Terraformで生成したLambda関数のコードをリポジトリで管理してデプロイはCIでやりたい
インフラリソースの準備
まず Lambda 自体を Terraform で作る。
この時点で適当にGitリポジトリを生成し、IaC関連のコードは infra というディレクトリに配置することとする。
以下のコードで terraform apply したら "HelloWorldLambda" という名前の関数ができる。
ソースコード
terraform {
required_version = "~> 1.7"
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.40"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}
variable "bucket_name" {
description = "The name of the S3 bucket to deploy functions"
type = string
}
resource "aws_s3_bucket" "lambda_code_bucket" {
bucket = var.bucket_name
}
resource "aws_s3_bucket_public_access_block" "this" {
bucket = aws_s3_bucket.lambda_code_bucket.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
resource "aws_iam_role" "lambda_execution_role" {
name = "lambda_execution_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole",
Principal = {
Service = "lambda.amazonaws.com"
},
Effect = "Allow",
},
]
})
}
resource "aws_iam_policy" "lambda_logging" {
name = "lambda_logging"
description = "IAM policy for logging from a lambda"
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Action = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
Resource = "arn:aws:logs:*:*:*"
},
]
})
}
resource "aws_iam_role_policy_attachment" "lambda_logs" {
role = aws_iam_role.lambda_execution_role.name
policy_arn = aws_iam_policy.lambda_logging.arn
}
data "archive_file" "lambda_zip" {
type = "zip"
output_path = "${path.module}/lambda_function.zip"
source {
content = "def handler(event, context):\n print('Hello World')\n return 'Hello World'"
filename = "main.py"
}
}
resource "aws_s3_object" "lambda_code" {
bucket = aws_s3_bucket.lambda_code_bucket.bucket
key = "lambda_function.zip"
source = data.archive_file.lambda_zip.output_path
etag = filemd5(data.archive_file.lambda_zip.output_path)
}
resource "aws_lambda_function" "this" {
function_name = "DeployExampleLambda"
s3_bucket = aws_s3_bucket.lambda_code_bucket.bucket
s3_key = aws_s3_object.lambda_code.key
handler = "main.handler"
runtime = "python3.10"
role = aws_iam_role.lambda_execution_role.arn
timeout = 30
}
※ プロファイルは適当なものを設定しておく (e.g. export AWS_PROFILE=handson-profile)
AWSマネージメントコンソールで Lambda 関数が存在することを確認し、テスト実行をしてみる。
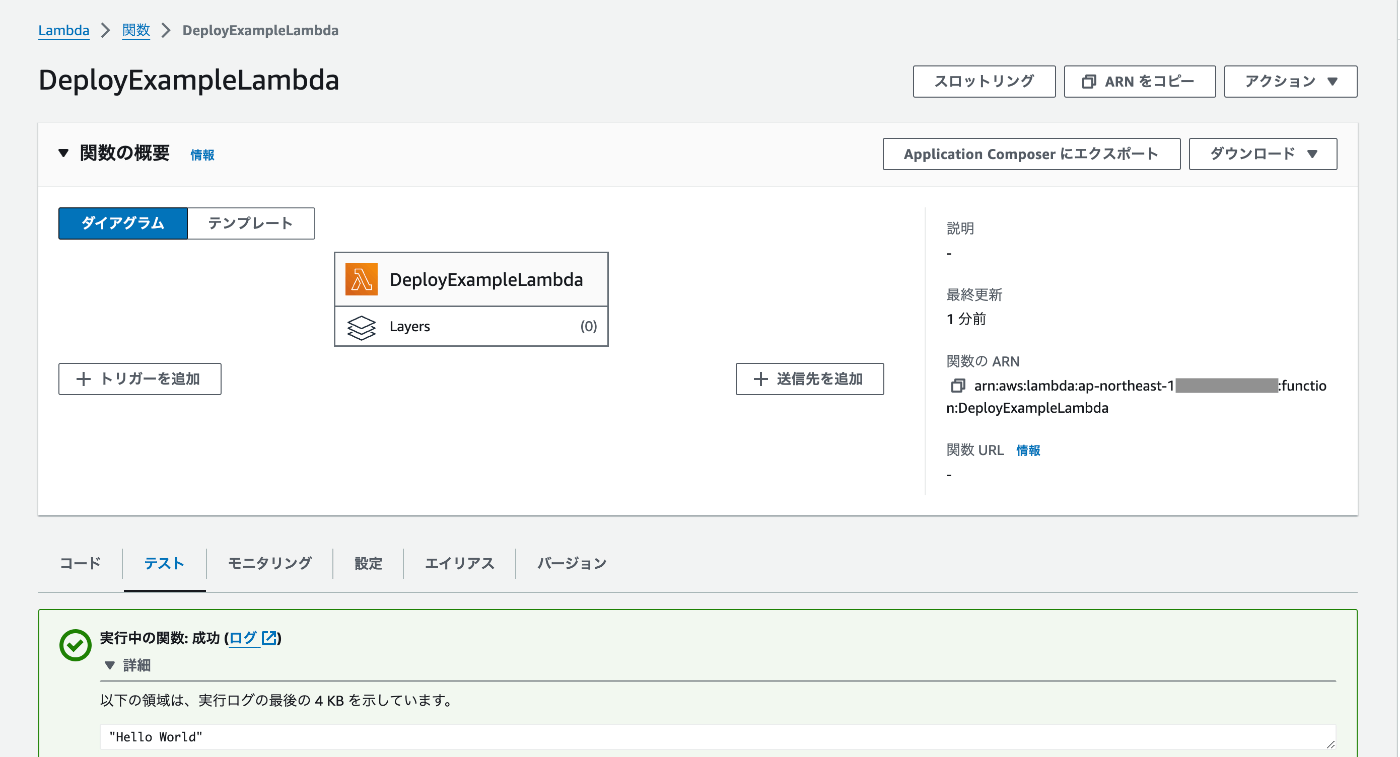
上記のような出力になればこの節の内容は問題なし。
Pythonの環境構築
今回は Python で実装するのでまずは環境構築を行う。
関数のソースコードは functions 以下で管理するので、この時点でディレクトリを生成しておく。
Pipenv のインストール
Macの場合は以下
$ brew install pipenv
Pipenv を採用する理由は以下。
- バージョン切り替えの利便性が上がるため
- 仮想環境を用いて他の環境との干渉を防げるため
- パッケージの管理が行いやすくなるため
同様のことができるものであれば Pipenv 以外で代替しても問題なし。
Pipenv による Python のインストール
今回はプロジェクトのルートから関数本体とIaCとでディレクトリが分けるようにしているので、前者に移動してインストールを実行する。
$ cd functions
$ pipenv --python 3.10
仮想環境のアクティベート
$ pipenv shell
終了するときは exit を実行する。
仮想環境自体を削除したい場合は pipenv --rm を実行する。
パッケージのインストール
依存関係のインストール
$ pipenv install pandas numpy
開発やテストで利用するパッケージのインストール
$ pipenv install --dev jupyter
関数コードの準備
まずサンプルとして適当なコードを用意する。
ただ、実践的なものは他のパッケージと依存関係を持つはずなので、適当に numpy や pandas を使うようにしている。
import json
import numpy as np
import pandas as pd
# NOTE: 依存パッケージを含めて関数をアーカイブして、それがデプロイできるかをチェックすることが肝要なので内容は適当
def handler(event, context):
array = np.array([1, 2, 3, 4, 5])
array_sum = np.sum(array).item()
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
df_sum = df.sum().to_dict()
return {
'statusCode': 200,
'body': json.dumps({
'numpy_sum': array_sum,
'pandas_sum': df_sum,
})
}
レイヤーの追加
pandas などを利用するには以下のようなレイヤーと呼ばれるものを追加する必要がある。
以下から用途にあったレイヤーを探せる。
今回だと、リージョンは ap-northeast-1 でランタイムのPythonバージョンである3.10と一致している arn:aws:lambda:ap-northeast-1:770693421928:layer:Klayers-p310-pandas:13 を選択した。
Terraform で、Lambdaの引数として上記を指定する。
$ git diff
diff --git a/infra/lambda.tf b/infra/lambda.tf
index e23785a..39d162a 100644
--- a/infra/lambda.tf
+++ b/infra/lambda.tf
@@ -27,4 +27,5 @@ resource "aws_lambda_function" "this" {
role = aws_iam_role.lambda_execution_role.arn
timeout = 30
+ layers = ["arn:aws:lambda:ap-northeast-1:770693421928:layer:Klayers-p310-pandas:13"]
}
編集したら terraform apply して反映する。
手動デプロイによる動作確認
適当に package という ZIP ファイルを作るための作業用ディレクトリを作って、アーカイブを AWS CLI でデプロイする。
$ mkdir package
$ cd package
$ cp ../main.py .
$ zip -r lambda_function.zip .
$ aws lambda update-function-code \
--function-name DeployExampleLambda \
--zip-file fileb://lambda_function.zip
デプロイ後に、マネージメントコンソールで以下のような出力が得られたらOK.

Github Actions による自動デプロイ
Github Secrets の設定
以下を各々設定すること
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEYAWS_REGIONLAMBDA_FUNCTION_NAME
このサンプルでは本番やステージングを区別しないので、"Repository secrets" を利用
ワークフローの定義
name: Build and Deploy Lambda Function
on:
push:
paths:
- functions/main.py
jobs:
build_and_deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Package Lambda function
run: |
cd functions
zip -r lambda_function.zip main.py
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
- name: Deploy to AWS Lambda
run: |
aws lambda update-function-code --function-name ${{ secrets.LAMBDA_FUNCTION_NAME }} --zip-file fileb://functions/lambda_function.zip
これで push されたときに functions/main.py が変更されていたら自動でデプロイされるようになる。
Discussion