて知るきっかけになればと思います!
この記事ではあまり Histgram やエグザンプラーについて詳細に触れられていません。
Cloud Native Days Tokyo 2022 のセッションでもう少し細かく解説したのでもし興味がある方がいらっしゃったらぜひ見てみてください。
それでは皆さん良いお年を!
Discussion