BigQueryでパーティションカラム同士をusing句を使ってfull outer joinしたときにスキャン量を減らせない罠
前提
BigQueryではデータのスキャン量に応じて料金がかかるという仕組みになっています。
そのため、不必要なカラムはクエリから取り除いたり、参照元をパーティション分割テーブルにしておいたり、といった工夫で料金を抑えることができます。
(なお、クエリで全く使われないカラムについてはBigQuery側で判別してスキャンしないようにしてくれているので、途中のサブクエリで select * from ... のようにしても大丈夫だったりします。)
本題
今回、2つのパーティション分割テーブル同士を完全外部結合(full outer join)するようなクエリでスキャン量が減らせていないことに気づきました。
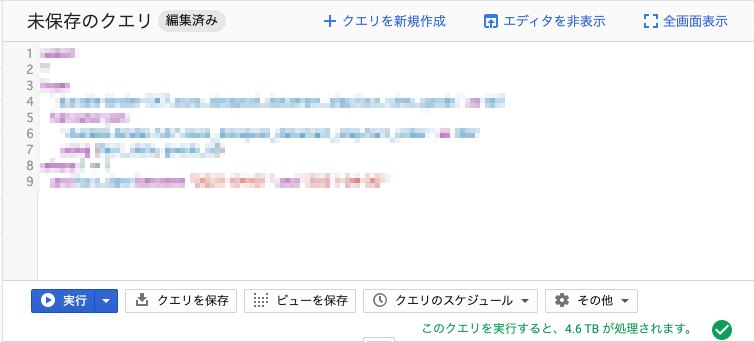
実行したクエリは以下のような感じ(テーブル名やカラム名を適当に隠しています)
select
*
from
`project.dataset.tbl1` as tbl1
full outer join
`project.dataset.tbl2` as tbl2
using (dt, id)
where 1 = 1
and dt between "2021-04-01" and "2021-04-30"
どちらのテーブルにもパーティションカラムdtが存在し、それを使って範囲条件を指定することでスキャン量を抑えるつもりでしたが、コンソールに表示されたスキャン量の予測は2つのテーブルをフルスキャンした時の数値となっていました。
using句にパーティションカラムを使うと、扱いが少し変わってしまうのかもしれません。
スキャン量を抑えるためにいくつかクエリの回収案を考えてみました。
案1:where句で2つのテーブルそれぞれに対して条件を指定
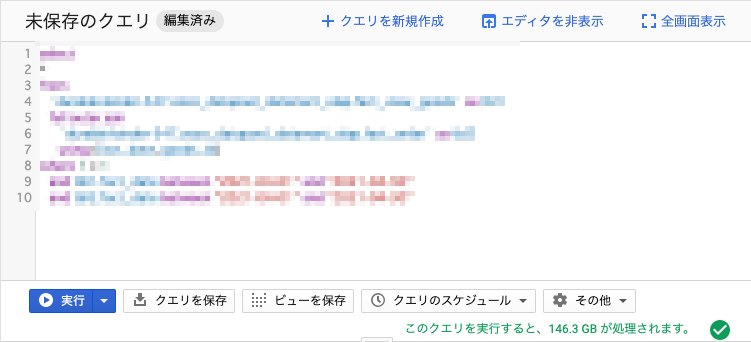
select
*
from
`project.dataset.tbl1` as tbl1
full outer join
`project.dataset.tbl2` as tbl2
using (dt, id)
where 1 = 1
and tbl1.dt between "2021-04-01" and "2021-04-30"
and tbl2.dt between "2021-04-01" and "2021-04-30"
まずは、明示的にそれぞれのテーブルのdtカラムに対して条件を指定するように修正してみました。
しかし、クエリ結果をよく見てみるとレコード数がだいぶ少なくなっていました。
元のクエリではfull outer joinをしているため、どちらか一方が欠損しているキーでも保持していますが、上のクエリのように両方のテーブルに対して明示的に条件を指定してしまうと、どちらか一方が欠損しているキーは落ちてしまうようです。
案2:条件同士をorでつなぐ
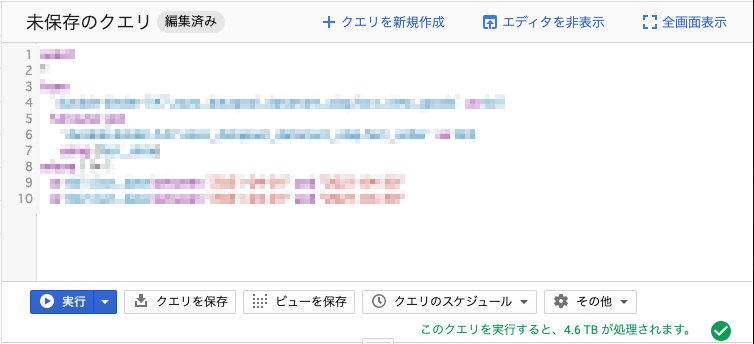
select
*
from
`project.dataset.tbl1` as tbl1
full outer join
`project.dataset.tbl2` as tbl2
using (dt, id)
where 1 != 1
or tbl1.dt between "2021-04-01" and "2021-04-30"
or tbl2.dt between "2021-04-01" and "2021-04-30"
そこで、次に条件同士をorでつないでみました。
しかし今度はスキャン量が元のクエリと同じフルスキャンした時の数値となってしまいました。
案3:先にサブクエリで条件を指定しておいて、後で結合する
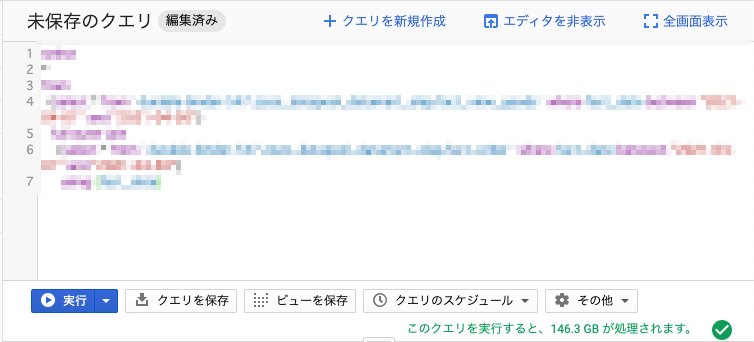
select
*
from
(select * from `project.dataset.tbl1` where dt between "2021-04-01" and "2021-04-30")
full outer join
(select * from `project.dataset.tbl2` where dt between "2021-04-01" and "2021-04-30")
using (dt, id)
やはり素直なやり方は、最初に個々のテーブルに対して条件を指定して必要なデータだけを明示的に読み込むようにして、結合処理などは後から行うというものかと。
これならスキャン量を抑えつつクエリ結果も望んだものとなります。
おまけ案:そもそもfull outer joinを使わない
select
dt, id
from
`project.dataset.tbl1`
where 1 = 1
and dt between "2021-04-01" and "2021-04-30"
union distinct
select
dt, id
from
`project.dataset.tbl2`
where 1 = 1
and dt between "2021-04-01" and "2021-04-30"
これまでは簡単にselect *と書いていましたが、実際には結合に使用したdt, idだけを抽出してマスターテーブルのようなものを作ろうとしていました。
そこで今回のクエリでやりたいことをよく考えると、union distinctを使ったクエリで十分だということがわかりました。
これも案3と同様、個々のテーブルに対して先に条件をして後から結合しているようなものですね。
(最終的に抽出するカラム自体も減っているのでスキャン量がさらに減っています)
おわりに
ググってみてもこの辺りの仕様を理解できる資料が見つけられなかったのですが、ご存知の方がいればコメントで教えていただけると嬉しいです。
Discussion