Javaまとめ
Javaの特徴
- 1996年にサン・マイクロシステムズによって開発された
- 2010年にオラクルに吸収合併されたことによって版権もそちらに移っている
- クラスベースのオブジェクト指向言語
- マルチスレッド
- ガベージコレクション
- JVMという仮想マシン上で実行されるため、実行環境を問わないプラットフォーム非依存な言語
- webアプリケーション、API、モバイル、組み込みといったさまざまな開発に使用されている
- 世界中で使用されている言語だが、特に日本では金融システムのような大規模で堅牢性の問われるシステムに広く使われている
- 2023年9月にJava21がリリース
- Java はレガシーと言われることが多いがJava8では関数型インターフェースとラムダ式、ストリームAPIが導入されており、最近のJavaではよく使用されているモダンな言語にあるような様々な機能も導入されておりJava自体は進化を続けている
- Javaがレガシーなのではなく、Javaが使われている環境がレガシーなことが多い
- レガシーという言葉も悪い意味ではなく、IT業界で「枯れている」という言葉は安定して使われてきたということでもあり、公開されている情報も多いため、悪いことではない
- 実際の開発現場では最新の技術よりも充分に枯れている技術が採用されることも多い
- Javaは静的型付け言語のためプログラムを実行する前にコンパイルを必要とし、コンパイル時に型を必要とする
- 動的型付け言語は実行時に書いたプログラムを解釈するインタプリンタ方式
- Rubyなどでは実行時にコンパイルしながら実行するJITコンパイラなどを採用していたりする
- なので動的言語だから遅いという浅い考えは捨てた方がいいし、静的型付言語の方が型があって速いみたいな考えもやめたほうがいい
- Javaはコンパイルによってプログラムをバイトコードに変換する
- Javaの言語設計の核心であるWrite Once, Run Anywhereは一度書いたらどこでも実行できるとあるように、JVMという仮装マシン上で中間言語を実行するようにしたことで実現されている
インタプリンタとコンパイル
Javaのようなコンパイル言語と比較される動的言語はコンパイルを必要としないでインタプリンタによって解釈される。このインタプリンタにより解釈の部分がいまいち具体的に何をしているのか気になったので調べたけどあんまりいい答えは得られなかった。
コンパイル言語が中間言語や機械語にコードを変換して実行するというのはいいのだが動的言語がコードを解釈して実行とは何なのか??
これは書いてあるそのままでコードをインタプリンタが解釈して実行するという説明以上にいい説明はなさそう。解釈というのは中間言語や機械語に変換、つまりコードを実行時に解釈してコンパイルし、実行していると思っていたがそれは違うらしい。そういうインタプリンタを採用した言語もあるが、機械語や中間言語に変換するのは絶対ではないらしい。インタプリンタの実行速度を改善するためにJITコンパイラが組み込まれていたりするが、JITコンパイラが逐次的に必要な箇所をいい感じにコンパイルしてキャッシュして実行するような方式なのでインタプリンタ方式がコードを実行時にコンパイルするという風に誤解されるようになったのかもしれない。それをやってるのはJITコンパイラでありインタプリンタではない
コメント荒れてるけど参考
Javaのコンパイルの仕組みは?
Javaはjavacコマンドを使い.javaファイルから.classファイルにコンパイルする。これはJavaのソースコードをJVMが解釈できる中間言語(バイトコード)に変換している。実行はJVM上で実行され、バイトコードをインタプリンタもしくはJITコンパイラが読み取り実行される。一言でコンパイルといってもこのように思っているよりも複雑。
JDKとJRE
JDKはJava Development Kit。Javaで開発するためのツール一式が揃っている。
JREはJava Runtime Environment。これはJavaの実行環境。
JDKはコンパイラであるjavacも実行環境であるJREも含んでる。今からJavaで開発しようとするならJDKのことだけ考えていればよさそう。
Javaのディストリビューション
以下の記事がわかりやすい(岸田さんの記事なので内容の信憑性は問題ないと思う)
2017年にバージョンアップの方針の変更と同時にJavaを有償化する話が出た。これはOracle社のサイトからダウンロードしたJavaを使ってwebサービスを運用する場合に有償になるのはなるが、それ以外の無償のJavaを使うことは普通にできる。
それ以外の無償のJavaというのはAmazonのcorrettoやTemrinなど複数の無償ディストリビューションがある。
Javaの実装としてOSSで公開されているのはOpenJDKのみでこれをビルドして実行ファイルとして配布しているのが各ディストリビューションということになる。
JavaとOracleの話はしばしば話題に上がる(主にライセンスの話)がOracle以外の無償Javaを使うのであればそこまで関係ない、はず。
とりあえず、Javaの学習やJavaで開発するだけであればOracleやライセンスの話は関係ない
Javaのリリースサイクル
Java17まではあんまり定まっていない感があるがJava11からJava17の間は3年だった。しかし、このリリースサイクルがうまくいっていたのとJavaの新仕様を使ってもらうためにLTSのサイクルが2年になったようで2023年の9月にJava21がリリースされている。これが最新のLTS。次は 2025年の9月でJava25の予定。
LTSは2年に1回だけどfeatureリリースは年に2回で9月と3月
Javaの環境構築
WindowsとMacの両方を考慮するのめんどくさいからVSCodeのDevcontainersでいい感じにJavaの開発環境を配布できないだろうか??
Docker Desctopインストールして起動するまでがハードル高いかな??
一応VSCodeでJavaを書きたい人はいるみたい
devcontainerの中でgradle initしたところ作成された雛形とgradleのバージョンの相違的なのでビルドもできずここらへんよくいじくること多いけどこんなの未経験の段階でやったら心折れまくるだろうなと思ったのでDevcontainerで開発するのは諦める
素直にIntelliJで
IntelliJは単体でインストールも可能だがToolbox Appを使用してインストールすることで自動アップデートができるらしい。
Javaのインストールは
- IntelliJからインストールする方法
- 自分で用意する方法
があるけどIDEからやると知らない間にJavaがインストールされていてインストールしたという自覚さえなくなるので自分で用意してみる方がいいかも
というわけでSDKMAN
(関係ないけどasdfがあんまり機能していないなぁ)
curl -s "https://get.sdkman.io" | bash
source "$HOME/.sdkman/bin/sdkman-init.sh"
sdk version
SDKMAN!
script: 5.18.2
native: 0.4.6
Windowsは別途インストール方法を確認
# 最新LTSのJavaをインストール
sdk install java
java --version
openjdk 21.0.3 2024-04-16 LTS
OpenJDK Runtime Environment Temurin-21.0.3+9 (build 21.0.3+9-LTS)
OpenJDK 64-Bit Server VM Temurin-21.0.3+9 (build 21.0.3+9-LTS, mixed mode)
パスも通ってる
ビルドシステム
MavenかGradleが必要と思いきやIntelliJは内部に独自のビルドシステムを持っているのでGradleすら自分で用意する必要がなさそうだ。
IntelliJのビルドシステムでプロジェクト作成すると拡張子.imlのファイルが作成されている。さすがにGradleでビルドしたいのでビルドシステムにはGradleを指定。
gradlewを用いてプロジェクトを作成するのでGradleのインストールはローカルマシンに必要ないのか。
ただ、IntelliJでJava21のプロジェクトを作成しようとするとサポート対象外と警告が出る。
IntelliJが古いのか。IntelliJアップデートしたら作成できた。
ローカルにJavaもGradleもインストール不要でプロジェクト作成できるのか。IntelliJ神だな。
build.gradleがgroovyじゃなくてKotlin DSLがデフォルトに変わってそう。
今からだとどっちでやるのがいいんだろうなぁ。。
ディレクトリ構成
.
├── build
│ ├── classes
│ │ └── java
│ │ └── main
│ │ └── org
│ │ └── example
│ │ └── Main.class
│ ├── generated
│ │ └── sources
│ │ ├── annotationProcessor
│ │ │ └── java
│ │ │ └── main
│ │ └── headers
│ │ └── java
│ │ └── main
│ └── tmp
│ └── compileJava
│ └── previous-compilation-data.bin
├── build.gradle.kts
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
├── settings.gradle.kts
└── src
├── main
│ ├── java
│ │ └── org
│ │ └── example
│ │ └── Main.java
│ └── resources
└── test
├── java
└── resources
- build ビルドした成果物。バイトコード
- build.gradle.kts ビルドファイル
- gradle gradlew関連のファイル
- src ソース
- .gitignore
- gradlew gradlewの起動スクリプト
- gradlew.bat gradlewの起動スクリプト
- settings.gradle.kts プロジェクト構成の設定など。マルチプロジェクト構成のときなど
gradlew
gradlewとはGradle Wrapperの略称でプロジェクトに組み込まれる自己完結型バージョンのこと。これのおかげでチームメンバーは自分でローカルマシンにGradleをインストールする必要はなく、バージョンを統一してプロジェクトをビルドすることができる。gradle-wrapper.jarはgradlewの実行に必要なJavaライブラリ。gradle-wrapper.propertiesには使用するGradleのバージョンやダウンロードURLなどが記述されている。gradlewの起動スクリプトはgradlewとgradlew.bat。
build.gradle(.kts)
ビルドに必要なプロジェクトの依存関係やプラグイン、ビルドタスクなどを記述する。build.gradleは大きく以下のように分けられる。
- プラグイン
- リポジトリ
- 依存関係
- タスク
プラグイン
plugins {
id("java")
}
上記例ではjavaプラグインを使うことを宣言している。
リポジトリ
repositories {
mavenCentral()
}
ライブラリをどこから取得するか。上記例ではMaven Central。jcenterなんかもあったが非推奨になった気がする。
依存関係
プロジェクトの依存関係。
dependencies {
testImplementation(platform("org.junit:junit-bom:5.10.0"))
testImplementation("org.junit.jupiter:junit-jupiter")
}
上記例ではJUnitの依存関係を宣言している。testImplementationでは本番ビルドには含まれないのでテストライブラリなどはtestImplementationで宣言する。
platformはgradle5.0以降で導入され、特定のライブラリ群の依存関係を一元管理するためのもの。上記例ではJUnitのBOMを指定することで、junit-jupiterのバージョンを宣言することなく依存関係を宣言している。
タスク
タスクは独自に宣言して使うこともできる。使用できるタスクは以下のコマンドで確認できる。
./gradlew tasks
以下の例ではtestタスクにJUnitを使用することを宣言している。
tasks.test {
useJUnitPlatform()
}
独自のタスクを定義するには以下のように登録する
tasks.register("hello") {
group = "Other"
doLast {
println("Hello World!!")
}
}
./gradlew hello
> Task :hello
Hello World!!
Javaの基礎文法
- まずはクラスについて
- Javaは一つのファイルに一つのクラスを定義する
- クラスについて詳しくは後述
- とりあえずJavaで何かプログラムを書きたければクラスを宣言してそこに書く必要があるということ
- Javaのプログラムを実行する場合、エントリーポイントを探して実行する
public class Main {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}
- 上記が最小のJavaの実行コード
-
public static void main(String[] args)がエントリーポイントとなる - これが意味することはクラスの回で詳しく説明する
-
System.out.println()についてはJavaで標準出力に出力するための記法 - とりあえず何かターミナルに表示させたければこれを使うでおk
型
- Javaは静的型付け言語のため変数の宣言、関数の引数や戻り値に型をつける必要がある
- Javaの型には以下のようなものがある
プリミティブ型
- byte 8ビット整数
- short 16ビット整数
- int 32ビット整数
- long 64ビット整数
- float 32ビット浮動小数
- double 64ビット浮動小数
- char 16ビットUnicode文字
- boolean true or false
ラッパー型
- Byte
- Short
- Integer
- Long
- Float
- Double
- Character
- Boolean
- プリミティブ型を参照型として扱えるようにしたラッパークラス
- プリミティブ型ではnullが扱えないがラッパークラスであれば扱える
- ラッパークラスには便利なstaticメソッドが用意されていたりする
参照型
- クラス 全てのJavaクラス。ラッパークラスも含めて
- インターフェース Listのようなインターフェースも参照型
- 配列 int[]やString[]のような
- 列挙型(enum) enumについて詳しくは後述
文字列
- Javaでの文字列の基本的な宣言は以下
String str = "Java";
- 文字はダブルクォーテーションで囲う
- 文字列の結合
System.out.println("Hello, " + "World!!");
System.out.println("Hello, ".concat("World!!"));
- 文字列の結合はいろいろ方法があるが単純な結合であれば+演算子で良い
- concatのような関数も用意されているが単純な結合であれば対してパフォーマンスに差はないので+演算子で十分
- 基本的に文字列はイミュータブルで文字列を結合するには文字列の再生成が生じるためコストが高い
- なので、文字列の結合頻度が高い場合はStringBuilderなどを使った方がパフォーマンスが高い
// StringBuilder
var sb = new StringBuilder();
for(var i = 0; i < 100; i++) {
sb.append(i);
}
var str = sb.toString();
System.out.println(str);
- StringBuilderは内部的にバッファを持っている
- デフォルトでは16文字分の容量
- Javaは文字列をUTF-16で扱い、UTF-16は一文字2バイトなのでデフォルトでは32バイト
- StringBuilderはバッファを超えると文字列の倍のバッファサイズに自動で拡張する
var sb = new StringBuilder();
System.out.println(sb.capacity()); // 16
sb.append("a".repeat(17));
System.out.println(sb.capacity()); // 34
- よく使いそうな処理
// 文字列の長さ
System.out.println("abcde".length()); // 5
// 小文字、大文字
System.out.println("upper".toUpperCase());
System.out.println("LOWER".toLowerCase());
// 空白 isEmpty, isBlank, trim
var emptyStr = " ";
System.out.println("emptyStr is empty : " + emptyStr.isEmpty()); // false
System.out.println("emptyStr is blank : " + emptyStr.isBlank()); // true
var includeSpaceStr = " Java ";
System.out.println(includeSpaceStr);
System.out.println(includeSpaceStr.trim());
System.out.println(includeSpaceStr.strip()); // Unicodeの空白文字全体を対象
- isEmptyとisBlankで挙動が違うので注意
- isEmptyは空白を許容しないがisBlankは空白を許容するため空白のみの文字列も空とみなす
- 文字列のフォーマット
var name = "Alice";
var age = 20;
var formated = String.format("user name is %s. age is %d", name, age);
System.out.println(formated);
formated = "";
formated = "user name is %s. age is %d".formatted(name, age);
System.out.println(formated);
- フォーマット指定子の代表的なものは以下
-
%s文字列 -
%d整数 -
%f不動少数 -
%x16進数
-
System.out.printf("%s\n", "Java");
System.out.printf("%d\n", 21);
System.out.printf("%f\n", 1.11); // 1.110000
System.out.printf("%.2f\n", 1.11); // 1.11
System.out.printf("%x\n", 255); // ff
System.out.printf("%04d\n", 1); // 0001
- 文字列抽出と分割、prefixとsuffixへのマッチング
// substring
var day = "2024/5/8";
System.out.println("today is " + day.substring(7) + " day");
System.out.println("today is " + day.substring(0, 4) + " year");
// split
var arr = day.split("/");
for (var s : arr) {
System.out.println(s);
}
// startWith, endWith
class Id {
static String get(int num) {
return num == 0 ? "01-xxxx" : "xxxx-a";
}
}
System.out.println("start with 01: " + Id.get(0).startsWith("01")); // true
System.out.println("end with a: " + Id.get(1).endsWith("a")); // true
- Stringはcharの集合
- charの配列をStringにしたりStringをcharの配列にしたりできる
- charはシングルクォートで囲う
// charの話
char a = 'a';
for(char c : "Java".toCharArray()) {
System.out.println(c);
}
- 正規表現と置換
-
java.util.regex.Patternとjava.util.regex.Matcherを使う - 正規表現は普通に文字列として書ける
- 基本は
Pattern p = Pattern.compile("<正規表現>");でPatternオブジェクトを作る -
Mathcer m = p.mathcer("<文字列>");で指定の文字列に正規表現をマッチさせる -
m.find()ではbooleanが返り、マッチしていればtrueが返る
var p = Pattern.compile("^Hello, World(!+)?$");
var m1 = p.matcher("Hello, World");
var m2 = p.matcher("Hello, World!");
var m3 = p.matcher("Hello, World!!");
var m4 = p.matcher("Hello, World!!$");
System.out.println("m1: "+m1.find());
System.out.println("m2: "+m2.find());
System.out.println("m3: "+m3.find());
System.out.println("m4: "+m4.find());
var p2 = Pattern.compile("(\\d{3})-(\\d{3})-(\\d{4})");
var m5 = p2.matcher("049-111-2222");
if(m5.find()) {
System.out.println(m5.group());
System.out.println(m5.group(1));
System.out.println(m5.group(2));
System.out.println(m5.group(3));
}
- 正規表現でマッチさせて置換とかもできる
var pass = "ajeiuikoljlx";
var passPattern = Pattern.compile("[a-zA-Z]");
var passMatcher = passPattern.matcher(pass);
System.out.println(passMatcher.replaceAll("x"));
- 文字列とbyte配列について
- 文字列はgetBytes()のような関数でbyte[]に変換できる
- このbyte値はエンコーディングする文字コードで変わってくる
- なのでUTF-8とSJISでエンコードした場合のバイト配列の値は同じ文字でも変わってくる
- 現代では問題ないことも多そうだが明示的に文字コードを指定する癖、もしくはどの文字コードでエンコードしているのかを常に意識する癖をつけておくとここら辺の処理でハマっても慌てずに対処できそう
- ちなみに絵文字のようなマルチバイト文字のバイト配列を取得すると以下のような結果になる
System.out.println(Arrays.toString("😄".getBytes()));
// [-16, -97, -104, -124]
- 上記の絵文字は4バイト文字でJavaのbyte型は-128~127の範囲の値を取るため128以上の値は負の値になるため上記のような結果になる
// テキストブロック Java 15
var json = """
{
"name": "Alice",
"age": 20,
}
""";
System.out.println(json);
// 文字列テンプレート Java 21 プレビュー機能
var lang = "Java";
System.out.println(STR."This code is \{lang}");
- 文字列テンプレートはプレビュー機能で実行するのに
enable-previewオプションをつける必要があったり(つけても警告でたけど)使えるようにするのに手間なので使いたい人だけ使ってください - Unicode文字それぞれにはコードポイントが割り振られている
- このコードポイントだったり文字コードだったりを扱うのは結構難しいところだと思ってる
数値
// 32ビット整数
int num = 1;
Integer num2 = 2;
// 64ビット整数 数字の後に`L`をつける
long num3 = 3L;
Long num4 = 4L;
// 32ビット浮動小数 数字の後に`f`をつける
float num5 = 0.1f;
Float num6 = 0.1f;
// 64ビット浮動小数
double num7 = 0.1;
Double num8 = 0.1;
// 四則演算
// 足し算
System.out.println(num + num); // 2
System.out.println(num + num2); // 3(後述のアンボクシングが働く)
// 引き算
System.out.println(5 -1); // 4
// 掛け算
System.out.println(2 * 5); // 10
// 割り算
System.out.println(10 / 2); // 5
// System.out.println(10 / 0); // 0徐算 ArithmeticExceptionが発生する
// 暗黙的な型変換
System.out.println(num + num5); // 1.1
// オートボクシングとアンボクシング
var list = new ArrayList<Integer>();
// オートボクシングでintからIntegerに自動変換される
list.add(1);
list.add(2);
// アンボクシングでIntegerからintに自動変換される
int sum = 0;
for(int i : list) {
sum += i;
}
// オートボクシングのパフォーマンス影響
// 毎回Integerインスタンスを生成することになりとてもコストがかかる処理になってしまう
// IntelliJはこのようなとき警告出してくれるので便利
Integer sum2 = 0;
for(var i = 0; i < 1000;i++) {
sum2 += i;
}
// Integerはnullを受け入れるので、以下のようにnullが混入する場合もある
// 以下の場合、nullのラッパークラスをアンボクシングしようとしてNullPointerExceptionが発生する
// list.add(null);
// for(var i : list) {
// i++; // この処理に特に意味はない
// }
// 小数の計算は正確には表現できない
// プログラムにおける小数は近似値でしかなく以下のような誤差が生じてしまう
// お金の計算のような誤差が許されないような計算をする場合はBigDecimalを利用する
System.out.println(1.00 - 9 * 0.10); // 0.09999999999999998
var n1 = new BigDecimal("1.00");
var n2 = new BigDecimal("9");
var n3 = new BigDecimal("0.10");
System.out.println(n1.subtract(n2.multiply(n3))); // 0.10
// 文字列 -> 数値
Integer.parseInt("1");
try {
Integer.parseInt("a");
} catch (Exception e) {
System.out.println(e.getClass()); // class java.lang.NumberFormatException
System.out.println(e.getMessage()); // For input string: "a"
}
制御構文
for
// for文
for(int i = 0; i < 10; i++) {
System.out.print(i); // 0123456789
}
/// 拡張for文
var list = List.of(1, 2, 3);
for(var num : list) {
System.out.print(num); // 123
}
if
var result = calculator.add(1, 2);
if(result == 3) {
System.out.println("result is 3!!");
} else if(result == 5) {
System.out.println("result is 5!!");
} else {
System.out.println("result is other!!");
}
三項演算子
- 三項があれば単項や二項もある
- 単項とは
++や単純に正負の数を表すときの+記号など - 二項は
1 + 1や1 + 1 == 2のようなやつ - 三項はオペランドが三つということらしい
/// 三項演算子
var message = result == 3 ? "result is 3!!" : "result is " + result;
System.out.println(message);
while
// while
// 123445678910
var counter = 0;
while(counter < 10) {
counter++;
System.out.print(counter);
}
counter = 0;
System.out.println();
// 123445678910
// do-whileは最初に処理ブロックが評価されるので絶対一回は処理が実行される
// どちらでもいいがdo-whileでないといけない場面もほとんどないかつ、
// 条件が最初にきていたほうが読みやすいので前者の書き方推奨
do {
counter++;
System.out.print(counter);
} while (counter < 10);
switch
// switch式 Java12
// switch式は式なので変数に結果を代入できる
// breakがいらない
// Java12以降であればswitch式を推奨
var result3 = calculator.add(1, 2);
switch (result3) {
case 0 -> System.out.println("result 0");
case 1 -> System.out.println("result 1");
default -> System.out.println("result " + result3);
}
var result4 = calculator.add(1,1);
var result5 = switch (result4) {
case 0 -> 0;
case 1, 2 -> result4 * 2;
default -> result4;
};
System.out.println(result5); // 4
switchはJava17あたりからバージョンが上がるごとに変更が入っている。主にswitch式によるパターンマッチングあたりの挙動に関するものが多い感じ。以下の記事がそこらへんまとめてくれてる
配列とList, Set, Map
// 配列
// 初期化1 配列のサイズを指定 この場合はサイズ5でnullが格納される
var strArr = new String[5];
// 初期化2 宣言と同時に初期値を指定
strArr = new String[]{"a", "b", "c"};
var arr = new int[2];
// 配列への書き込み
arr[0] = 1;
arr[1] = 2;
// 配列の読み込み
System.out.printf("arr[0]: %d arr[1]: %d%n", arr[0], arr[1]); // arr[0]: 1 arr[1]: 2
// 配列のサイズを超えた要素にアクセスするとエラー
try{
arr[2] = 3;
} catch(IndexOutOfBoundsException e) {
System.out.println("サイズを超えた要素にアクセスするとエラー");
}
// 配列のループ
for(var i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
for(var num : arr) {
System.out.println(num);
}
// 多次元配列
var matrix = new int[][] {
{1, 2, 3},
{1, 2, 3},
{1, 2, 3},
};
System.out.println("---------------------------------------------------");
// List
// Listはインターフェースで実際の実装クラスがある
// 代表的なのがArrayListでLinkedListといったクラスもある
var arrayList = new ArrayList<Integer>();
var linkedList = new LinkedList<Integer>();
// 追加
arrayList.add(1);
arrayList.add(2);
// 取得
System.out.println(arrayList.get(1)); // 2
// 削除
System.out.println(arrayList); // [1,2]
arrayList.remove(1);
System.out.println(arrayList); // [1]
// contains
if(arrayList.contains(1)) {
System.out.println("arrayList contains `1`");
}
// isEmpty
arrayList.clear();
if (arrayList.isEmpty()) {
System.out.println("arrayList is empty");
}
// immutableList
List<Integer> immutableList = List.of(1, 2, 3);
try {
immutableList.add(4);
}catch (UnsupportedOperationException e) {
System.out.println("イミュータブルListは変更できないよ");
}
// sort
var sortList = new ArrayList<>(List.of(2, 3, 1));
System.out.println(sortList); // [2, 3, 1]
Collections.sort(sortList); // 自然な順序でソート
System.out.println(sortList); // [1, 2, 3]
// 匿名クラスでComparatorインターフェースのcompareメソッドを実装する
sortList.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o2, o1);
}
});
System.out.println(sortList); // [3, 2, 1]
// ラムダ式
sortList.sort((o1, o2) -> Integer.compare(o1, o2));
System.out.println(sortList); // [1, 2, 3]
// メソッド参照
sortList.sort(Comparator.comparingInt(o -> o));
// Set
var set = new HashSet<Integer>();
var linkedHashSet = new LinkedHashSet<Integer>();
var treeSet = new TreeSet<Integer>();
var immutableSet = Set.of(1, 2, 3);
// Map
var map = new HashMap<String, String>();
var linkedHashMap = new LinkedHashMap<String, String>();
var treemap = new TreeMap<String, String>();
var immutableMap = Map.of("key1", 1, "key2", 2);
ArrayListとLinkedList
-
ArrayListは内部的に配列を利用している
-
要素の追加や取得はO(1)で非常に高速
-
一方要素の削除やデータの挿入は要素をシフトさせる必要があるため最悪O(N)の計算量で遅い
-
わかりやすいのだと先頭に要素を追加するなどの操作は遅い
-
LinkedListは要素同士を前後双方向のリンクで参照する
-
要素の挿入、削除はリンクの付け替えで済むので高速に動作する
-
一方、要素の取得は先頭から辿る必要があるため最悪O(N)の計算量で遅い
-
基本的にはArrayListで要件は満たせることが多いはず
-
要素の挿入、削除を頻繁に行うようなListが必要な場合にLinkedListを検討すると良さそう
HashSetとLinkedHashSetとTreeSet
- HashSetは順序を保証しない
- 要素の追加、削除、検索は平均して計算量O(1)
- LinkedHashSetは内部的にハッシュテーブルとリンクリストを組み合わせて使用する
- 要素の挿入順序を保証する
- 要素の追加、削除、検索は平均して計算量O(1)
- TreeSetは自然順序もしくはコンストラクタで指定されたコンパレータによる順序に従ってソートされる
- 要素の追加、削除、検索は計算量O(log n)
- ソートされた順序が必要な場合に使える
HashMapとLinkedHashMapとTreeMap
Setとほぼ同じ
クラスとインターフェース
基本
package org.example;
public class ClassDemo {
public static class User {
// プロパティ
private String name;
private int age;
// コンストラクタ
public User(String name, int age) {
this.name = name;
this.age = age;
}
// getter / setter
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String hello() {
return "Hello, " + this.name;
}
}
public static void demo() {
var user = new User("Tanaka", 20);
System.out.println(user);
System.out.println(user.hello());
}
}
抽象クラス
- 抽象化したいフィールドを宣言できる
- 抽象化したい関数を定義できる
- abstract修飾子をつけた関数を宣言することで継承先に関数の実装を強制できる
package org.example;
public abstract class AbstractUser {
private String name;
private int age;
protected AbstractUser(String name, int age) {
this.name = name;
this.age = age;
}
public String hello() {
return "Hello, " + this.name;
}
public abstract String greet();
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
インターフェース
- インターフェースは振る舞い
- abstract classとの違いはabstract classはクラスなので多重継承できないのとフィールドや関数を定義できる
- インターフェースもデフォルト関数定義できるようになったので関数の実装を定義できるが、これはJavaの機能拡張の過程でしょうがなく入れたみたいなことを聞いたことがあるので積極的に使う機能ではないのかもしれない
- と思ったけどネット調べた感じだとそのようなことは特に言われてない
- 安易に使うべきではないが使うこと自体は別に悪くはないのかも
- インターフェースはあくまで振る舞いで実装を書くべきでない
- フィールドは持つことができないが定数は持つことができる
- しかし、定数のみを持つ定数インターフェースはアンチパターンなのでやるべきでない
- インターフェースのデフォルト実装について
https://qiita.com/yonetty/items/d6c1375c9a4a523be3c5 - ただ単に共通した実装が欲しくてmixin的な使い方をし、そのインターフェースが各所で使われた日にはデフォルトの実装の変更が全ての実装箇所で問題を起こす可能性がある
- 継承より委譲と言われる良い例
- 慣れないうちは使うべきでない
public interface Greetor {
void greet();
// 定数 public static finalは省略できる
String HELLO = "Hello";
// デフォルト実装
default void hello() {
System.out.println(HELLO + "!!");
greet();
}
}
定数とenum
- 定数は
finalをつけることで初期化してから値が変更されないことを保証する - 定数は一般的に
staticをつけることでクラス間でインスタンスを共有する - なので定数は一般的に
public static finalをつけることになる - 定数は全て大文字のスネークケースで書くことが多い
- 定数はアプリ内でよく使う、不変な値を宣言するときに使うと良い
- なんでもかんでも定数にするのはよくない
- 定数を管理する方法として以下がある
- 定数クラスを作って定数だけ置く(継承できないようにfinal & インスタンス作れないようにprivateコンストラクタで)
- 定数インターフェース(インターフェースの使い方ではない)
- enum
- 基本的にはenumが推奨
- enumはシングルトンであることを保証できるし、関数やフィールドも定義できて拡張性がある
package org.example;
import java.util.EnumSet;
import java.util.Optional;
import java.util.regex.Pattern;
public class ConstantsDemo {
// 定数
public static final String MESSAGE_1 = "Hello, World!!";
// Patternオブジェクトなんかは毎回インスタンス化せずに定数で宣言しておく方が
// 毎回インスタンスを生成せずに済むため効率が良いことが多い
public static final Pattern MOBILE_PHONE_PATTERN = Pattern.compile("^\\d{3}-\\d{4}-\\d{4}$");
// enum
enum StatusCode {
OK(200, "Success"),
NOT_FOUND(404, "Not Found")
;
// フィールド
private final int code;
private final String message;
// コンストラクタ
StatusCode(int code, String message) {
this.code = code;
this.message = message;
}
// code -> enum
public static Optional<StatusCode> codeOf(int code) {
return EnumSet.allOf(StatusCode.class).stream().filter(sc -> sc.code == code).findFirst();
}
}
public static void demo() {
System.out.println(MESSAGE_1); // Hello, World!!
// MESSAGE_1 = ""; 定数なので値の上書きはできない、不変
System.out.println(StatusCode.OK);
System.out.println(StatusCode.NOT_FOUND);
StatusCode.codeOf(200).ifPresent(System.out::println);
StatusCode.codeOf(404).ifPresent(System.out::println);
StatusCode.codeOf(500).ifPresentOrElse(System.out::println, () -> {
throw new IllegalArgumentException("サポートしていないステータスコードです");
});
}
}
record
Java16から正式導入。レコードは不変オブジェクトを簡単に作成するためのものでいわゆるPOJOと呼ばれるようなオブジェクトの代わりに使うことができ、コンストラクタやゲッター、equals(), toString(), hashCode()などが自動生成される。
public record Example(String str, int num) {
}
var ex = new Example("example", 1);
レコードの要素はコンポーネントという。
Javaのrecordは関数型プログラミングの代数的データ型の考えを取り入れて作られている。代数的データ型には以下の2種類がある
- 直積型
- 直和型
直積型は型をandで繋ぐ掛け算のイメージ。具体的にいうとJavaのクラスやrecordは直積型。
直和型はユニオン型や列挙型(enum)なんかが当てはまり、これは型をorでつなぐ足し算のイメージ。RustのResult型やHaskelのMaybe型なんかは直和型。
これらの何が嬉しいかというと複雑なデータ構造を型システムに落とし込み、安全なコードを実現するとともに代数的データ型を扱う時にパターンマッチングと相性が良いという面がある。
Javaのrecordはこのような関数型プログラミングにおける代数的データ型とパターンマッチングの概念を持ち込んだもの。
Javaのrecordやseald class とswitch式を使ったパターンマッチングの話は後でまとめて書く。
recordについてもう少し書くと
record User(long id, String name, int age) {
// staticイニシャライザ
static {
System.out.println("static");
}
// staticメソッド
public static void hello() {
System.out.println("Hello");
}
// staticフィールド
public static final String HELLO = "Hello";
// コンパクトコンストラクタ
public User {
System.out.println("id "+id+" age "+age);
}
// 普通に関数の定義
public User newUser() {
return new User(this.id, this.name, this.age);
}
}
- staticイニシャライザを定義することができるのでUser recordの呼び出しで処理を実行することができる。ただし、インスタンスイニシャライザは宣言することができない。
- staticメソッドも定義可能。普通に
User.hello()のように呼び出すことができる。 - staticフィールドも定義可能。普通に
User.HELLOのように参照可能。 - コンパクトコンストラクタという機能がある。これはコンストラクタの仮引数を使って処理が書ける。ただし、フィールドの初期化はできないのでインスタンス生成時に何か処理を挟みたい時などに使うのか?ちょっと用途があまりイメージできない
- 普通に関数の定義も可能。
var user = new User(1, "name", 20); user.newuser()のようにインスタンスから関数呼び出しが可能。
匿名クラス、 関数型インターフェース、ラムダ式
匿名クラス
public class StreamDemo {
private interface Reader {
void read();
}
public static void demo() {
// 匿名クラス
Reader r = new Reader() {
@Override
public void read() {
// 何か読み出し処理
System.out.println("何か読み出しの処理をしました");
}
};
r.read();
}
}
- インターフェースを実装した具象クラスを用意せずにインスタンスを生成できる。
- 上記の例ではReaderインターフェースを実装したクラスを宣言せずにインスタンス化している。
// 実際は以下のように特定のインターフェースを引数に取る関数
// を呼び出す場合に使うことが多いでしょう
useReaderFunc(new Reader() {
@Override
public void read() {
// 何か読み出し処理
System.out.println("何か読み出しの処理をしました");
}
});
- 実際は上記の例のようにインターフェースを引数に取る関数の呼び出しで使うことが多い
- インターフェースの実装クラスのインスタンスが必要ないケースではインターフェースを実装したクラスを用意してインスタンス化するのは少し面倒
- そこで匿名クラスが使える
関数型インターフェース
- メソッドを一つだけ持つインターフェースは関数型インターフェースという。
- 関数型インターフェースは
@FunctionalInterfaceをつけて明示的に宣言することもできる - アノテーションはつけなくても問題ないが、つけたほうが関数型インターフェースであることが明確になるのであったほうがいい。コンパイラでのチェックも入るよう
- Javaですでに用意されている関数型インターフェスには以下のようなものがある
public static void demo() {
// 匿名クラス
Reader r = new Reader() {
@Override
public void read() {
// 何か読み出し処理
System.out.println("何か読み出しの処理をしました");
}
};
r.read();
// 実際は以下のように特定のインターフェースを引数に取る関数
// を呼び出す場合に使うことが多いでしょう
useReaderFunc(new Reader() {
@Override
public void read() {
// 何か読み出し処理
System.out.println("何か読み出しの処理をしました");
}
});
// Runnable run: () -> void
// 引数も戻り値もなし
new Runnable() {
@Override
public void run() {
}
}.run();
// Predicate<T> test: T -> boolean
// 引数を一つ取りbooleanを返す関数
new Predicate<String>() {
@Override
public boolean test(String s) {
return false;
}
}.test("test");
// Consumer<T> accept: T -> void
// 引数を一つ取り戻り値はなしの関数
new Consumer<String>() {
@Override
public void accept(String s) {
}
}.accept("test");
// Function<T, R> apply: T -> R
// 引数を一つ受け取り結果を返す関数
new Function<String, String>() {
@Override
public String apply(String s) {
return "";
}
}.apply("test");
// Supplier<T> get: () -> T
new Supplier<String>() {
@Override
public String get() {
return "";
}
}.get();
// UnaryOperator<T> apply: T -> T
// 引数を一つ取り同じ型の値を返す関数
new UnaryOperator<String>() {
@Override
public String apply(String s) {
return "";
}
}.apply("test");
// BinaryOperator<T, T> apply: T, T -> T
// 同じ型の引数を二つ受け取り、同じ型の値を返す関数
new BinaryOperator<String>() {
@Override
public String apply(String s, String s2) {
return "";
}
}.apply("test", "test");
//BiFunction<T, R, U> apply: T, R -> U
// 二つの引数を受け取り、結果を1つ返す関数
new BiFunction<String, Integer, Boolean>() {
@Override
public Boolean apply(String s, Integer integer) {
return null;
}
}.apply("test", 1);
// BiConsumer<T, R> accept: T, R -> void
// 引数を二つ受け取り、値は返さない関数
new BiConsumer<String, Integer>() {
@Override
public void accept(String s, Integer integer) {
}
}.accept("test", 1);
// BiPredicate<T, R> test: T, R -> boolean
// 引数を2つ受け取り、booleanを返す関数
new BiPredicate<String, Integer>() {
@Override
public boolean test(String s, Integer integer) {
return false;
}
}.test("test", 1);
}
ラムダ式
匿名クラスはラムダ式で書き直すことができる。上記の例で言うと以下のような感じ。
new Predicate<String>() {
@Override
public boolean test(String s) {
return false;
}
}.test("test");
((Predicate<String>) s -> false).test("test");
- 少しわかりづらいかも
- とりあえず、関数型インターフェースは関数が1つなのでラムダ式で書くと実装すべき関数名などを省略して書けるので上記のように簡潔に書ける
- 関数型インターフェースの何が嬉しいかというと匿名クラスでも述べたが関数型インターフェースを引数に取る関数が簡潔に書けるということ
- 前述したReaderインターフェースを引数に取る関数の例で言うと以下のような感じ
useReaderFunc(new Reader() {
@Override
public void read() {
// 何か読み出し処理
System.out.println("何か読み出しの処理をしました");
}
});
// ラムダ式
useReaderFunc(() -> System.out.println("ラムダ式で実装しました"));
- 非常に簡潔に書ける
- ラムダ式は匿名クラスを簡潔に書けるようにする記法と覚えておけば良い
- このように簡潔に匿名クラスを書けるラムダ式が導入されたので次に説明するストリームAPIが非常に強力となり、Javaの開発体験を大きく変えた、はず
- ラムダ式を書くにはいくつかルールを覚える必要がある
- ただIntelliJのようなIDEを使っていればIDEが最適化してくれるので書いているうちに覚えるのでそこまで必死に覚える必要はないかもしれない
- 以下はComparatorの例
// sorted()は関数型インターフェースであるComparatorを引数にとるため以下のようにラムダ式で書ける
// Comparatorはcompare: T, T -> int という抽象メソッドのみを持つ関数型インターフェース
// compareが返す整数値によってListなどの並び替えをする
var l = Stream.of(2, 3).sorted((Integer s1, Integer s2) -> {
return s2 - s1;
});
- ラムダ式の仮引数は型推論が効くので省略ができる
var l = Stream.of(2, 3).sorted((s1, s2) -> {
return s2 - s1;
});
- 処理が1行で済む場合は
{}とreturnは省略できる
var l = Stream.of(2, 3).sorted((s1, s2) -> s2 - s1);
ラムダ式の仮引数が1つの場合
l = Stream.of(2, 2, 3).filter((Integer num) -> num > 2);
- ラムダ式の仮引数が1つの場合
()が省略できる
// 型も型推論が効くので省略できる
l = Stream.of(2, 2, 3).filter(num -> num > 2);
ラムダ式の仮引数がないとき
Optional.empty().orElseThrow(() -> new RuntimeException("値が存在しません"));
- OptionalのorElseThrowは引数にSuplierを取る
- ラムダ式の仮引数がない場合は
()と書ける。 - かっこの省略はできない
メソッド参照
メソッド参照はラムダ式の簡潔な書き方として使われ、ラムダ式同様関数型インターフェースをターゲットにすることができる。メソッド参照には4つの種類がある
- 静的メソッド参照
- インスタンスメソッド参照
- 任意のオブジェクトのインスタンスメソッド参照
- コンストラクタ参照
簡単な例でいうと以下のような感じで単純な関数呼び出しを行うラムダ式であればメソッド参照に書き直せる。これもIDEを使っていればサジェストしてくれるのであまり気にしなくてもいい気がする。
Function<String, Integer> f = Integer::parseInt;
f = str -> Integer.parseInt(str);
静的メソッド参照
上記例であるInteger.parseInt()のような静的メソッドを使ったメソッド参照。
インスタンスメソッド参照
インスタンスでも同じようにメソッド参照が使える。
String str = "Hello";
Supplier<Integer> lengthSupplier = str::length;
任意のオブジェクトのインスタンスメソッド参照
Function<String, String> toUpperCase = String::toUpperCase;
toUpperCase.apply("aaa");
// これと同義
toUpperCase = s -> s.toUpperCase();
引数に渡したインスタンスのインスタンスメソッドを呼ぶだけのパターンのメソッド参照。これは知らなかった。
コンストラクタ参照
コンストラクタ呼び出しもメソッド参照できる。何の意味もない処理だが以下のような感じで使える。
class MyClass {
private final String id;
MyClass(String id) {
this.id = id;
}
public String getId() {
return this.id;
}
}
Stream.of(1, 2, 3)
.map(String::valueOf)
.map(MyClass::new)
.forEach(mc -> System.out.println(mc.getId()));
Stream API
すでに何度か出てきたがコレクションや配列に対する一連の操作を行うための強力な機能がStreamです。Stream APIは関数型プログラミングの考え方がJavaに取り入れられてできたものでmapやfilter, reduceなどの関数名は関数型プログラミングでよく使われるもの。他の言語でもこういった関数型プログラミングのいいところを取り入れてることが多くJavaScriptやKotlinなんかでも標準で用意されている。
Stream APIの特性
- 遅延評価
- Streamの中間操作でmapとかfilterをメソッドチェーンで繋いでいるとコレクションなどのデータを毎回ループで処理しているように見えるが実際は最後の終端操作まで実行されない。
- そのため効率的にデータを処理することができる
- 可読性
- 通常のfor文は手続き的に処理を書いていくことになるのでコードがStream APIを使うとメソッドチェーンで簡潔に書ける
- 並列処理
- Javaで並列処理や並行処理を書こうとするとExecutorServiceなどを使って新たにスレッドを作ることになるが、Stream APIの
parallelStream()を使うと簡単に並列処理が書ける
- Javaで並列処理や並行処理を書こうとするとExecutorServiceなどを使って新たにスレッドを作ることになるが、Stream APIの
for文との比較
- for文の方がオーバーヘッドは少ない
- Streamの処理はラムダ式とメソッドチェーンを多用する分オーバヘッドはfor文と比べて大きくはなる
- Goがmapなどをなかなか採用しなかったのもfor文のほうが速いからという理由があるらしい
- とはいえ、Streamを使うことで簡潔にデータ処理をかけること、関数型プログラミングライクなメソッドチェーンで連鎖的に処理を書けること、簡単に並列処理をかけることなどStreamを使うメリットのほうがはるかに大きいように感じる
- ただし、Streamでメソッドチェーンやラムダ式を多用しすぎて逆に可読性が落ちるというのはあるあるなのでそこには注意したい
- そういった場面では素直にfor文を使ったほうがいい
- Javaは他の言語と比べて簡潔に書けないことが多いのでStream APIは強力な武器であることは間違いない
- よほどのことがない限りStream APIを使うことでのオーバーヘッドは気にしなくてもいいようには感じる
Streamの書き方
Streamは主に以下の3つの流れで処理を書く。
- Streamの生成
- 中間操作
- 終端操作
Streamの生成
Streamはさまざまな方法で生成できる。
Stream.of("aaa", "bbb", "ccc");
Stream.empty();
Stream.builder()
.add(1)
.add(2)
.build();
// 無限シーケンス
Stream.iterate(0, num -> num + 1);
var r = new Random();
Stream.generate(r::nextInt);
IntStream.range(0, 100);
-
Stream.of()で生成する -
Stream.builder()を使って生成する- これはビルダーパターンでStreamを生成できる
- 動的にStreamを生成したいときなどに使える
-
Stream.empty()- 空のStreamが必要なときに
- Streamを返す関数の戻り値や初期値などに使える
- 無限シーケンス
-
Stream.iterate()、Stream.generate()を使うことで生成できる - ただこれらは無限シーケンスになるので
limit()などを使わないと無限ループになるので注意
-
中間操作
- 中間操作では生成したStreamに対してフィルタリングや加工といった処理をして終端操作に渡す役割を担う
- 主に
filter()やmap()をメインに使うことになるが他にも中間操作はある - 中間操作は省略可能でStreamの生成からそのまま終端操作に行ってもいい
IntStream.rangeClosed(0, 10)
.filter(n -> n % 2 == 0)
.forEach(System.out::println);
IntStream.rangeClosed(0, 10)
.map(n -> n * 2)
.forEach(System.out::println);
終端操作
- 中間操作を経て渡ってきたStreamを集計したり、中間操作を実行して結果を返したりする
- 今まで出てきた
forEach()の他に集計するsum()やListに変換するtoList()などがある
IntStream.rangeClosed(0, 10)
.sum();
Stream.of(1, 2, 3).toList();
- 省略はできない
インナークラス
Javaのクラスにはクラス内に定義できるインナークラスがある。インナークラスは大きく以下の4種類に分類できる。
- メンバークラス
- ローカルクラス
- 匿名クラス
- 静的クラス
メンバークラス
クラスのメンバーとしてクラスを宣言
public class OuterClass {
public class MemberClass {
}
}
// メンバークラス
var outer = new OuterClass();
var member = outer.new MemberClass();
- メンバークラスは外側のクラスの全てのフィールドなどにアクセス可能
- メンバークラスをインスタンス化する場合は外側のクラスをインスタンス化する必要がある
ローカルクラス
関数の中で宣言されたクラス
public class OuterClass {
public void hello() {
final var text = "Hello!!";
// スコープは関数内になるため
// 可視性の修飾子はつけれない
class LocalClass {
public void print() {
System.out.println(text);
}
}
new LocalClass().print();
}
}
- ローカルクラスは関数内でのみ有効なため可視性の修飾子はつけれない(意味がない)
- ローカルクラスからは関数内で宣言されている変数などにアクセスは可能
- しかし、全てfinalもしくは実質的にfinalである必要がある
静的クラス
public class OuterClass {
public class MemberClass {
}
static public class StaticClass {
{
// 外側の非staticなフィールドにはアクセスできない
// のでこれはコンパイルエラーになる
var m = new MemberClass();
}
}
}
// 静的クラス
var s= new OuterClass.StaticClass();
- staicでメンバークラスを宣言する
- staicクラスからは外側のクラスの非staticなフィールドなどにアクセスできない
- インスタンス化は外側のクラスをインスタンス化しなくてもsaticにコンストラクタを呼べる
使い分け
- 外側のクラスに強く依存する場合はメンバークラス
- その関数内でのみ使われるような場合にはローカルクラス
- 外側のクラスを補助し外側のクラスに依存しないクラスが欲しい場合は静的クラス
Sealed Class, Sealed Interface
ちょっと先に
これも
でまあ簡単に言うとこう
Sealed Classは継承先を限定することで今までよりスーパークラスの扱いをより限定することができる。アクセス修飾子よりもより宣言的で限定できるというものです。
Sealed Classの何が嬉しいかというとSealed Classとswitch式を組み合わせたパターンマッチングを用いて今までより簡潔にenumのような値を扱えることだと思います。
より拡張性の高いenumみたいなイメージ。で、それをやろうとするとSealed interfaceとrecordを使う感じになりそう。(recoedは通常のクラスを継承できないのでInterfaceを使いたくなるはず)。以下はKotlinの例をJavaのSealed Interfaceとrecoedで書いてみた例。
public sealed interface Color {
record Red() implements Color {}
record Blue() implements Color {}
record Green() implements Color {}
record Rgb(int red, int blue, int green) implements Color {
@Override
public String toString() {
return "(%d,%d,%d)".formatted(this.red, this.blue, this.green);
}
}
}
最初sealed classで書いていたがそうなるとrecordが使えないのでいろいろ冗長になってしまう。一応載せておくとこんな感じ
public sealed class Color {
static final public class Red extends Color {}
static final public class Blue extends Color {}
static final public class Green extends Color {}
static final public class Rgb extends Color {
public final int red;
public final int blue;
public final int green;
public Rgb(int red, int blue, int green) {
this.red = red;
this.blue = blue;
this.green = green;
}
@Override
public String toString() {
return "(%d,%d,%d)".formatted(this.red, this.blue, this.green);
}
}
}
Interfaceにすると以下のような感じでかなり記述を減らせるのでこのような使い方をしたい場合はSealed Interface + recordがかなりいい感じになる
- sealed classを継承したクラスは
final、sealed、non-sealedの修飾子をつける必要がある。recoedはデフォルトfinal扱いなので記述不要 -
Color.Redのように呼び出すにはstaticをつける必要がある。interfaceはデフォルトでstatic扱い - Interface内のメンバークラスはデフォルトでpublicなので記述不要
- Rgbクラスをrecordにするとフィールド宣言やコンストラクタの記述も減らせる
ちなみにSealed Classは継承先をpermitsで宣言的に記述する必要があるが継承先をインナークラスに限定する場合は記述不要
// この場合permitsは省略可能
public sealed interface Color permits Color.Red, Color.Blue, Color.Green, Color.Rgb {
record Red() implements Color {}
record Blue() implements Color {}
record Green() implements Color {}
record Rgb(int red, int blue, int green) implements Color {
@Override
public String toString() {
return "(%d,%d,%d)".formatted(this.red, this.blue, this.green);
}
}
}
で、これをどう使うかというと以下のような感じで使える
var color = getColor("rgb", /* red = */255, /* green = */255, /* blue = */255);
switch(color) {
case Color.Red ignored -> System.out.println("red");
case Color.Blue ignored -> System.out.println("blue");
case Color.Green ignored -> System.out.println("green");
case Color.Rgb rgb -> System.out.println("rgb: "+rgb);
// default -> throw new IllegalStateException("Unexpected value: " + color);
}
}
private static Color getColor(String str, Integer red, Integer green, Integer blue) {
return switch (str) {
case "Red", "red" -> new Color.Red();
case "Green", "green" -> new Color.Green();
case "Blue", "blue" -> new Color.Blue();
case "RGB", "rgb" -> new Color.Rgb(
red != null ? red : 0,
green != null ? green : 0,
blue != null ? blue : 0
);
case null, default -> throw new IllegalStateException("Unexpected value: " + str);
};
}
一つ目のswitch式でdefaultを省略しているが、これはSealed Interfaceを使っているとコンパイラが網羅できているかどうかを知ることができるので仮にcaseのパターンが増えたときに追加漏れが起きるとコンパイルエラーになるので追加漏れに気づくことができる。これをdefaultを書いてしまうとコンパイルエラーが出ず気づくことができないのでこのようなパターンマッチングを使う場合、defaultは省略したほうがいい。
enumとの比較
このような場合、enumでもおなじようなコードを書けるがRgbクラスのようなフィールドを持たせたいときに対応できない。enumのように一連の状態などを列挙するときにより拡張性が高く、柔軟な記述ができるのがSealed Interfaceの嬉しいところで拡張enumみたいに言われる理由。
狙って使うのは難しいかもしれないがenumが欲しくなった時にSealed Interfaceで書けないかということを覚えておくといいかもしれない。
例外
まずJavaの例外クラスの体系を頭に入れておいた方がいい
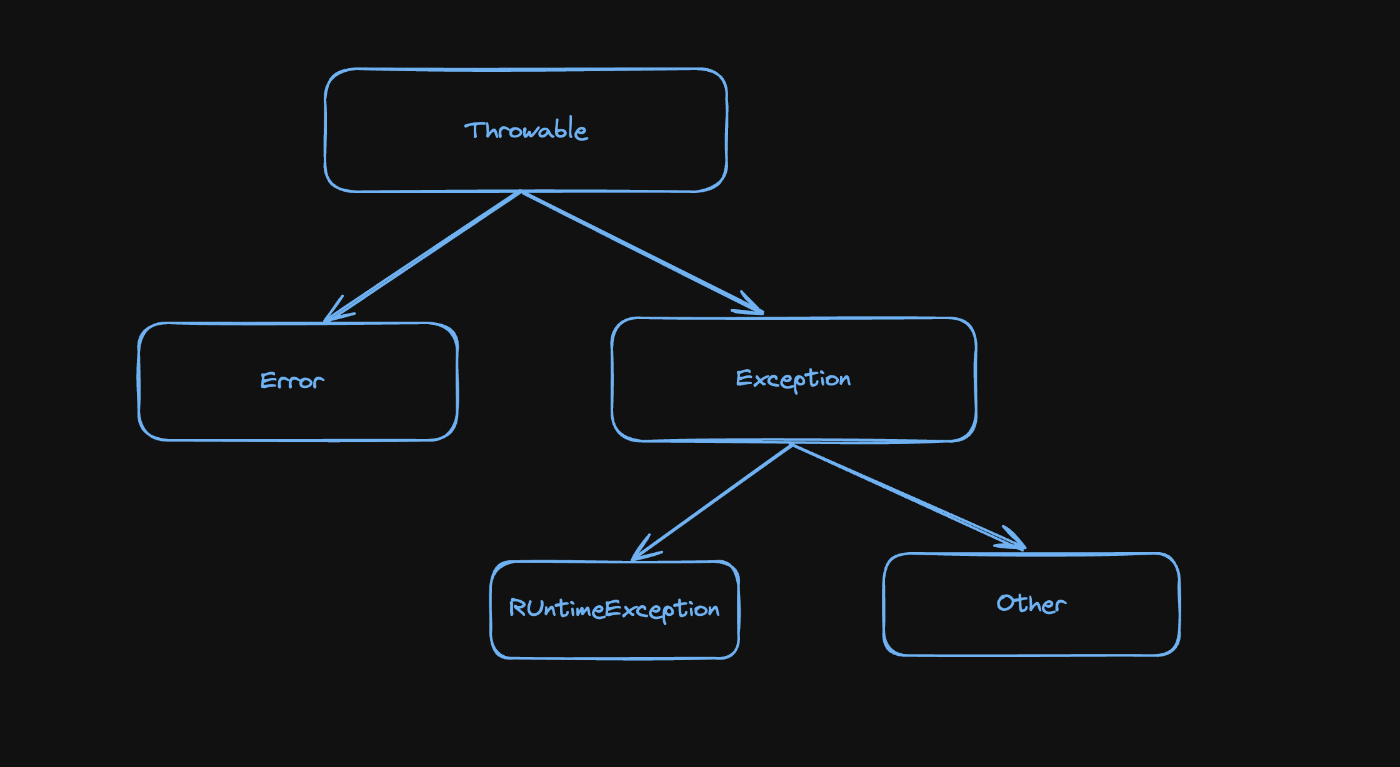
Throwable
全てのエラーの1番トップレベルの親クラスにあたる。Throwableはシステムが修復不可能なErrorもエラーハンドリングが必要な検査例外も全てcatchできてしまうので基本的にはThrowableでcatchすべきでない。
Error
システムが修復不可能なエラーの親クラスになる。具体的にはOutOfMemoryErrorなどがあるがこれも修復不可能なエラーのため基本的にはcatchすべきでない。
Exception
後述する実行時例外と呼ばれるRuntimeExceptionと検査例外と呼ばれるエラーの親クラスにあたる。全てのエラーを補足したい場合はこのExceptionクラスで補足するのがいいかもしれないが基本的には実行時例外も検査例外も全てを補足することになってしまうのでより細かい粒度のエラーで補足したほうが望ましい。
RuntimeException
実行時例外と呼ばれるエラーの親クラスにあたる。具体的にはIndexOutOfBoundsExceptionなどがある。実行時例外も基本的には想定外のエラーになることが多いので可能な限り実行時例外を補足するような設計は避けることが望ましい。実行時例外はtry-catchすることを強制されない。
Checked Exception
Exceptionクラスを継承したRuntimeException以外の全てのエラーで検査例外と呼ばれるエラーになる。これはコンパイラからtry-catchで補足することを強制されるためtry-catchしてエラーハンドリングする必要がある。
try-catch
RuntimeExceptionとそのサブクラスはtry-catchで補足する必要はない。RuntimeException以外のExceptionを継承した例外はtry-catchで補足するか呼び出し元に伝搬する必要がある。
public class ErrorDemo {
private static void throwRuntimeException() {
throw new RuntimeException("runtime exception");
}
private static void throwCheckedException() throws Exception {
throw new Exception("checked exception");
}
public static void demo() {
// RuntimeExceptionはtry-catchは不要
// throwRuntimeException();
// 検査例外はtry-catchするか呼び出し元に例外を伝搬する必要がある
try {
throwCheckedException();
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
finally
try-catchに追加でfinallyブロックを書くとtry-catchで囲った処理が成功しても失敗しても必ず実行したいような処理を書くことができる。これはリソースの解放なんかが用途として上がるが、リソースの解放などに関しては後述するtry-with-resourcesで記述することができるのでリソースの解放に関してはそっちのがいい。
try {
throwCheckedException();
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
System.out.println("Complete!!");
}
カスタム例外
RuntimeExceptionもしくはExceptionを継承することで独自のカスタム例外を定義することができる。
record User(long id){}
static class NotSpecifyIdException extends RuntimeException {
public NotSpecifyIdException() {
super();
}
public NotSpecifyIdException(String message) {
super(message);
}
public NotSpecifyIdException(String message, Throwable cause) {
super(message, cause);
}
}
static class NotFoundUserException extends Exception {
private final long id;
public NotFoundUserException(long id) {
super();
this.id = id;
}
public NotFoundUserException(long id, String message) {
super(message);
this.id = id;
}
public NotFoundUserException(long id, String message, Throwable cause) {
super(message, cause);
this.id = id;
}
@Override
public String getMessage() {
return super.getMessage() + " id: " + this.id;
}
}
private static User findUser(Long id) throws NotFoundUserException {
if(id == null) {
throw new NotSpecifyIdException("IDの指定がなければ実行時例外をスローする");
} else if(id != 1) {
throw new NotFoundUserException(id, "ユーザーが見つかりませんでした");
} else {
return new User(id);
}
}
テスト
Javaのテストはtest/java配下に配置する。JavaのテスティングライブラリはJUnitを採用している企業が多い。Groovyで書くSpockというライブラリもあるがJavaで書くならほぼほぼJUnitになるはず。
執筆時点でJUnitはJUnit5となっておりJUnit4から大きく変わっていて、パッケージもorg.junit.jupiterという風に変わっている。
テスト結果のアサーションにはhamcrestというマッチャーが広く使われてきており、JUnit4には一部hamcrestが組み込まれていたこともあり、採用率は1番高そう。
しかし、JUnit5からはhamcrestは組み込まれておらず、別途マッチャーライブラリを依存関係に追加する必要があり、メソッドチェーンでアサーションできるAssertJも最近では人気がありそう。
JUni5にはorg.junit.jupiter.api.Assertionsパッケージに組み込みのアサーションが用意されているので依存関係を追加しなくてもアサーションはできるが昔からJUnitでテストを書いている人にはhamcrestによるアサーションが馴染みが深いだろうし、AssertJのメソッドチェーンによる書き心地は人気が高く、最近での採用例が多そうなのでhamcrestかAssertJのどちらかを使うのが良さそう。
Google製のTruthというAssertJに似たアサーションもあり、こちらも気になるところではある。
AssertJ
以下の依存関係を追加。
testImplementation("org.assertj:assertj-core:3.26.3")
AssertJは以下のようなstatic import をすると使いやすい。
import static org.assertj.core.api.Assertions.*;
assertThat(1 + 1).isEqualTo(2);
テストの書き方
@Testをテスト関数につけて実行する。テストの表示は@Displaynameを使って変更することもできる。
package org.example;
public class Caluculator {
public enum Operator {
ADD, SUBTRACT, MULTIPLE, DIVIDE;
}
private Operator operator;
public Caluculator(Operator operator) {
this.operator = operator;
}
public double calculate(int x, int y) {
return switch (this.operator) {
case ADD -> x + y;
case SUBTRACT -> x - y;
case MULTIPLE -> x * y;
case DIVIDE -> (double) x / y;
};
}
}
package org.example;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import static org.assertj.core.api.Assertions.*;
public class CalculatorTest {
@Test
@DisplayName("1 + 1 = 2")
void addTest() {
var sut = new Caluculator(Caluculator.Operator.ADD);
var act = sut.calculate(1, 1);
assertThat(act).isEqualTo(2);
}
}
ライフサイクル
package org.example;
import org.junit.jupiter.api.*;
import static org.assertj.core.api.Assertions.*;
public class CalculatorTest {
@BeforeAll
static void init() {
System.out.println("BeforeAll");
}
@BeforeEach
void setup() {
System.out.println("BeforeEach");
}
@AfterAll
static void finish() {
System.out.println("AfterAll");
}
@AfterEach
void teardown() {
System.out.println("AfterEach");
}
@Test
@DisplayName("1 + 1 = 2")
void addTest() {
var sut = new Caluculator(Caluculator.Operator.ADD);
var act = sut.calculate(1, 1);
assertThat(act).isEqualTo(2).satisfies(value -> System.out.println("act: " + value + " expect: " + 2));
}
@Test
@DisplayName("3 - 1 = 2")
void subtractTest() {
var sut = new Caluculator(Caluculator.Operator.SUBTRACT);
var act = sut.calculate(3, 1);
assertThat(act).isEqualTo(2).satisfies(value -> System.out.println("act: " + value + "expect: " + 2));
}
}
-
@BeforeAllテストクラスのテストを実行する1番最初に一度だけ実行。関数はstaticで宣言する必要あり。 -
@AfterAllテストクラスのテストの実行完了時に1度だけ実行。関数はstaticで宣言する必要あり。 -
@BeforeEachテスト関数の実行前に実行。 -
@AfterEachテスト関数の実行後に実行。
実行結果は以下。
BeforeAll
BeforeEach
act: 2.0 expect: 2
AfterEach
BeforeEach
act: 2.0expect: 2
AfterEach
AfterAll
ライフサイクルは便利な反面、あまり処理を寄せすぎると各テストケースが密になり負債になったり、テストケースを見てもどういうテストをしているかわかりづらいテストになってしまうので多用は注意が必要。極力使用しないようにして、必要になったときに使うくらいがいい。
アサーションガイド
基本
assertThat("AssertJ")
.isNotNull()
.startsWith("Assert")
.endsWith("J");
テスト結果説明
asを使う
record User(String name, int age){}
var user = new User("user", 30);
// テストの説明追記
// [check user's age]
// expected: 20
// but was: 30
assertThat(user.age).as("check %s's age", user.name).isEqualTo(20);
文字列
var str = "test";
assertThat(str).isNotNull();
// 空文字ではない
assertThat(str).isNotEmpty();
// 空文字もしくは空白のみではない
assertThat(str).isNotBlank();
assertThat(str).startsWith("te");
assertThat(str).endsWith("st");
assertThat(str).isEqualTo("test");
assertThat(str).contains("es");
assertThat(str).matches(Pattern.compile("^[a-z]{4}$"));
数値
var num = 2;
assertThat(num).isLessThan(5);
assertThat(num).isGreaterThan(1);
assertThat(num).isPositive();
Collection
var list = List.of("a", "b", "c");
assertThat(list).contains("b").doesNotContain("d");
assertThat(list).allMatch(elm -> elm.length() == 1);
assertThat(list).anyMatch(elm -> Objects.equals(elm, "b"));
var map = Map.of("key1", 1, "key2", 2, "key3", 3);
assertThat(map).contains(Map.entry("key2", 2));
assertThat(map).isNotEmpty();
Exception
class SomethingThrow {
static void throwEx() throws OperationNotSupportedException {
throw new OperationNotSupportedException("この関数は実行できません");
}
}
assertThatThrownBy(SomethingThrow::throwEx)
.hasMessage("この関数は実行できません")
.isInstanceOf(OperationNotSupportedException.class);
パラメーターテスト
パラメーター化テスト、Table Driven Test(テーブル駆動テスト)、 データ駆動テストなど呼び方はいろいろあるがテストロジックと入力、期待する出力データを分離することでさまざまなパターンを網羅的にテストする手法。
Dynamic Test
JUnit5には Parameterized Testsというものがあり、パラメーター化テストといえばこれを思い浮かべる人が多そうだが、JUnit5には動的にテストケースを作成するための機能が用意されており、これを使うとデータパターンをループで回して動的にテストケースを作成することができるためパラメーター化テストを作成することができる。
@TestFactory
Stream<DynamicTest> calculatorTest() {
record Case(String name, int x, int y, Caluculator.Operator operator, double expected){}
List<Case> tests = List.of(
new Case("1 + 2 = 3", 1, 2, Caluculator.Operator.ADD, 3.0),
new Case("5 - 3 = 2", 5, 3, Caluculator.Operator.SUBTRACT, 2.0),
new Case("5 * 2 = 10", 5, 2, Caluculator.Operator.MULTIPLE, 10.0),
new Case("6 / 3 = 2", 6, 3, Caluculator.Operator.DIVIDE, 2.0)
);
return tests.stream().map(t -> DynamicTest.dynamicTest(t.name, () -> {
var sut = new Caluculator(t.operator);
assertThat(sut.calculate(t.x, t.y)).isEqualTo(t.expected);
}));
}
-
@TestFactoryをつける - 戻り値はList<DynamicTest>またはStream<DynamicTest>
Parameterized Test
@ParameterrizedTestをつけることでパラメーター化テストを書くことができる。@ValueSourceをつけると以下のように引数にパラメーターを取ることができる。
@ParameterizedTest
@ValueSource(ints = { 2, 4, 6, 8 })
void evenTest(int num) {
assertThat(num % 2).isZero();
}
パラメーターの型は以下のものがとれる。
- short
- byte
- int
- long
- float
- double
- char
- boolean
- java.lang.String
- java.lang.Class
パラメーターにはnullや空文字といったコーナーケースを含めるとテストの信頼度があがる
@ParameterizedTest
@NullAndEmptySource
@ValueSource(strings = { " ", " ", "\t", "\n" })
void nullEmptyAndBlankStrings(String text) {
assertThat(text == null || text.trim().isEmpty()).isTrue();
}
@EnumSourceを使うことで指定のEnumを網羅的に扱えます。
@ParameterizedTest
@EnumSource
void operatorTest(Caluculator.Operator op) {
assertThat(op).isNotNull();
}
@MethodSourceを使うことでテストケースの外部からパラメーターを注入することも可能です。
@ParameterizedTest
@MethodSource("range")
void testWithRangeMethodSource(int argument) {
assertThat(argument).isNotEqualTo(9);
}
static IntStream range() {
return IntStream.range(0, 20).skip(10);
}
この場合、Streamを戻り値にしたstatic関数を定義し、関数名を@MethodSourceに指定する。関数名を省略した場合はテストケースと同じ関数名を探しに行く。
またorg.junit.jupiter.params.provider.Argumentsを使うとDynamic TestでやったようなTable Driven Testみたいな書き方もできる。
@ParameterizedTest
@MethodSource("CalculatorProvider")
void calculatorMethodSourceTest(int x, int y, Caluculator.Operator operator, double expected) {
var sut = new Caluculator(operator);
assertThat(sut.calculate(x, y)).isEqualTo(expected);
}
static Stream<Arguments> CalculatorProvider() {
return Stream.of(
Arguments.arguments(1, 2, Caluculator.Operator.ADD, 3.0),
Arguments.arguments(5, 3, Caluculator.Operator.SUBTRACT, 2.0),
Arguments.arguments(5, 2, Caluculator.Operator.MULTIPLE, 10.0),
Arguments.arguments(6, 3, Caluculator.Operator.DIVIDE, 2.0)
);
}
@FieldSourceを使うとフィールドとして宣言されているListや配列などをパラメーターとして使うこともできる。
@ParameterizedTest
@FieldSource
void oddPattern(Integer num) {
assertThat(num % 2).isEqualTo(1);
}
static final List<Integer> oddPattern = List.of(
1, 3, 5, 7, 9
);
変数名を指定するか指定しない場合は同じ変数名のフィールドを使用しようとする。
@CsvSourceを使うとCSV形式でパラメーターを指定できる。
@ParameterizedTest
@CsvSource({
"1, 1, 2",
"2, 3, 5",
"0, 1, 1",
"-2, 2, 0",
})
void addTest(int x, int y, double expected) {
var sut = new Caluculator(Caluculator.Operator.ADD);
assertThat(sut.calculate(x, y)).isEqualTo(expected);
}
Javaが15以上でテキストブロックをサポートしていれば以下のようにも書ける。
@ParameterizedTest
@CsvSource(textBlock = """
1, 1, 2
2, 3, 5
0, 1, 1
-2, 2, 0
""")
void addTest(int x, int y, double expected) {
var sut = new Caluculator(Caluculator.Operator.ADD);
assertThat(sut.calculate(x, y)).isEqualTo(expected);
}
ヘッダーも記述できる。
@ParameterizedTest
@CsvSource(useHeadersInDisplayName = true, textBlock = """
x, y, expected
1, 1, 2
2, 3, 5
0, 1, 1
-2, 2, 0
""")
void addTest(int x, int y, double expected) {
var sut = new Caluculator(Caluculator.Operator.ADD);
assertThat(sut.calculate(x, y)).isEqualTo(expected);
}
CSVファイルを直接指定することもできる。
@ParameterizedTest
@CsvFileSource(resources = "/add-test-parameters.csv", useHeadersInDisplayName = true)
void addTestWithCSVFile(int x, int y, double expected) {
var sut = new Caluculator(Caluculator.Operator.ADD);
assertThat(sut.calculate(x, y)).isEqualTo(expected);
}
@ArgumentSourceにArgumentsProviderを実装したクラスを指定することで以下のようにも書ける。
@ParameterizedTest
@ArgumentsSource(FruitArgumentsProvider.class)
void fruitTest(String fruit) {
assertThat(fruit).isNotEqualTo("orange");
}
public static class FruitArgumentsProvider implements ArgumentsProvider {
@Override
public Stream<? extends Arguments> provideArguments(ExtensionContext context) throws Exception {
return Stream.of("apple", "banana").map(Arguments::of);
}
}
まだ、書き切れてない機能も多くあるがここに書いてある機能だけでも基本的なテストを書く分には困らないはず。
いろいろ言い方があってなんて呼んでいいかわからないがGoで言うテーブル駆動テストをJavaで書くにはDynamic TestかParameterizdTestが使えそうだが、Goに近い雰囲気で書けるのでDynamic Testのが好み。テストケースの外部にパラメータを置くのがあんまり好みではないのもある。どちらを使っても同じようなテストは書けそう。
実践的内容
HTTP
実際の現場ではSpringのようなFWを使うことがほとんどだと思うが、以下のようにJavaの標準パッケージのcom.sun.net.httpserverを使うことでHTTPサーバを起動することができる。
package org.example;
import com.sun.net.httpserver.HttpExchange;
import com.sun.net.httpserver.HttpServer;
import java.io.IOException;
import java.net.InetSocketAddress;
public class Server {
public static void start() throws IOException {
var server = HttpServer.create(new InetSocketAddress(8080), 0);
// "/hello" へのリクエストを処理するハンドラーを設定
server.createContext("/hello", (HttpExchange exchange) -> {
// レスポンスの内容を設定
var response = "Hello, World!";
exchange.sendResponseHeaders(200, response.getBytes().length);
// レスポンスをクライアントに送信
try(var os = exchange.getResponseBody()) {
os.write(response.getBytes());
}
});
// デフォルトのスレッドプールを使ってサーバーを起動
server.setExecutor(null); // null はデフォルトの executor を使用することを意味する
server.start();
System.out.println("Server started on port 8080");
}
}
HTTPクライアントに関してはJavaは選択肢がいろいろある。
- 古くからあるJava標準のHttpURLConnectionが微妙
- Appach Commons HttpClient, Apache HttpComponentsが少し古い
- google-http-java-client これもそこそこメジャーぽいけど情報があんまりない
- OkHttp Androidでよく使われてそう。ドキュメントが見やすい
- HttpClient Java11で入った標準モジュール
今何か選ぶならOkHttpかHttpClientが良さそう。標準モジュールでできるなら外部ライブラリを入れないにこしたことはないのでHttpClientを使ってみる。
package org.example;
import java.io.IOException;
import java.net.Authenticator;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpClient.*;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.stream.IntStream;
import static java.net.HttpURLConnection.HTTP_OK;
public class HttpClientDemo {
public static void demo() {
try(var client = HttpClient.newBuilder()
.version(Version.HTTP_1_1)
.followRedirects(Redirect.NORMAL)
.connectTimeout(Duration.ofSeconds(20))
// .authenticator(Authenticator.getDefault())
.build()) {
var req = HttpRequest.newBuilder()
.uri(URI.create("https://example.com"))
.timeout(Duration.ofMinutes(2))
// .header("Content-Type", "application/json")
.build();
// 同期通信
HttpResponse<String> response = client.send(req, HttpResponse.BodyHandlers.ofString());
System.out.println(response.statusCode());
System.out.println(response.body());
// 非同期通信
var futures = IntStream.range(0, 3).mapToObj(i -> {
var req2 = HttpRequest.newBuilder()
.uri(URI.create("https://example.com"))
.header("Count", String.valueOf(i))
.timeout(Duration.ofMinutes(2))
.build();
return client.sendAsync(req2, HttpResponse.BodyHandlers.ofString());
}).toList();
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).get();
for (var future : futures) {
var res = future.get();
if (res.statusCode() == HTTP_OK) {
System.out.println("Success!!");
System.out.println("count: " + res.request().headers().firstValue("Count").orElse(""));
}
}
} catch (IOException | InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}
}
特徴としては以下のようなものがある。
- Builderパターンで構築できる
- 同期通信と非同期通信がある
- HTTP2やWebSocketなどにも対応
使い勝手としても悪くないためHttpClientで十分な気はする。ただ、非同期通信まわりがもしかしたらOkhttpの方が書きやすいなどがあるかもしれない。同期リクエストであればHttpClientで十分。
ファイル操作
java.ioパッケージが使われていたがより高機能なファイル操作ができるAPIとしてjava.nio.fileパッケージがJava7から使えるようになっている。
java.nio.file.Pathsやjava.nio.file.Filesクラスを使うことでファイルの作成や読み込み、書き込みなどは簡単に操作できる。
以下はsrc/main/resources配下に配置したファイルをクラスローダーから読みこむ例。
public class FileDemo {
public static void demo() throws IOException {
try(
var is = FileDemo.class.getClassLoader().getResourceAsStream("test.txt");
var isr = new InputStreamReader(Objects.requireNonNull(is));
var bsr = new BufferedReader(isr, 1024);
){
// var bytes = is.readAllBytes();
// System.out.println(new String(bytes));
var sb = new StringBuilder();
String line;
while((line = bsr.readLine()) != null) {
sb.append(line);
sb.append(System.lineSeparator());
}
System.out.println(sb);
}
}
}
IO処理ではStream系のクラスをよく使う。
大まかに
- InputStream
- OutputStream
- Reader
- Writer
に分類することができる。ファイルから生成するFileInputStreamやバッファを使って書き出すBufferedWriterといった実装クラスがある。
上記の例だとクラスローダーからファイルをinputStreamで読み出してバイト列に書き出して文字列に変換するかInputStreamReaderもしくはBufferdReaderでバッファを確保して文字列に読み出している。
try-with-resources
Java7で導入された安全にリソースを解放するための構文で主にファイルやDBのクローズ処理を自動で行う構文。
この構文が導入される前はfinallyブロックでclose()を呼び出していた。
構文は上記の例のようにtryブロックの中でリソースを扱う。AutoCloseableインターフェースを実装しているクラスであればtry-with-resources構文が使える。
基本的にクローズが必要なリソースを扱う場合はこの構文を使うようにする。
標準入出力
標準入力はSystem.in、標準出力はSystem.outを使う。標準入力でユーザーからの入力を待つみたいなのはScannerクラスを使い、nextLine()などを使うことで入力された値を変数にマッピングすることができる。
var scanner = new Scanner();
var input = scanner.nextLine();
以下は入出力でじゃんけんする簡単なプログラム
package org.example;
import java.util.*;
public class SystemInDemo {
private static final List<Integer> CHOICES = List.of(1, 2, 3);
public static void demo() {
try(var s = new Scanner(System.in)) {
System.out.println("じゃーんけーん");
System.out.println("1. 👊");
System.out.println("2. ✌️");
System.out.println("3. ✋");
int input;
while (true) {
try {
input = s.nextInt();
if (CHOICES.contains(input)) {
break;
}
}catch (InputMismatchException ignored) {
// 入力をクリア
s.nextLine();
}
System.out.println("1-3で選んでください");
System.out.println("じゃーんけーん");
}
System.out.println("ぽん!");
var rand = new Random();
var choice = CHOICES.get(rand.nextInt(3));
System.out.println("あなたの手: " + displayChoice(input));
System.out.println("わたしの手: " + displayChoice(choice));
switch (input) {
case 1 -> {
if(choice == 1) {
System.out.println("あいこです");
} else if(choice == 2) {
System.out.println("あなたの勝ちです");
} else {
System.out.println("あなたの負けです");
}
}
case 2 -> {
if(choice == 1) {
System.out.println("あなたの負けです");
} else if(choice == 2) {
System.out.println("あいこです");
} else {
System.out.println("あなたの勝ちです");
}
}
case 3 -> {
if(choice == 1) {
System.out.println("あなたの勝ちです");
} else if(choice == 2) {
System.out.println("あなたの負けです");
} else {
System.out.println("あいこです");
}
}
}
}
}
private static String displayChoice(int choice) {
return switch (choice) {
case 1 -> "👊";
case 2 -> "✌️";
case 3 -> "✋";
default -> throw new IllegalStateException("Unexpected value: " + choice);
};
}
}
DB操作
JavaはDBと対話するのにJDBCという低レベルのAPIを使う。実際の現場ではJDBCを抽象化したORMが使われることがほとんどでJDBCを直接使うことはほとんどないはず。
最もよく使われるORMにはHibernateというものがありHibernateを含む多くのORMはJPAという仕様に準拠している。JPAはあくまで仕様なのでそれに準拠した実装がORMみたいな感じ。
SpringではSpring Data JPAというものがあり、これはJPAをより抽象化したSpringの仕様であり、ORMとしてはHibernateが使われることが多いが別のORMを使うこともできる。
JavaのORMにはMybatisやJOOQなどHibernate以外にも多く存在する。
以下は全てのORMのベースとなるJDBCを直接使ったDB操作のコード例。
package org.example;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Optional;
public class UserRepository implements AutoCloseable{
public record User(int id, String name) {}
private final Connection conn;
private final PreparedStatement createUserQuery;
private final PreparedStatement findUserQuery;
public UserRepository(String url) throws SQLException {
this.conn = DriverManager.getConnection(url);
this.createTable();
this.createUserQuery = this.conn.prepareStatement("INSERT INTO users (id, name) VALUES(NULL, ?)");
this.findUserQuery = this.conn.prepareStatement("SELECT id, name FROM users WHERE id = ?");
}
private void createTable() throws SQLException {
try(var stmt = this.conn.createStatement()) {
stmt.execute("""
CREATE TABLE IF NOT EXISTS users(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name VARCHAR(50)
);
""");
}
}
public int createUser(String name) throws SQLException {
this.createUserQuery.setString(1, name);
return this.createUserQuery.executeUpdate();
}
public Optional<User> findById(int id) throws SQLException {
this.findUserQuery.setInt(1, id);
var rs = this.findUserQuery.executeQuery();
if(rs.next()) {
var idd = rs.getInt("id");
var name = rs.getString("name");
return Optional.of(new User(idd, name));
}
return Optional.empty();
}
public void close() throws SQLException{
this.findUserQuery.close();
this.createUserQuery.close();
this.conn.close();
}
}
public static void main(String[] args) throws SQLException {
try(var userRep = new UserRepository("jdbc:sqlite::memory:")) {
var id = userRep.createUser("user1");
userRep.findById(id).ifPresentOrElse(System.out::println, () -> System.out.println("not found user"));
}
}
ログ
Javaのログはややこしい。
とりあえず覚えておきたいこととしてログ実装の抽象化部分(ファサード)と実装が分かれておりそれを組み合わせる形で現在は使われることが多い。
まず最初にlog4jが使われていたがJava標準の**java.util.logging(jul)**が実装され、そこまで流行らなかったにせよlog4jでログを出すライブラリとjulでログを出すライブラリが1つのプロジェクトで混在するようになってしまった。
そこでcommon languagesが登場しlog4jもjulも統一して使えるようになったがcommon languagesも使いづらく、slf4jが誕生しデファクトとなったそうな。
slf4jはファサードのため実装部分はlogbackがあるため、slf4j + logbackが広く使われているよう。その後、log4j2がリリースされLog4shellの脆弱性で世間を騒がせたりもしたがパフォーマンスを重視するならlog4j2を採用するケースも増えてるよう。安定をとるならslf4j + logback。
以下、log4j2によるログ実装の例。
build.gradle.ktsに以下を追加。
implementation("org.apache.logging.log4j:log4j-api:2.23.1")
implementation("org.apache.logging.log4j:log4j-core:2.23.1")
log4j-apiがファサードでlog4j-coreが実装部分。
src/main/resources配下に設定ファイルを配置する。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="INFO">
<Properties>
<Property name="logPattern">%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n</Property>
<Property name="logDir">logs</Property>
</Properties>
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="${logPattern}"/>
</Console>
<RollingFile name="RollingFile" fileName="${logDir}/app.log"
filePattern="${logDir}/app-%d{yyyy-MM-dd}-%i.log.gz">
<PatternLayout pattern="${logPattern}"/>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true"/>
<SizeBasedTriggeringPolicy size="10MB"/>
</Policies>
<DefaultRolloverStrategy max="10"/>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="com.example" level="debug" additivity="false">
<AppenderRef ref="RollingFile"/>
</Logger>
<Root level="${sys:LOG_LEVEL:-info}">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
設定ファイルはXMLで書かれていることが多い。JSONやYAML形式でも書けるらしいがネットの情報はほぼほぼXMLで書かれてるのでXMLで書く。YAMLで書きたい感もあるがあえてYAMLで書く必要もなさそう。
設定ファイルはConfigurationタグから始まる。その中に大きく分けてProperties、Appenders、Loggersタグに分類される。
Propertiesタグには設定ファイル全体で使うプロパティを定義する。上記の例ではログのフォーマットをプロパティとして定義している。
Appendersタグにはログをどこに出力するかを決めるアペンダーを定義する。アペンダーにはConsoleアペンダーやFileアペンダーなどがある。
Loggersタグにはロガーを定義する。特定のパッケージやクラスで出力するログの設定をする。
ログの使い方は以下のような感じ。
package org.example;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class LogDemo {
private static final Logger logger = LogManager.getLogger(LogDemo.class);
public static void demo() {
logger.info("Info");
logger.warn("Warn");
logger.info("1 + 1 = {} 10 - 5 = {}", 2, 5);
try {
throw new Exception("Error");
} catch (Exception e) {
logger.error(e);
}
}
}
2024-08-25 09:19:57.668 [main] INFO org.example.LogDemo - Info
2024-08-25 09:19:57.670 [main] WARN org.example.LogDemo - Warn
2024-08-25 09:19:57.682 [main] INFO org.example.LogDemo - 1 + 1 = 2 10 - 5 = 5
2024-08-25 09:19:57.682 [main] ERROR org.example.LogDemo - java.lang.Exception: Error
上記の例のlogger.info("1 + 1 = {} 10 - 5 = {}", 2, 5);は、パラメーター化されたログで、プレースホルダーを使ってログを出力している。こうすることで、ログは遅延評価されることになりログレベルにより出力する必要のないログであれば無駄な文字列変換などの処理が走らなくなるのでパフォーマンスが向上する。そのため、log4j2ではこのようなプレースホルダーを使用したログの出力が推奨されている。
Lombok
Javaはどうしてもボイラープレートと呼ばれるような冗長なコードが多くなりがち。そのようなボイラープレートをアノテーションからコンパイル時に自動生成することで記述量を大幅に減らせる。
導入には以下の依存関係を追加する。
compileOnly("org.projectlombok:lombok:1.18.34")
annotationProcessor("org.projectlombok:lombok:1.18.34")
testCompileOnly("org.projectlombok:lombok:1.18.34")
testAnnotationProcessor("org.projectlombok:lombok:1.18.34")
IDEにLombokのプラグインがだいたい用意されているのでプラグインを入れることで適切なコード補完が出たり、不要な警告を防げるようになる。
アノテーションにはいろいろあるがよく使うのは
@Getter@Setter@Data@ToString@Builder@Log4j2@Sl4j
ここら辺だと思う。
package org.example;
import lombok.*;
import lombok.extern.log4j.Log4j2;
@Log4j2
public class LombokDemo {
public static void demo() {
@Getter
@Setter
@RequiredArgsConstructor
@ToString
class User {
@NonNull private final String name;
private int age;
}
var user = new User("user");
user.setAge(30);
System.out.println(user);
log.info("Lombokでloggerの初期化しました");
val a = "";
}
}
たしかにgetterやsetterを省略できるのは楽。ただ、コンストラクタは省略されていると認知不可が上がる気がする。@NonNullは後述のBean Validationもあるので使うならこっちは使わないかも。Loggerの宣言もいらないのは楽かも。特に@Dataが強力すぎて多用してしまいがち。
Lombokはかなり強力な機能のため使われている現場が多そうだが@Dataは多用すると考えなしにsetterを生やすことになるので不要にプロパティを変更可能な状態にしてしまってたりしそう。コンストラクタも引数なしならいいが、複数のコンストラクタがある場合は省略しないで書いた方がわかりやすい気がする。
特にLombokが力を発揮したのはDTOやPOJOと呼ばれるクラスを作るときだと思うがrecodeが実装されたことでデータ構造を持つだけのクラスを作るのは容易になった。加えてIDEの機能でgetterやsetter、equalsやhashcodeも自動生成できるようになっている。
現代の開発でもLombokは強力な武器になるが敢えて使わないという選択もありな気がする。個人的にはなくてもそこまで困らないのでなくてもいい気がしている。そもそもアノテーションだらけになるコードがそんなに好きじゃない。後述するBean Validationは特に好きじゃない
Bean Validation
宣言的にバリデーションルールを適用できるライブラリでSpringなどのフレームワークで広く使われている。導入は以下のように依存関係を追加する。
Bean Validationは仕様のため、実際に使うのは実装であるhibernate-validator。メッセージ解決のための評価式にexpresslyの依存も追加する必要がある。
implementation("org.hibernate.validator:hibernate-validator:8.0.1.Final")
implementation("org.glassfish.expressly:expressly:6.0.0-M1")
使い方は以下のような感じ
package org.example;
import jakarta.validation.Validation;
import jakarta.validation.constraints.NotBlank;
import jakarta.validation.constraints.PositiveOrZero;
public class BeanValidationDemo {
record User(
@NotBlank
String name,
@PositiveOrZero
int age
){}
public static void demo() {
try(final var vf = Validation.buildDefaultValidatorFactory()) {
final var validator = vf.getValidator();
var user = new User(null, 20);
validator.validate(user).forEach(v -> System.out.println(v.getMessage()));
user = new User("", 20);
validator.validate(user).forEach(v -> System.out.println(v.getMessage()));
user = new User("user", 10);
validator.validate(user).forEach(v -> System.out.println(v.getMessage()));
}
}
}
空白は許可されていません
空白は許可されていません
Spring + Thymeleafでフォーム入力があるとき、フォームの値をBean Validationでバリデーションし、その結果を表示するという感じでSpringといい感じに統合されている。
独自でバリデーションルールを作成したい場合は以下のようにしてカスタムバリデーションを定義することができる。
@Constraint(validatedBy = StartsWithValidator.class)
@Target({ ElementType.FIELD, ElementType.PARAMETER })
@Retention(RetentionPolicy.RUNTIME)
public @interface StartsWith {
String message() default "The string must start with the specified prefix";
String value(); // 必須のプロパティとして接頭辞を定義
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default {};
}
package org.example;
import jakarta.validation.ConstraintValidator;
import jakarta.validation.ConstraintValidatorContext;
public class StartsWithValidator implements ConstraintValidator<StartsWith, String> {
private String prefix;
@Override
public void initialize(StartsWith constraintAnnotation) {
this.prefix = constraintAnnotation.value(); // アノテーションの値を取得
}
@Override
public boolean isValid(String value, ConstraintValidatorContext context) {
if (value == null) {
return true; // @NotNullなどと組み合わせた場合に対応
}
return value.startsWith(prefix); // 値が指定された接頭辞で始まるかを検証
}
}
個人的にはアノテーションだらけになるのと、バリデーションロジックが散らかるという点でYAVIのようなバリデーションライブラリの方が好み。
マルチスレッド処理
歴史的に以下のようなキーワードがある。
- Thread
- ExecutorService
- WebFlux(リアクティブプログラミング)
- Virutual Thrad
Java19から入ってJava21で正式に使えるようになったVirtual Threadがなぜ作られたのかが以下のスライドがわかりやすい。
ThreadはOSの物理スレッドと1対1で対応するため、メモリ消費量や処理パフォーマンスなどに問題があった。そのため、ExecutorServiceなどを使ってスレッドプールを使うようにして並行・並列処理を書くのが主流だったっぽい。
その後、リアクティブプログラミングの流行りからかSpring Web Fluxのようなノンブロッキングなプログラミングが流行る。これは非同期処理というかスレッドのブロッキングを避けスループットを上げるというパフォーマンス向上の面が強いがJavaにおけるスレッドの使い方ということで取り上げる。
ただ、ノンブロッキングなプログラミングは今までのプログラミングモデルと異なる部分が多く学習コストというか使いこなすのが難しいという面があったように感じる。
このような歴史から、簡単に今までのThreadよりも高パフォーマンスで大量にスレッドを作成できるようにVirtual Threadが作られた。
Virtual ThreadはSpringなどのフレームワークが対応してきたらそれを使えばいいし、単独で使うにしてもExecutorServiceから使うなどして直接Virtual Threadを扱う必要はないらしい。なんにせよまだ情報が少ない
今から積極的に学ばなくてもいいもの
Servlet/JSP
JavaのServletはHTTPリクエストを処理したり、動的コンテンツを生成するためのサーバーサイドプログラム。Servletはそれ単体では動作することはできず、通常TomcatのようなServletコンテナと呼ばれる実行環境上で動作する。
JSPはHTML内にJavaコードを混在させることができ、動的なコンテンツを生成するための技術。JSPはTomcatのようなServletコンテナ上でServletにコンパイルされ、クライアントからのリクエストを処理したりする。
現代のJavaによるサーバーサイド開発の現場ではSpring bootのようなフレームワークが使われていることが多く、ServletやJSPを直接学ぶ必要はない。
Springの内部的にServletが使われているかもしれないが直接Servletを扱う機会はほとんどないはず。JSPもThymeleafというテンプレートエンジンがあるため、学ぶ必要なないと言える。
Swing/JavaFX
SwingはJavaでデスクトップアプリケーションを作成するための技術。古くから、特にエンプラ系で使われていた。GUIアプリケーションが全盛の時代に広く使われていたと思うが、現代ではブラウザで使用できるWebアプリケーションの方が好まれる傾向にあるように感じる。
Swingはメンテナンスモードに入っており、後継としてJavaFXがあるようなので今から新しく学習する必要はないように思われる。
デスクトップアプリケーションでいうとElectronやTauriなどRustやTypeScriptで書けるツールもあり、あえてSwing や JavaFXを採用するメリットはない気がする。Javaで全部やりたいとかなければ
現在でもSwingやJavaFX製のアプリケーションは多く稼働しているものがあり、開発をすることもあるかもしれないが、必要になったときに学べばよく、今から積極的に学ぶ必要性は薄い気がする。
JavaのFW事情
Spring
少なくとも国内では圧倒的にSpringが使われていると思う。Spring frameworkは認証やDB操作やいろんな機能が組み合わせて使用できるフルスタックフレームワーク。起動が遅いのがデメリット。
quarkas, Micronaut
コンテナ時代にSpringの起動の遅さはデメリットになる。コンテナ上で実行することを考えて作られたフレームワークがquarkasとMicronautなどがある。Springベースで実装でき、起動が早いのが特徴。
spark / javalin
Rubyのsinatraを参考に作られた軽量フレームワークとしてsparkがあったがそこからforkする形で作られたのがjavalin。Javaはどうしてもエンプラ系で使われることが多く、大規模開発が多いのでSpringのようなフルスタックフレームワークが使われることが多いが、手元でサクッと動かすような軽量フレームワークがあまりなかった印象。
sparakやjavalinはGoのechoのような雰囲気で使えそうなので個人的にはそのくらい軽いフレームワークが好みなので気になる。javalinの方が後発なのでjavalinの方が良さそう?
抜けてたので追記
Optional
Java8で導入された。Javaはnullableな型を表現することはできないのでnullが混入していそうな値にはnullチェックを徹底して行う必要がある。nullである可能性のある値を安全に扱うためにOptionalは使用することができる。
var str = Optional.of("string");
var str2 = Optional.empty();
// str is present: true
System.out.println("str is present: " + str.isPresent());
// str2 is present: false
System.out.println("str2 is present: " + str2.isPresent());
基本はOptional.ofもしくはOptional.ofNullableで値をOptionalでラップする。空のOptionalを明示的に作るならOptional.emptyが使える。
Optionalは関数の戻り値として使われることが多く、安全に関数の戻り値を扱うことができる。
var optVal = doSomething();
if(optVal.isPresent()) {
System.out.println(optVal.get());
}
if(doSomething2().isEmpty()) {
System.out.println("null value");
}
isPresentやisEmptyでOptionalの値があるのかを確認し、処理を書くことができる。値を取り出す場合はgetで取り出せるが、値がない場合はNoSuchElementExceptionが発生してしまうため、必ず値を存在をチェックした後か後述のorElseなどを使い、get単体ではあまり使わない方がいい。
実践的な使い方としては以下のようなラムダ式を利用した関数型的な書き方ができる。
// 値がなければエラーをスローする
var result = doSomething().orElseThrow(() -> new RuntimeException("null value"));
// 値がなければ指定の値を使う
result = doSomething().orElse("");
// 値がなければ指定の処理で値を生成する
result = doSomething().orElseGet(() -> {
var other = "other";
return other.toUpperCase();
});
// 値があれば指定の処理を実行する
doSomething().ifPresent(System.out::println);
// 値があれば第一引数の処理をし、なければ第二引数の処理を実行する
doSomething().ifPresentOrElse(
System.out::println,
() -> { throw new RuntimeException("null value"); }
);
// 指定のPredicateがfalseだったら空のOptionalになる
doSomething()
.filter(s -> Objects.equals(s, "value"))
.ifPresent(System.out::println);
// 指定の処理をOptionalのまま実行する
// 値がなければ空のOptional
doSomething()
.map(String::length)
.ifPresent(System.out::println);
record User(String name) {
public Optional<String> getName() {
return Optional.ofNullable(this.name);
}
}
// ネストしたOptionalをフラットにする
Optional.of(new User("user"))
.flatMap(User::getName)
.ifPresent(System.out::println);
ジェネリクス
ジェネリクスは型安全に汎用的な処理を記述することができる強力な記法です。ジェネリクスは以下のような型パラメーターをクラスやインターフェース、関数に宣言することで実装することができます。
public static void demo() {
// ジェネリクスクラス
record Box<T>(T item){
}
var box = new Box<>(1);
System.out.println(box.item());
// ジェネリクス関数
System.out.println(len("value"));
System.out.println(len(100));
System.out.println(len(true));
}
private static <T>int len(T value) {
return value.toString().length();
}
上記の例でいうと型パラメーターTが宣言されているためT型のitemを保持するBoxクラスを定義することができています。これは、インスタンス化するときにコンストラクタの引数から型推論されT型の型が決まる。上記の例でいうとコンストラクタ引数に1を指定しているので型パラメータはInteger型として推論される。
非境界ワイルドカード
ジェネリクスといえばワイルドカードがでてくると途端に難しくなる。というかパズル感が増す。
// List<E> list = new ArrayList<E>();
List<Object> list = new ArrayList<>();
// 型パラメータEがObjectなのでList<String>も入りそうだが入らない
// String型がObject型を継承していてもList<Object>型とList<String>型は一致しないため
list = new ArrayList<String>();
とりあえず上記の例にあるように型パラメータが継承関係にあったからといっても代入することはできない。List<Object>で宣言したらList<Object>と一致しないと代入できない。List<String>などではだめ。
しかし、以下のようにワイルドカードを使うと代入できたりする。
// 非境界ワイルドカード型
// こういうの
List<?> list2 = new ArrayList<>();
// List<?>は全てのList<E>の親クラスになる
// つまりList<String>もList<Integer>も入る
list2 = new ArrayList<String>();
list2 = new ArrayList<Integer>();
上記のようにList<?>であればList<String>でもList<Integer>でも代入できる。これが非境界ワイルドカードというもの。
注意点としては非境界ワイルドカード型で受けた場合、Object型になるという点と非境界ワイルドカード型を引数に取る関数はnullしか受け付けなくなるということ。
List<?> list2 = new ArrayList<>();
// これはObject型になる
var elm = list2.get(0);
// nullしか受け付けない
list2.add(null);
非境界ワイルドカード型と原型
繰り返しになるが非境界ワイルドカード型には以下のような制約がある。
- 関数の戻り値の型パラメーターはObject型になる
- 関数の引数の型パラメーターにはnullしか受け付けなくなる
しかし、原型というものがあり、これは二つ目の制約を無視できる。
List list3 = new ArrayList<String>();
list3.add("value");
list3の方はlist<E>の原型を指定している。 非境界ワイルドカード型では実行できなかったadd()が実行できるようになっている。しかし、IDEなどから警告が出るようになっている。
原型は後方互換性のために残されているため極力使用しないほうがいい。
境界ワイルドカード型
原型を使わずに非境界ワイルドカードを使いやすくするのに境界ワイルドカード型がある。
これには上限境界ワイルドカード型と下限境界ワイルドカード型がある。
ここでもう一度非境界ワイルドカード型の制約を載せておきます。境界ワイルドカード型はこの制約を緩めるためのものです。
- 関数の戻り値の型パラメーターはObject型になる
- 関数の引数の型パラメーターにはnullしか受け付けなくなる
上限境界ワイルドカード型
以下のようなもの。
List<? extends Number> list4 = new ArrayList<>();
// これは当然大丈夫
Object value = list4.getFirst();
// 型パラメーターの上限がNumberであることをコンパイラは知ることができるので
// これも大丈夫
Number num = list4.getFirst();
// 関数の引数は引き続きnullしか取れない
list4.add(1);
上記のように上限境界ワイルドカード型は非境界ワイルドカード型の
- 関数の戻り値の型パラメーターはObject型になる
という制約を緩め上限として指定した型で戻り値を受けることができるようになる。
下限境界ワイルドカード型
以下のようなもの。
// 下限境界ワイルドカード型
List<? super Number> list5 = new ArrayList<>();
// これは当然大丈夫
Object value2 = list5.getFirst();
// 型パラメーターはNumber型もしくはそのスーパークラス。
// もし実際の型がObject型であればNumber型で受けることはできない。
Number num2 = list5.getFirst();
// これは通る
// Number型かそのサブクラスを受け入れられる
// コンパイラはNumber型もしくはObject型であることを知ることができるので
// これは受け入れられる
list5.add(1);
上記のように下限境界ワイルドカード型は非境界ワイルドカード型の
- 関数の引数の型パラメーターにはnullしか受け付けなくなる
という制約を緩める。
上記の例だとNumber型で値を取り出すことはできなくなったが、NUmber型もしくはそのサブクラスの要素と追加することは可能となっている。
境界ワイルドカード型とPECS
PECSとはProducer-Extends、Consumer-Superの略。
Producer、つまりジェネリクス型を返すような関数では上限境界ワイルドカードを使うと良い。
Consumer、つまりジェネリクス型を消費するような関数では下限境界ワイルドカードを使うと良い。
ということ。境界ワイルドカードを使うときに上限と下限どちらを使えばいいのかの指針となる。
境界ワイルドカード型と変位について
変位には不変・共変・反変がある。
普通のジェネリクス型は不変。そのため、List<Integer>とするとList<Integer>と一致するようにしなければならない。
ジェネリクス型を共変にすると上限境界ワイルドカード型となる。共変の特徴は上限境界ワイルドカード型の特徴と一致する。
ジェネリクス型を反変にすると下限境界ワイルドカード型となる。反変の特徴は下限ワイルドカード型の特徴と一致する。
このようにジェネリクスは境界ワイルドカードを使い変位を変えることができるようになっている。ちなみにScalaではクラス宣言時に変位を指定することができるらしい。
参考
以下の記事が非常にわかりやすかった。
非境界ワイルドカードと境界ワイルドカードについて
PECSについて
Java EE(Jakarta)とGuava
Javaで開発しているとよく目にするのによくわかっていなかったので。
JavaEE(Jakarta)
ChatGPTに聞いてみた
Java EEの起源:
Java EEは、1999年にサン・マイクロシステムズ(Sun Microsystems)によって「J2EE」(Java 2 Platform, Enterprise Edition)として初めてリリースされました。Java SE(Standard Edition)に対して、エンタープライズ向けの追加機能を提供することを目的としていました。
Java EEは、エンタープライズアプリケーション開発に必要な多くの標準APIやフレームワーク(EJB、JPA、JMS、Servletsなど)を提供し、サーバーサイドJavaプログラミングの標準となりました。
オラクルによる買収とJakarta EEへの移行:
2010年にオラクルがサン・マイクロシステムズを買収した後、Java EEの開発もオラクルの管理下に入りました。しかし、Java EEの進化が遅れたことから、エンタープライズJavaコミュニティの不満が高まりました。
2017年、オラクルはJava EEの開発と管理をオープンソースコミュニティに移行することを決定し、Eclipse Foundationにその運営を委ねました。この時、商標権の問題から「Java EE」の名称を使うことができなくなり、新たに「Jakarta EE」という名前が採用されました。
Jakarta EEの進化:
Jakarta EE 8は、Java EE 8の後継として2019年にリリースされ、APIや技術仕様の多くはJava EE 8と互換性を持つように設計されました。
Jakarta EE 9では、より大きな変更が加えられ、パッケージ名がjavaxからjakartaに変更されました。この移行は、エンタープライズJavaの新たな発展を象徴するものです。
Java EEがエンタープライズ向けの機能を追加するためにサン・マイクロシステムズによって開発され、オラクルに吸収されて2017年にEclipse Foundationに移管され名称もJakarta EEい変わった。
パッケージ名もjavaxからjakartaに変わってる。
Javaで開発するうえではそのくらいを知っておけば良い。
Guava
Googleが開発、公開しているオープンソースのJavaのユーティリティーライブラリ。いろいろJavaの標準にはない機能を提供してくれてるらしいがあんまり必要になったことはないのと個人的にこういったユーティリティーライブラリを積極的に使う派ではないのでリンクだけ載せときます。
ユーティリティーライブラリとしてはApache Commonsなんかも有名
javaコマンド
IDEを使っていれば直接javacやjavaコマンを使ってビルドしたり実行したりすることはあまりない。しかし、実際にアプリケーションをデプロイする際にはビルドと実行コマンドでアプリケーションを実行することになるのでここら辺も知っておいた方が良い。
ビルドと起動
ビルドはjavacコマンドでする。javacにはjavaファイルを指定する。ビルドするとクラスファイルが作成されるためjavaコマンドで実行する。指定するのはクラス名。
mkdir hello
cat <<EOF > hello/Hello.java
package hello;
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
EOF
javac hello/Hello.java
java hello.Hello
> Hello, World!
packageが指定されている場合はそのpackageと対応するディレクトリ配下にクラスファイルが存在している必要がある。
単一のソースコードであればjavaコマンドで直接コンパイルと実行ができる。
java hello.Hello
Hello, World!
JARファイル
実際の開発現場ではJARファイルにビルドして1つのファイルにし、実行環境に配置して実行することが多いと思う。コンテナ環境なんかでも1つのJARファイルにビルドして配置できたりするほうが便利。
JARファイルの作成には以下のようにbuild.gradle.ktsにマニフェストの記載を追加してgradleタスクを実行する。
tasks.jar {
manifest {
attributes["Main-Class"] = "org.example.App"
}
}
./gradlew jar
java -jar app/build/libs/app.jar
Hello, Java
Fat JAR
上記のJARファイルの作成方法では依存関係として外部ライブラリを追加していた場合、外部ライブラリはJARファイルに含まれない。依存関係も含まれるようにしたJARファイルをFat JARなどという。
Fat Jarはshadowプラグインを使って作成することができる。
plugins {
// Apply the application plugin to add support for building a CLI application in Java.
application
// これを追加
id("com.gradleup.shadow") version "8.3.0"
}
shadowJarというgradleタスクが追加されるので実行してFat Jarを作成する。
./gradlew shadowJar
java -jar app/build/libs/app-all.jar
Springのようなフレームワークを使っている場合は、フレームワークに組み込まれているビルドタスクなどを実行すれば良い、はず。
起動オプション
現代においてそこまで指定するものはない気がするがざっくりまとめておく。
- 実行関係のオプション
- -cp クラスパスの指定とか
- -jar jarファイルの実行とか
- -D プロパティの指定とか
- アサーション系のオプション
- -ea, -daとか実行前のアサーションの実行について
- デバッグ系のオプション
- いろいろあるけどすでに古くなっているオプションとかがありそう
- OOM時にヒープダンプ取るオプションはあると調査捗るかもしれない
java -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dump MyApplication
- HotSpot系のオプション
- 主にパフォーマンスに関わりそうなオプション
- GCに関するオプション
- メモリに関するオプション
-Xms512m-Xmx512m - コンパイラ関係のオプション これを調整するほどの機会がなさそう
エルゴノミクス・デフォルト
JVMが実行マシンのリソースなどから適切な起動オプションを自動で設定してくれる。JVMにお任せ的なやつ。ここら辺の起動オプションに下手に手をいれるくらいならJVMに任せてしまった方がいいと思う。ヒープメモリの指定すらいらない気がする。そんなことないか。最大ヒープサイズと最小ヒープサイズは同じ値を指定することでメモリサイズの拡張のオーバーヘッドをなくすことができるなどがあるらしいのでメモリサイズは指定したほうが良さげ。
OOM時のビープダンプの設定もつけると良さそうだけどコンテナ主流の現在出力だけしてもダンプの確認まで考えなくてはいけなくて、永続化ボリュームをマウントしてそこに出力したり、S3みたいなストレージに転送したりとかも考えられるけどDatadogのようなクラウドネイティブな監視ツールで確認するほうが現代的。
なので最小、最大ヒープサイズを同じ値でするだけでとりあえずはいいんじゃないだろうか。
取り上げてない内容
- graalVM
- jaksonとかgson使ったjsonの扱い(XMLとかxlsxとかPDFとかファイル種別はきりないから)
- JShell(playgroundあればそんなに必要ない気がして)
- Java起動オプションとか(コンテナにしろサーバーレスにしろ勝手にスケールして自分でサーバーインスタンスの面倒を見なくなってるのとDatadogとかでアプリケーションの処理の詳細まで監視できるようになっている今、ここらへんの知識はそこまで必要ないかなと思って。そもそも学習しづらい)
- javaコマンドで指定する起動オプションとか
- VisualVMを使ったモニタリングとか
- ヒープダンプとったりとか