単体テストの考え方/使い方を読んでテストについて考える
なぜ単体テストを書くのか
- 質の悪いテストはテストなしの状態と同様持続的な成長を妨げる。
- 単体テストを行ったという事実を作り上げることを目的としてテストを書いて質の良いテストになるわけがない
- 作成した単体テストがプロダクトにどう役立つのかを考えれていない
- こういった考え方でテストを書いている人はコピペで呼び出しとアサーションだけを変えたようなコピペテストを量産しがち
- 確かに、このようなテストは有害になってしまうかもしれない
- テストケースの数を増やしたからといって単体テストの目的が達成されるわけではない
- テストコードは多ければ多い方がいいと思っているエンジニアが多い。コードは資産ではなく負債です。
- テストコードはプロダクションコードとは別物と思っているエンジニアが多い。テストコードもプロダクションコードと同じ姿勢で向き合うべきだ。
- コード網羅率は行数しかみていないのでテストスイーツの質は評価できない
- そこで、分岐に目を向けた分岐網羅率がある。
- これもテストスイートの質を判断することはできない
- 分岐網羅は実行しただけで検証されない確認不在のテストがあるとき、テストの質を判断できないから
- 加えて、外部ライブラリまでは分岐カバレッジは見れないから
- カバレッジはテストの質を判断するうえで重要な指標だが、このような数字にとらわれるのはあんまり良くない
メモ
- テストがコードが動くことを担保するものという認識になってる人が多そう
- その一面もあると思うけどそれは副産物であってテストは持続可能な開発を実現するための設計手法だと思う
- ただ、これはテストするエンジニアの分布、特に日本のSIer文化においてはしょうがないとも思う
- そこまでSIerの実態は知らないが、綿密に設計されたものを仕様通りに動かすことが使命なのでそれを担保、証明するためのものがテストになっているのだと思う。
- だから、エビデンスやカバレッジなどの可視化できるものを欲しがり、本質的ではない作業が蔓延してるのだと思う。
- ただ、テストにかける工数はたぶんめちゃくちゃ使ってて、大規模サービスをいろんな角度からテストしてるとも思うのでそれはすごいと思う
- ただ、こういった目的のもとテストを書くことを強制されるとテストを書くことが目的となり、質の悪いテストを量産する風潮にもつながると思う
- テストをなぜ書くのか、テストの目的はなんなのかを自分で気づき、ちゃんと考えてテストを書くようになるにはけっこうなハードルがあると思う。
単体テストとは何か?
- 古典学派とロンドン学派がある
- 古典学派のバイブルはTDD。共有依存以外はモックを使わない派閥。
- ロンドン学派は全ての依存関係をモックにする派閥。
- 単体テストの定義は以下のように書かれている
1. 「単体」と呼ばれる少量のコードを検証する
2. 実行時間が短い
3. 隔離された状態で実行される
隔離について
ロンドン学派
-
1の単体という括り方も微妙に違うのだけど大きく違いがでているのが3番の隔離について
-
ロンドン学派ではテスト対象のクラスから協力者オブジェクト(collaborator)を隔離することだと考えている。なので、依存関係を全てテストダブルに置き換えようとする。
-
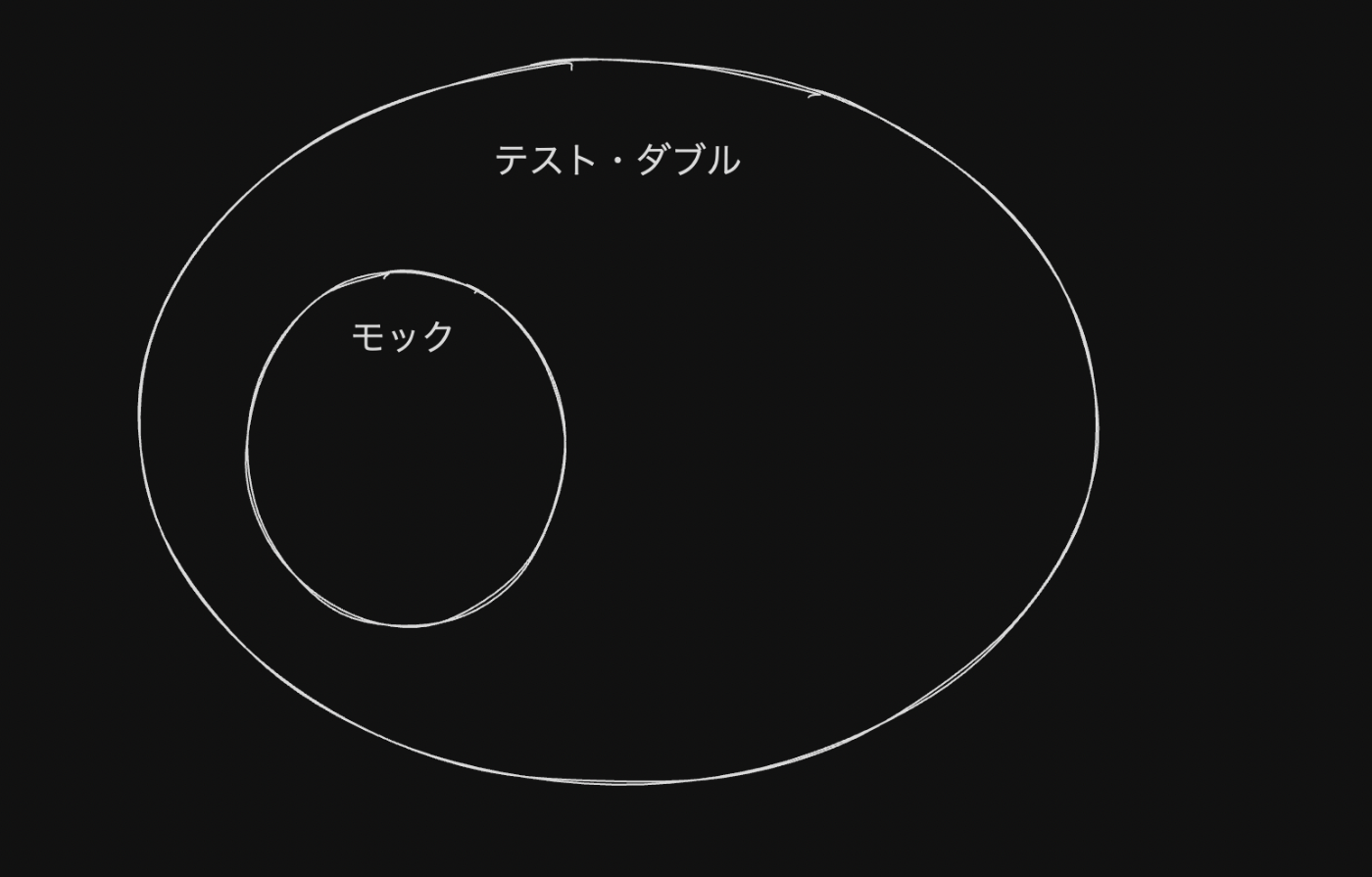
テスト・ダブルとモックは厳密には違う意味合いだが、ほぼイコールのニュアンスで使われていることが多い
-
テスト・ダブルのダブルのせいでよく意味がわかってなかったけどスタントマンの英語(stunt double)から来てるらしい
-
テスト・ダブルとはテストで使われるすべての種類の偽りの依存のこと
-
モックはそのなかの一種といえる
- ロンドン学派は一度に一つのクラスしか検証しないという指針がある。なので、ロンドン学派の
ユニットが指すものは必然的にクラスになる
古典学派
- ロンドン学派が考える隔離はテスト対象から他のあらゆる依存を隔離することだと考えており、これはコードベースでの隔離である。
- 一方、古典学派はテストケースを隔離すると考えており、テストケース間で影響を与えてしまうような共有依存が最低限のテスト・ダブル対象となり、モックにする対象は少なくなる。
- 古典学派は
一つのユースケースをユニットとしてテストする感じなので、テストする対象が一つのクラスになるとは限らない。これもロンドン学派との違い。

依存の種類
- ロンドン学派はほぼ全ての依存に対してテスト・ダブルを使用しようとするが、value objectやプリミティブ型の値に関してはテスト・ダブルを使用しなくても良いとしている

古典学派とロンドン学派の違い
ロンドン学派の利点
- 検証の粒度が細かい。一つのテストケースで一つのクラスしか検証しないため粒度が細かくなる
- 依存関係が複雑でもモックを使うことでテストが容易
- テストが失敗した時に原因を特定しやすい。依存はすべてテスト・ダブルのためテストが失敗したらテスト対象のクラスが原因であることがほとんど
ロンドン学派が微妙とする意見
- 粒度が細かいことは利点にならない。真に単体としてテストすべきなのは現実世界のビジネスサイドの人たちが求める振る舞いのため、ロンドン学派の考え方だと一つのユニットテストでその振る舞いを検証できるとは限らなくなる
- 確かに複雑な依存関係をテスト・ダブルにすることでテストを容易にすることができるが、それは設計が良くないという問題に向き合ってないことになる
- コードの修正とテストの実施をちゃんとしていれば古典学派のやり方でもテストが失敗したときの原因箇所の特定は容易なはずである
- 一般的にロンドン学派の方が実際のプロダクションコードと密接に結びついており、古典学派的にはあまり賛同できない
結合テストとe2e
- ロンドン学派では実際のcollaboratorオブジェクトを使って行うテストは全て結合テストとなるため、古典学派が書いた単体テストはロンドン学派的には結合テストに分類される
- 結合テストとe2eテストは同じようなテストに見えるが、一般的にe2eの方がプロセス外依存を多く含むことになる。
メモ
- 古典学派の方がビジネスサイドよりというかDDDっぽい開発組織で好まれそうな書かれ方
- たしかにビジネスサイドが求める機能の振る舞いを単体テストとしてテストするほうがアプリケーションの機能をテストしており質が高いと考えられなくもない
- そして、複雑な依存のモック化が設計が悪いという話はまじでそうだなと思った
- 本書ではクラスという言葉が使われるのでJavaやC#みたいな言語、つまりエンプラ系のやっぱり世界の話だよなーという感想
- 個人的には古典学派の考え方はテスト至上主義で設計至上主義な感じがしてしまう。開発者に要求しているものが多いというか、スパルタといか、なんというか
- 設計が悪いのは見逃せないことなんだけど、依存を注入するようなレイヤードアーキテクチャで複雑な現実のビジネス要件を古典学派的にテストしようとすると依存関係の解決にとても労力がかかりそうと思う。それを全てモック化できるので開発者のテストを書く心的ハードルは下がるんじゃないかなと思う
- 特にGoやTypeScriptなんかはクラスの概念がなく関数単位でのテストが相性いいイメージもあるのでロンドン学派的な単体の捉え方な人が多いんじゃないか
- ただ、ロンドン学派的なテストがよりプロダクションコードに密接に結びついているのはテストを書くのがある意味、難しいと思っていて、脳死でモック化してテスト書いているとテストを成功させるようにテストを書いていたり、検証しているようで何も検証していなかったりといったことが起こりそう。
- テストを書きながらリファクタリングをし、プロダクトコードを実装の過程で洗練させていくことが染み付いている開発チーム(つまりTDDやテストファースト、リファクタリングなどが染み付いている組織)なら、それは古典学派的なテストのほうがいいのだろう
- ただ、そうでなければ複雑なビジネス要件を満たしたプログラムの依存関係は決してそんなにシンプルなものではないだろうからテストの前の依存関係の解決には大きな労力を使うことになり、開発スピードの低下に繋がりかねない。
- 古典学派の単体テストでカバーしているような振る舞いテストはロンドン学派的には結合テストを用意することで同じようにカバーできるので、プロダクションコードもテストコードも複雑になりすぎないように注意深く、モックを使って小さくテストを書いていくロンドン学派的な考えに個人的には賛同してしまう。
単体テストの構造的解析
- 準備(Arrange)、実行(Act)、確認(Assert)の3つのフェーズでテストを構成することをAAAパターンという
- given, when, thenみたいなものと理解。たぶん、これはBDDの文脈で使われることが多い??
- 一つのテストケースに複数のフェーズを用意すべきでない
- if文を使うべきではない。条件分岐を書くということは多くのことをテストしようとしていることを示唆しているし、読みづらくなるし、保守コストがかかる
- 通常、3つのフェーズの中では準備フェーズが最も長くなる。場合によってはファクトリ関数なんかを用意することも有用
- そして、実行フェースは通常1行で済むはず。これが1行で済まないのであればAPIの設計に欠陥がある可能性がある。
- 確認フェーズが大きくなりすぎるようであればプロダクションコードの抽象化がうまくいっていない可能性がある
- テストの後始末は通常単体テストであれば発生しないはず。発生するのであればそれは結合テストの可能性が高い。
- 3つのフェーズは空白行で区切れば十分なはず。ただし、一つのフェーズで複数の空白行を使用したいケースもあるのでそういった場合はコメントで区切ると良い
- テストフィクスチャ。全てのテストケースが毎回同じ結果になるように共通した処理を実行する。
- アンチパターンとして各テストケースの準備フェーズをこのテストフィクスチャとして実行すること。
- これはケース間の結びつきが強くなりすぎるうえに、テストケースが読みづらくなる。
- これを解決するのはファクトリメソッドを導入することである。ただし、単純な準備であればファクトリメソッド自体不要である。
テストの命名
- 最も役に立たない命名。
{テスト対象関数}_{事前条件}_{想定する結果}
getUser_when_new_user_expect_success - 厳格な命名規則に縛られないようにする。自由に柔軟に
- ドメインエキスパートのような非開発者が読んでも伝わるように
- アンスコを使って単語を区切る
- テストはコードではなく振る舞いをテストするためメソッド名を含めるべきでない。
- ただし、ビジネスロジックが含まれないユーティリティークラスは例外。
-
shoule beをテスト名に含めるのはアンチパターン。isにすべき。これは単体テストは振る舞いを事実として伝えるものとしているからである。
メモ
- パラメーターテストで書くことにこだわってテストケースが複雑化してたかもしれない
- 特にGoのテーブル駆動テストの書きかただとwantErrorみたいなフィールド定義してしまいがち。
- 正常系と異常系でテストケースは分けた方がわかりやすいかもしれない
- Goでは何もテスティングフレームワークを使わなければif文でアサーションする。アサーションの読みやすさという観点で見るとtestifyのようなテストパッケージを採用する理由になるかもしれない。
良い単体テストを構成する4本の柱
- 質の良いテストケースを認識することと作成することは異なるスキル。
- 質の良いテストケースを作成できるようになるにはまず質の良いテストケースを認識できるようにならなければならない。
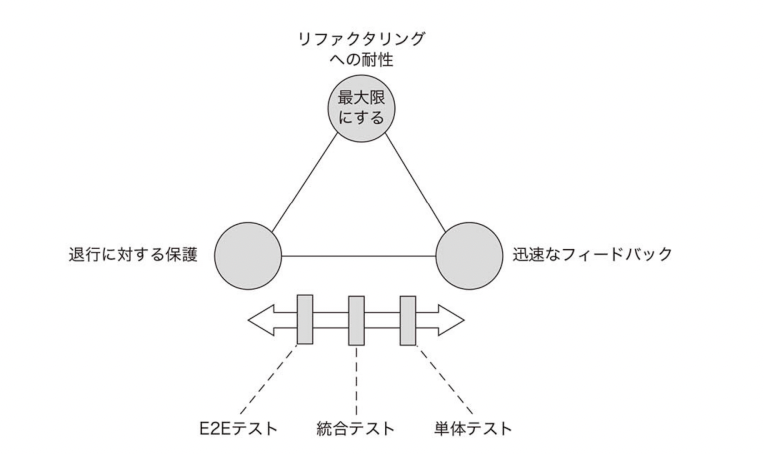
- 四本の柱
1. 退行(regression)に対する保護
2. リファクタリングへの耐性
3. 迅速なフィードバック
4. 保守のしやすさ
1. 退行(regression)に対する保護
- 含まれるプロダクションコードの量が多くなれば退行が起こる可能性は高くなる
2. リファクタリングへの耐性
- テストが失敗することなくどれだけリファクタリングできるかの耐性
- リファクタリングをしたことでテストが失敗する。このようなテストの失敗を偽陽性という。
- リファクタリングへの耐性とはこのような偽陽性への耐性である。
- 偽陽性を多く発しているテストケースはリファクタリングのたびにプロダクションコードが正常にもかかわらずテストが失敗するので、テスト結果を軽視するようになり、テストを無視するようになり、プロダクションにバグを持ち込む負の連鎖が発生する。
- 偽陽性を生み出すということはプロダクションコードの振る舞いではなくコードの詳細をテストしてしまっている可能性がある
- リファクタリングをすることでコンパイルエラーが発生するならそれも偽陽性だが、コンパイルエラーが発生しない偽陽性に比べれば修正は容易である。コンパイルエラーが発生しないような偽陽性は修正も調査も難しい。
- 実際の振る舞いが正しくないのにテストが成功してしまうのは偽陰性という
- プロジェクトの初期では偽陽性よりも偽陰性の方が大きな弊害になると言える。なぜなら、偽陰性とは警告されないバグのことであり、偽陽性はリファクタリングの妨げになると考えられているがプロジェクトの初期の段階ではリファクタリングが実施されることはあまりないからである。
- しかし、プロジェクトが成熟してくるとリファクタリングの必要性が増すにもかかわらず偽陽性がそのリファクタリングの大きな妨げとなる。
理想的なテストの価値
- 理想的なテストは上述した4本の柱を全て満たしたテストのことである
- これは全てを満たす必要があり、一つでも0のものがあればそれは無価値なテストとなる。テストの価値は掛け算
- しかし、4本の柱の1-3は排反する性質のため全てを最大限に備えることはできず、ある柱に注力したならば他の柱はある程度犠牲にする必要がありこれはトレードオフとなる
- どの柱に注力するかでテストの性質が変わってくる
E2Eテスト
- e2eテストは最もプロダクションコードが実行されるテスト。外部APIやDBなど全てのコードが実行される。そのため、退行に関する保護を十分に備えたテスト。
- また、e2eテストは偽陽性を持ち込みにくいテストのためリファクタリングへの耐性が最も備わったテストである。
- しかし、e2eテストは実行に時間がかかるため迅速なフィードバックという柱の性質は備えていない。
取るに足りないテスト
- ほんとに単純な処理を確認するテストは極めて実行が早い。処理が短いので嘘の警告を発する偽陽性が持ち込まれることも極めて少ないのでリファクタリング耐性もある。
- しかし、単純すぎて何も検証していないのと同様なので退行が検出されることはほとんどない。
- 取るに足らないテストはプロダクションコードとおなじことを別の書き方で表現しているだけで常に成功する意味のないテストである。
壊れやすいテスト
- 同様に実行時間が短く、退行を見つけることには優れていても多くの偽陽性を持ち込んでしまうようなテストもある。このようなテストは壊れやすいテストといえる。
- これはwhatではなくhowに目を向けてテストを作成してしまったがために、プロダクションコードに深く結びついてしまったテストのことである。
- このようなテストはプロダクションコードは問題ないはずなのにテストが失敗してしまう偽陽性を多く持ち込みリファクタリング耐性はほとんど備わってないといえる
最善なテスト
- 上述したように保守性を除く3つの柱は排反する性質のため全てを最大限満たすようなテストは作成することができない。そのため、どの柱をどのくらい頑張るかのトレードオフを戦略的に決定する必要がある。
- まず、リファクタリング耐性は最大限頑張らないといけない。なぜなら、リファクタリング耐性はあるかないかの極論であり、堅牢なテストのためには偽陽性を取り除くこととされているからである。
- そして、保守のしやすさは意識してやるかやらないかなのでこれは意識してなるべく小さく保守性を保てるようにテストを作成する必要がある。
- そして、退行と迅速なフィードバックはどちらの柱をどのくらい頑張るかというバランス調整をしてテストを作成することで最善なテストに近づく。
テストピラミッド
- 有名なやつ
- どのテストでもリファクタリング耐性は最大限やる必要がある
- 退行に関してはほぼ全てのプロダクションコードを動かすE2Eテストは最大限頑張ることになる
- 逆に単体テストに近づくほど迅速なフィードバックに注力する割合が増えていくイメージ
- ただ、テストするプロダクトやケースによって例外はあるのでケースバイケースで
ブラックボックステストとホワイトボックステスト
- ブラックボックステストとはシステムの内部構造を知ることなしに実施するテスト。howではなくwhatをテストするテスト。
- 逆に、内部構造を知った上でテストするテストをホワイトボックステストという。これはシステムのコードからテストを作成するためプロダクションコードとの結びつきが強くなる。つまり偽陽性が多く生まれる。
- 基本的にはホワイトボックステストよりもブラックボックステストが優先されるべきである。
- なぜならホワイトボックステストは一見して何をテストしているのかが分かりづらく、偽陽性を多くもたらしてしまう可能性があるから。
- ただし、カバレッジなどのコードの網羅率を上げたいときなどにはホワイトボックステストは有益で、ブラックボックステストと組み合わせることでより質の良いテストスイーツができる。
メモ
- 偽陽性はロンドン学派的に全ての依存をモックにするようなテストはプロダクションコードと深く結びついているため起こりやすいのではないか。
- そうなると、古典学派のテストよりも壊れやすくリファクタリングがしづらいと言える。
- つまり、ロンドン学派のテストは作成しやすいが維持しづらいと言える。
- 古典学派だろうとロンドン学派だろうとコードの詳細ではなく振る舞いをテストすることを意識してテストを書かないと偽陽性が生まれ、壊れやすい質の悪いテストが作成され、リファクタリングのハードルが上がることになる。
- 本章を読んだ感想としてリファクタリング耐性つまり偽陽性をもたらさないことはテストを書く上で重要視されていると感じた。
- リファクタリング耐性が著しく低くなるとテストを重要視しなくなり、リファクタリングの習慣がなくなり、持続的な成長からかけ離れた開発環境になってしまうからだとも思う。
- 基本的にはテストを書くハードルを可能な限り下げたいのでロンドン学派的にモックフル活用にしたい。
- ただ、そうなるとプロダクションコードとの結びつきが強くなりリファクタリング耐性の低下につながるのだろうか。
- これはテストコードの作成の仕方でどうにかならないのだろうか。
モックの利用とテストの壊れやすさ
- テストダブルにはモックとスタブの2種類がある
- より細かく分けると5種類に分類される
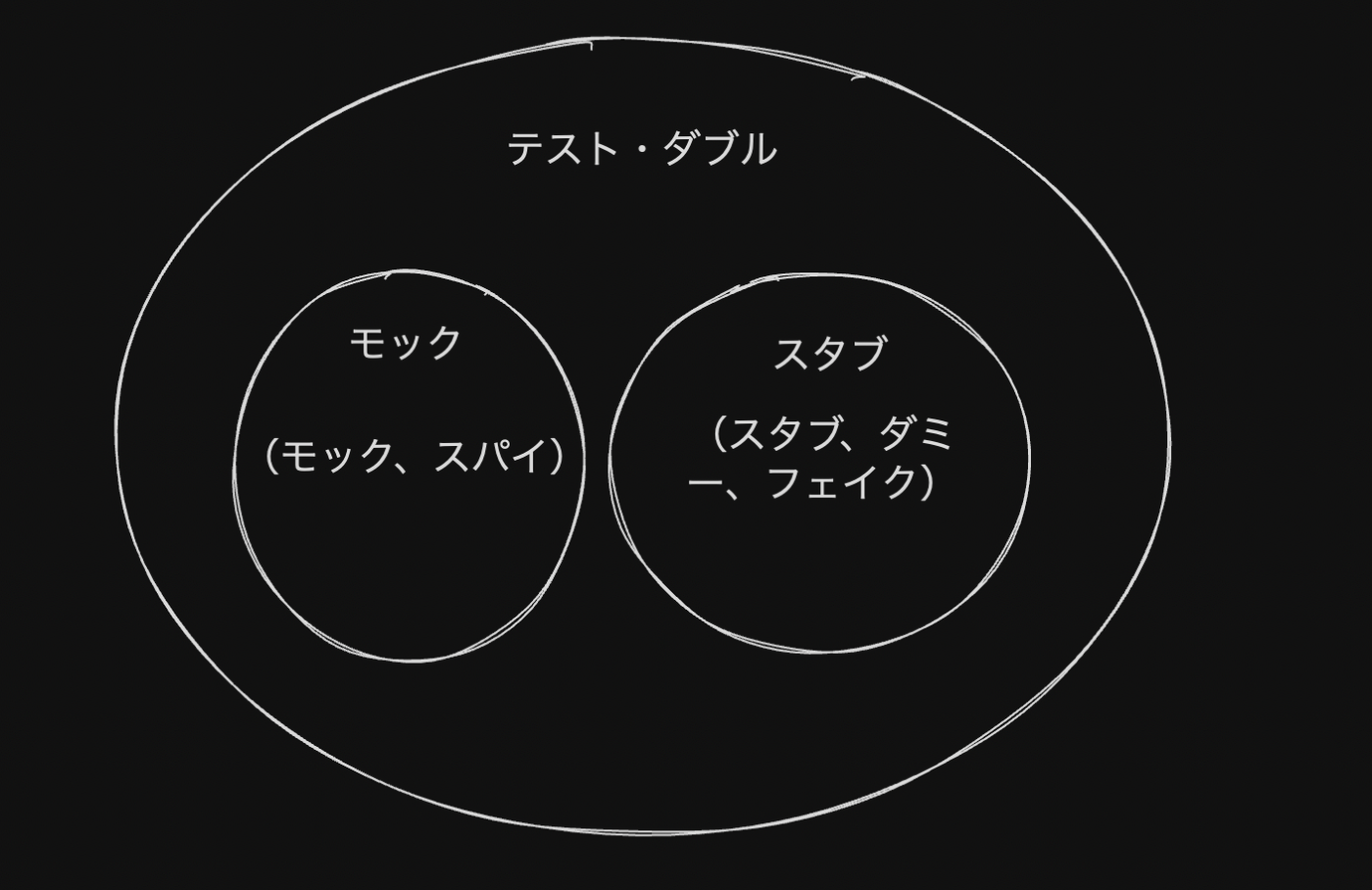
- モックはテスト対象システムからその依存に向かって行われる外部に向かうコミュニケーションを模倣する。
- スタブは依存からテスト対象システムに向かって行われる内部に向かうコミュニケーションを模倣する。
- データベースからデータを取得するような時はスタブである。副作用のない動作を模倣したいときは一般的にスタブが使われる。
- メールを送信するようなシステムは外部の副作用のある動作であり、このようなシステムを模倣したいときはモックが使われる。
- モックとスパイの違いはそれほどないが、スパイは開発者自身の手で実装されるという違いがある。
- スタブとダミーとフェイクの違いはどのくらい知的に振る舞えるかの違い。
- ダミーはnull値や一時しのぎの文字列などシンプルなハードコードされた値。
- スタブは設定した振る舞いができ、より洗練されている。
- フェイクを使う目的はスタブとほぼ同じだが、フェイクはまだ存在しない値を模倣するのに使う。
- 一般的にモックを利用する際にはモックライブラリを使用することが多い。
- このとき、そのモックライブラリで用意する道具としてのモックとテストダブルとしてのモックを混同しないようにするのが大事
- なぜなら、道具としてのモックはモックだけでなくスタブとしても振る舞えるからである。
- モックは外部に向かうコミュニケーションを模倣したら検証したりするのに使われる。
- 一方、スタブでは模倣のみに使われ決して検証には使われません。
- スタブの振る舞いを検証するのはアンチパターン。
- なぜなら、良い単体テストは偽陽性を持ち込まず、結果の振る舞いを検証するようなテストであるためその過程の振る舞いはテストで検証すべきではないから。
- このような、過剰な検証は過剰検証とも呼ばれるため、スタブの振る舞いは決して検証してはならない。
- モックとスタブの役割を兼ね備えることがある。
- このとき、スタブの振る舞いを設定し、モックの振る舞いを検証する。
- この場合、スタブとは呼ばずにモックと呼ぶことが多い。
- なぜなら、スタブよりもモックにおける振る舞いのほうが重要だから。
- publicやprivateなどのアクセス修飾子を適切に使うことで実装の詳細を隠蔽し、観測可能な振る舞いのみを公開することがちゃんと設計されたAPIである。
- ちゃんと設計されたAPIのテストは必然的に質の良いテストになる
- システム内コミュニケーションと外部APIなどのシステム外コミュニケーションがあるときシステム外APIはプロダクションコードに関わらず同じ結果をもたらすのでモックにしてよいし、モックにしたからといってテストが壊れやすくはならない。
- モックとスタブの関係はコマンドクエリ分離の原則(CQS)に似ている
- モックにして検証するべきなのは観察可能な振る舞いのみ。実装の詳細はモックにすべきでない。
- 公開されたAPIの観察可能な振る舞いに実装の詳細が漏洩されてしまうと、カプセル化された不変条件が無視されてカプセル化が崩壊してしまうことになる。
- アプリケーションが行うコミュニケーションはシステム内コミュニケーションとシステム間コミュニケーションの2種類に分かれる
- システム内コミュニケーションは実装の詳細であるためモックにすべきでない
- システム間コミュニケーションもテスト対象の実装を通してしかアクセスできないようなものは副作用が発生し得ないため実装の詳細とみなす。つまりモック化すべきでない
メモ
- モックとスタブを区別しないで使用していたがこの違いは大事
- なぜならスタブであればその振る舞いを検証することがアンチパターンで壊れやすいテストにつながるから
- 実装の詳細の適切な隠蔽とAPI設計の話。ちゃんと不変であるべき状態をカプセル化し、実装の詳細を隠蔽するようにAPI設計をすることで、堅牢なよい APIとなる
- システム内の実装にヘキサゴナルアーキテクチャのようなレイヤードアーキテクチャを採用することで公開すべき内容と隠蔽すべき内容を適切に設計できる。
- このような、ちゃんとした設計をしていれば観測可能な振る舞いと実装の詳細が適切に分離できてるよね?みたいなことでこういった設計の話が出たのかな
- そして、モックとすべきを観測可能な外部とのコミュニケーションだけとしている。実際にテスト対象からしかアクセスされない外部コミュニケーションは実装の詳細としてモックすべきでないとしている
- これの理解が完璧でない
- 実装の詳細をモックにすべきでないという主張は理解できる。
- テスト対象からしかアクセスされないシステム外コミュニケーションがよくわからない。
- システム外コミュニケーションってDBとのやりとりだよね?DBとのやりとりを抽象化したRepositoryとかはテスト対象からしかアクセスされない詳細な実装になるってこと??
- そうなると、古典学派的にはRepositoryもテストダブルを使うべきでないということか?
- ほんとにDBとのコネクション部分のみテストダブルにするような仕組みにするんか?(例えばテスト用のインメモリDBとかTestcontainersみたいな仮想環境)
- とりあえず、ここまででモックを使用することでリファクタリング耐性が保たれない質の悪いテストにつながるのでロンドン学派よりも古典学派の方が良いよという流れ
- できればモックフル活用でテスト作成のハードルを極端に下げたいのでロンドン学派でも質の良いテストを書く道はあるよという主張を期待
単体テストの3つの手法
- 出力ベースのテスト 純粋関数のように副作用のない任意の入力に対して必ず決まった出力が得られるようなときのテスト手法。戻り値を検証する。
- 状態ベースのテスト テスト対象の処理実行後のオブジェクトやDBなどの状態を検証する。
- コミュニケーションベースのテスト モックを使用してコミュニケーションを検証する。
- テストの質としては出力ベースのテストが最も質が高い
- 出力ベースのテストを書くためにはテスト対象の関数を副作用のない純粋関数にすることである
- ここら辺は関数型プログラミングの世界だが、関数型プログラミングの中の副作用の分離だけ理解できればいい
- これはクリーンアーキテクチャのようなレイヤードアーキテクチャのドメイン層の分離と似ている
- 関数型アーキテクチャは全てのコードを関数的核と可変核に分類される
- 関数型アーキテクチャでは可変核の部分は純粋関数となるよう副作用のないよう関数を作成し、副作用は関数的核で実行する
- 関数型アーキテクチャはテストの書きやすさ、保守のしやすさなどのメリットの代わりにパフォーマンスの犠牲などとのトレードオフ
メモ
- 単体テストの最高の形は入力値に対して必ず決まった出力が期待できる純粋関数であり、この純粋関数をなるべく多く作成することで質の良い単体テストとなる
- 純粋関数を作るには関数型の話ではあるが、関数型プログラミングを使う必要はなく、副作用の分離をすることを意識し、ドメインロジックで副作用を起こさないようにすることが大事
- ただ、全ての関数を副作用のない純粋関数にするのは難しいためなるべく多くの関数を純粋関数にするような意識が大事。なるべく多く純粋関数にしようという意識が大事
- 別に関数型を学ぶ必要はないのかもしれないけどこの純粋関数を作成する意識づけだったり、テクニック的なものだったりで学ぶこともありそうだから別途関数型は再度勉強したい
単体テストの価値を高めるリファクタリング
-
4種類のプロダクションコード
- ドメインモデル
- 過度に複雑なコード ドメインロジックを含み複雑になりすぎたfat controllerがまさにこれ
- 取るにたらないコード ドメインロジックも含んでおらずテストするメリットがほぼないコード。このようなコードはcollaboratorもほぼない。
- コントローラー ドメインロジックを持たないがドメインモデルなどを適切に連携して呼び出す
-
ドメインモデルが最も重要なプロダクションコードでテストすべきコード
-
過度に複雑なコードはドメインロジックを多く含むのに、collaboratorが多く複雑すぎてテストするのが困難で最も危険なコード。これをドメインモデルとコントローラーに分割する必要がある
-
質の悪いテストコードなら書かないほうがいい
質素なオブジェクト
過度に複雑なコードをドメインモデルとコントローラーに分離するための設計パターン。過度に複雑なコードは簡単にテストできない依存とドメインロジックが共存してしまっているため、重要なドメインロジックがテストできないようなコードのこと。このようなコードから重要なドメインロジックを抽出してそれを包み込む質素なクラスを作成し、テストが難しい依存を結びつける。このとき、作成した質素なクラスにはロジックを含んではならない。
これはヘキサゴナルアーキテクチャのドメインの分離や関数型アーキテクチャの副作用の分離とやっていることは同じようなものです。
ヘキサゴナルアーキテクチャはドメインからプロセス外依存を切り離しドメインロジックはドメイン層でプロセス外依存とのコミュニケーションはアプリケーション・サービス層で扱わせる。
関数型アーキテクチャはヘキサゴナルアーキテクチャをより厳しくしたものでプロセス外依存だけでなく全てのcollaboratorを切り離したものである。
いずれもドメインロジックをテストしやすいようにするためにドメインロジックとそれ以外を分離するような設計パターンといえる。
エリックエヴァンスのドメイン駆動設計の文脈では集約という用語がある。
そして、これらの分離する設計はテストがしやすいだけでなくプロダクションコードの複雑さを解決し、保守のしやすいコードに保つことだできます。
- プロセス外依存(読み込み) -> ドメインモデル -> プロセス外依存(書き込み)が1番理想だが実際はそんなにうまくいかない
- ドメインモデルのビジネスロジックの結果を用いてさらに読み込みを行う場合など
- このような時の解決策は以下の3つの選択肢がある
- 外部の依存に対する全ての読み込みと書き込みをビジネスオペレーションの始まりと終わりに持っていく 処理フローを簡潔なまま保てるが不要な場合までプロセス外依存を呼び出すことになるのでパフォーマンスを犠牲にする。そのかわりコントローラーの簡潔さとドメインモデルへのプロセス外依存の注入は避けられる
- ドメインモデルにプロセス外依存を注入する コントローラーの簡潔さとパフォーマンスは保たれる。その代わりにドメインモデルのテスト容易性は犠牲になる
- 決定を下す過程をさらに細かく分割する パフォーマンスとドメインモデルのテスト容易性は保たれるがコントローラーの簡潔さが犠牲になる
- パフォーマンスは犠牲にできない。加えて、ドメインモデルに複雑性を持ち込むのも許容できない。
- そのため、残るは三つ目の選択肢のみ
- コントローラーの簡潔さは損なわれるが、頑張れば複雑性を抑えることはできる
確認後実行パターン
コントローラーが複雑になっていくことへの対策として確認後実行パターンが使える。コントローラーで処理を実行するかどうかの制御をしてしまうとドメインロジックの漏洩になりカプセル化が壊れてしまう。逆にドメイン層で処理を実行できるかの制御をすると不要なデータまで取得することもあり、パフォーマンスが犠牲になる。
これを解決するためにドメインモデルに制御ロジックを別途追加してコントローラーではそれを呼び出すだけにする。そうすることでコントローラーの簡潔さが保たれ、読み取り->ビジネスロジック->書き込みのフローを保てる
ドメインイベントの利用
ドメインロジック側で行われたドメインモデルの状態変化を外部システムに伝えることが必要なこともある。ただし、この責務をコントローラーに持たせるのはコントローラーを複雑にする。このようなときにコントローラーに適切に状態の変化を伝えるにに使えるのがドメイン・イベント。
- 確認後実行パターンやドメインイベントなどを使用することで読み込み->ビジネスロジック->書き込みといった簡潔なフローとビジネスロジックと副作用の分離を適切に施した上に、コントローラーを簡潔に保つことができる
メモ
- 単体テストを書くのにモックを使いたいんだという考えは誤りだったのかもしれない
- というのも、今まで書いてきたプロダクションコードではコントローラーという部分がほとんど仕事をしていなかった
- インターフェイスで抽象化しドメイン層に落とし込んだDBの操作も結局ドメイン層の中心となるクラスに依存性を注入してしまっていたため複雑性は解決できていなかった。そのようなクラスをテストするにはモックを使いたいのは当たり前(プロセス外依存の注入のため)
- 真にドメイン層からプロセス外依存を副作用を分離するにはプロセス外依存とドメインロジックを結びつける質素なオブジェクト、つまりコントローラーでそれをやらなければならない
- そうすれば、ドメイン層の処理がテストしやすい純粋関数に近づく
- コントローラーではドメインが漏れ出ているように見えるかもしれないがドメインロジックは含まれておらず、プロセス外依存やドメインモデルを適切に呼んでるだけである。
- DBからとってきたデータオブジェクトはドメインモデルへと変換し処理をする必要がある(ドメイン層からDBの詳細を知ることになってしまうから)
- これは使用しているORマッパーで済むこともあるかもしれないし、Spring JPAで扱うEntityクラスなんかは詳細すぎるのでやはりドメインモデルに変換する必要がありそう
- この変換処理はロジックとなるためコントローラーから取り除く必要がある、ドメイン層でのファクトリ関数みたいなのでやると良さそう
- このような、ファクトリメソッドはロジックを含まないためユーティリティークラスと同様の扱い、つまりテストは不要である
- 嘘かも。ファクトリメソッドはバリデーションロジックとかあるケースもあるのでそのような部分はテストすべきかも
- 純粋なドメインモデルのコンストラクタなんかは取るに足りないコードなのでテストは不要だと思う
- 事前条件に関してはロジックとなるものはテストすべきだが、ロジックではない事前条件はテスト不要でしょう
なぜ結合テストを行うのか?
メモ
- 結合テストは単体テストで確認できなかった全ての異常系とコントローラーの接続を確認する
- もっと言うと結合テストは1件のハーピーパスがテストできればいい
- プロセス外依存は管理下の依存であればモック化すべきでない。管理外のプロセス外依存はモックを使うべき。
- 明らかな不具合となるような場合は早期失敗で、プログラムを落として良い。そうすることで、無駄にテストを作る必要がなくなる。
- 管理下にある依存とはテスト対象のアプリケーションを通してでしかアクセスされない依存のことで、DBなどが該当する。つまり、DBなどは管理下にある依存のためモック化すべきでない。インメモリDBやTestcontainersのような本番DBとは別にテスト用の仮想環境を用意するのはいいと思う。
- 結合テストの実際の流れは準備フェーズでデータの作成やモックの準備、実行フェーズは実行、確認フェーズは実行後のデータのアサーションやモックの検証。データの確認にはプロダクションコードを使うべきです。そうすることで実際の挙動をテストすることができる。
- 実装クラスを1つしか持たないクラスのインターフェースを作るべきでない。
- YAGNI
- 元来、インターフェースは作るものではなく発見されるもの。
- 作ろうと思って作るべきでない。
- では、なぜみんなインターフェースを作るのか?
- インターフェースを作り依存性を注入することでモックをつかったテストが書けるからである。
- しかし、本書を通して本当にモックを使うべきプロセス外依存以外はモックを使うべきでないとされているため質の良いテストを書くという視点で考えると無駄にインターフェースを作成すべきでない
- これは、クリーンアーキテクチャが抽象に依存するようなアーキテクチャであり、広く採用されているからかモックを使用したテストを多くみかける。実際私もモックでテストを書きたかったし、モックでテストを書くためになるべく抽象に依存するように脳死でインターフェースを作成してきた。
- しかし、古典学派的にテストを考えるとモックを必要とせず、そのためインターフェースも必要とならず、クリーンアーキテクチャも不要となる。いわゆる三層アーキテクチャで十分とされている。
- モックを使いたかったのはドメイン層の最も重要な部分のテストが複雑すぎてできなかったからである。
- この設計の悪さに目を瞑らずコントローラーとドメインとに処理をちゃんと分離できればモックもクリーンアーキテクチャも必要とならず必要最低限のテストを書くことができる。
- ログも依存であり副作用だが、開発者しかみないようなログは実際のプロダクトには関係なくテストすべきでないが、そうでない場合はログもテストすべき。
モックのベストプラクティス
- モックに置き換えるのは管理下にないプロセス外依存のみ
- そして、最も依存との境界に近いインターフェースをモックとする
- そうすることで、テストで実際に動くプロダクションコードが多くなり、リファクタリング耐性が上がる
- 作成するテストダブルの対象がアプリケーションの境界に位置するクラスであれば、モックよりもスパイの方が優れている
- モックの対象になる型は自身のプロジェクトが所有する型のみにする - サードパーティー性のライブラリを使用するときそのアダプタとなるインターフェースを作成することでサードパーティー性のライブラリに依存しすぎないコードとなる
- テストではプロダクションコードを使用してはならない
- テスト時にはプロダクションコードは信用してはならず、プロダクションコードの定数やリテラルを使用することは何もテストしてないことになる。
メモ
- 使用するモックライブラリによってモックやスパイといった用語が指すものが微妙に違う気がしないでもない
- でも本書でスパイをモックと呼んでもいいとあった。スパイという用語を知らない開発者の方が多そうだし、モックとスパイの違いは実装方法の違いだけなので。
データベースに対するテスト
データベースをテストするのに必要な事前準備
-
スキーマをバージョン管理する
-
開発者ごとに個別のデータベースインスタンスを用意する
-
データベースに対する変更を本番環境に反映する際は移行ベースを用いる
-
参照データはアプリケーションに必要不可欠なものなのでスキーマと同じようにInsert文などでバージョン管理すべき。参照データとはアプリケーション起動前に用意しておく必要のあるデータのこと。マスタデータみたいなものと理解
-
各開発者が共通のDBを使用してテストするとお互いのテストに影響が出てしまうため望ましいのは各開発者のローカルマシンにDBを立ててテストを実施すること
-
開発環境で発生したDBの変更を本番環境に反映する方法は状態ベースと移行ベースの2パターンある
-
状態ベースはデータベースの状態を見るので、本番環境と開発環境の状態を比較ツールで状態比較し、差分を反映する。これは移行手順が明確でないがデータベースの状態が明確になる。
-
移行ベースはどのように移行するかを見ているので、Flywayのようなマイグレーションツールが使われる。これはデータベースの状態は明確でないが、どのように移行するかが明確である。
-
状態ベースよりも移行ベースの方がどのように変更を反映するかの方法を知ることができるため有利である。ただし、まだリリース前のような本番環境への操作ハードルが低い段階であれば状態ベースを使用することも考えられる。
-
プロダクトコードだけでなくテストコードにおいてもトランザクションは重要
-
結合テストでは1つの共有するテスト用のDBが存在するためテストケースを並列で実行しないこととテスト後にデータの後始末をすることが重要
-
DBにはDockerのような仮想環境を使用することで並列実行を可能にすることもできるが、これはあまりにも保守コストが高すぎる。
-
結合テストでのデータの後始末方法として考えられるのは以下の4つ
- テストケース実行前にバックアップからDBを復元 時間かかる
- テスト実行後に後始末 後始末が実行されなかった時に問題
- ロールバック 本番環境でやってることと一致しなくなる
- テスト実行前に後始末 これが1番いい
-
後始末するときは参照データは消しちゃダメ
-
インメモリDBの使用は本番環境とのDBとの機能面での違いが生まれるため推奨しない
-
結合テストはすぐに肥大化する傾向にある
-
そのため、結合テストのコードはいかに短くするかが重要となる
-
これはテストケース間で共通した処理、たとえば準備フェーズの処理をファクトリメソッドとして切り出すなどが考えられる
-
このようなファクトリメソッドの使用はオブジェクト・マザーと呼ばれるパターン。別のパターンにテスト・データ・ビルダーというビルダーパターンでデータを作るパターンもある。ただ、ボイラープレートが増えるというデメリットも
-
実行フェーズは実行したい関数を引数にとる(委譲するような関数)をつくることで実行フェーズも短くすることができる
-
確認フェーズも短くできるよ。C#は拡張関数が定義できるので流れるように取得から検証までできる。拡張関数いいな
-
書き込みは非常に重要である一方、読みこみは例え上手くいかなかったとしてもそこまでの影響はない。つまり優先度は低く複雑な読み込み処理であればテストする価値はあるが単純な読み込みであればテストする価値はない。
-
リポジトリはプロセス外依存を扱うコードのため保守コストが高くつくのに、退行に対しての保護をそれほど受けることができないので、もしテストしたいとしてもそれはControllerの結合テスト内でテストしたほうが良い。
メモ
- 本番DBへの変更の反映には移行ベースの方がいいらしいので、Flywayのようなマイグレーションは使っていったほうがいい
- Goでマイグレーションツール使ったことないからよく使われているのを別途調べたい
- コントローラーとDBの間にトランザクションをはさむ
- 本書ではRepositoryクラスがトランザクションに依存しており、トランザクションの取得、ロールバックとSQLのコミットの処理が分離されている
- ここら辺使用するORMやフレームワークにもよるけどとりあえずコントローラーから直接DB操作をするのは避けるのがベターっぽい
- それはトランザクション境界がわかりやすくなるだけでなくORMや使用するDBの変更に強くするため的な話。だけども、それはRepositoryをインターフェースにしてその抽象に依存することでDBの詳細を切り離す的な話でもあり、それは古典学派的テストによるアーキテクチャではクリーンアーキテクチャは不要という話と矛盾する
- Repositoryを具象クラスにするのかインターフェースにするのかはよく考えたほうがよさそう
- あと、いわゆるEntityクラスをそのままドメインモデルとして扱ってるけどこれもドメインモデルの構造体を用意して変換させたほうがいいのではなかろうか??
- Goでトランザクション処理どんな感じで書けるかは別途試したい
- Dockerを使用したテストはコストが高すぎるとあってビビったがDockerによるテストに対して反対しているわけではなさそう。
- Dockerを使用したテストケースの未熟な並列実行に対して異を唱えている
- Testcontainersやdockertestというそれなりに枯れたテスト用のコンテナ管理ツールがあるのでどこまで保守コストを下げれるかがミソな気がする
- あと、テストケースのコンテナを使用した並列実行は確かに意図しない結果を招いたりするので難しい
- まあでもTestcontainersのようなライブラリを使用すればあんまりコンテナの管理を考えることなく一つのテストケースに1コンテナを割り当てられる気がするので使用してもいい気がする。
- ただ、本書はコンテナよりもローカルマシンで起動させたDBを推奨している
- 嘘、1つのテストケースに対して1コンテナ起動するのもコスト高そうかも。遅くなるし。わからん。
- 何らかのグループ分けをして単体テストと結合テストはグループ分けした方がよさげ
- テスト実行前に後始末するならBeforeEachみたいな事前処理でclean()みたいなことしてもいいかなと思った
- 本書ではC#がデフォルト引数を設定できる言語でもあるためオブジェクト・マザーパターンを使用している。Goではデフォルト引数を設定できないのでもしファクトリメソッドを作るならビルダーパターンでもいいかもしれない。でもこういうときGoだとオプショナルファンクションパターンみたいな方がいいのかもしれない。
単体テストのアンチパターン
プライベートメソッドのテスト
- プライベートメソッドのテストを作成することは観察可能な振る舞いをテストするという原則に反する。
- そのようなことをすると退行に対する保護を失うことになる。
- もし、テストしたいのであれば観察可能な振る舞いに含めることを検討する。
- テストすることを目的にプライベートメソッドを公開するうようなことはしてはならない。
- プライベートなメソッドに重要なロジックが埋もれてしまうことを抽象化の欠落という。
- 観察可能なプライベートメソッドは基本的には該当するものはないが、例外的にそのようなメソッドはありえるのでその場合はテストを書いても問題はない。
プライベートな状態の公開
- テストをすることを目的にテスト対象のアクセス修飾子をpublicに変更することはしてはいけない
テストへのドメイン知識の漏洩
- プロダクションコードのロジックをテストに持ち込むべきでない
- プロダクションコードのロジックをコピペしただけのテストをよく見る
- そのようなテストはリファクタリング耐性などはほぼ持たない質の悪いテスト
- ハードコードする勇気
プロダクションコードへの汚染
- テストでしか使用しない処理がプロダクションコードに含まれてしまっている
- テストかどうかをモードやフラグで判断して処理を変えるようなものが典型的なアンチパターン
- これはテストコードとプロダクションコードが混ざってしまい、保守コストが増えてしまう。
具象クラスに対するテストダブル
- 今までインタフェースに対してテストダブルを作成してきたが、具象クラスに対してもテストダブルは作れる
- しかし、具象クラスに対してテストダブルを作れるということは単一責任の原則が遵守されておらず、設計的に大きな問題があることを示唆する
- 例えば、重要なロジックと管理下にないプロセス外依存を使用する処理を含んだクラスがあったとするとプロセス外依存だけをモックにしたいのにそれができない
- これが単一責任の原則に反しているためでこのようなときはクラスの処理を分離し、プロセス外依存の処理はインタフェースにしてモックにすれば良い
単体テストにおける現在日時の扱い
-
time.Now()みたいに現在時刻を使う時は多々ある - しかし、現在日時はテストを実行するたびに変わりテストしづらい
- テストで現在日時を扱いやすくするための3つのパターンを示す
環境コンテキストとして現在日時を扱う方法
- 現在日時を取得するクラスを別途用意する
- プロダクトからは普通に現在日時を取得する関数を呼び、テスト時はテスト用の固定日時を返すような初期化の仕組みを作る
- しかし、これはアンチパターン
- なぜならプロダクションコードを汚すことになるから
明示的な依存として現在日時を扱う方法
- 値として現在日時を注入する
- しかし、値として依存性を注入するのはDIフレームワークと相性が悪い
- そのため、ビジネスオペレーションの最初の方で現在日時をサービスとして注入し、以降はそこから現在日時を取得するようにする