失敗から学ぶRDBの正しい歩き方を読む
1章 データベースの迷宮
- データベースはアプリケーションよりも寿命が長い
- 見て何かわからないような命名は避ける
- タイポのようなミスは気づいた段階で早期に直した方が良い
- CHECK制約をつける
- アプリケーション側でやってるかもしれないがCHECK制約があることでコードを見なくても仕様がわかる
- ちなみにMySQLでCHECK制約が使えるようになったのは8.0.16から
2章 失われた事実
- データの履歴が大事
- マスタデータの値が変わるとそれまでのデータの整合性が保てない可能性がある
- データを変更したときにその結果に至るまでの過程の状態が失われてしまう可能性がある
- 過去の状態、過程は大事
- そのため、履歴の保存が大事
- 論理削除なんかは過去の状態を消さないための履歴の保存とも言える気がする
- 履歴の保存はトレードオフ
- 保存するレコード量が増えたり、集計の際のパフォーマンスに影響がでるかも
- パフォーマンスを考えてあえて履歴を保存しないという選択もある
- その場合は遅延レプリケーションやElasticsearchなどの分析ツールに保存する
遅延レプリケーションについて
DBのマスターノードとスレーブがあるときにスレーブへのデータ同期を遅延させることでマスターのデータが壊れた時にスレーブから復旧させられるようにできる。遅延の時間は1時間でも3時間でも1日でも要件によって。
AWSやGCPのようなパブリッククラウドのマネージドサービスとしてDBを使用する場合、AWSのRDSなら別のAZにレプリカを作成し高可用性の構成を推奨してたりする。
3章 やり過ぎたJOIN
- 不用意なJOINは危険
- JOINの回数が増えると計算量が指数関数的に増加する
- そのため、パフォーマンスに致命的な影響がでる可能性がある
- しかし、これはインデックスが貼られていることで計算コストを大きく減らすことができる
- JOINのアルゴリズムは主に以下の3つがある
- Nested Loop Join(NLJ)
- Hash Join
- Sort Merge Join
- NLJは1行ずつループして処理する
- Hash Joinは小さい表を全件読み、ハッシュ表を作る
- 大きいテーブルを全件ハッシュ表を見ながら読み込む
- 結果、両テーブルを全件読み込みだからO(N) + O(N) = O(2N) = O(N)ということでいいなのか?
- Sort Merge Joinは2つの表を結合キーでソートして上から順に値を比較して結合
- Postgreは3種類をサポートしているが、MySQLはNLJしかサポートしていない
4章 効かないINDEX
B-treeインデックスとして考える
検索結果が多い、全体の件数が少ない
- 10万件のレコードをフルスキャンするよりインデックスを貼ることで数ブロック見るだけで見つけられる
- しかし、検索結果が多い場合はフルスキャンした方が速いこともある。
- 極端な例だと1万件のレコードから9999件のレコードを取得するならフルスキャンの方が速くなる
- 一般的な実務レベルでは検索結果がテーブル全体の10%未満を指標にするのがいい
- 数万から数十万行のテーブルにインデックスを貼る
- 都道府県マスタのような47件しかないテーブルにインデックスを貼っても使われず、フルスキャンの方が速い
- 10万件の会員データから10%の10代を引いてくる場合、インデックスが使われる可能性は高い
- しかし、50%の20代を引いてくる場合インデックスは使用されない可能性が高い
- そして、これは月日が経つことでデータの比率が変わってくるためインデックスの使われ方も変わるということに注意する必要がある
条件にその列を使ってない
- よくあるのが以下のような例
SELECT*FROM users WHERE age*10>100;
これは以下のようにするとインデックスが効く
select * from users where age > 100 / 10;
- 関数の引数に指定した列のインデックスについても同じことが言える
- Postgreの場合、式インデックスというものがあるのでインデックスを利かすことができるらしい
カーディナリティの低い列に対する検索
- 性別のようなデータの種別が少ない(カーディナリティが低い)列にインデックスを貼っても有効に使われない可能性が高い
- 性別のような場合インデックスを貼っても、50%が検索結果としてヒットする可能性が高く、検索結果が多すぎる
あいまいな検索
- 前方一致でしかインデックスは効かない
- 後方一致でインデックスを効かせたい場合、revers()などの関数で対象の列をひっくり返し別の列に保存したり、Postgreの式インデックスを使う必要がある
- 部分一致は全文検索インデックスなどを利用する必要がある。
統計情報と実際のテーブルで乖離がある場合
- インデックスを利用するかどうかはクエリオプティマイザが決める
- オプティマイザは定期的に作られる統計情報に大きく依存する
- 統計情報とはテーブルから一定数のサンプリングを行い作られるもの
- サンプリングの前に大量データ更新が行われたり、サンプリングで偏ったデータが使われたりすると実行計画の精度に影響する
- SQLアンチパターンにインデックスショットガンというアンチパターンが紹介されている
- これは闇雲にインデックスを貼りまくるやつで昔よくやっちゃってた
- インデックスを貼ると更新系のクエリが遅くなるのと複雑な複合インデックスを貼るとオプティマイザが不適切な選択をすることがある
- これについてはMENTORの原則に基づいて対応しましょうとのこと
- 要はちゃんとスロークエリなどのモニタリング情報を見て、実行計画を確認して、有効なインデックスを貼ろうねみたいな感じ、たぶん
- インデックスは作るより削除する方が難しい
- インデックスはディスク容量も食うし、更新系のクエリのパフォーマンスに影響するので不要なインデックスは残しておきたくない
- なので、インデックスはよく考え、不要なインデックスはつくらないようにする
- 基本的にデータが少ないならインデックスは不要
- 複合インデックスでまとめる、もしくは単一インデックスで十分ではないか検討する
あいまい検索の補足
全文検索の話がでたので少し補足。MySQLで全文検索をする場合FULLTEXT INDEXを使用することができる。以下の記事がわかりやすい
MySQLで全文検索をするときにLIKE検索、FULLTEXTの他にMroongaというツールもある。これはInnoDBの代わりに指定することで使えるよう。以下の記事にまとまってる
パフォーマンスチューニング
以下のパフォーマンスチューニングについての記事
5章 フラグの闇
- 代表的なのは削除フラグ。
- 削除フラグをあちこちにつけてしまうとリレーションされてるデータを引く時に全部JOINしなくてはいけなくなるケースがある
- クエリが複雑になるし、パフォーマンス的な影響もでる
- UNIQUE制約もつかえない
- カーディナリティも低くなる
- 削除フラグだけでなくステータスや有効・無効などの状態をDBが持ってることが問題
- DBには事実のみを記録する
- 例えば、削除フラグの話だと物理削除し、削除用のテーブルを用意してそっちに移すようにするなどの方法が考えられる
- または、トリガーを使うことでアプリケーション側で考えなくて良くなる
- Viewを使うなども有効
- 対象のテーブルが小さく、インデックスが不要でJOIN対象にならなそうなどの条件が揃っていれば削除フラグをあえて許容するのもあり
6章 ソートの依存
- RDBはソートが苦手。
- RDBのクエリには処理の評価順があり、ソートを実行するORDER BYはSELECTの後に実行される。
- つまり、データを取り出してから並びかえが実行されることになる
- ソートがクイックソートのようなアルゴリズムなら計算量はO(NlogN)で高速な部類ではないのか?とも思ったが、DBにおけるソート処理は消費するメモリやI/O処理であることを考えるとコストは高い処理になる。
- このようにORDER BYは高コストになりがちなのでWHEREで件数を絞ることが重要。
- なので、WHERE句に指定する列に対するインデックスを貼ることでさらに高速化が期待できる。
- しかし、カーディナリティが低い列だとインデックスを貼っても高速化は期待できない。
- WHERE句でのインデックスが期待できない場合ORDER BY句へのインデックスが重要。
- インデックスはソート済みの状態で作られるため、ソートしたデータを取得したいならばインデックスからそのまま取り出せる。
- ページネーションでLIMITとOFFSETを使うのはアンチパターン。
- OFFSET分読み込む必要があるから
- ページネーションは難しい
- LIMIT-OFFSETを使う場合はOFFSET分読み込む必要があるのでwhere句でなるべく絞るようにすることを考えたり、JOINやGROUP BYなどクエリが複雑になってかたときのインデックスとかも考えないといけないし、データは常に増えていくので表示がずれることなど考えることがいっぱい
- なので、RedisのようなNoSQLを併用するような手法が効果的
- ただ、どうRedisを組み込むのかがあんまりイメージできてない
- LIMIT-OFFSETに変わる手法として以下のようなシーク法というのがあるらしい
- これは最終行の何らかのkeyを使うことで次のページ情報を取得するような手法
- これなら途中でデータが追加されたことによるUIの表示ずれのようなものは起きないけどページ数を指定した表示は難しい
- 無限スクロールならいいかもしれない
- ソート処理は基本的にはクイックソートが使われる
- しかし、データ数が多くメモリ上で実行できなくなるとソート結果をファイルに書き出す外部ソートに変わる
- そのため、データ数が増えたことで急にクエリが遅くなるということがある
- 以下の記事がいろんな手法比較してて参考になる
- この記事ではページ番号指定でLinkヘッダにページ番号リンクを付けてレスポンスを返す方法をとってるらしいがページ番号指定方式の実装は具体的にどうやるのだろうか
- 結局LIMIT-OFFSETの方式になってしまわないだろうか
- Redisでやる場合を考えたけどデータ追加時にRedisのsorted setにid突っ込んどいて一覧表示にはRedisを見るようにする。なければDB見る
- レコードの作成順だけならこれでいいけど名前順とかになると難しい
- 単純な一覧表示ならシーク法もしくはRedisでidをsorted setに突っ込んどく実装でいけなくもない気がする
- これ以上複雑な一覧表示が必要ならElasticsearchのような全文検索エンジンを使った方がいいのかもしれない
7章 隠された状態
- IDにID以上の意味を含ませるのはアンチパターン
- それ以外にEAV、Polymorphic Associationsの2つのアンチパターンがSQLアンチパターンで紹介されている
EAV(Entity Attribute Value)
- 複数の目的に使われるカラムを用意する設計
- 以下のようなテーブル
|id| 属性名 | 値 |
|1| 年齢 | 32 |
|2| 特技 | サッカー |
- 属性に対する値があるのかないのか、属性があるのかないのか、組み合わせや属性名の一覧などわからないことが多い
- さらに、必須属性やデータ型が指定できなかったりなどの設計上の問題も多い
必須属性が設定できない
- 見出し通りでEAVでは必須属性が指定できない
データ型が指定できない
- これも見出しのまんまで値のカラムに固定のデータ型を指定できない。日付型のときもあれば文字列の場合もあるようではデータ型を指定できない
正規化されていないため外部キー制約が強制できない
- 例えば属性名に都道府県が入る時値カラムには「東京」と「東京都」の両方が保存される可能性がある
- 本来であれば都道府県マスタテーブルのようなものを作ってそのidを外部idとしてリレーションしておけば表記揺れは発生しないが、EAVではできない
Polymorphic Associations(ポリモーフィック関連)
- 子テーブルが複数の親テーブルを持つような設計
- 子テーブルの参照先によって親テーブルが変わるので外部キー制約が使えない
JSONの甘い罠
- JSON型が存在し、JSONの値をそのまま保存できる
- しかし、JSON型を安易に使うと検索やインデックスの関係からうまく使えないことも多い
- さらにORMがJSON型に対応していないことが多いなどデメリットも多い
- 外部APIのJSONレスポンスをそのまま保存することでAPIの仕様変更に対応できるなどといったメリットも存在する
9章 強過ぎる制約
- PostgreのDOMAINやMySQLのENUMのような強過ぎる制約は仕様変更に弱い
- DBスキーマを仕様変更により変更するにはALTER文を実行する必要があり本番環境が数時間ダウンする可能性もある
- なので、DBに強過ぎる制約をつけるのは考えたほうがいい
- MySQLは外部キー制約の子を更新しても親テーブルに共有ロックがかかりデッドロックの温床になる
- これは排他ロックをとることでデッドロックを回避できるらしいがロックがはずれるまで待つ必要があるのでパフォーマンスに影響する
- 制約は悪ではなく、ビジネスロジックや状態を持たない範囲で適切に制約をつけることが大事
- あえて段階を付けるなら以下のようになる
- 制約なし 何でも入る
- 弱い制約 NOT NULLとかUNIQUEとか。最低限ここは欲しい
- 強い制約 CHECK制約など。ここでつける制約は一般的な事実の範囲に収める。都道府県の数が47とか
- 強過ぎる制約 ビジネスロジックが漏れ出てる。これはやりすぎ
転んだ後のバックアップ
- バックアップには大きく分けて3種類ある
- 論理バックアップ mysqldumpなどのようにDBそのものを再構成できるようにバックアップを取ること
- 物理バックアップ データベースの物理ファイルをまるごとバックアップする手法
- PITR 特定の日時の状態にデータをリストアできる手法
- バックアップの設計をするときはどの手法を採用するにしてもRPO, RTO, RLOについて考える必要がある。
RPO(Recovery Point Objective): 復旧できるデータ
- 障害が発生したときに、いつの時点のデータを復旧するかの指針
RTO(Recovery Time Objective): 復旧までにかかる時間
- 障害が発生してから復旧するまでの時間
- 1日1回の物理バックアップお状態に戻すのが目標ならば物理バックアップを使ってDBが復旧するまでの時間がRTO
- 障害発生直前まで戻したい場合はPITRになる
- その場合、フルバックアップからトランザクションログを任意のところまで反映完了するまでの時間がRTO
RLO(Recovery Level Objective): 復旧したいレベル
- 障害が発生した時にどこまで復旧させるかの指針
11章 見られないエラーログ
- エラーログを最低限見れる状態にする
12章 監視されないデータベース
- まずはモニタリングすることが大事
13章 知らないロック
- ロックにはレベルと粒度という概念がある
- レベルは排他ロックや共有ろっくなど
- 粒度はテーブルロックか行ロックかなど
- ロックは
SELECT ... FOR UPDATEのように明示的に宣言することもできる -
INSERT ... SELECTのようなSELECTの結果を追加・更新するようなクエリはクエリが完了するまで対象の共有ロックを取得する - 外部キー制約も子テーブルに対する更新を行うと親テーブルが共有ロックを取る
- MySQLは対象ではない行もロックを取るギャップロックと** ネクストキーロック**がある。
ギャップロック
- MySQLは基本的に行レベルでロックを取る
- ギャップロックは行と行の間の領域に対してロックを取る
- これは複数のトランザクションが同じデータ領域に対して操作しようとしたときのデータの一貫性を保つ
- 例えば、他のトランザクションからの操作でデータが増えたら減ったりして見えてしまうファントムリードを防ぐ
ネクストキーロック
- 対象のレコードとその前後のギャップロックを組み合わせたもの
RDBMSによってロックの取り方は違う!!
14章 ロックの功罪
-
よく聞くRDBMSのACID特性
- Atomicity(原子性) トランザクション内の操作が全て実行されるか、されないかを保証
- Consistency(一貫性、整合性)
- Isolation(分離性、独立性) 実行中のトランザクションが他のトランザクションに影響しないことの保証
- Durability(永続性)
-
ここでIsonlationがよく話題に上がる
-
マイクロサービスではこのIsolationが保証できないから分散トランザクションがうんぬんみたいな話になる
-
マイクロサービスでなくてもIsolationを完全に担保するには直列で処理するしかなく並列での操作ができない
-
そのためトランザクション分離レベルを使い、Isonlationの制限を緩めている
-
トランザクション分離レベルは以下の4種
- read uncomitted
- read committed
- repeatable read
- serializable
-
下に行くほど並列度が下がる。serializableは完全な直列操作
-
トランザクション分離レベルによって以下のようなデータ不整合の発生する可能性がある
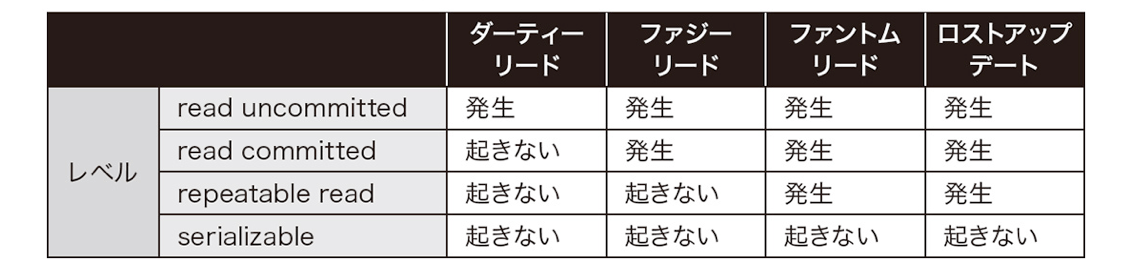
ダーティリード
- 他のトランザクションから自分のコミットしていない変更内容が見えてしまう現象
- ロールバックしたのにロールバック前のデータが読み取られて不正合が起きる的な
ファジーリード
- ダーティリードと違い他のトランザクションのコミットしていないデータは見えない
- トランザクションが途中にほかのトランザクションがコミットした内容は見えちゃう
- 分離レベルで言うとread commitedはファジーリードが起きるが、repeatable readでは起きない
- Postgreのデフォルトはread commitedだがMySQLはrepeatable read
ファントムリード
- 他のトランザクションがコミットした追加・削除が見えてしまう現象
- repeatable readにすることでファジーリードは防げてもファントムリードは防げない
- と書いてあったけど今はMySQLでのrepeatable readでファントムリードは基本発生しないらしい
- データの更新は見えないが追加や削除は見えてしまう
ロストアップデート
- 複数のトランザクションで更新が並列に実行された場合、結果が上書きされてしまうこと
- ロストアップデートはトランザクション分離レベルで振る舞いが変わる
- repeatable readの場合、後から更新した値で完全に上書きされる
- read commitedで
UPDATE 商品 SET 価格 = 価格 + 5 WHERE id = 1;のような値を読み取ってプラスするような更新処理では前のトランザクションで更新された値を読み取った上でさらに足して更新するような処理になる
15章 簡単過ぎる不整合
- 非正規化をパフォーマンス的な観点などからどうしてもやりたくなるときがある
- しかし、基本的には非正規化はすべきでない
- 非正規化が劇薬であることを知った上で使う判断ができるようになろう
- 非正規化したくなる3つの場面
テーブルを作って正規化するのが面倒なとき
- これは完全なアンチパターン
- 手間を惜しんだために大きな負債を作ることになる
外部キー制約によってデッドロックなどが発生しているとき
- このケースは外部キー制約をとって非正規化することで対応している現場が多い
- が、そういった対応はアンチパターン
- もしそのような時は適切にロックを取るように修正する
正規化によってJOINコストが高くなり、パフォーマンス影響が出た時
- 基本的には正しく正規化すればデータの重複はなくなり全体的なデータ量も少なくなりメモリに載せやすくなる、はず
- ただ、それでもパフォーマンス問題になるケースはあるのでそれは以下の項で
データの不整合と速度の等価交換
- 正規化とパフォーマンスの問題は大きく2つのパターンに分けられる
- 一つはN対Nのリレーションを表現するために交差テーブルを用意しているパターン
- インデックスが正しく貼られていれば問題にならないが、データ量が多くなったり、カーディナリティに偏りが出だすと著しくパフォーマンスが劣化する場合がある
- もう一つがJOINが多段になる場合
- JOINは掛け算なので多段になればなるほどパフォーマンスは劣化し、一つでもインデックスが効かないものがあればパフォーマンス影響は大きい
- この場合、非正規化ではなくキャッシュの利用を考えることが有効
- アプリケーションキャッシュやNoSQLなどの選択肢があるが、参照整合性とのバランスで決めるといい
非正規化の代替
- CHECK制約
- ENUM型 ENUM型は宣言した順にソートされる
- そのため、順序も含めて値を指定したい場合、CHECK制約よりも効果を発揮する
- 前述したようにこのような強めの制約は暗黙的になりやすく、制約の更新にはALTERを必要とするため変更コストが高い。
- なので、多用は厳禁で基本は非正規化を考えるべき
キャッシュ中毒
- キャッシュにもいろいろ種類がある
- DB側でキャッシュを利用するクエリキャッシュ
- DB側のクエリ速度が問題になる時に有効
- 頻繁に更新されるテーブルではキャッシュはクリアされるので効果は薄い
- 更新がされないマスタテーブルなどが対象だけど、それならばアプリケーション側でキャッシュしたほうが効率的
- なので、基本的にはクエリキャッシュは使用されることはない
- アプリケーションキャッシュ
- Redisやメモリキャッシュ
- キャッシュは劇的にパフォーマンス向上が見込めるがアーキテクチャやデバッグがかなり複雑になる
- まずはRDBMSで解決できないかを考えそれでも解決できなければキャッシュ戦略を考える
17章 複雑なクエリ
- 実装者のスキル不足 or テーブル設計がクソ
18章 ノーチェンジ・コンフィグ
- デフォルトのコンフィグではパフォーマンスは出ない
- MySQLではMySQL Tunerという診断ツールがある
- RDSのようなマネージドはこのようなコンフィグについて気にしなくて良い
塩漬けのバージョン
- 日頃からバージョンを最新にするようにしよう
20章 フレームワーク依存症
- フレームワークやORMとは上手く付き合おう
私も「失敗から学ぶRDBの正しい歩き方」をきっかけに、最近RDBのテーブル設計について学んでいます。とても参考になりました!
「失われた事実」「隠された状態」「フラグの闇」の解決案をあれこれ考えて記事にしてみました。
もしよかったら、いいね、コメント、ツッコミをもらえると嬉しいです!