SpiceDB入門
今回のサンプルコード
業務でよくわからないまま使っているのでちゃんと入門しておきたいメモ。
執筆時点(2025年4月)でとにかく情報が少ない。zennの記事は3つしかなかった。
なんなら全部同じ方の記事だった。
あとはこのスライドくらいしか日本語の情報はない
ただ、このスライドはだいぶ実装寄りの話でだいぶ参考になると思う
とりあえず公式
読んでいきましょう
だれが開発してるのか
SpiceDBはAuthZed社によって開発されているOSS。AuthZed社に関しては以下の記事で紹介されているが2020年に設立されたパーミッション管理のスタートアップ。
SpiceDBとは
Google社内で使われているZanzibarという認可システムを元に作られた認可システム。ZanzibarはGoogle DriveやYoutubeといった大規模サービスの認可を高速に実現する仕組みであり、論文も発表されている。以下の記事なんかが概要をつかめるかもしれない。
SpiceDBは以下のような特徴を持つ。
- 権限データを保存・計算するための、最もスケーラブルで一貫性のあるGoogle Zanzibarにインスパイアされたデータベース
- GoogleのZanzibar論文に記載されているアーキテクチャに忠実な分散並列グラフエンジン
- 独自のスキーマにより宣言的にきめ細かな認可の仕組みを構築できる
- SpiceDB Caveatsによる属性ベースのアクセス(ABAC)管理
- Ops friendly
- 観測可能なツール、強力なKubernetes Operatorなどが用意されている
- インメモリ、Spanner、CockroachDB、PostgreSQL、MySQLなど、多様な関係性ストレージをサポート
AuthZed Dedicated
SpiceDBをセルフホストして運用するハードルが高い場合はAuthZed DedicatedというマネージドSaaSがある。
SpiceDB Client
ZedというCLIツールと公式のクライアントライブラリ(Go, Java, Node.js, Python, Ruby, C#)とサードパーティー製のコミュニティライブラリ(PHP, Rustなど)がある。
公式のgRPCとRESTのAPIリファレンスもある。
料金
-
freeOSSを自前でセルフホスト -
DedicatedAuthZedによるマネージド -
Enterprise自前セルフホストだが商用向けの機能盛り込んだSpiceDBのリビジョンが使える
ドキュメント
インストール
mac(Homebrew)、Docker, k8sなどでインストールできる。
macだと以下のコマンドでspiceDBとzedのインストールができる。
brew install authzed/tap/spicedb authzed/tap/zed
一応、今回はdocker imageからSpiceDBを起動してbrewでインストールしたzedを使っていろいろ触ってみようと思う。
docker pull authzed/spicedb:latest
Clientライブラリ
前述した通りSpiceDBはgRPCでアクセスできるので様々な言語をサポートしている。今回はGoのクライアントライブラリを使ってみる。
Open Policy Agent
Open Policy Agent(OPA)というSpiceSBと同じ認可処理の機能を提供するシステムがある。ドキュメント内ではOPAとSpiceDBはまったく異なるアプローチをしているため比較すること自体に意味はないとしており、OPAユーザーがSpiceDBを理解するための橋渡し的なドキュメントを用意してくれている。
OPAについては初耳だったので軽く調べてみたけど意外と日本語の記事が多かった。
k8sの文脈の記事やスライドが多かった。そもそもOPAはCNCFプロジェクトらしい。Regoというスキーマ言語を用いて様々なシステムの汎用的なポリシー制御を行うOSSらしい。以下の記事がわかりやすかったがその汎用的なポリシ制御からOPAは開発者が書くIaCの検証と認可の2つの用途に大きく分けることができ、検証の領域がだいぶ実用的に発展しているらしい。それでk8sの話題が多かったのか。
で、もう一つの認可の部分でのOPAの活用がSpiceDBと競合しているという話。
OPAはSpiceDBとは別の話だがまったく知らなかったので勉強になった。
FAQのところでSpiceDBはポリシーエンジンではないとしており、そのため、リバースインデックスを活用できることが大きな違いであるとしている。リバースインデックスとは「従業員がアクセスできるリソースはなにか?」といった問い合わせのことらしい。
また、ドキュメントにはRoRのCancancanというgemの利用ユーザーのためのガイドも用意してくれている。
チュートリアル
ドキュメントにブログサービスに対してSpiceDBを活用するハンズオン的なガイドがあったので実際にやってみる。
内容としてはAuthZedのマネージドを使ってschemaの作成、permissionの作成、permissionのチェックを行う。
AuthZedのマネージドはアカウントを作れば無料で使えたが、どこまで無料なのかがよくわからない。
事前準備
- AuthZedのアカウントを作る
- チュートリアル始まるので適当にPermission Systemを作る

- API ClientsのタブからAPIトークンを作成する
SpiceSBの起動
docker run --rm -p 50051:50051 authzed/spicedb serve --grpc-preshared-key "<API Token>"
zed CLIでAuthZedのマネージドのPermission Systemとやり取りしてそうなのでdockerでSpiceDBを起動する必要はなさそうだった。試しにDocker コンテナ停止してもZedでやり取りできた。
SpiceDB クライアントの使用
SpiceDBのCLIクライアントであるzedなのだが、エディタのzedとコマンド名が被るという問題に直面したので別名をつけてインストールする必要があったのが地味にめんどくさかった
Homebrewでエディタのzedをインストールしたみたいでauthzedの方のzedをインストールするのが大変そうだったのでバイナリを直接ダウンロードしてパスの通った場所に配置した。
# authzed -> zedの別名
authzed version
client: zed v0.30.1
service: (unknown)
以下のコマンドでリソースを作る。clientはGoなどのClientライブラリも使えるけど今回はzed CLI使うのが簡単そうだったのでzed使う。
authzed schema write <(cat << EOF
definition user {}
definition post {
relation reader: user
relation writer: user
permission read = reader + writer
permission write = writer
}
EOF
)
11:07PM FTL failed to write schema error="rpc error: code = InvalidArgument desc = error parsing schema: parse error in `schema`, line 1, column 1: found reference `user` without prefix"
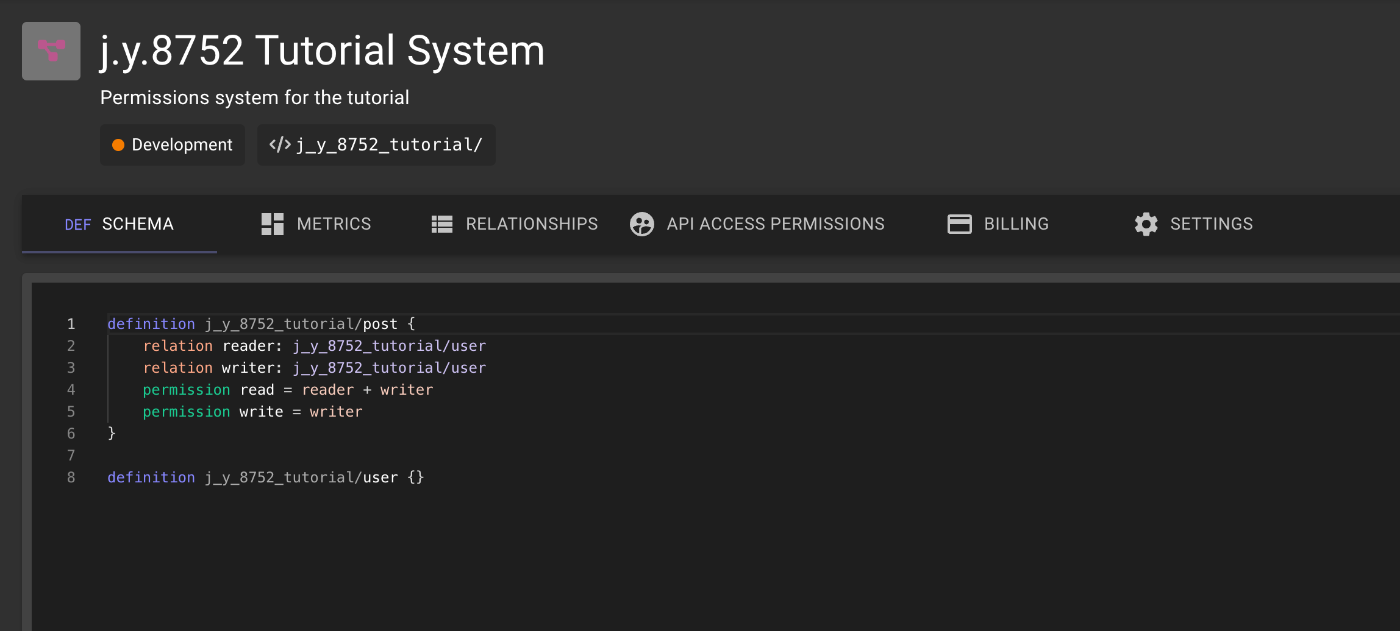
なんかprefixをつけろと怒られてそうだったので以下のようにしてみた。prefixはAuthZedのダッシュボードのPermission Systemにschema prefixがあるからそれを使う。
authzed schema write <(cat << EOF
definition j_y_8752_tutorial/user {}
definition j_y_8752_tutorial/post {
relation reader: j_y_8752_tutorial/user
relation writer: j_y_8752_tutorial/user
permission read = reader + writer
permission write = writer
}
EOF
)
成功するとダッシュボードから確認できる。
次にpermissionを作成する。
authzed relationship create j_y_8752_tutorial/post:1 writer j_y_8752_tutorial/user:emilia
GiAKHjE3NDU5Nzk3OTg5NDMzOTM4NjAuMDAwMDAwMDAwMA==
コマンドの詳細は後でやるとしてとりあえずこれで記事に対してのユーザーの権限を作成できる。この例ではemiliaというユーザーにpost_idが1の記事にwrite権限を付与している。
コマンドが成功するとトークンが出力されるがこれはたぶんZed Tokenと呼ばれるものでその時点でのpermissionを参照するために使うとかそんなやつだったと思う。これも後でちゃんと調べる。
authzed relationship create j_y_8752_tutorial/post:1 reader j_y_8752_tutorial/user:beatrice
GiAKHjE3NDU5Nzk4NTE0ODMwMjU4MjkuMDAwMDAwMDAwMA==
同じように今度はread権限のユーザー権限も作成する。
あとは以下のようにpermission checkができる。
# emiliaはwrite権限があるので読み取りできる
authzed permission check j_y_8752_tutorial/post:1 read j_y_8752_tutorial/user:emilia --revision "GiAKHjE3NDU5Nzk3OTg5NDMzOTM4NjAuMDAwMDAwMDAwMA=="
true
# emiliaはwrite権限があるので書き込みできる
authzed permission check j_y_8752_tutorial/post:1 write j_y_8752_tutorial/user:emilia --revision "GiAKHjE3NDU5Nzk3OTg5NDMzOTM4NjAuMDAwMDAwMDAwMA=="
true
# beatriceはread権限なので書き込みはできない
authzed permission check j_y_8752_tutorial/post:1 write j_y_8752_tutorial/user:beatrice --revision "GiAKHjE3NDU5Nzk4NTE0ODMwMjU4MjkuMDAwMDAwMDAwMA=="
false
# beatriceはread権限なので読み取りはできる
authzed permission check j_y_8752_tutorial/post:1 read j_y_8752_tutorial/user:beatrice --revision "GiAKHjE3NDU5Nzk4NTE0ODMwMjU4MjkuMDAwMDAwMDAwMA=="
true
チュートリアルの内容は以上。
このチュートリアルではAuthZedのマネージドを使っているので自前でセルフホストする例と無料で使える範囲を知りたいかも。
無料で使える範囲
Permission SystemがDevelopmentとProductionが選べてProductionはクレジット登録しないと使えない。Development環境が無料で使えそう。勉強のためにちょっと触るくらいならDevelopment環境で良さそう。
AuthZed Cloud
次世代のサーバーレスSpiceDBみたいなことを謳ってた。ちょうど執筆している段階でwaiting list登録で使えたりするみたい。今回は掘り下げないが将来的に自前のセルフホスト以外の選択肢になるのかな
Observability
以下を参照。Prometheusとかotelとか対応してるそうです。今回は特に掘り下げない。
Zanzibar
SpiceDBの元となっているZanzibarについてもう少し掘り下げておく。
ReBACについて
Relationship-based Access Control(ReBAC)は認可システムを設計するためのパラダイムの一つである。ReBACのコアのコンセプトはサブジェクトとリソース間の関係性の連鎖の存在がアクセスを定義するものであるという考え方。
この抽象化だけで、非常に人気のあるRBACやABAC設計を含む、他のすべての既存の認可パラダイムをモデル化することができる。このコンセプトは、キャリー・ゲイツが2006年に発表した論文「Access Control Requirements for Web 2.0 Security and Privacy(ウェブ2.0セキュリティとプライバシーのためのアクセス制御要件)」で説明されたもので、フェイスブックはこのパラダイムの初期の採用者として挙げられている。
ブロークン・アクセス・コントロールがOWASPトップ10の上位を占めるようになった現在、ReBACは正しい認可システムを構築するための推奨手法となっている。
ReBACの詳細については、Relationshipsのドキュメントを参照のこと。
上記、DeepLによる訳。
このサブジェクトとリソースの関係性についてはあとでまたやろうと思うがSpiceDBにおいては以下のようなものが基本的なpermissionの宣言である。
document:readme#editor@user:emilia
これはreadmeというIDを持つdocumentというリソースに対してeditorというpermissionもしくはrelationをemiliaというIDのuserというサブジェクトが持っているかどうかという基本的な問い合わせを表現している。
このようなサブジェクトとリソースの関係を連鎖的に探索して認可制御をするというのがこのReBACのコンセプトと理解。ZanzibarがこのReBACを元に設計されており、SpiceDBにおいてもこの仕組みが採用されている。
新たな敵問題(New Enemy Problem)
これはpermissionを更新とリソース保護が一貫して更新されないために不正にリソースにアクセスできてしまう問題のことであり、ZanzibarではZookiesという仕組みで解決しており、SpiceDBではZedTokensでこの問題を解決している。
以下ドキュメント記載の例。(DeepLにより翻訳。)
例 A:ACL 更新順序の無視
AliceはBobをあるフォルダのACLから削除する;
Aliceは次に、Charlieに新しいドキュメントをフォルダに移動するよう依頼する;
Bobは新しいドキュメントを見ることができないはずだが、もしACLチェックが2つのACL変更の間の順序を無視するなら、見ることができるかもしれない。
SpiceDBとの違い
Schema Language
Zanzibarではprotobufを使ったNamespace Configを使用しており、Google社内ではこのNamespace Configを生成するprotobufツールを多数用意している。
SpiceDBでは独自のSchema Languageを使用しており、これはprotobufのNamaspace Configにコンパイルすることができる。
個人的な感想だが、Google社内ではprotobufをいたるところで使い倒しているとgRPCやprotobufの文脈で度々聞くが、こういう話を聞くとやっぱりprotobufを使い倒しているんだなと感じる。
BufがgRPCはGoogleが社内で使うために一般的には不要な実装が多く、扱いづらいということを問題としてBuf CLIやConnectを作ったのも納得できる。
RelationとPermissionの区別
SpiceDBを使ったpermissionの作成を見ているとrelationとpermissionの区別がよくわからなくなる人がいると思う。
definition user {}
definition post {
relation reader: user
relation writer: user
permission read = reader + writer
permission write = writer
}
ドキュメントにもこの2つは本質的には同じだみたいな記述があったりもする。Zanzibarではこの2つを明確に区別はしていなかったがSpiceDBではこの2つを区別しており、アプリケーション側はpermissionに対して問い合わせをすることを推奨している。
relationはオブジェクト間の純粋で抽象的な関係のみを表現し、アプリケーション側からrelationに対して問い合わせをすることは可能だがpermissionに対してのみ問い合わせをすることを推奨している。
SpiceDBはpermissionとrelationを区別することでZanzibarで使われていた**_this**という紛らわしいキーワードを取り除けたとしている。
Reverse Index
ZanzibarもSpiceDBもReverse Index Expand APIを実装しており、アプリケーション側でaliceがread権限を持つdocumentは何か?みたいな問い合わせが容易にできるようになっている。
しかし、これはAPI応答がツリー構造のためアプリケーション側では使いづらいものとなっている。
SpiceDBでは構造化しない応答を実現するために追加のAPIを実装しているため平坦化した結果を使うことを可能としている。
Datasores
ZanzibarはSpannerのみをサポートしているが、SpiceDBは様々な主要なDatastoreをサポートしている。
Consistency(一貫性)
前述した新たな敵問題のためにZanzibarはZookieという仕組みを実装している。SpiceDBでもZedTokensという同様の仕組みを実装しているが、APIリクエストにZedTokensを指定することを可能としており、このワークフローを簡素化している。
IDの柔軟性
SpiceDBはオブジェクトに指定できるIDがZanzibarよりも柔軟。
ユーザーの扱い
以下、ドキュメントのDeepL訳。
グーグルでは、すべてのユーザーとサービスがGAIA(Google Accounts and ID Administration)と呼ばれるサービスに登録されている。GAIAは、64ビット整数の形ですべてのエンティティに一意な識別子を提供します。Zanzibarは、GAIA IDを使ってどのユーザーも表現できることを前提に設計されています。
Google以外ではユーザーはそれほど厳密に定義されていないため、SpiceDBはユーザーを他のオブジェクトと同様に扱います。これにより、SpiceDBはより複雑なユーザーシステムをサポートし、より強力なクエリを実行することができます。
definition ApiKey {}
definition User {
relation keys: ApiKey
}
definition Post {
relation viewer: User
...
permission view = viewer + viewer->keys
}
この例はSpiceDBにおけるユーザー定義の柔軟さを表す簡単な例で、Postに関連付けられたUserとUserに関連付けられたAPI Keyのどちらかでアクセス制御を可能とする例。
用語の違い

まとめ
ZanzibarはReBACと密接に関係しているがまったく同じものではない。ZanzibarはReBACを元に構築された認可システムの仕組みであることは間違いないがGoogleの大規模なサービス群間の認可を制御するために必要な様々な実装が組み込まれたものがZanzibarである。
SpiceDBはZanzibarからより一般的なケースで使いやすいように開発された認可システムといえる。これはgRPCからConnectを開発したBufのストーリーと近いものを感じる。
SpiceDB Operator
ドキュメントのいたるところで言及されているがSpiceDBはクラウドネイティブの原則だけでなく、kubernetesの原則にもしたがって設計されているため、kubernetes環境で利用することを推奨している。
そもそもSpiceDBはCNCFのプロダクトに認定されている。
k8s環境でSpiceDBを使うにはKubernetes Operatorとして用意されているSpiceDB Operatorを使うことを推奨している。
k8s環境でSpiceDBを使うことを推奨しているのはSpiceDBが分散システムであり複数のSpiceDBノードからなるSpiceDB Clusterを構築して使うことで高パフォーマンスでスケーラビリティのある認可システムを実現することができるからだと理解。
というよりもSpiceDBは問い合わせに対してキャッシュを探し出し、応答するような仕組みがあり、k8s環境ではクラスター内部でキャッシュの問い合わせをリソース間の通信経路を知ることができるため可能となっており、非k8s環境ではどうしてもキャッシュの問い合わせ先を知ることができずパフォーマンス的に劣ることになる。
また、SpiceDB Operatorを用いる利点としてはSpiceDBのアップデートを容易にするなどの利点もあり、SpiceDBのデプロイ先はk8s環境が推奨となっている。
SpiceDBはdocker imageとして配布されているためk8s環境でなくとも構築することは可能だと思うが、SpiceDB Clusterを構築するにはSpiceDB Operatorを用いてk8s環境で利用するのがおそらく一番簡単。
公式のブログでAWSのECS環境にSpiceDBをデプロイする方法が書かれているが最後のまとめでECSを使うことによるデメリットも記載されており、記事の作成自体はDiscodeでのECSでの構築例はあるか?という質問が発端らしい。
ディスパッチ
SpiceDBのディスパッチの機構については以下のアーキテクチャ図を見るのが早い。
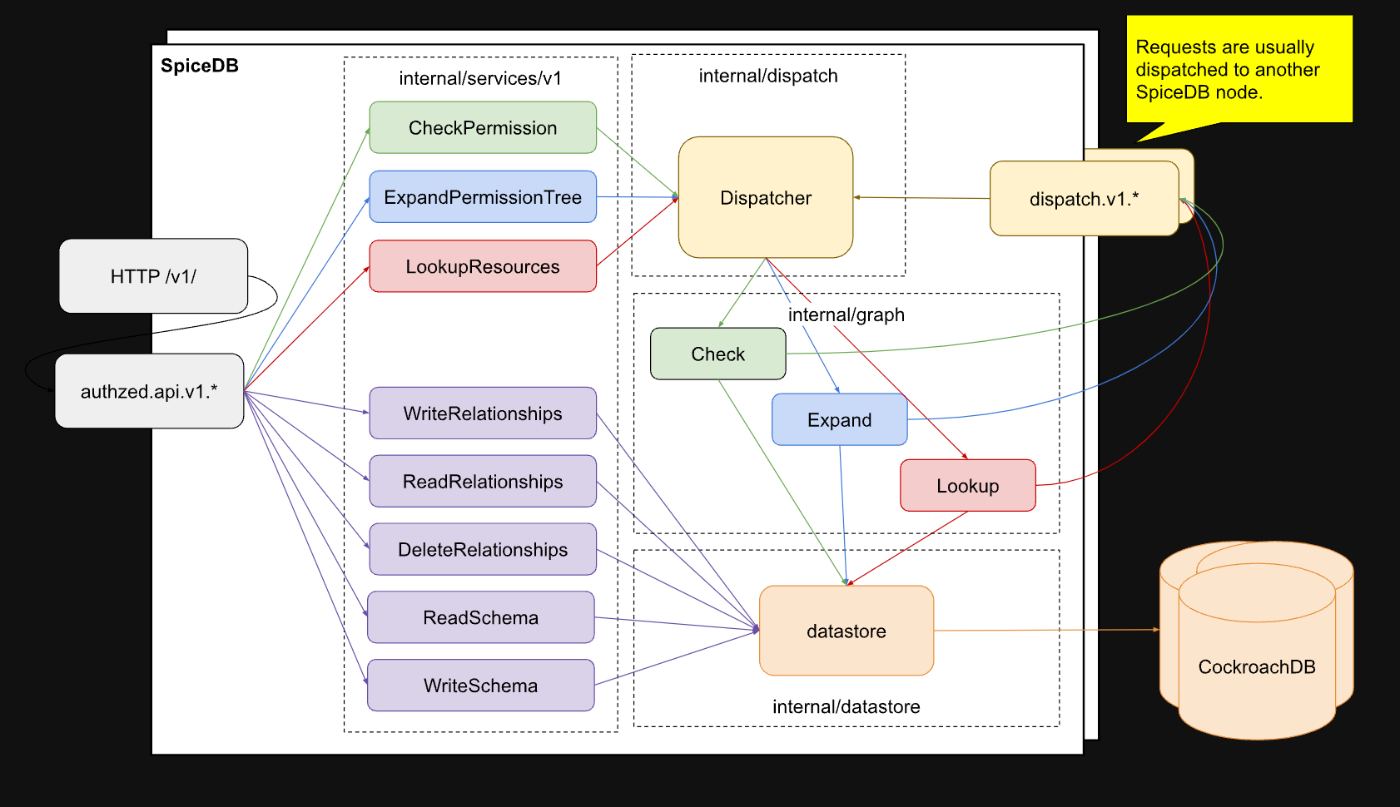
SpiceDBは分散システムであり、SpiceDBクラスター内には複数のSpiceDBノードが存在している。SpiceDBにきた問い合わせは過去に解決したキャッシュの存在を各ノードに問い合わせ、あればキャッシュを返すようになっている。
このディスパッチの機構がk8s環境以外だと難しいし、SpiceDBのバージョンアップをSpiceDB Operatorを使ってダウンタイムなしに実施することも難しいためk8s環境が推奨のデプロイ先となっている。
Relationships
SpiceDBにおけるRelationshipsとはサブジェクトとリソースをリレーションシップで結びつける。SpiceDBのもととなっているZanzibarが採用していたReBAC認可システムはそのリレーションシップを連鎖的にたどり、アクセスできるかどうかを決定する。
このようなRelationshipsを理解するためには以下のような簡単な質問を考えると良い。
Is this actor allowed to perform this action on this resource?
この質問は以下のような核となる要素に分解できる。
Is this actor allowed to perform this action on this resource?
/¯¯¯¯¯¯¯/ /¯¯¯¯¯¯¯¯¯/ /¯¯¯¯¯¯¯¯¯¯¯/
object permission or object
(subject) relation (resource)
ReBACは上記の質問から新たな問題を作り出す。
この資源から始まり、この関係を通じて、最終的にこの対象に到達する関係の連鎖が存在するのか?
この問題はグラフの到達可能性の問題であり、一般的なグラフデータベースは幅優先探索と深さ優先探索に最適化されているがReBACは認可システムに最適化された方法でスケーラブルかつ効率的に計算する。
そして上記の質問は以下のような文法でReBACでは表現される。
document:readme#editor@user:emilia
これは各要素を分解するとこう
resource subject
ID type
\ˍˍˍˍˍ\ \ˍˍ\
document:readme#editor@user:emilia
/¯¯¯¯¯¯¯/ /¯¯¯¯¯/ /¯¯¯¯¯/
resource permission subject
type or relation ID
これはもう説明することもなく、見ただけで何を問い合わせているかわかるだろう。
relationの書き込みについて
オブジェクトのrelationを最新の状態に保つのはアプリケーション側の責務です。公式ドキュメントでは以下のようなrelationの更新パターンを記載してくれている。
SpiceDB-only relationships
definition user {}
definition team {
relation member: user
}
definition resource {
relation reader: user | team#member
permission view = reader
}
このpermissino定義ではユーザーとユーザーが所属するチームを宣言し、あるリソースに関しての読み取り権限を定義しており、これらの関係性はアプリケーション側でDBなどに保存しておく必要は一切ない。
リソースAに対して読み取り権限のあるユーザーは誰か?に関してアプリケーションやDBは知っている必要はなくこれはすべてSpiceDBが知っていれば良く、アプリケーション側はReadRelationshipsやExpandPermissionsTreeを呼び出すだけで良い。
Two writes & commit
2つのオブジェクトの関係を保存する最も一般的な方法はDBとSpiceDBの両方に書き込むことである。
try:
tx = db.transaction()
# Write relationships during a transaction so that it can be aborted on exception
resp = spicedb_client.WriteRelationships(...)
tx.add(db_models.Document(
id=request.document_id,
owner=user_id,
zedtoken=resp.written_at
))
tx.commit()
except:
# Delete relationships written to SpiceDB and re-raise the exception
tx.abort()
spicedb_client.DeleteRelationships(...)
raise
他にもCQRSのイベントを使った非同期的な処理と似た更新方法なども紹介されていたが上記2パターンが最も一般的な更新方法だろう。
Caveats
Caveatsとは条件付きでrelationを定義することができるSpiceDBの機能である。これは動的なポリシーやABAC(Attribute Based Access Control)スタイルの決定をモデル化するエレガントな手法、とされている。
Caveatsは以下のようにスキーマを書くことができる。
caveat first_caveat(first_parameter int, second_parameter string) {
first_parameter == 42 && second_parameter == "hello world"
}
これはCELで評価されているため、非常に柔軟に条件付きrelationを定義することができる。CELに関してはprotovalidateを調べたときにまとめたのでこちらを参照。
以下簡単な例
definition user {}
definition restaurant {
relation customers: user
relation adult_customers: user with is_adult
permission order_food = customers
permission order_alcohol = adult_customers
}
caveat is_adult(age int) {
age >= 20
}
あんまり良いpermission定義ではないかもしれないが、レストランに関連付けられた客であれば注文の権限がある。アルコール注文に関しては20歳以上という条件付きのrelationがある客でないと注文できない。
このスキーマ定義をローカルで起動中のSpiceDB Clusterに反映する。
authzed schema write spicedb/demo.zed
authzed schema read
caveat is_adult(age int) {
age >= 20
}
definition restaurant {
relation customers: user
relation adult_customers: user with is_adult
permission order_food = customers
permission order_alcohol = adult_customers
}
definition user {}
次にrelationを作成する
authzed relationship create restaurant:1 customers user:alice
authzed relationship create restaurant:1 adult_customers user:alice --caveat is_adult
最後に権限チェックを実行する
// 20歳以上なのでアルコールの注文権限はある
authzed permission check restaurant:1 order_alcohol user:alice --caveat-context '{"age": 20}'
true
// 18歳なのでアルコールの注文権限はない
authzed permission check restaurant:1 order_alcohol user:alice --caveat-context '{"age": 18}'
false
// フードはrelationがあればいいので注文権限はある
authzed permission check restaurant:1 order_food user:alice
true
playground
使えばわかるとも思うが一応Playgroundでできることを書いておく。
SpiceDBを試すにはざっくり以下の方法がある。
- ローカルでSpiceDB環境を起動する
- マネージドのSpiceDBに対してコマンドを実行する
- Playgroundを使う
この中で環境構築やマネージドサービスを使用できるように準備する必要がないためPlaygroudを利用するのが一番てっとり早くSpiceDBを試す方法。
schema

ローカルでzedファイルを書くのと同じ感じでschemaファイルを試すことができる。ここでいろんなサブジェクトやリソース、定義したリソースに対するrelationやpermisionを定義することができる。
test relationships
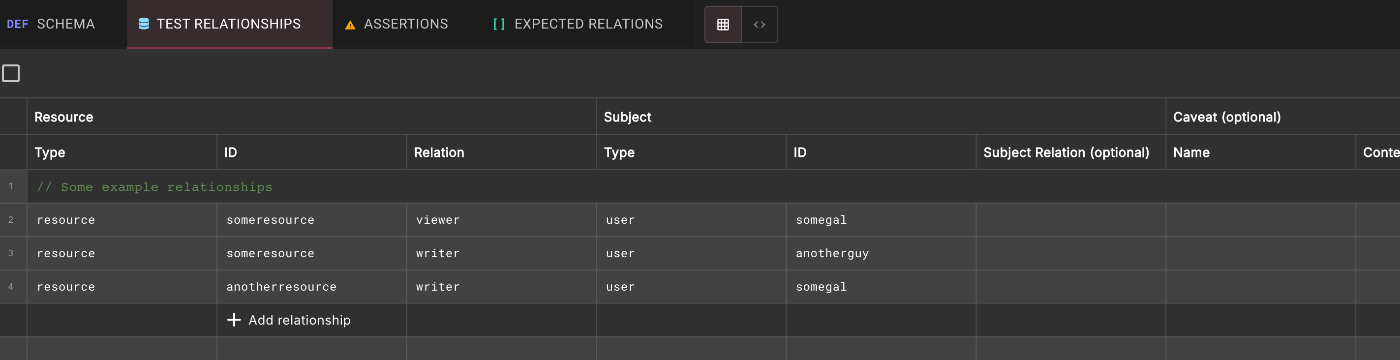
schemaで定義したものに対してrelationを作成、変更、削除できる。後述のテストの実行のためにここでrelationを作成する。
assertions

ここでアサーション定義、実行することができる。試しに作成したスキーマ定義に対してrelationを作成し、テストすることができる。
expected relations

expected relationsは特定のリソースに対してrelation(or permission)のあるサブジェクトを列挙して一度にチェックするのに役立つ。
resource:someresource#view:
- "[user:somegal] is <resource:someresource#viewer>"
- "[user:anotherguy] is <resource:someresource#writer>"
上記の例はresource:someresourceサブジェクトのviewというpermissionをもつサブジェクトをすべて列挙してチェックしている。viewのpermissionを持つのはviewerとしてrelationのあるuser:somegalとwriterとしてのrelationのあるuser:anotherguyであり、すべて列挙できているのでこのアサーションは成功となる。
その他にも、zedコマンドを利用できるterminalやスキーマの変更をwatchしてpermissionをチェックできる機能などもありPlaygroundだけでも十分スキーマ開発できる。
加えて、手元のスキーマファイルをimportしたり、逆にエクスポートしたりすることもできる。エクスポートファイルに関してはダウンロードすると以下のようなファイルになる。
schema: |
definition user {}
/**
* resource is an example resource.
*/
definition resource {
relation writer: user
relation viewer: user
permission write = writer
permission view = viewer + writer
}
relationships: |-
// Some example relationships
resource:someresource#viewer@user:somegal
resource:someresource#writer@user:anotherguy
resource:anotherresource#writer@user:somegal
assertions:
assertTrue:
- resource:someresource#view@user:somegal
- resource:someresource#view@user:anotherguy
- resource:someresource#write@user:anotherguy
assertFalse:
- resource:someresource#write@user:somegal
validation: {}
このファイルはAuthZedが用意してくれているGitHub Actionsでそのまま使ってCI環境でテストすることもできるし、このファイルを元に手元で編集したりもできるので便利。
test server
SpiceDBではtest serverが用意されており以下のコマンドで起動できる。
spicedb server-testing
これはAPIの認証に使う事前共有鍵ごとに空のDB storeを提供するため、テストケースごとに一意な認証鍵を使えば並行してSpiceDBのテストを実行することが可能となる。
test serverを実際のプロダクトで使う場合、GitHub Actionsが用意されているのでCI環境で利用することもできる。
steps:
- uses: "authzed/action-spicedb@v1"
with:
version: "latest"
これでCI環境でtest-serverを起動して使うことができる
Zed Validate
Playgroudでやっていたようなアサーションはzedコマンドのvalidateサブコマンドを使って実行することができる。
zed validate my-schema.zed
zed validateコマンドには拡張子が.zedのschemaファイルと拡張子が.yamlもしくは.zamlのバリデーションファイルを指定することができる。バリデーションファイルは前述のPlaygroundからエクスポートして得られるようなyaml形式のファイルになる。
スキーマファイルを指定した場合はschemaファイルの構文チェックが実施され、バリデーションファイルを指定した場合はファイル内のアサーションなどを実行することができる。
validateコマンドはローカル環境およびCI環境で実施し、AuthZedから提供されている以下のGitHub Actionsを使うことでCI環境でスキーマのテストを実行することができる。
steps:
- uses: "actions/checkout@v4"
- uses: "authzed/action-spicedb-validate@v1"
with:
validationfile: "your-schema.yaml"
VSCode拡張
Playgroudではなく手元の環境でスキーマファイルを書く場合、VSCode拡張が用意されているので入れておくと良い。
Schema Language
ここではスキーマ言語について説明。トップレベルで宣言できるのはdefinitionで定義するオブジェクトとCaveatsである。
/**
* somecaveat is a caveat defined
*/
caveat somecaveat(someparameter int) {
someparameter == 42
}
/**
* someobjecttype is some type that I've decided to define
*/
definition someobjecttype {}
オブジェクトとして定義したものはリソースやサブジェクトとしてSpiceDBのpermission systemで使うことができる。
caveatについては既に説明があるのでそちらを参照。
relation
relationは2つのオブジェクト(もしくはオブジェクトとサブジェクト)間の関係を表す。relationは以下のようにrelation <renation name>: <主語となるオブジェクトタイプ>定義する。
/**
* user represents a user
*/
definition user {}
/**
* document represents a document in the system
*/
definition document {
/**
* reader relates a user that is a reader on the document
*/
relation reader: user
}
relationは以下のように別のrelationやpermissionを含むこともできる。
definition user {}
definition group {
/**
* member can include both users and *the set of members* of other specific groups.
*/
relation member: user | group#member
}
これはつまりこういうこと
// guroup:1のmemberにuser:1のrelationを作成する
zed relationship create group:1 member user:1
// group:2のmemberにgroup:1のmemberのrelationを作成する
zed relationship create group:2 member group:1#member
// group:2に対してgroup:1のmemberが関連づいているかをチェックする
zed permission check group:2 member group:1#member
> true
以下のほうがわかりやすいかもしれない
// 東京営業所のチームAにuser:1は所属
zed relationship create group:tokyo_eigyousyo_team_a member user:1
// 東京営業所のチームBにuser:2は所属
zed relationship create group:tokyo_eigyousyo_team_b member user:2
// チームAとチームBは東京営業所に属している
zed relationship create group:tokyo_eigyousyo member group:tokyo_eigyousyo_team_a#member
zed relationship create group:tokyo_eigyousyo member group:tokyo_eigyousyo_team_b#member
こうすることで東京営業所に対してのpermissionやチームAに対してのpermissionなどを細かく設定でき、チームに対してのRoleを設定したい場合などに便利。
ワイルドカード
以下のようにワイルドカードを使うことができる。
definition user {}
/**
* resource is an example resource.
*/
definition resource {
relation writer: user
relation viewer: user | user:*
permission write = writer
permission view = viewer + writer
}
これは特定のリソースに対して特定のuserもしくはパブリック・アクセスの許可を設定することができる。
zed relationship create resource:1 viewer user:*
zed permission check resource:1 view user:1
> true
zed permission check resource:1 view user:2
> true
...
relationの命名
relationはオブジェクトが別のオブジェクトとどのような関係にあるかを示すもので名詞を使うべきとされている。
permission
permissionはオブジェクトに対して何らかのpermissionを表し、これは計算されたサブジェクトの集合の式で宣言する。具体的には以下
definition user {}
definition document {
relation writer: user
relation reader: user
/**
* edit determines whether a user can edit the document
*/
permission edit = writer
/**
* view determines whether a user can view the document
*/
permission view = reader + writer
}
permissionはdefinitionで定義したオブジェクト内でpermissionキーワードで定義し、そのpermissionの内容は前述したrelationを集合演算子を使った式で表す。
繰り返しになるがアプリケーション側で問い合わせをするようなpermissionは基本的にはrelationだけでなくpermissionを作ったほうが良い。
permissionを表すには以下のような演算子が使える。
-
+(Union) -
&(Intersection) -
-(Exclusion) -
->- アロー演算子。これは後でもう少し説明。
-
.any()はアロー演算子のalias。
.all()
(->)アロー演算子
あるフォルダの中のドキュメントをサブジェクトとして定義したい場合、以下のように親フォルダのrelationからread権限を子のドキュメントに移動させることができる。
definition user {}
definition folder {
relation reader: user
permission read = reader
}
definition document {
relation parent_folder: folder
relation reader: user
/**
* read defines whether a user can read the document
*/
permission read = reader + parent_folder->read
}
Zed Tokens
Consistency(一貫性)の文脈でZed Tokensは出てくる。一貫性とは分散システムの文脈でよく目にする用語であり、SpiceDBもkubernetes環境に最適化された分散システムのため当然この一貫性についても説明がある。
SpiceDBは適切な一貫性と高いパフォーマンスが求められている。
高いパフォーマンスを実現するためにSpiceDBはキャッシュの仕組みを実装しており、permissionに変更がなければキャッシュを返すことで高いパフォーマンスを実現している。このキャッシュの仕組みのためにあるSpiceDBノードから別のノードにキャッシュ問い合わせをすることを可能にするためのk8s環境が推奨環境となっている。(たぶん、k8sクラスター内部のDNS的な話)
しかし、キャッシュを使うということはキャッシュの鮮度を考えなければならない。古いキャッシュへの参照が起こってしまうといわゆる新しい敵問題が起こってしまう。
SpiceDBのAPIリクエストではconsistencyレベルとZedTokensを使用することでpermissionの鮮度とパフォーマンスのトレードオフを実現する。
以下はSpiceDBのAPIのデフォルトのconsistencyレベル

上記から分かる通り、relationの書き込み、削除とスキーマの読み書きにはfully_consistentのレベルが適用されそれ以外はminimize_latencyのレベルが適用されるようになっている。
minimize_latencyはキャッシュの中で最も存在する可能性が高いものを応答するようにするレベルで、パフォーマンスの最適化を図っている。トレードオフとして注意して使わないと新たな敵問題が発生する可能性がある。
fully_consistentのレベルはSpiceDBの存在するデータが最新のものを参照することを保証する。このレベルはキャッシュを明示的にバイパスするためレイテンシに劇的な影響を与える。書き込み後の読み取りが必要な場合、ZedTokensを使うことでデータの鮮度を保証するのに加え、パフォーマンスも維持することができる。
ZedTokensはpermissionのチェック、relationの書き込み、削除のAPIを実行したあとに返される。具体的には以下のAPI
- CheckPermission
- BulkCheckPermission
- WriteRelationships
- DeleteRelationships
返されるZedTokensは以下のようなもの
zed relationship create resource:2 viewer user:*
> GhUKEzE3NDY5MzkzMzQ1MzEwMDAwMDA=
ZedTokensはアプリケーションのDBに保存されることが理にかなっているケースがある。
具体的には以下のようなケース
- リソースが作成、削除されるとき
- リソースの内容が変更されるとき
- リソースへのアクセスが追加、削除されるとき
このようなイベントが発生するとき新たな敵問題を防ぎ一貫性を保つために一貫性を完全に保つような問い合わせをするかZedTokensを使う必要がある。
一貫性を完全に保つとは前述したfully_consistentのレベルで問い合わせをするということでこれはレイテンシーに影響を及ぼすのは前述した通り。
このときに発行されたZedTokensをリソースの情報といっしょに保存しておくことでfully_consistentでのレベルでの問い合わせをせずにZedTokensを使ってパフォーマンスを維持したまま一貫性を維持した問い合わせが可能となっている。
SpiceDBのもととなっているGoogleのZanzibarではこのようなケースのためにContentChangeCheck APIというものを用意していたが、これはSpiceDBのような設定可能なconsistencyレベルのような仕組みを持っていないからである。
Client Library(Go)
アプリケーション側でのSpiceDBの利用について。まずGoでは以下のパッケージを使う。
go mod init github.com/JY8752/spicedb-go-demo
go get github.com/authzed/authzed-go
go get github.com/authzed/grpcutil
authzed/grpcutilは厳密には必須ではないがSpiceDBに対してのclientコードを作成するのにコードを大幅に削減できる。
以下のコードを作成
package main
import (
"context"
"log"
v1 "github.com/authzed/authzed-go/proto/authzed/api/v1"
"github.com/authzed/authzed-go/v1"
"github.com/authzed/grpcutil"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
func main() {
emilia := &v1.SubjectReference{Object: &v1.ObjectReference{
ObjectType: "user",
ObjectId: "emilia",
}}
firstPost := &v1.ObjectReference{
ObjectType: "post",
ObjectId: "1",
}
client, err := authzed.NewClient(
"localhost:50051",
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpcutil.WithInsecureBearerToken("averysecretpresharedkey"),
)
if err != nil {
log.Fatalf("unable to initialize client: %s", err)
}
resp, err := client.CheckPermission(context.Background(), &v1.CheckPermissionRequest{
Resource: firstPost,
Permission: "read",
Subject: emilia,
})
if err != nil {
log.Fatalf("failed to check permission: %s", err)
}
if resp.Permissionship == v1.CheckPermissionResponse_PERMISSIONSHIP_HAS_PERMISSION {
log.Println("allowed!")
} else {
log.Println("not allowed!")
}
}
GitHubリポジトリのREAEMEにはAuthZedのマネージドに接続するコード例が記載されているが今回はローカルで起動しているSpiceDBクラスタに接続してみる
// ローカルでkubernetesクラスタを起動して、そこにSpiceDBクラスタをデプロイしている前提
// 以下コマンドでポート転送する
kubectl port-forward deployment/dev-spicedb 50051:50051
実行する前にrelationを作っておく
authzed relationship create post:1 viewer user:emilia
コードを実行
go run main.go
2025/05/11 22:34:38 allowed!
Client Library(Node)
npm i @authzed/authzed-node
import { v1 } from "@authzed/authzed-node";
const client = v1.NewClient(
"averysecretpresharedkey",
"localhost:50051",
v1.ClientSecurity.INSECURE_LOCALHOST_ALLOWED,
);
const { promises: promiseClient } = client; // access client.promises
// Create the relationship between the resource and the user.
const firstPost = v1.ObjectReference.create({
objectType: "post",
objectId: "1",
});
// Create the user reference.
const emilia = v1.ObjectReference.create({
objectType: "user",
objectId: "emilia",
});
// Create the subject reference using the user reference
const subject = v1.SubjectReference.create({
object: emilia,
});
const checkPermissionRequest = v1.CheckPermissionRequest.create({
resource: firstPost,
permission: "read",
subject,
});
// client.checkPermission(checkPermissionRequest, (err, response) => {
// console.log(response);
// console.log(err);
// });
const result = await promiseClient.checkPermission(checkPermissionRequest);
console.log(result);
npx tsx main.ts
{
permissionship: 2,
checkedAt: { token: 'GhUKEzE3NDcwMTc0MjUwMDAwMDAwMDA=' }
}
clientから非同期client取り出せて使えるようになってるのでPromise受け取って処理書いたりもできる。
各種APIの利用
基本はCheckPermissionでこれはすでにコード例でみた。
CheckBulkPermissionsとかもあるが一旦これはおいておいてあとはrelationshipのと書き込み、読み取り、削除といった基本操作。
ここで紹介すべきはLookup系のメソッド。これはSpiceDBのリバースインデックスの特性でrelationをたどることで以下のことが実現できるようになっている。
- リソースに対してrelation(or permission)があるサブジェクトをすべて取得する
- あるサブジェクトがrelation(or permission)関係にあるリソースをすべて取得する
これは認可機能を持つアプリケーションを開発していくうえで非常に強力な関数となるので覚えておいたほうが良い。
具体的な使用例は以下のような感じ。コードはGo
func (c *spiceDBClient) LookupResources(ctx context.Context, request *LookupResourcesRequest) (iter.Seq[string], error) {
subject := newSubjectReference(request.subject, request.subjectId)
resp, err := c.client.LookupResources(ctx, &v1.LookupResourcesRequest{
ResourceObjectType: request.resourceObjectType.String(),
Permission: request.permission.String(),
Subject: subject,
})
if err != nil {
return nil, err
}
return receive(func() (string, error) {
r, err := resp.Recv()
if err != nil {
return "", err
}
return r.ResourceObjectId, nil
}), nil
}
ちょっと無駄にiterとか使ってわかりづらいかもしれないがポイントは以下
resp, err := c.client.LookupResources(ctx, &v1.LookupResourcesRequest{
ResourceObjectType: request.resourceObjectType.String(),
Permission: request.permission.String(),
Subject: subject,
})
SpiceDBのclientから生えているLookupResourcesを使った例で、リソースのオブジェクトタイプとpermission、Lookupしたいサブジェクトを指定することでアクセス可能なリソースがすべて取得できる。
authzed relationship create post:1 viewer user:emilia
authzed relationship create post:2 viewer user:emilia
// user:emiliaでLookup
go run main.go
2025/05/14 13:13:17 resources: [1 2]
あと、Lookup系の関数はgrpcのserver streamingとして返ってくるので以下のような実装が必要。(実装は雰囲気)
for {
r, err := resp.Recv()
if errors.Is(err, io.EOF) {
break
}
if err != nil {
return "", err
}
r.ResourceObjectId
}
もう一つLookupSubjectsがあるが実装としては同じような感じなので省略。
SpiceDB Clusterの構築
書いたつもりで書いてなかったので。
ローカル環境で構築を想定。今回はmikubeを使うがkindなどを使っても良い。
minikube start
SpiceDB Operatorのインストール
kubectl apply --server-side -f https://github.com/authzed/spicedb-operator/releases/latest/download/bundle.yaml
以下のマニフェストファイルを作る
apiVersion: authzed.com/v1alpha1
kind: SpiceDBCluster
metadata:
name: dev
spec:
config:
# replicas: 2
# datastoreEngine: postgres
# logLevel: debug
datastoreEngine: memory
secretName: dev-spicedb-config
---
apiVersion: v1
kind: Secret
metadata:
name: dev-spicedb-config
stringData:
preshared_key: "averysecretpresharedkey"
今回手抜きでdatastoreとしてdatabaseは使わずにオンメモリでやっている。ので、clusterを停止させたらデータはなくなる。あと、preshared_keyはちゃんとやるなら秘匿情報として扱う必要がある。でかたら、applyする
k apply --server-side -f k8s/spicedb_cluster.yaml
以下のコマンドでポートフォワードすることでローカルの50051ポートに対してSpiceDBにアクセスできる。
kubectl port-forward deployment/dev-spicedb 50051:50051